# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上线一年后,Seede AI 推出了他们的海外版产品 Veeso AI,主打把原始素材转化成可交付的设计稿。
与 Lovart 这种面向懂设计的人群的产品相比,Seede AI 更容易上手,面对的人群也更大众一些,比如一家书店想做个小活动的海报、一家二线城市的医院想张贴个宣传告示、或者是一家健身房想在公众号里放一张会员招募活动海报等等,他们可以不用去研究配色、搭配,只需要找到一张他们喜欢的模版,放上自己的原素材,2 到 3 次对话,一张可交付的设计稿就出来了。
门槛足够低,但因为使用了各家 SOTA 模型,上限也足够好。
创始人 Longyi 早年在美团负责系统架构的工作,甚至从零手搓了一个美团内部版的「Vercel」。后来加入了创业公司 Dora AI——「面向建站领域的 Figma」,在 GPT-4 出来后意识到,传统的无代码架构,不彻底转向 AI-Native 是没救的。
这才有了现在的 Seede AI,单人 2 个月开发出产品的雏形、依靠微信转账验证了产品的 PMF。
有技术有洞察,产品有用户,并且已经跑通了 PMF,一步一步朝着更大的目标前进。
也许 FOMO,但目标很坚定。「设计工具的本质是帮人类创作,而 Seede 最终想做的是帮人类理解 Agent 产出的内容。」
人类理解世界的方式是视觉。当 Agent 成为信息的生产者,谁来帮人类『看懂』这些信息?Seede AI 想做这个尝试。
在海外版产品上线之际,我们跟 Longyi 聊了聊,想知道一款面向大众的 AI 设计产品,应该怎么做,又打算如何走。
产品官网:https://seede.ai
Founder Park:介绍下过往的创业经历?为什么决定出来创业?
Longyi:我的经历相对比较特别。大二就直接出来实习了,一开始在百词斩和掘金实习,发现实战学到的东西远比学校多,期间自己做的一个开源项目攒了一万六千多 Star,大四我就索性退学了。在得到一个刚孵化的业务里历练过之后,想去更大的平台看看,于是 2017 年我加入了美团。
在美团的四年(2017-2021),是我在底层架构和复杂系统上真正脱胎换骨的阶段。当时我负责团队的「扫码支付」业务,做架构设计不仅要扛住千万量级的并发,还要解决真实场景里的痛点——比如很多用户在网络环境不好的时候打开页面慢,我们就专门定制了一套缓存加速方案。
到了 18 年,Serverless 理念开始进入实用化阶段。我发现我们的前端团队在做业务时,很多逻辑其实放在服务端更好,但如果让前端去写 Node.js、Python 或 Java,那一整套运维部署又超级麻烦。为了解决这个痛点,我花了几个月时间,从零手搓了一个美团内部版的「Vercel」。这段经历让我不仅在复杂前端架构上有了沉淀,还深度切入了后端分布式计算领域。到 21 年,我觉得在大厂能做的挑战我都做过了,开始渴望真正的创业。
21 年刚好有一个绝佳的机会,我作为前五号核心成员加入了出海创企 Dora AI。最初,我们花了一年半时间死磕了一个「面向建站领域的 Figma」,产品上线后顺利积累了五六十万用户。但到了 22 年底 ChatGPT 爆发,团队意识到:生成式 AI 绝对会颠覆现有的无代码产品形态。我们迅速在 23 年转向 AI 化,靠着「一句话提示词生成网站」的超前理念,直接拿下了 Product Hunt 月榜第一,在 X 等平台彻底出圈,几个月内引爆了近 100 万新增用户。
但那波爆发背后,也让我看清了技术路线的局限。当时的基模能力(只有 GPT-4)还不足以支撑真正的 AI-Native,我们只能靠硬核工程去弥补——利用 Diffusion 生成设计稿,再手搓复杂的 AI Pipeline,串联 YOLO、SAM 等多个模型,花了六七个月才勉强把生成的丰富内容还原到无代码编辑器中。虽然效果不错,也有人付费,但我发现,只要底层依然是传统的「无代码架构」,用户后续的人工操作门槛就依然很高,这是一种范式上的落后。
所以我意识到,不彻底转向 AI-Native 是没救的。24 年下半年,我决定出来自己做,完全围绕 AI 生成能力设计了 Seede AI。
Founder Park:选择出来单干,为什么会选择设计或者海报设计方向?
Longyi:我一直很关注这个领域。从大厂出来做的上一个产品,就是因为对「所见即所得」的设计工具非常感兴趣。很早我就开始用 PS、Canva、Figma、Sketch 了,虽然不是专业设计师,但对这类产品天然感兴趣,这类产品通过简单的拖拉拽,能让小白完成设计作品。
24 年我看到,传统工具似乎都可以通过 AI 变得更易用、门槛更低,就考虑出来做。当时我也评估过,有了之前的架构经验结合 AI,稍微努力一下,两三个月就能搭出来 MVP,可以快速测试有没有人买单。走了一个相对短的研发周期,尽量快地拿到反馈。后来拿到了正反馈,所以就在持续做。
Founder Park:初期阶段怎么验证 PMF 的?
Longyi:借助 Cursor,加上过去在美团积累的架构底子,Dora 十个人花了一年半,Seede 我一个人花两三个月就做出来了。因为产品极度依赖大模型,我非常看重商业化验证,早期甚至没写支付系统,就直接贴了个人微信,谁要买积分就加我详聊。其实那时候并不是想收钱,只是想看看究竟哪些人在用、愿意付钱。愿意付钱才会扫我,正好能跟他聊聊,然后送积分。到了 3 月份左右,每天都有不少人加我,看到挺强的付费信号,我才去把公司和支付系统搞出来。
当然,Seede 的工程成本还是高的,持续迭代了快一年,工程细节非常多。另外,要打造面向大众的产品,交互细节也多,比如「复制粘贴」该出现在哪儿,都有讲究。
Founder Park:如果用两句话来介绍产品,会怎么说?
Longyi:Seede AI 可以把你的想法变成可交付的设计稿。你提一个设计需求,Seede 就会在画布中生成一个包含版式、文字、图像的可编辑设计。并且我们可以保证,这个作品可以直接用于交付发布、投放或者打印。
Founder Park:这里说的「设计稿」是指?比如长海报之类的?
Longyi:不只是海报。「可交付」这个点上,我们和普通文生图有区别。
我们内部的定义是,首先尺寸正确,边距、字体都是 OK 的;其次,信息清晰可读,我们通过 AI 的 Coding 能力,把层级、对比等专业排版知识应用进去,让内容组织得层次清晰;另外,用户会有品牌诉求,比如颜色、Logo 位置,这些都可以在结构化设计稿里有很好的呈现。这些都通过 AI 搞定,最后可以直接导出使用。
这个过程减掉了一个很重要的环节,就是设计代理。比如原来得依赖专业设计师,或者去打印店、淘宝店反复沟通,等很长时间。但 Seede 可以完成整个设计闭环,从提需求到拿结果,进度自己把控。很多用户反馈,用了产品后发现,原来找的美工反复说都听不懂,但 AI 能很好地理解他的意思。

Founder Park:怎么定义「可交付」?
Longyi:第一,很多人用 Midjourney 做图,会发现生成的图整体不错,但关键信息漏掉了,或者文字模糊。如果海报里的关键信息不可控、改不对,他就觉得发不出去,不能用。
第二,交付设计稿不光是「抽卡」生成一张图,还要能沿着同一种风格把东西都搞出来。举个例子,会议嘉宾的名牌,如果用 Nano Banana 来做,每个嘉宾的图除了名字不一样,其他地方可能也变了。但是对于我们的结构化设计,这一点就很有优势。
Founder Park:是不是意味着「可交付」也需要提供固定、可复用的能力?就像刚才说的嘉宾图,我可能要做 30 个,每次都得保证它们是一样的,同一个设计稿要频繁来用。
Longyi:对。重复使用是一个很重要的点。另外就是系列图,虽然每一个不一样,但要延续某种关键的风格或版式。比如做会议海报,页脚得统一。这种延续性很关键。一个良好的结构,就是延续多种产物、对模型非常友好的上下文。
Founder Park:以前做产品,图片生成模型连文字都生成不好,所以代码生成是更好的选择。但 Nano Banana 出现之后,你还会这么想吗?
Longyi:我们很早也接入了 Nano Banana。它的能力确实让人兴奋,但恰恰是它的出现,让我们更清楚地看到:端到端生成和代码结构化生成,解决的是两个完全不同的问题。
端到端生成的魅力在于「快」——你给一句话,它给你一张图。但代价是「黑盒」——你拿到的是像素,是素材,不是结构。想改个标题?想换个颜色?重新生成。你对结果没有掌控权。
而代码生成的本质,是让模型「理解视觉」而不是「模仿视觉」。当模型用代码回应你的需求时,它在说:「我理解了什么是标题、什么是重点、什么是视觉引导——现在我把我的理解写成结构,你可以检查、修改。」
所以我们的定位很清楚:Nano Banana 是非常强的端到端素材生成器,负责底图、氛围、视觉冲击力。而 Seede 是那个「容器」——把 Nano Banana 生成的素材,与标题、价格、结构化信息组织在一起,变成一个用户真正可编辑、可交付的设计。
端到端生成的是「素材」,代码生成的是「方案」。前者交付像素,后者交付掌控权。
至于这个容器里,有多少来自端到端模型、多少来自代码,对用户不重要。我们只关心一件事:帮小白用户或没时间做设计的人,做出专业级的可交付设计。
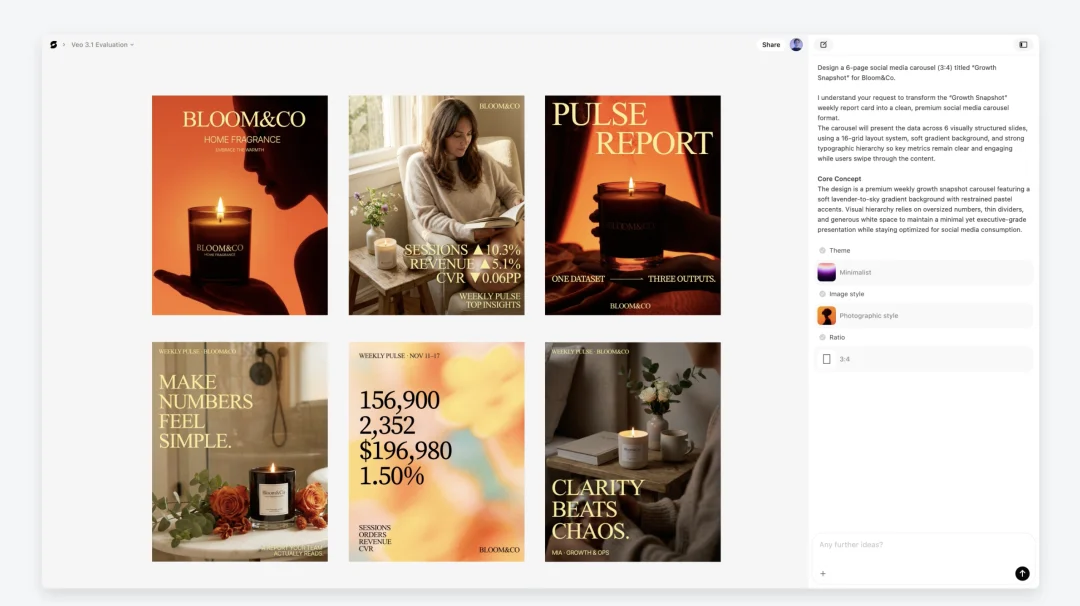
Founder Park:不管怎么样,最终这些都是你们能力的一部分。下面的素材生成能力越强,我给用户的交付就越好。你们赌的不是模型本身,就像 ChatGPT 在创作和代码上都很强,但最终出圈的产品,还是要在这个模型基础上做工程化和产品包装。
Longyi:对。模型是引擎,我们是产品经理——同样是电动机加螺旋桨,可以造电风扇,也可以造电动飞机,取决于你理解用户的真实需求。
Token 成本意味着 AI 产品的成本结构和传统互联网完全不一样。
传统产品用户用多少次,边际成本都趋近于零。但 AI 产品不一样——每一次生成都在消耗真金白银。我们非常关注 Token Efficiency,不只是技术优化,而是商业模式的起点。
Seede 用结构化数据生成视觉,同样的算力成本,信息密度是端到端生成的 10 倍以上。当你要规模化服务大众用户时,这个差距会从「技术优势」变成「竞争优势」。
再说一个观察:大众用户很少直接用大厂的第一方产品——因为大厂在做模型的「说明书」,而不是用户的「工具」。NotebookLM 这种特例太少了。
AI 应用的渗透才刚刚开始。最近很多尝试过 OpenClaw 的用户就是 AI 先行者,有很多吐槽「养不起」。这个阶段,我们要做的不是跟模型赛跑,而是用模型的能力,去高效率服务那些还没被真正服务好的大众用户。
Founder Park:你们当时觉得产品的竞品是谁?现在呢?
Longyi:如果一定要找一个符号来类比,可能是 Canva——不是因为我们想做同样的东西,而是因为它在「让普通人能做设计」这件事上,建立了一个时代的认知。我们思考的维度在变。
Canva 的伟大之处在于「模板化设计」——用专业人士沉淀的模板,让小白用户也能做设计。但模板的本质是静态的上下文预置,匹配度最多 60-70%。
而 AI 让上下文流动起来。当用户说清场景和诉求,AI 能像设计师一样思考,把匹配度提到 90% 以上。
但更重要的是,这个变化指向一个更大的未来:Canva 时代是为「人类生产内容」设计的,AI 时代是为「Agent 生产、人类消费」设计的。
今天,越来越多信息来自 Agent 而非人手。谁来把它们变好看?谁来理解它们要出现在什么场景?
这就是 Seede 要做的事——不是又一个工具,而是一个理解场景的界面层。一端接入 Agent 输出的任何信息,一端输出人类可本能理解的视觉语言。
Canva 拥有巨大的模板数量,但是我们在探索场景理解。它服务「人找模板」的时代,我们服务「Agent 生成、场景呈现」的时代。
生成式模式替代传统模板,不是工具的迭代,是时代的更替。
Founder Park:模板之所以流行,是因为用户的审美不够或者表达能力不够。审美不够可能是 AI 可以解决的,但表达不够这个问题,如果没有模板了,这个问题解决了吗?
Longyi:这里的关键是理解一件事:在 AI 时代,「模板」的定义变了。
过去,模板是骨架——一个固定的版式,你往里填内容。它的确解决了表达不够的问题,因为用户只需要「找到对的」然后「填空」。
但在 AI 时代,上下文即模板。
第一,AI 本身有足够强的设计语料。设计领域数据丰富,即使用户表达得模糊,模型也能凭借泛化能力匹配出超出预期的结果——你给个大概方向,它比你更懂怎么落地。
第二,很多用户确实没想清楚自己要什么。所以我们会延续「模板」这个概念,因为这是当前这一代人的基础认知。但这里的模板不再是固定骨架,而是可 Remix 的上下文。
比如一个餐厅老板看到竞对的风格,可以拍下来发给 AI:「参考这个,帮我生成我家的。」他不需要描述「什么是工业风、什么是暖色调」,一张图就是他的模板。
我们也在鼓励用户分享作品,沉淀的不是传统模板,而是设计过程中的关键上下文——就像是 Skills。我们认为所有东西都可以 Remix:你想要麦当劳的结构,配奈雪的色调,AI 能理解并组合。
所以模板没有消失,它从固定的版式进化成了流动的上下文。从「人找模板」变成「AI 理解模板」。
Founder Park:如果 Canva 做 AI,对你们冲击大吗?
Longyi:冲击肯定会有。但如果 Canva 重构底层架构来做 AI,反而证明我们的方向是对的。
但更根本的区别是:我们不是「加了 AI 的设计工具」,而是 Agent to Human 时代的视觉界面。
Canva 再怎么变,核心依然是「帮人做设计」。而 Seede 是一个界面层——一端连接 Agent 输出的信息,一端输出人类可读的视觉语言。当未来内容由 Agent 生产、由人类消费,中间需要这层「呈现层」。这是两个时代的区别。
回到竞争:设计领域足够分散,巨头不可能全面垄断。我们的策略是瞄准具体场景,用用户反馈循环打磨产品——观察高频需求,深挖真实痛点,让用户愿意付费、愿意反馈,认知就越滚越深。
只要这个循环在,我们就能从小到大。等巨头转过弯来,我们已经跑远了。
未来 Seede 可以不只是图文生成产品。当代码描述的如果是内容结构,那它其实可以被渲染成任意形态:图、H5、视频、应用……当模型生成多模态内容的速度不断加快,Seede 就能支持实时、可交互的内容生成,而这已经是非常可见的未来了。
Founder Park:Canva 过往的数据积累没用吗?范式转换后,在旧范式下收集的数据,对于做一个 AI-Native 产品帮助没那么大?
Longyi:对,产品架构不一样。一个是产品优化循环,一个是数据优化循环。数据这部分确实不行。用户选哪个模板、填什么内容,可能只有一点点用,但这数据怎么和模型能力做对齐?这里有很大 gap。而我们积累的数据是模型生成的结果、用户对结果做了微调得到的最终产物。这部分数据对模型来说,是高质量的增量数据。
Founder Park:举个极端的例子,如果 Canva 或者 PS 照抄你们的产品,你觉得威胁大吗?
Longyi:巨头本来就有这类产品,Canva 的 Magic Studio 也迭代一两次了。但 AI-Native 产品有一个关键点,巨头的成本模型不对齐。传统 SaaS 和 AI-Native 的成本模型完全不同。以 Canva 的营收规模,很难把 AI 产品作为核心业务放出来。它原来只收 10 美金订阅费,绝对不希望大家都用 AI,因为这会导致毛利率从 95% 掉到 50% 甚至更低,营收受损太严重。巨头要等 AI 产品能占到核心营收的大头,才会给予同等量级的定位。他们也在内部不断做尝试,比如 Canva 就招募了一个在 AI Coding 设计方向很牛的人。
至于其他公司,其实已经有产品在像素级抄袭我们了。连我没想明白的核心逻辑、UI 结构全抄了一遍,甚至连我想砍掉的功能都抄过去了。结果他刚抄完,我们新版本迭代就把那些部分砍掉了。
Founder Park:换个角度,如果你站在 Canva 的角度,你会怎么选?
Longyi:我当然是等一个足够亮眼的新产品跑起来后再去做,让他们先探索,到一定量级再去收购。
Founder Park:内部转型的压力确实比收购大多了。
Longyi:对。比如 Canva 市值两三百亿美金,如果有公司很快做到四五十亿,可能就像 Meta 收购 Instagram,内部孵化不一定成,不如直接买。对于 Adobe,Adobe 在狙击 Figma 和 Canva 上做了很多尝试。Figma 火了之后,Adobe 也很快跟进,出了他们的产品叫 Adobe XD,做 UI 原型设计,价格上更像 Figma。但他们做的那个差距就很尴尬,后来好像已经直接废弃了,所以后来才去收购 Figma,但又被反垄断调查了。
Founder Park:用户画像大概是什么样的?Seede 的人群更大众,离 AI 重度用户远一些?
Longyi:我们关注的用户主要是内容创作者、小商家运营、海外电商,还有自媒体或创业者。目前 90% 收入来自 C 端。主要场景是社交媒体、广告营销以及活动海报。
心智上,我们的用户一方面是接受新鲜事物的年轻人,另一波是中年人,门槛足够低让他们也能做。用户中位数在 30 岁左右。
还有一部分学生,学生群体跟 Canva 一样,对我们的未来发展很有帮助,但对商业化帮助有限,因为同样的产品,让学生付钱比较困难。国内大学生生活费有限,如果每月收 99,我大概率也不会买。未来我们也计划针对教育用户提供更多免费额度。
Founder Park:长图、海报、社媒图片的比例大概是多少?
Longyi:长图挺多,占 40% 左右;活动海报和社媒各占 20% 多;PPT 最近用的人也挺多,占比 10%。剩下就是易拉宝、展板这种线下物料。
Founder Park:画布形态对于你们的目标用户有门槛吗?
Longyi:我觉得现在的设计不算有门槛。为什么做画布?因为设计领域需要一个东西承载设计空间。画布是基础,不一定需要无限画布。有了画布,你才能放大看细节,缩小看总体感觉。所以一个可以缩放的空间是必须的。
无限画布是在这个基础上组织堆叠更多元素。但考虑到大多数用户没用过无限画布,我们早期虽然引擎是无限的,但只提供简单的垂直布局,通过上下滑动来交互,这套模式仍然是我们默认的模式。当然,也有不少熟练用户在用无限画布模式,方便组织复杂的多页内容。
无限画布其实是触控友好的,但我们 70% 的用户是 Windows 键鼠用户,所以我们现在让键盘鼠标也可以通过上下滑动轻松控制。对于有经验的用户,我们会推荐他用无限画布。
另外一个有意思的点是,用 iPad 做设计的用户也有,我们在纯触控设备上也会做一些优化。
Founder Park:默认有限画布,熟练后轻易切换。
Longyi:对。画布是所有视觉设计类的基础载体。我们现在也在把画布和对话这两部分进一步融合,把「所见即所得」的理念进一步 AI-Native 化。比如,传统设计工具的目标是让你选中元素,去调整属性。我们的思路是,你选中元素,甚至不用选中,通过 AI 对话的方式,它去帮你调整属性。
比如一些专业设计师能把字体调得艺术风格非常好,但普通用户可能就只会加粗、换颜色,调不出来好效果。但 AI 可以理解所有的设计属性定义,根据用户的需求组合出一个良好的设计。比如用户说「我这想要一个火辣的标题」,那它可能会配出来一个比较红、带金色火焰风格之类的组合。
Founder Park:怎么判定用户生成的是「好设计」?
Longyi:其实现在整体还非常主观。说起来有点好笑,有个马来西亚华裔用户用我们产品跟我们交流,说「你们的产品审美很好,非常符合我们这种马来西亚华人的审美和用户习惯」。其实我们感觉并没有做什么特别的设定,但用起来就是感觉挺符合华人审美的。这可能是模型和我们自己团队审美的一个交叉点。
我们的思路是,在用户没有提供风格诉求的情况下,尽量让用户采用到我们精心匹配的设计。我们团队有两个核心部分,一个是审美,另一个是产品工程。所以我们希望用户在没有明确风格预期的情况下,会使用到我们预设的一些比较好的设计。未来我们把用户社区引入进来,可能在不同的地区、不同的场景,设计会更加本地化。但我们希望,我们平台至少都要比直接使用基模有更多一些风格倾向。这是一方面是我们的审美的独特性,另一方面也是和基模保持一定的审美偏差。如果同样一段提示词,在 Gemini 生成和在 Seede 生成一模一样,那我们就没有特别多独特价值了。
Founder Park:你们付费流程是怎么优化的,可以详细说说吗?
Longyi:我们做得其实很简单,就是观测用户从进入官网、注册、得到第一个设计作品、到最终导出的全链路。早期版本基准就比较高,因为 AI 减掉了上一代产品的搜索填充流程。但我们发现如果把上手门槛进一步降低,整体转化率还能提高。
核心优化几个点:第一步是引导用户知道这个产品能干什么,我们有场景引导,让用户快速得到第一印象。在产品层面我们只提供相对简单的定制,更多是利用模型的 Coding 能力,组织好 Context 让它生成对应领域的设计。第二步是优化首次生成效果,我们内部叫 One-shot——如果生成出来非常丑或者画面混乱,用户直接就走了。
第三是把免费试用从 5 积分提高到了 10 积分。5 积分只能用高级模型生成两次,10 积分能让他用高级模型生成 5 次以上,对产品的理解会更深。
如果进一步把付费墙做好,付费率应该还会更高。但是我不希望让 Seede 这个产品过于商业化,现在还在打磨阶段,不希望在商业化上那么激进。因为我们是积分制,不同的设计、素材用量消耗不同。有的用户用得猛,其实是微亏的。
Founder Park:现阶段对于国内产品,你会看重哪些指标?
Longyi:核心关注付费、激活和留存。留存的话,我们现在的周度和月度留存,在同类工具里是比较顶尖的。
我们有几个关键阶段的数据:从生成到导出的流程,包括观测导出率、导出场景、分辨率和格式。另外我们会算每天新增用户的 ARPU,去看付费意愿。还有一个很关键的指标是错误率。
Founder Park:错误率怎么判定?是用户点了「不喜欢」,还是系统出错了?
Longyi:「不喜欢」这个设计我们早期有,后来砍掉了。之前跟模型团队交流后发现,像豆包这种 Chatbot,用户点的「Yes/No」的数据噪声太大,没有那么大用处。我们更关注实际的交互。有的设计不错,用户点「不满意」只是个人审美问题。所以我们关注更真实的「导出」行为。
单页面项目至少得导出一次,我们才知道他可能是真的要采用。复杂项目他会反复做小调整再导出,我们能从这种数据节奏观测满意度。还有基础交互,比如把某些东西反复拖来拖去,我们能推测出他对 AI 结果里哪些地方觉得不够好。目前我们 90% 的精力都在「One-shot」的优化阶段。
Founder Park:One-shot 的优化具体做了哪些事?
Longyi:我们在这件事上投入是最多的,而且持续做了很久,主要拆分成三部分。
第一,最重要的是模型基础。所有 AI 产品 80% 的效果都归功于模型,没有好模型,AI-Native 产品就是空中楼阁。
第二,剩下的部分里,60% 投入在 Context Engineering 上。首先得保证代码正确,Agent 输出代码没有致命错误的概率,我们内部优化后在 99.5% 到 99.8% 左右,当然这也取决于不同模型。
如果它输出的东西不能被正确地运行,用户看到的就是空白。所以我们做了几件事:在 Context 层做一些 Badcase 的验证,通过评估知道哪些模型容易犯某些可以被修复的小错误,然后让它避免出现。解决不了的部分,我们会在模型生成产物后,用算法去做代码修复。如果算法也搞不定,比如一些很致命的语法错误,我们又会引入一个专门做 Hotfix 的 Agent,去做异常代码的检测和修复。我们发现,如果一个模型老犯某个错误,你让它自己去修,大概率也修不好,所以这里也得搞成混合模型的模式。这就基本解决了稳定性。
第三,如何让它生成的东西好看。我们让设计师按场景去做了一个内部叫「审美数据库」的东西,把很多好看的设计做了拆解,把一些通用的部分,比如版式设计、元素风格、配图风格等维护成了一个库。最近我们又在参考像 Claude 的模式,把这些进一步抽象成了 Agent 在设计层面的 Skill。也就是说,一个好的模型可能基础是 60 分,但叠加了我们由设计师精心组织的上下文或者 Skill 之后,整个设计能力能从 60 分提升到 80 分。
Founder Park:上下文工程的核心包括哪些?
Longyi:我们在设计 Memory 概念,包含用户记忆和项目记忆。通过多次交互,积累用户的审美倾向。因为我们是无限画布,也能累积到项目层级的风格。
不过,用户的 Memory 一直都还没有上线,我们在海外的新产品 Veeso 上想更好地做一次架构升级,顺带就会把这些加上。Veeso 上的 Context 和 Memory,除了项目级和用户级的 Memory,我们还全新规划了一个自研的 Agent。
Agent 运行在浏览器中,面向的是我们的设计工具,我们自己全新设计了一个基于文件系统的 Agent Loop,并且为它设计了很多面向设计任务领域的 API,让 Agent 能够充分理解到它是在一个无限画布、一个视觉化的编辑器里工作。这和很多其他领域的 Agent 区别还挺大的。
整体架构上,我们参考了 Claude Code、OpenClaw 的概念,只不过是让它运行在浏览器和编辑器中。上下文最核心的部分,还是我们的设计师调教出来的设计 Skill。至少包含两部分,一部分是它在这个场景的工作模式,另一部分是一些拆解下来的风格。我们没有用像 RAG 那种生硬的方式,而是类似 Agentic Search 的模式,让 Agent 根据用户的意图,在我们的设计审美数据库里面,更加智能化地去做语义搜索和匹配,拿到相关的 Skill,甚至可以做混合。比如做一个会展活动的易拉宝,那它得知道什么是「会展活动」,什么是「易拉宝」,有了这些 Skill 之后才能输出一个专用于会展活动的、专业的科技风格的易拉宝。
Founder Park:你们会对基模做强化学习吗?还是核心在工程能力?
Longyi:还是在 Context Engineering 上。这样不管哪个模型只要能力强,随时可以拿来用。我们现在应该更多做「模型解耦」,不去基于某个模型做定义、做 fine-tune。我们这种场景,用纯外挂式的 Context 就能解决。
Founder Park:也就是说你们不会被任意一个模型绑定,只要有最强的,随时可以拿来用。
Longyi:对,我们的上下文是跨模型共享的。
Founder Park:国内这边,你们前期增长主要来自哪些渠道?之后有什么调整?
Longyi:现在基本没做增长,主要靠自媒体和口碑。我们的策略是再打磨一下产品,等海外新产品 Veeso 发布后,再让 Seede 在国内做正常推广。
我们在 12 月才勉强做了第一次花钱的营销。市场团队去跑内容合作流程,找达人、谈内容、发视频、观测效果。投了 1.5 万预算,聊了十多个 KOC,效果非常好。我们走更真实的 KOC 路线,因为用户更偏传统渠道,可能对技术、对 AI 产品关注都不是那么多,反而是办公场景、电商运营、学生这些。算下来我们的 ROI 非常好,应该投了 1.5 万,新增了三四万的付费收入。
Founder Park:如果国内已经跑通 PMF 且毛利为正,为什么现阶段要去铺海外?
Longyi:做海外有个关键点,就是得尽早启动,产生初步声量,这个时间点非常关键。如果我现在专注国内做大半年再去做海外,这个时间差会让海外同类产品先触达关键传播节点,让大家先入为主。
我们产品有必要尽早面向海外。要进入主流用户市场,可能得花三四个月甚至更长时间去测试、找曝光渠道,所以得尽快搞定。
如果海外版能达到像国内 Seede AI 一样,每天都有大量用户实时反馈,那收入上会有巨大不同。同样的精力,在国内可能赚 10 万人民币,在海外可能是 10 万美金,甚至可能会更高,汇率和付费意愿都有区别。出于团队稳步发展考虑,把海外跑通是最高优先级。对于国内,我希望它良性发展,到今年年中,Seede 能通过营收覆盖国内研发团队的一部分支出。
Founder Park:在你的规划里,海外和国内产品在付费模式、设计上有大区别吗?
Longyi:是的。比如海外我们会切换成订阅制加 Usage-based 的增量模式,而不是简单的纯积分制。这样收入更稳定,高频用户体验也更好。国内很多高频用户也在问多久出包月或年费。另外在 Agent 架构这块,我们在新产品上做了新架构,不影响 Seede 已有用户的体验。等新架构跑得相对稳定,再放到国内的升级版本上。
它是全新的产品,可以放心大胆改造。可以认为海外版是全新的 2.0 版本,没有历史包袱。
Founder Park:如果有机会回到 2025 年初重新开始做 Seede,你会做出哪些不一样的决策吗?
Longyi:会。而且这个「如果」我最近确实想过很多次。
我可能会在工程上做好一定的基础之后,更早、更激进地去做一些市场的东西。作为技术出身的创始人,我的本能是把产品打磨到「足够完美」再推向市场。但这一年走过来,我们验证到一个非常亮眼的 PMF——用户不仅喜欢我们,而且愿意为「掌控权」付费,愿意为「生成即编辑」这种看似反直觉的体验买单。
如果重来一次,我会更早相信:当你的直觉告诉你这件事是对的,市场的反馈会比你的工程标准更早到来。
Founder Park:会尽快第一步就出海吗?
Longyi:有可能,可能会更加激进地去做出海。
现在回头看,视觉语言是没有国界的。我们做的「内容优先、设计随行」这件事,本质上是在解决一个全球性问题:当 Agent 开始大规模生成信息,人类怎么「看懂」这些信息?这个问题在中国存在,在美国、欧洲、东南亚同样存在。
因为人类理解世界的方式是视觉,所以抢占瞳孔的机会窗口是全球同步的。Seede 要做的就是面向全球用户。海外版 Veeso 的发布,就是我们对这个判断的回应。
Founder Park: 你希望 Seede 成为一个什么样的代名词?
Longyi:我希望我们是第一个面向 Agent to Human 时代的「场景化视觉界面」。
当 Agent 拥有世界上最聪明的大脑,把全世界的信息都挖出来、想清楚了,它最后是怎么给到你的?人类不读 JSON,不看向量——我们理解世界的方式是视觉。
Seede 不做另一个设计工具,而是一个界面层:一端接入 Agent 输出的任何信息,一端输出人类可本能理解的视觉语言。就像 GUI 是人与操作系统的界面,Seede 是人与 Agent 世界的界面。
今天我们能做一部分 Canva、Word、Excel 的事,因为信息本身就是多样的。但那些工具是为「人类生产内容」的时代设计的,Seede 是为「Agent 生产、人类消费」的新时代而生。
我希望未来人们提到「把信息变好看」的时候,想到的不是某个工具,而是一种格式、一种界面、一种本能——就像今天提到「把文字排整齐」会想到 Word。
我们有机会成为一个新的名词,或一个新的文档格式:帮助每个人美化手上的信息,无论它来自哪里,无论它是什么形态。
文章来自于“Founder Park”,作者 “Founder Park”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
