# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。

论文链接:https://arxiv.org/abs/2512.19920
一个仅 40 亿参数的模型在接受该方法训练后,其幻觉抑制能力竟然超越了 GPT-5 等前沿大模型。

图1:模型在回答数学问题时输出的置信度标注示例。每个声明都附带置信度分数和理由说明。
研究团队指出,当前主流的大模型后训练范式 —— 基于可验证奖励的强化学习(RLVR)—— 存在一个根本性的奖励错位问题。在标准 RLVR 中,奖励函数通常是二元的:回答正确得 + 1 分,回答错误得 - 1 分。在这种机制下,只要正确概率大于零,一个追求效用最大化的智能体会被激励生成可能错误的答案。这就造成了对「拒绝回答」行为的惩罚,迫使模型抑制不确定性的表达,将猜测伪装成事实。模型被训练成了「优秀的应试者」—— 为了最大化预期分数而猜测,而不是成为「诚实的沟通者」—— 在置信不足时选择放弃。

为了实现这一目标,研究团队设计了两种策略:

作为显示生成置信度的替代方案,该策略使用 PPO 算法中 Critic 网络的价值函数作为隐式置信度估计器。理论上,Critic 网络通过最小化预测值与策略回报之间的 Brier 分数进行训练,其价值函数会收敛到成功概率。
研究团队进一步将行为校准从响应级别扩展到声明级别,使模型能够精确标注答案中单个不确定的推理步骤,而非简单地拒绝整个回答。这一扩展面临三大挑战:
挑战一:连贯性问题。直接将不确定的声明替换为 < IDK > 可能破坏推理的连贯性 —— 例如在数学问题中,后续步骤往往依赖于前面的结论。研究团队选择让模型输出完整响应,同时用 HTML 标签可视化高亮不确定的声明。
挑战二:中间步骤的歧义性。在思维链(CoT)推理中,中间步骤的正确性和置信度存在天然歧义:一个步骤可能正确识别了前面声明中的错误。为此,研究团队忽略中间推理过程,仅在最终的结构化步骤上进行校准。
挑战三:缺乏细粒度标签。声明级的正确性标注难以获取。研究团队设计了基于弱监督的学习目标:将声明级置信度聚合成响应级置信度,再使用 Brier 分数奖励进行训练。

实验发现,最小值聚合在声明级评估中表现更优,因为它能更有效地激励模型识别推理链中的薄弱环节。而乘积聚合虽然更适合响应级校准,但可能导致单个声明的置信度过于乐观。
研究团队在多个基准测试上评估了该方法,包括字节跳动 Seed 团队发布的极具挑战性的数学推理基准 BeyondAIME,以及 AIME-2024/2025 和 SimpleQA(跨领域事实问答基准)。
核心评估指标

Confidence AUC:使用模型的置信度分数对正确和错误回答进行排序,计算 ROC 曲线下面积。AUC 越接近 1,说明模型越能准确地将高置信度分配给正确回答,将低置信度分配给错误回答。这是一个纯衡量模型「自知之明」的指标,不受模型本身能力强弱的影响。
响应级评估:超越 GPT-5
在 BeyondAIME 上的响应级评估结果显示(表 1),研究提出的方法显著优于 Qwen3-max,Kimi-K2,Gemini-2.5-Pro 和 GPT-5 等模型。其中,采用言语化置信度(Verbalized Confidence)、置信度乘积聚合(Qwen3-4B-Instruct-confidence-prod)的 40 亿参数模型取得了 0.806 的 SNR 增益,大幅超越 GPT-5 的 0.207。采用 Critic 价值函数(Qwen3-4B-Instruct-ppo-value)也取得了相当好的效果。
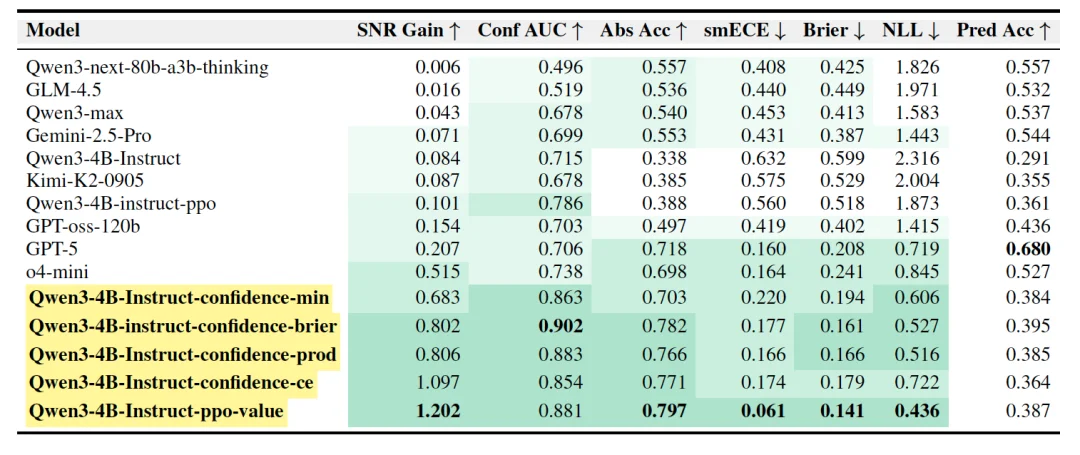
表1:BeyondAIME 响应级评估结果。SNR Gain 和 Conf AUC 是衡量幻觉抑制效果的关键指标,数值越高表示模型越能有效抑制幻觉。
声明级评估:超越 Gemini-2.5-Pro
研究团队还将行为校准从响应级别扩展到声明级别,让模型能够精确标注单个不确定的推理步骤。在 BeyondAIME 的声明级评估中(表 2),置信度最小聚合方法取得了 0.301 的 SNR 增益,显著优于 Gemini-2.5-Pro 的 0.019。
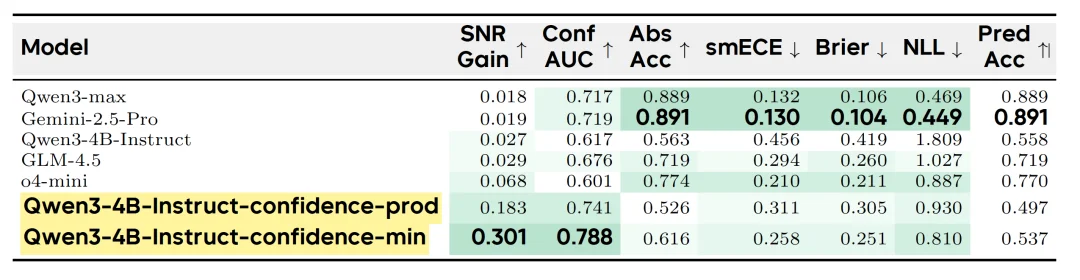
表2:BeyondAIME 声明级评估结果。最小值聚合方法在 SNR Gain 和 Conf AUC 两个核心指标上均大幅领先前沿模型。
置信度校准图:多数前沿模型缺少「自知之明」

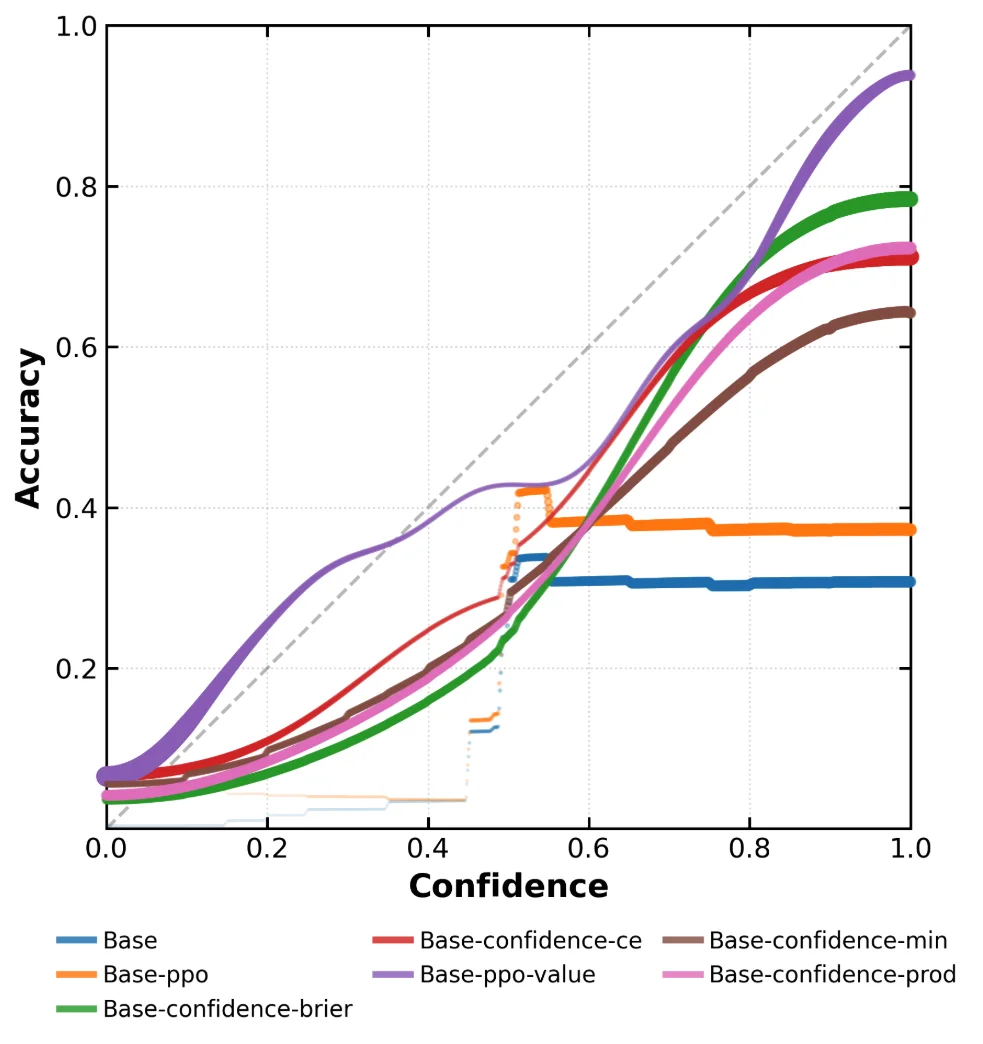
图2:前沿模型在BeyondAIME上的响应级置信度校准图。可以观察到,很多模型的准确率是一条水平线,与其声明的置信度几乎没有相关性。
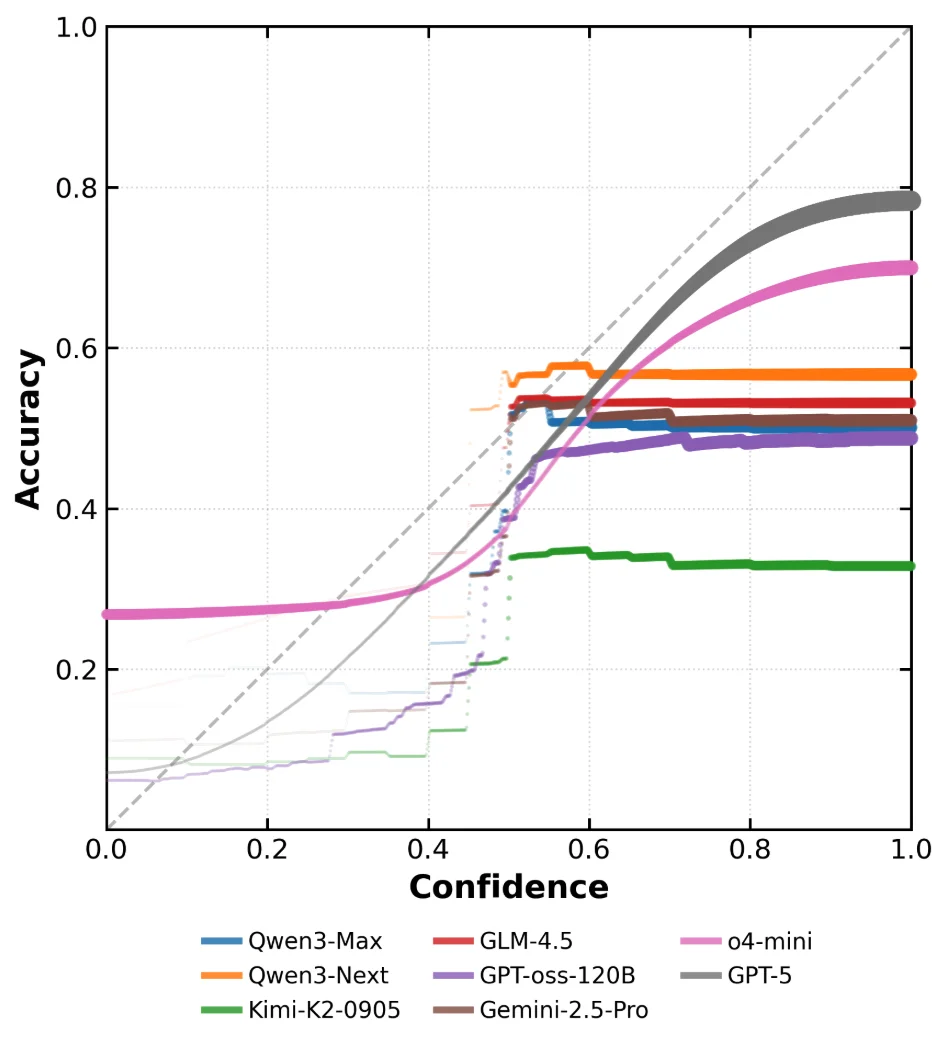
图3:本研究模型在BeyondAIME上的置信度校准图。经过行为校准训练后,模型的准确率与其声明的置信度呈现强烈的正相关关系。其中Base和Base-ppo是基准。
行为校准的四个目标
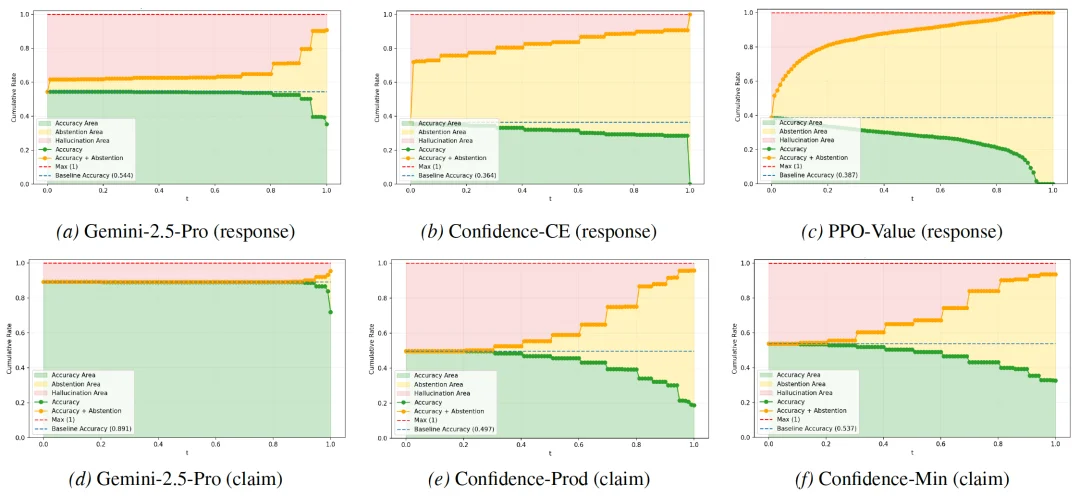
图4:在不同风险阈值下的准确率、拒绝率和幻觉率变化曲线。绿色区域代表准确率,黄色区域代表拒绝率,红色区域代表幻觉率。随着风险阈值t的增加,模型逐渐从「应试者模式」过渡到「完全诚实模式」。
研究团队设计的系统满足行为校准的四个目标:

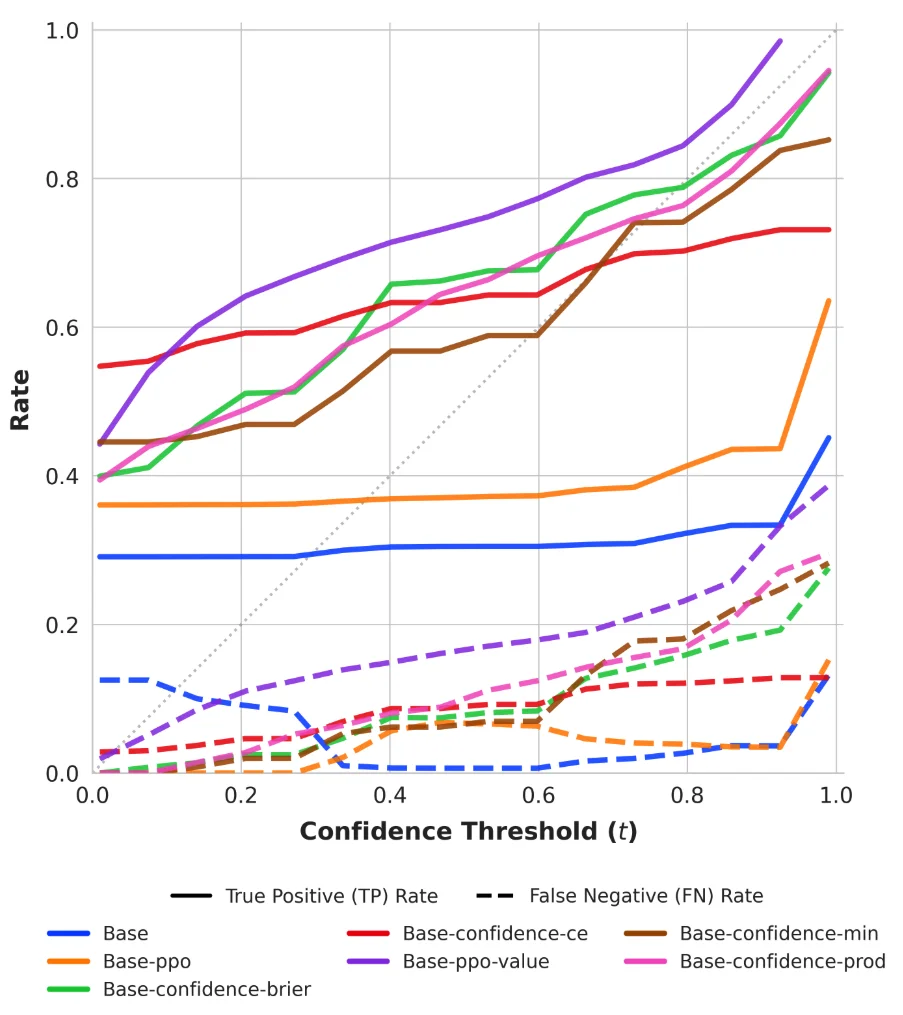
图5:行为校准的True Positive(实线)和False Negative(虚线)。TP曲线应位于对角线上方,FN曲线应位于对角线下方。Base和Base-ppo是基线
跨领域泛化:元技能的可迁移性
为了验证该方法训练出的元认知能力是否具有可迁移性,研究团队将在数学数据上训练的模型直接在 SimpleQA(具有挑战性的长尾事实知识基准)上进行零样本评估。
结果显示,方法的 SNR 显著优于基础指令模型,超越了大多数评估的前沿模型,与包括 Claude-Sonnet-4.5 和 GPT-5 在内的最强前沿模型相当。由于零样本评估的设定,在模型缺乏基础知识的全新领域上,行为校准被有效迁移,这说明行为校准是一种与预测准确率解耦的技能。
该研究还带来了一些理论洞察:
1. 幻觉缓解与事实准确率是两种不同的能力。研究团队观察到,对于某些前沿模型而言,准确率与幻觉率或置信度校准之间并没有正相关关系。GPT 系列模型的优势更多体现在控制幻觉的能力上,而不仅是准确率的优势。
2. 小模型也能实现与大模型相当的置信度校准。实现有效「校准」所需的计算资源远低于追求绝对准确率所需的资源。反过来说,某些大模型的言语化置信度并不能准确反映其实际表现。
3. 行为校准是一种可学习的属性,可以通过训练得到改善。这与此前认为幻觉是 LLM 不可避免的内置特性的观点形成了对比。
文章来自于“机器之心”,作者 “吴嘉赟”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
