# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DragStream,首次实现视频生成时的实时拖拽编辑。用户可随时拖动画面中的物体,自由平移、旋转或变形,系统自动保持后续帧连贯自然,无需重训模型,无缝适配主流AI视频生成器,真正实现「所见即所得」。
随着视频扩散模型(VDMs)的快速发展,AI生成视频的写实度与流畅度实现了跨越式突破,自回归架构的VDMs更是让流式视频生成成为行业主流趋势,用户对视频生成的精细化、实时化控制需求愈发强烈。
但在实际应用中,现有技术始终无法满足用户的核心痛点:如何在视频流式生成的过程中,对画面进行实时、细粒度的交互式修改?
拖拽式操作凭借直观、易用、精细的特性,早已成为图像编辑领域的核心交互方式,也被业界视为视频交互式控制的最优解之一。但现有方案始终存在难以突破的瓶颈:
更关键的是,直接在流式场景中应用拖拽操作,还会面临两个无法回避的核心挑战:
针对行业现存的碎片化、局限性问题,新加坡南洋理工大学和合肥工业大学的研究人员在顶会ICLR 2026上,首次提出了流式拖拽导向交互式视频操控(stReaming drag-oriEnted interactiVe vidEo manipuLation,REVEL) 这一全新任务,彻底统一了拖拽式视频操控的标准范式。
研究人员同时打造了免训练的DragStream方法,真正实现了视频生成过程中「任意时刻、任意内容」的拖拽式编辑,支持平移、变形、2D/3D旋转等全类型拖拽操作,可无缝接入现有自回归视频扩散模型,彻底破解了流式拖拽编辑中隐分布漂移、上下文干扰两大核心行业难题。

论文链接:https://arxiv.org/abs/2510.03550
代码仓库:https://github.com/junbao-zhou/DragStream
项目主页:DragStream.github.io
Demo链接:https://huggingface.co/spaces/junbaozhou/DragStream
论文明确了,REVEL任务的核心目标是:让用户能够对自回归VDMs生成的任意视频帧,在任意时刻施加拖拽式操作,同时保证后续相邻帧与修改后的画面保持一致,最终实现对视频生成输出的流式、细粒度控制,让生成视频始终贴合用户预期。
更重要的是,研究人员首次将拖拽式视频操控统一为编辑与动画两大类型,且二者均支持用户自定义的平移、变形、2D/3D 旋转效果:
这一范式打破了过往拖拽视频方法「编辑与动画割裂、操作类型受限」的核心局限,为流式交互式视频编辑建立了统一的技术标准。
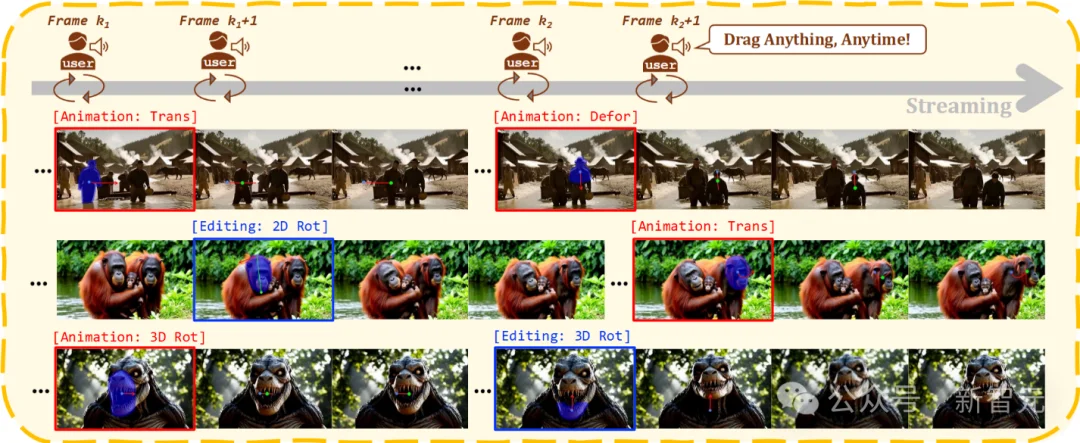
图 1:REVEL 任务效果示例。展示了通过 DragStream 实现的流式视频操控结果,涵盖物体平移(Trans)、变形(Defor)、旋转(Rot)等编辑与动画拖拽效果,直观呈现用户在视频生成的任意时刻,对任意画面内容进行拖拽修改的完整流程
为了在免训练的前提下解决REVEL任务的两大核心挑战,研究人员提出了全新的DragStream方法,通过自适应分布自校正(ADSR)策略与空频选择性优化(SFSO)机制两大核心创新,从根源上抑制隐分布漂移与上下文干扰,实现了高质量、高稳定性的流式拖拽视频操控。
1. 自适应分布自校正(ADSR):彻底解决隐分布漂移难题
拖拽操作带来的扰动,会让隐编码的均值、方差出现剧烈波动,导致隐嵌入严重偏离原始分布,最终让拖拽过程中断、画面内容错乱。
文中提出的ADSR策略,核心思路是利用相邻帧的统计信息约束隐编码分布:记录当前帧的前序相邻帧隐嵌入的均值与标准差,在每一轮隐优化迭代后,用这些稳定的统计信息对当前帧的隐编码分布进行校正。
这一简单却高效的策略,能够持续抑制拖拽带来的分布漂移,不仅保证了拖拽过程的稳定持续,还能有效避免拖拽过程中物体属性出现非预期变化,让修改后的画面始终保持一致性。
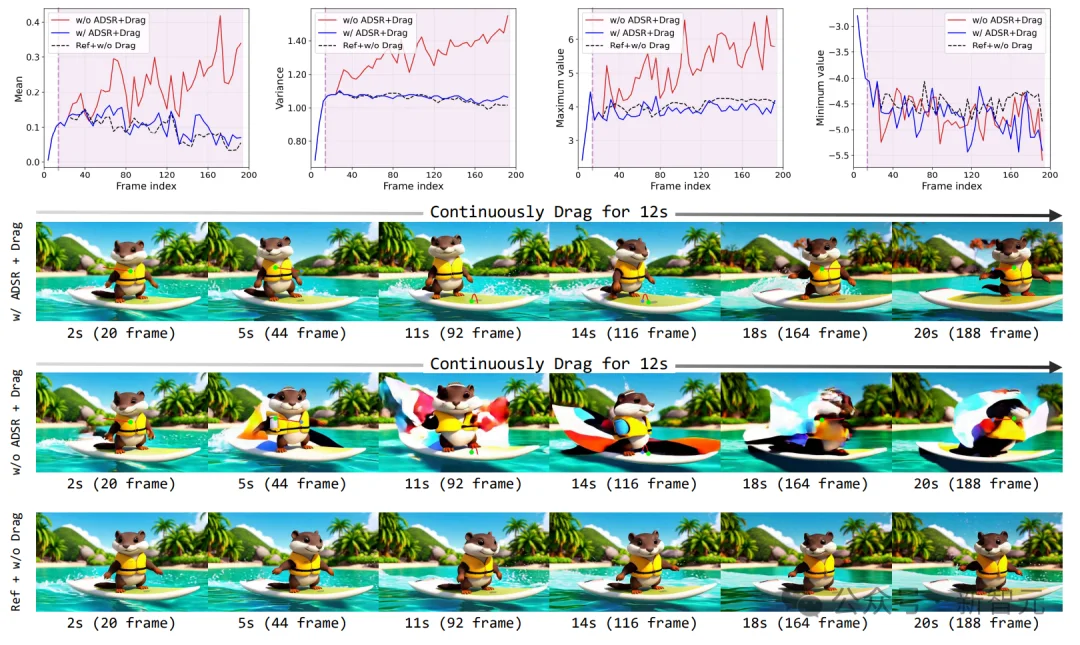
图 2:隐分布漂移挑战与 ADSR 效果对比。第一行展示了拖拽操作后隐编码均值、方差、极值的剧烈波动;无 ADSR 策略时,隐分布严重漂移,拖拽过程中断,物体属性出现异常;加入 ADSR 后,分布漂移被有效抑制,拖拽过程稳定,画面内容保持正常
2. 空频选择性优化(SFSO):平衡上下文信息利用与干扰抑制
上下文帧是流式视频生成的核心基础,却也是拖拽效果的主要干扰源 —— 过往帧的视觉线索极易误导模型,在拖拽区域周边生成重复部件、伪影等异常内容。
研究人员设计的SFSO机制,从频域与空域两个维度实现了选择性优化,在充分利用上下文帧视觉信息的同时,彻底缓解其带来的干扰。
可切换频域选择(SFS)策略
针对高频信息易引入伪影、低频信息缺乏细粒度细节的行业痛点,在DiT去噪器的自注意力模块中,通过2D傅里叶变换与巴特沃斯滤波器,在每一轮隐优化迭代中,从预设的截止频率集合中随机选择频率进行滤波,再通过逆傅里叶变换重构特征。
这一设计让模型能够平衡高低频信息的传播,既保留了画面的细粒度视觉细节,又避免了高频噪声主导拖拽过程,从根源上减少了伪影的产生。
临界驱动空域选择(CSS)策略
为了避免拖拽优化影响到非目标区域,研究人员通过高斯滤波图对梯度反向传播进行空间约束:梯度的权重会随着与拖拽编辑区域中心的距离增加而衰减,让优化过程始终聚焦在拖拽的核心目标区域,避免梯度泄露到背景与非编辑区域,进一步减少了画面的不自然失真。

图 3:上下文干扰挑战与 SFSO 效果对比。无 SFSO 策略时(ω=1),上下文帧干扰导致画面出现重复物体部件、明显伪影;加入SFSO (switchable)后,上下文干扰被有效抑制,拖拽效果精准,生成画面自然流畅
值得一提的是,研究人员提出的 DragStream 是完全免训练的,且具备模型无关的特性,能够无缝集成到任意现有的自回归视频扩散模型中,无需对模型主干进行修改,适配成本极低。
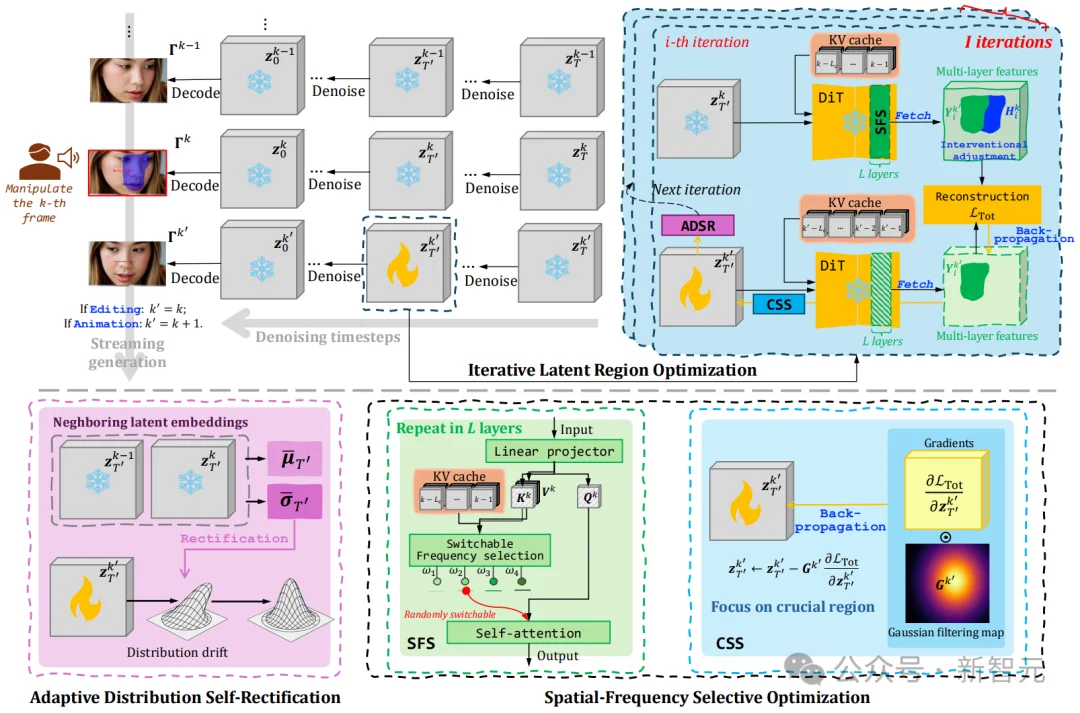
图 4:DragStream 整体技术管线示意图。完整呈现了从用户输入拖拽指令,到隐编码迭代优化,再到 ADSR 分布校正、SFSO 空频选择性优化,最终输出修改后视频帧的全流程
为了验证DragStream的性能,研究人员构建了包含204段不同场景、不同拖拽轨迹的视频基准数据集,与适配后的SOTA方法DragVideo、SG-I2V进行了全面的对比实验,结果显示DragStream在所有维度均实现了碾压级领先。
可视化效果:精准自然,无拖拽失效与画面畸变级
在各类拖拽场景中,DragStream都能实现精准的拖拽效果,完美保留物体的外观与结构,几乎没有视觉失真、伪影与拖拽失败的情况。而对比的SOTA方法,普遍出现拖拽失效、画面畸变、物体结构错乱、伪影严重等问题。

图5:DragStream与SOTA方法的可视化结果对比。展示了在2D/3D旋转、平移、变形等不同拖拽操作下,该方法相比DragVideo、SG-I2V,实现了更精准、更自然的拖拽效果,无拖拽失败、画面畸变等异常
量化指标:全维度领先SOTA级
采用 ObjMC(运动保真度)、DAI(拖拽编辑质量)、FVD(视频整体质量)、FID(画面保真度)四大行业通用指标进行量化评估,结果显示:
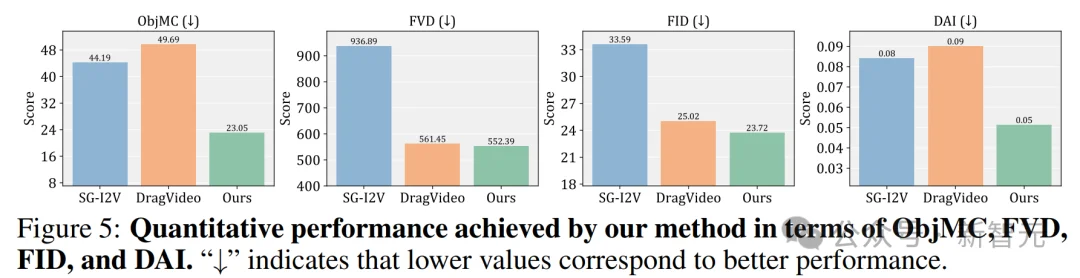
图6:DragStream与SOTA方法的量化指标对比。直观呈现该方法在 ObjMC、DAI、FVD、FID 四大核心指标上,均全面领先DragVideo与SG-I2V
超强泛化性:覆盖全场景复杂需求
研究人员通过大量拓展实验,验证了DragStream的超强泛化能力:
同时还发现,当拖拽指令与文本提示词发生冲突时,模型会始终遵循用户的拖拽指令 —— 因为 DragStream 对隐嵌入的修改更直接、更明确,真正把视频生成的控制权交到了用户手中。
该方法也存在局限性:在高度不合理、违背物理常识的拖拽指令下,方法无法实现高质量操控,因为这类指令与 VDMs 从大规模数据中学到的先验知识严重冲突,这也是未来行业可以继续探索的方向。
论文的核心贡献,不仅是提出了一个免训练、高性能的流式拖拽视频编辑方法,更在于首次定义了REVEL这一全新任务,统一了拖拽式视频操控的完整范式,彻底打破了过往视频生成「生成 - 不满意 - 重生成」 的低效循环。
DragStream的出现,让用户能够在视频流式生成的任意时刻,对画面中的任意内容进行实时拖拽修改,真正实现了 「想拖就拖,所见即所得」 的交互式视频编辑体验。同时,其免训练、即插即用的特性,也大幅降低了技术落地的门槛,为消费级交互式视频生成工具的发展奠定了坚实的技术基础。
REVEL任务的提出与DragStream方法的开源,一定能够激发业界更多的探索,共同推动流式交互式视频生成技术的进一步突破,让AIGC视频的创作自由度再上一个新台阶。
参考资料:
https://arxiv.org/abs/2510.03550
文章来自于“新智元”,作者 “LRST”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
