# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自2025年10月Claude正式确立Agent Skills规范以来 ,Agent能力的边界正在被暴涨的脚本仓库迅速拓宽。截至2026年2月末,公开可用的Skills数量已突破28万大关 。回顾过去半年,Skills开发的火力几乎全集中在了“供给侧”,而且绝大多数由分散的第三方开发者维护。因此马上出现了三个连在一起的问题:用户看不清整个生态、平台难以治理质量、agent无法把分散skill组合成高质量多步工作流。

来自上海人工智能实验室的研究者认为,skill生态真正的价值,不在“单个skill替模型补一个洞”,而在“多个skill组合起来,完成单个skill做不到的任务”。如果没有明确的组合机制,生态只会越长越碎,最终大量skill处于可见但难用、已安装但不被调起的状态。这篇论文真正追问的,不是“有没有更多skill”,而是另一个更偏系统层的问题:当skill数量从几十个膨胀到几千、几万、几十万之后,agent到底还能不能把这些能力有效用起来?这篇论文给出的答案是:光把skills堆给agent没有用,真正缺的是一层中间层,用来做组织、检索、裁剪、编排和执行。这层中间层,就是AgentSkillOS。项目地址:https://github.com/ynulihao/AgentSkillOS

很多人第一眼会把AgentSkillOS误解成skill搜索引擎,或者某种skill市场的增强版。但研究者的定位并不是这样。论文里,AgentSkillOS被定义为一个两阶段框架:


因此,AgentSkillOS的本质是一个Skill-aware Orchestration Layer(技能感知编排层)。它接管了系统控制流,决定了本次I/O该读写哪些文件、哪个线程该被阻塞、哪几个脚本可以被并发拉起。

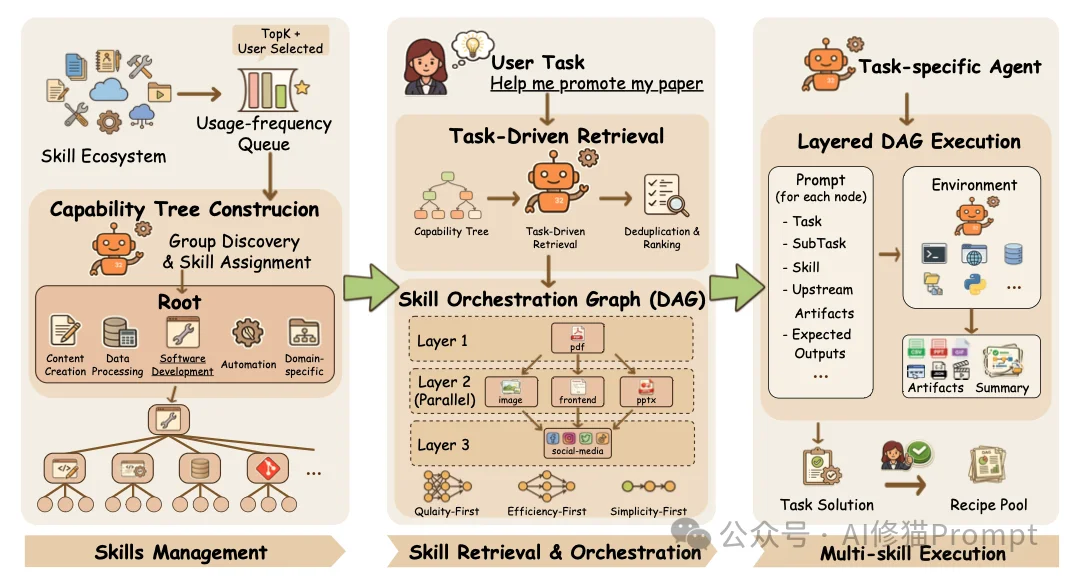


这个机制在工程上宣告了一个结论:处理海量生态的正确姿势,从来不是把几十万个API全塞进内存,而是通过“高频热缓存 + 长尾冷向量”的物理隔离,控制系统的可见空间。

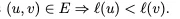

研究者指出,这种“树形引导 + 向量兜底”的混合检索引擎,能挖掘出字面上毫无关联、但在底层能力上高度互补的技能。例如“帮我推广这篇论文”,基于树状推理,它能召回PDF解析、数据可视化图表、以及前端网页生成脚本,而这些实体词根本不在用户的原始指令中。
面对筛选出的极简名单,系统提供三种强制图拓扑策略:
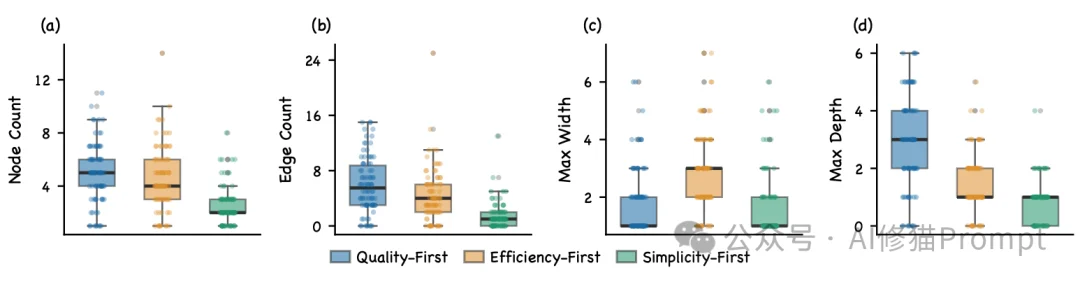
数据统计呈现出极度清晰的物理隔离特性:Quality-First产出的图总节点最多、最大深度(串联数)最深;Efficiency-First则大幅压扁了深度,同时创造了极高的最大宽度(单层并发峰值);Simplicity-First则是一张节点极少、连边高度稀疏的微型图。这证明系统并未在玩弄提示词文字游戏,而是真正在改变底层程序的执行路径。
在图确立后,LLM的上帝视角被系统剥夺。调度器严格依据层级约束运行:同层节点 asyncio.gather 并发触发,跨层节点 await 阻塞等待。 在拼装单个节点的Prompt时,系统做到了极度严谨的I/O隔离:向当前子LLM明确注入上游物理文件(Upstream Artifacts)的文件指针与使用规范,并硬性框定其下游预期的输出格式(Expected Outputs)。这意味着每个子进程都被锁在自己的沙盒里,彻底断绝了上下文污染的可能。
为了论证这套操作系统的可用性,研究者抛弃了传统基准测试中单一的文本问答(Pass/Fail),纯手工构建了一个涵盖30个重度工程任务的数据集,横跨数据计算、文档创建、动态视频、视觉设计和Web交互五个高难度域。
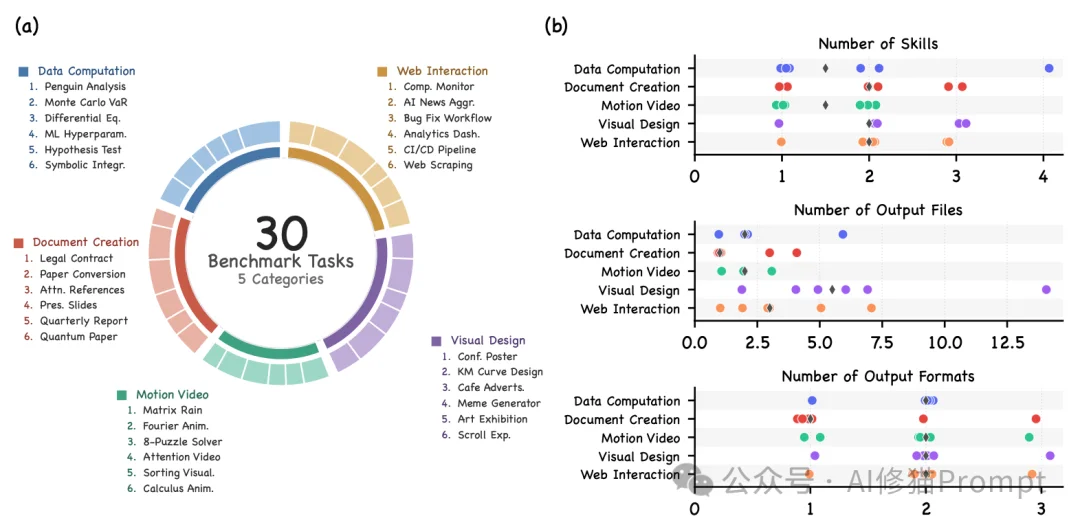
其核心评判标准极其严苛:必须交付能在现实商业环境中流转的纯物理文件格式(如排版严密的PDF、PPTX文件、具备交互逻辑的HTML源码,乃至高帧率的视频渲染原片)。
在评判系统产出时,研究者构建了一条全自动的多模态清洗流水线:将文档与幻灯片强制渲染为页面图像,HTML截取全屏快照,视频则通过脚本均匀抽取帧序列并提取时长与帧率元数据,最终统一封装给大模型裁判(LLM Judge)。
为了彻底消灭大模型评测中臭名昭著的“位置偏差(Position Bias)”,系统对每一组对抗强制执行交叉换位比较(先看A再看B,随后先看B再看A)。若两次判定偏好一致则录入系统;若结论产生冲突(每次都只偏向特定的物理位置),则判定为平局(Tie)。

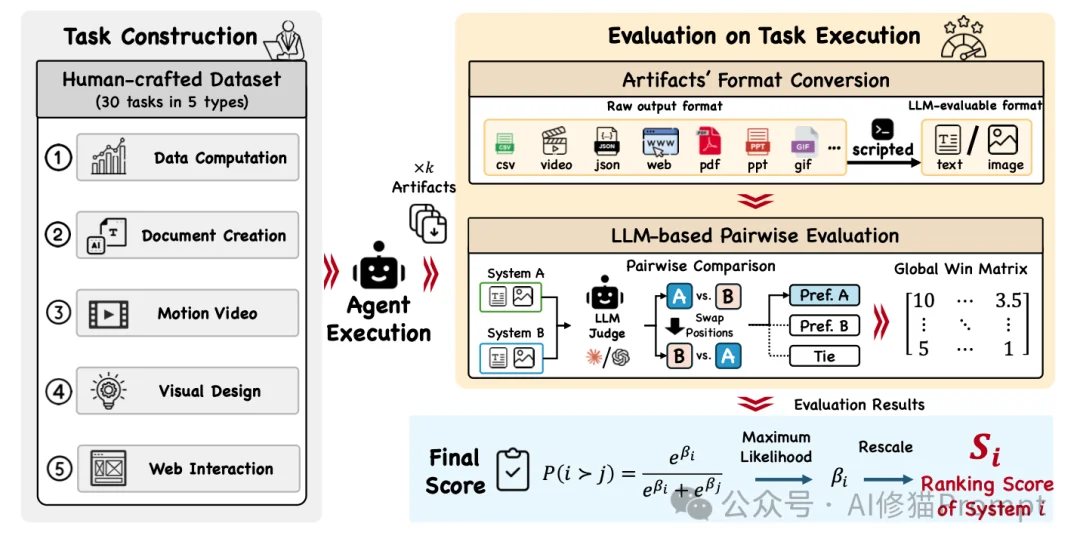

在200、1K、200K三种生态规模的极限拷问下,实验数据揭示了一个彻底颠覆直觉的工程铁律。
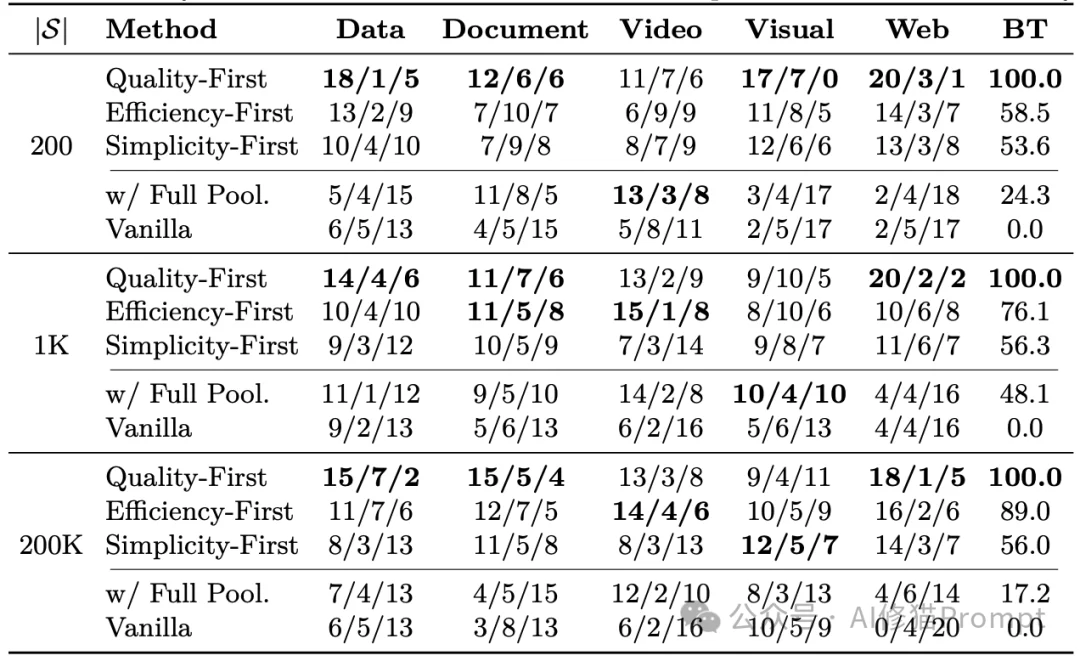
采用“质量优先”策略的AgentSkillOS在三种规模下毫无悬念地斩获100.0的满分(基准上限)。而最为讽刺的是作为对照组的w/ Full Pool。该配置没有进行任何预处理,直接将全量技能库暴露给原生Claude SDK,让大模型自主决定调用逻辑。其在三个规模下的得分分别为24.3、48.1、17.2,被彻底击穿。这印证了前文所述的物理坍塌:技能池越庞大,不具备内核调度机制的原生模型死得越快,海量工具在其眼中等同于不可见的噪声数据。
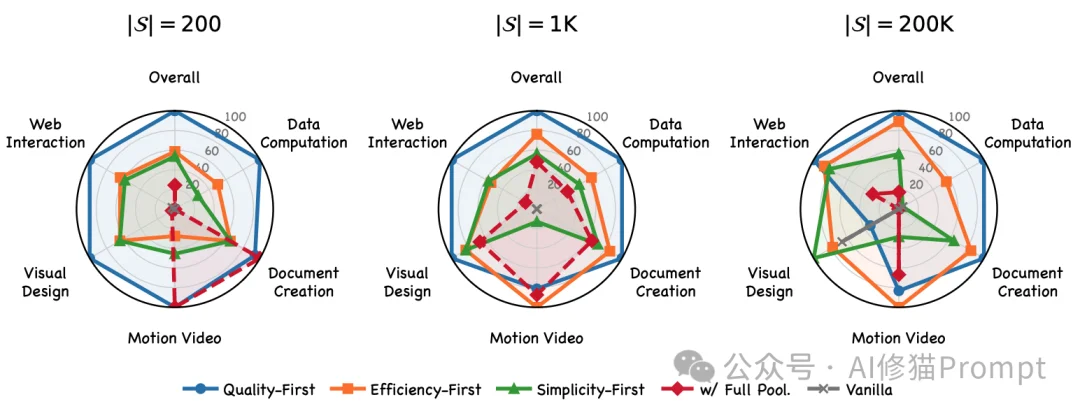
而在最为残酷的消融实验(Ablation Study)中,研究者剥夺了系统生成DAG图纸的能力,但给了它最极致的作弊条件:直接向原生系统喂入该任务标准答案所需要的完美技能名单(w/ Oracle Skills)。 结果表明,即便给定完全正确的手术刀,由于缺乏确定的工作流指引,纯靠LLM扁平化调用的原生系统,依然大幅度输给了自带DAG编排图纸的AgentSkillOS。
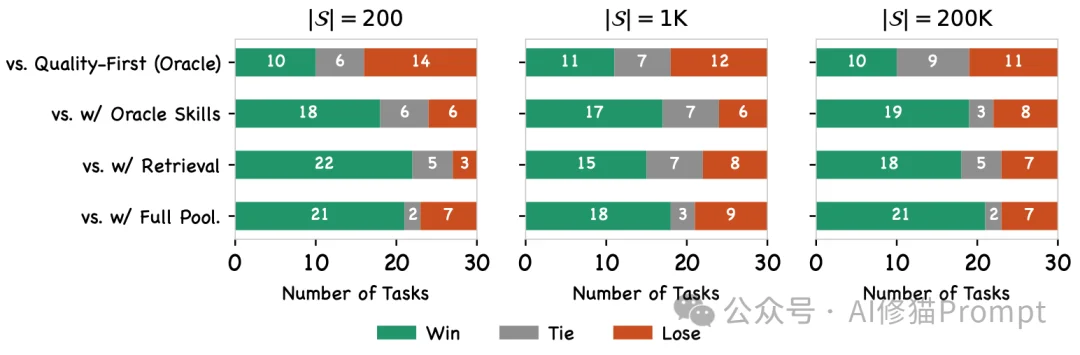
研究者的工作很扎实,但边界并不隐蔽。

这些限制不会推翻论文结论,但会提醒您:AgentSkillOS的真正意义,不是“明天就能替代现有所有skill平台”,而是它已经把一个长期被忽视的问题说透了,skill生态扩大后,agent先遇到的瓶颈不是模型推理本身,而是skill的可见性、可选性与可组合性。AgentSkillOS产出案例:
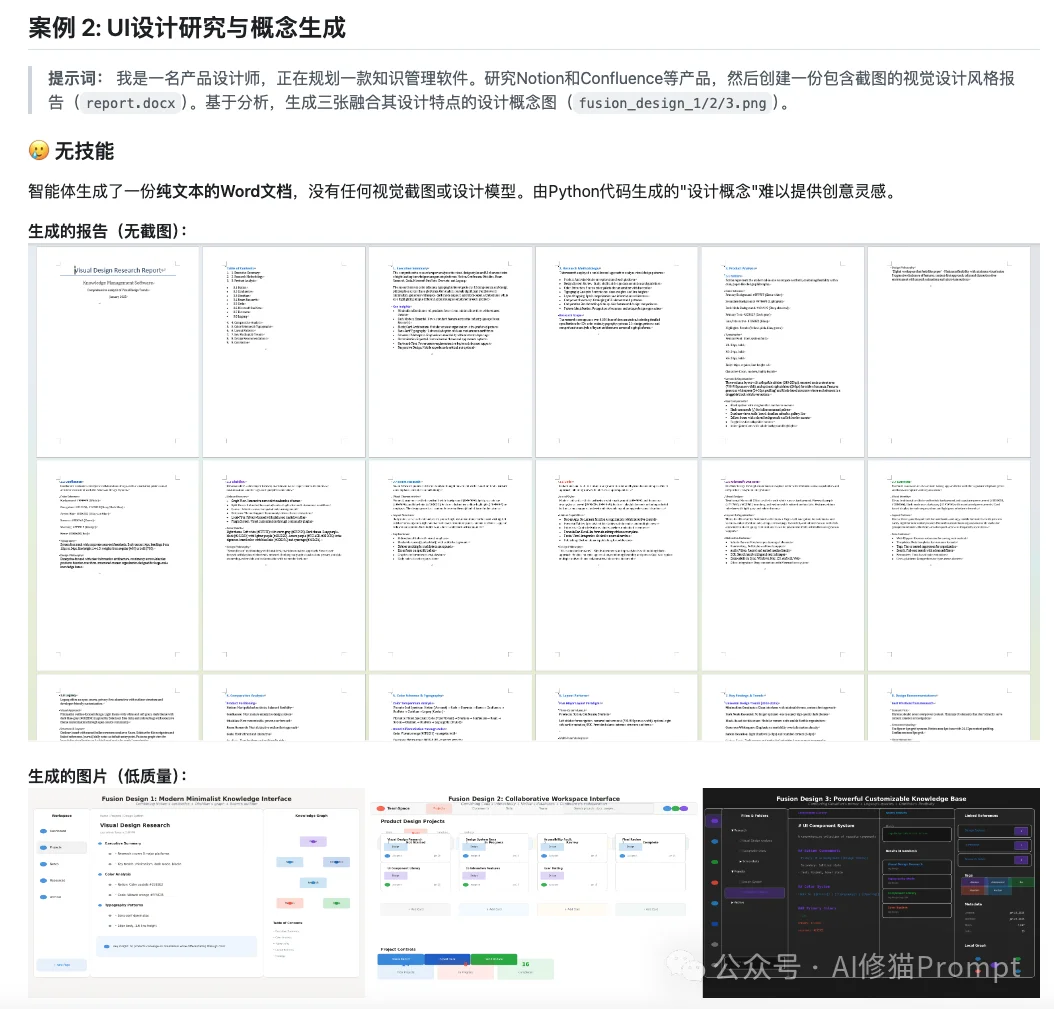
当agent skills进入生态规模,系统设计的重点不再是继续增加skill数量,而是给skill生态补上一层“能力树检索+DAG编排+recipe复用”的中间层。
AgentSkillOS证明了两件事:第一,树形检索确实能逼近数据库级别的skill选择;第二,DAG编排不是附属功能,而是决定多skill任务质量的关键变量。对于资深工程师、研究员和黑客而言,这篇论文真正值得带走的,不是某个具体仓库,而是一种更准确的判断:未来的agent系统,竞争点会逐步从“谁接了更多tools/skills”,转向“谁能把技能生态组织成可计算、可解释、可复用的执行空间”。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
