# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是袋鼠帝。
我最近做了一个挺有意思的实验。
我给AI发了一张图片,然后问了它一个问题:如果从别的角度看,这个东西会长什么样?
比如,从左边看,从右边看,从背面看,或者从下面往上看。
这些常规角度,其实现在很多AI都已经能做到了。
我又想到一个更极端的问题:如果不是这几个固定的方位,而是从360度任意角度去看呢?
换句话说,如果我们像绕着一辆车走一圈那样去观察一个物体,AI能不能准确推理出在每一个极其细微的机位下,它应该呈现出什么画面?而且,如果我们要让AI生成这些特定角度的画面,那个提示词该怎么写?
类似这样的情况:

这件事情并不简单,需要不断调整提示词,并反复抽卡。毕竟,AI接收到的输入只是一张扁平的二维图片,它没有厚度,没有背面的信息。
但没想到,现在已经有工具把这件事做成了,而且操作方式简单到离谱。
先给大家看个效果,下面这段黑神话悟空的角色展示视频,就是我用两张静态图片,只花了大概5分钟搞出来的。

不同角度的运镜,悟空头上的毛发、衣服的粗糙质感、盔甲的反光,甚至在做大动作时的肌肉张力,都很不错。
但生成视频我用的提示词只有非常简单的一句话:根据我的分镜图片,生成视频(BGM是导入剪映配的)。
这个效果之所以能这么简单实现,一个重要原因是AI现在可以从360度观察一个物体了。
就像是一个摄影师,可以按照你的要求,调整机位、改变焦距,从不同方向去拍照。
我给大家拆解一下这个视频的制作过程你就明白了
以前我们要展示一个IP角色或者模型,一般得靠建模师或者动画师一帧一帧地K关键帧。现在AI生视频火了,大家开始用AI跑视频。
但是,这里面有个坑:
你想用AI跑出那种带丝滑运镜,比如镜头从全景推到脸部特写,还要带点广角拉伸的视觉效果,你需要的提示词写出来绝对堪比一篇小作文。需要精准地描述推、拉、摇、移的轨迹。
对于我这种不懂专业摄影、运镜术语的视频小白来说,简直是折磨。
脑子里有画面,但手敲不出对应的词。如果你想改一下镜头轨迹,还得跟AI反复拉扯半天。
现在,我找到了一条邪修捷径。不需要那些复杂的运镜提示词
首先打开AI设计工具:Lovart
https://www.lovart.ai/
需要用到它的一个硬核功能:Multi-Angle(多角度)。
简单来说,就是把一张图,变成一个可以被多机位反复拍摄的立体场景。
接下来只要用 Lovart 的 多角度 功能配合 一键广角 或 一键特写 ,先批量生成一各种角度、镜头的分镜图片,然后再把这些图片打包丢给视频生成模型,直接首尾相连就成了。
第一步,我先找了一张纯黑背景的黑神话悟空标准站立照。

第二步,让它做各种大透视动作(科普一下大透视动作),这一步是为了让视频画面更有视觉冲击力。
为了方便达到这样种效果,我整理了一套大透视动作模版,可以直接用。
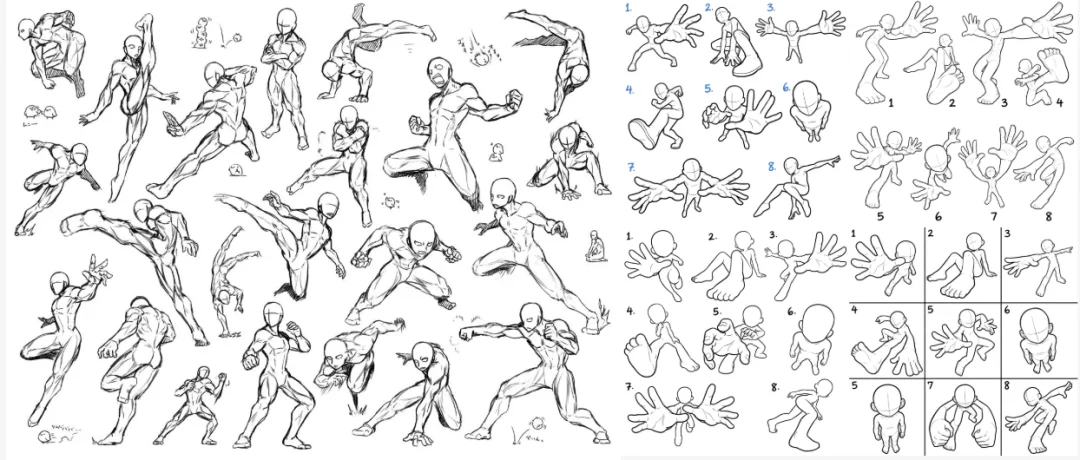
我直接在 Lovart 里调用了 NanoBanana Pro模型,输入提示词:
让附件1中的人物做附件2中的8个动作。








Lovart 一次性就甩给了我 8 张不同动作的高清大图,每张图的细节都拉满了,连手掌心的纹路都没糊。
第三步,也是最核心的一步:制作运镜分镜头。
我选中其中一张动作图,直接右键点击 多角度 功能。
画面上会弹出一个控制面板,它分两种模式,一种是主体模式,你可以直接用鼠标拖拽画面里的猴子,就像手里拿着一个手办在转动一样;另一种是摄像头模式,你可以像摄影师一样,调整虚拟摄像机的角度。

你可以选择推近给个脸部特写,也可以拉远开个广角。
只要找到你满意的角度,点一下生成,一张完美的新视角分镜图就出来了。
完全不需要去想提示词怎么写,而且在调整角度的时候非常直观,不用脑补

我用这种方法,迅速捏出了几个不同角度的站立效果图,以及几个大动作的不同视角图。
每一张图里,猴子的衣服纹路和毛发走向都保持着惊人的一致性,完全没有因为角度改变而崩坏。

最后,我把这组像连环画一样的分镜图扔给 Veo3.1(因为它对毛发和脸部的把控比较准)
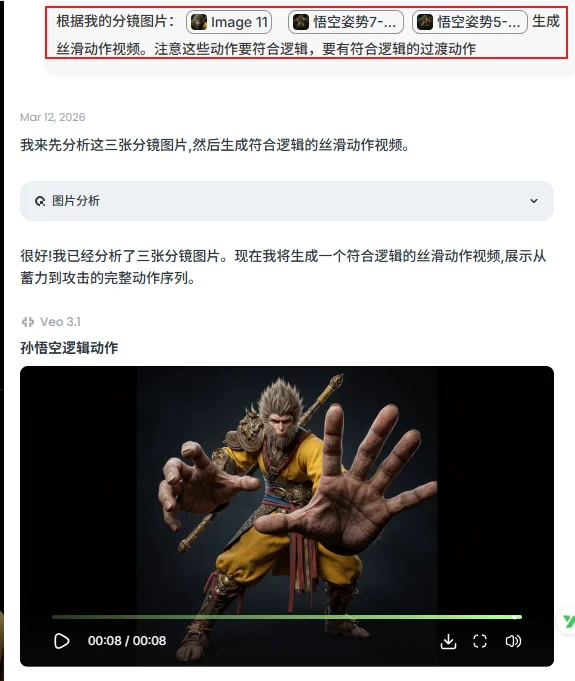
一段还不错的运镜就这么诞生了。全程没有写一行复杂的运镜提示词~
既然它能这么轻松地生成多视角图,那它肯定也能用在淘宝的商品图上,岂不是连请摄影师拍白底图的钱都省了?
我随便找了一张普通的鞋子照片,准备把它爆改成高级感拉满的淘宝多角度产品展示图。

为了让质感提上来,我先在 Lovart 里用了一段提示词
大意是让 AI 分析鞋子的几何形状、材质、品牌标志,然后应用极具商业感的光影逻辑
CORE OBJECTIVE: Generate a professional studio editorial presentation based strictly on the [ATTACHED_INPUT_IMAGE]. The AI must perform a deep visual analysis of the subject's geometry, material, and brand identity to apply consistent logic across all 7 panels.
Step 1: DYNAMIC VISION ANALYSIS (INTERNAL)
Identify Subject: Detect the primary object in the [ATTACHED_INPUT_IMAGE].
Brand Detection: Identify the logo or brand associated with the subject. If no logo is visible, use the subject's name as a high-end typographic emblem.
Material Logic Synthesis:
If Industrial/Tech: Precision reflections, sharp rim lights, geometric perfection.
If Liquid/Glass: Caustics, refraction, transparency, high-gloss.
If Organic/Living: Subsurface scattering, natural textures, soft diffused light.
If Textile/Fashion: Micro-fiber detail, fold dynamics, matte/satin sheen.
COMPOSITION STRUCTURE
A single, high-resolution seamless image.
Style: Ultra-high-end Studio Photography / Editorial / Commercial.
Consistency: The subject's color, wear-and-tear, and design details must remain 100% identical across all 7 views.
Technical: 8k resolution, ray-traced
把它修成了一张高级的摄影棚拍图。

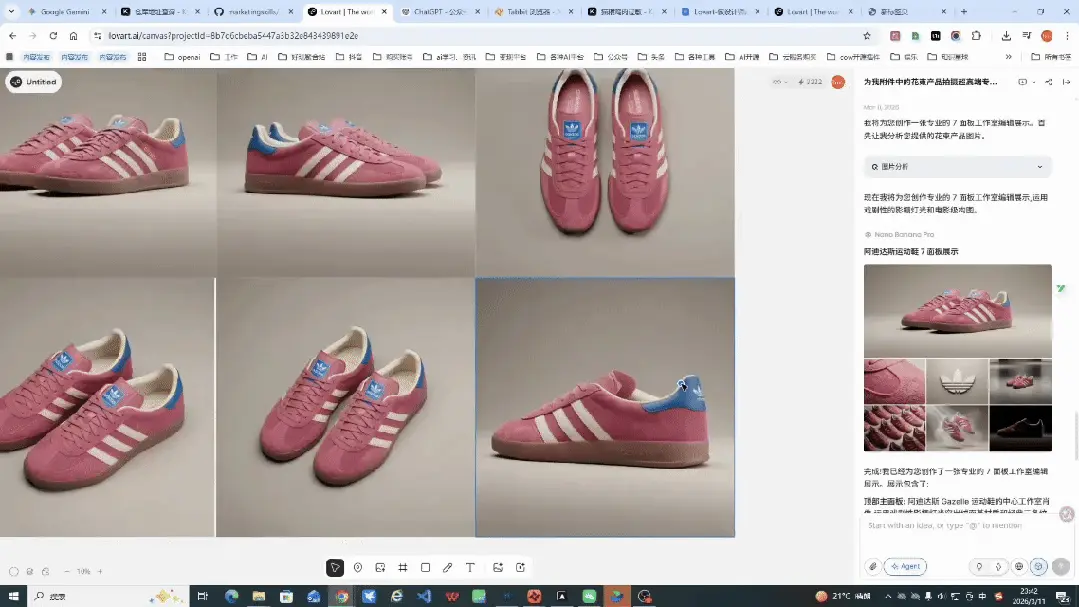
接着,重头戏来了。我选中修好的图,打开 多角度 功能。
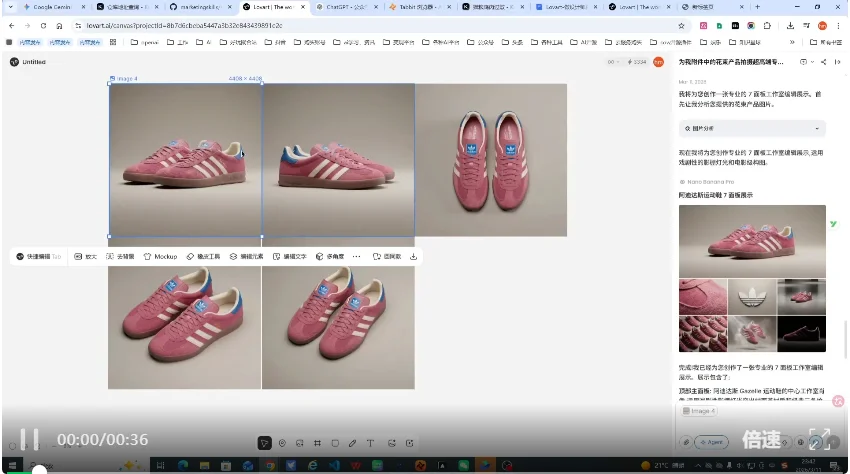
就像你在橱窗里看这双鞋一样,我只需要轻轻拖动鼠标参数滑块,鞋子的侧面、背面、俯视图、45度角展示图,就一张张蹦出来了。

生成的过程极其简单粗暴。而且出来的图片细节非常经得起推敲,放大看,鞋面麂皮材质都一清二楚。这要是直接拿去上架,谁能看出来这是一张图变出来的?
还可以拍一张自拍之后,调整各种不同角度的机位(而且非常方便,指哪打哪),一张照片瞬间变9宫格~

接下来再上上强度,如果换成带复杂光影的人物写真呢?
这其实很有挑战,因为角度一变,光打在脸上的阴影位置也必须跟着变,不然就会显得很假。
我找了一张摄影棚里拍的女生写真,脸上的明暗对比非常明显。

我用 多角度 功能生成了她微微侧脸和俯视的角度。
结果让我非常意外,AI 不仅正确重构了她的五官透视,甚至连那束打在鼻梁和颧骨上的光,也随着脸部的转动,非常自然地发生了偏移。
这说明 AI 不是在简单地贴图,它是真的理解了这个场景里的光源位置。

另外,Lovart 还有一个很nice的功能:Vectorize(矢量化)。
简单说,就是把普通的 PNG 或者 JPG 等图片,一键转换成 SVG 矢量图。
一些朋友可能不知道矢量图有什么用。
你平时看到的那些图,放大几倍就会出现马赛克一样的像素点。
而矢量图,无论你放大多少倍,边缘永远是极其平滑锐利的。
比如你看,这个龙虾的logo(你们猜猜看,哪一张是SVG图,哪一张是原图?)

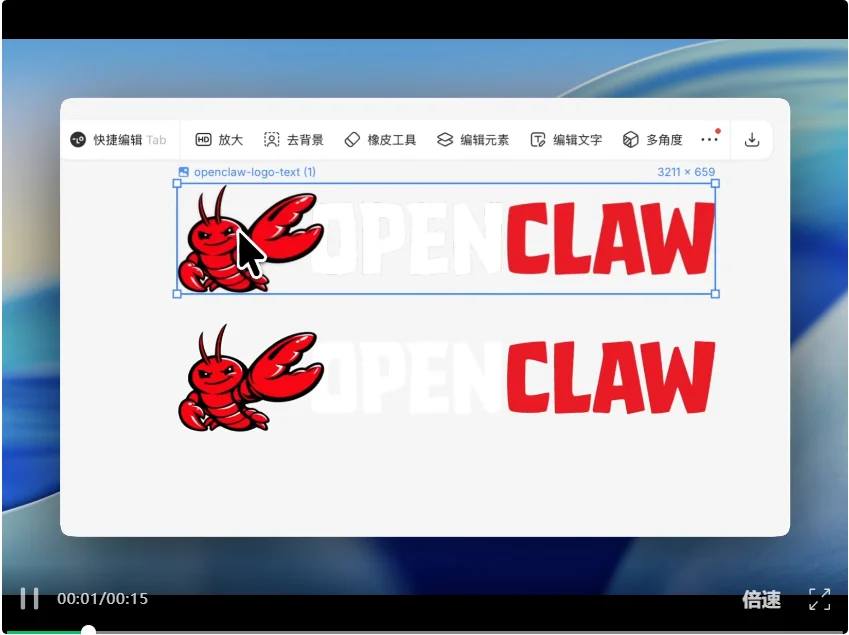
可以看到,原图的龙虾logo放大之后,明显不清晰了。
但是生成的SVG图,放大到同样的倍数,还是非常清晰,且边缘平滑锐利。


这对于做 Logo、做前端图标、做需要印刷的海报来说,是刚需。
如果你最近也在做电商设计、搞品牌视觉、画插画角色,或者是需要大量配图的社媒运营,可以去试试 Lovart
用下来,我觉得它最有意思的一点是:
一张图,不再只是"一张图"。
而是一整套设计素材的起点。
同时,这个过程中,我们也再也不用像以前一样,为了素材,反复抽卡了~
文章来自于“袋鼠帝AI客栈”,作者 “袋鼠帝”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
