# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。

去年 EMNLP BoF 上我讲过:Omni 模型是 2026 年 Dense Retrieval 的胜负手。
真正引起我们注意的是音频。大多数人听到多模态 Embedding 首先想到的是图像,顶多再加个视频。音频是被遗忘的模态:数据难采、标注难做、做的人少。
过去一段时间,我们 Jina AI 团队恰好在啃这块硬骨头:如何在 1.2B 规模内做出高性能的音频向量模型?这也是我们通向全模态愿景的关键一步。
趁着 Gemini Embedding 2 发布的节点,把我们一路上踩的坑和学到的东西分享给大家。
音频向量就是把一段音频压成一个定长向量。输入原始波形,模型输出一个稠密向量(通常 768 到 3072 维),编码了这段声音的语义内容。语义相似的两段音频,向量也相近;一段音频和它的文本描述,在共享向量空间中距离很短。这是 Omni Embedding 拼图里的一块:一旦音频能和文本、图像映射到同一个向量空间,跨模态检索就打通了。
2022 年以来的主流方案是 Contrastive Language-Audio Pretraining(CLAP),本质上就是把 CLIP 搬到音频域。思路很直接:一个音频编码器,一个文本编码器,中间用对比学习拉近配对的音频-文本、推远不配对的。LAION-CLAP 在这个基础上用 630K 对数据加 Feature Fusion 做了放大。当前最强变体(Elizalde et al., 2023)在 4.6M 对数据上训练,音频编码器横跨 22 种音频任务,配合自回归解码器,250M 参数量在 AudioCaps 上做到 42.0 cvR@5。
CLAP 的问题在哪?它从零开始学习音频和文本之间的对齐。这意味着你需要海量的配对数据去建立跨模态桥梁,460 万数据对不是白烧的。
我们走了一条完全不同的路:把已经听懂音频的多模态 LLM,直接改造成 Embedding 模型。 桥梁已经在预训练中建好了,我们要做的只是把它从生成模型重塑为向量模型。
先说输入输出。输入是原始音频波形,从 WAV/MP3/FLAC 解码后重采样到 16kHz 单声道。音频编码器先转成 128-bin log-mel 频谱图,再处理成特征 token 序列,大约每秒 150 个 token。一段 10 秒音频约 1500 token。最大输入 30 秒,更长的需要切片。输出是单个稠密向量,维度在 896 到 3584 之间,取决于 LLM backbone 的规模。
起点是 Qwen2.5-Omni,一个原生音频理解的多模态 LLM。三个组件:
两个模态共享同一个 LLM backbone。这不是我们做的对齐,是 Qwen2.5-Omni 在预训练时就建立的。音频特征和文本 token 经过同一堆 Transformer 层处理,在表示空间里天然就有一定程度的对齐。我们要做的是把这种隐式对齐显式化为一个向量模型。
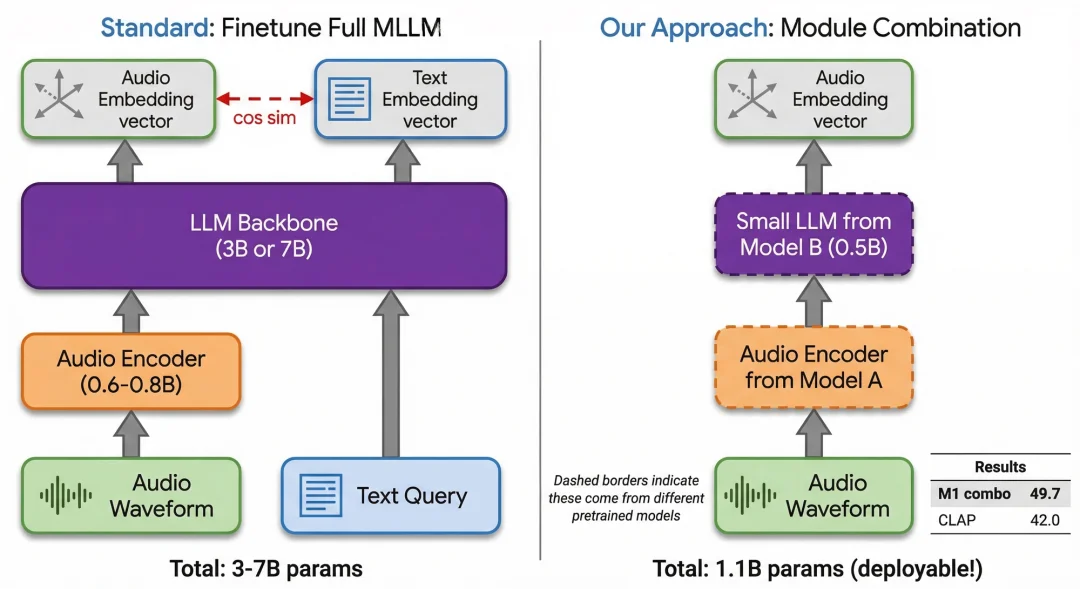
架构对比
左边是标准做法,端到端微调整个 MLLM(3-7B 参数)。右边是我们的模块化组合做法,把预训练音频编码器接到一个更小的 LLM backbone 上。共享 backbone 同时处理音频特征和文本 token,在同一个向量空间中生成 Embedding。
训练目标是 InfoNCE 对比损失。两个模态各自独立编码,双向计算 loss 后取平均:
def training_step(audio_batch, text_batch):
audio_embeds = model.encode_audio(audio_batch) # [B, D]
text_embeds = model.encode_text(text_batch) # [B, D]
audio_embeds = F.normalize(audio_embeds, dim=-1)
text_embeds = F.normalize(text_embeds, dim=-1)
sim = audio_embeds @ text_embeds.T / temperature # [B, B]
labels = torch.arange(len(sim), device=sim.device)
loss = (F.cross_entropy(sim, labels) +
F.cross_entropy(sim.T, labels)) / 2
return loss
五个音频-文本配对数据集,共 181K 样本:
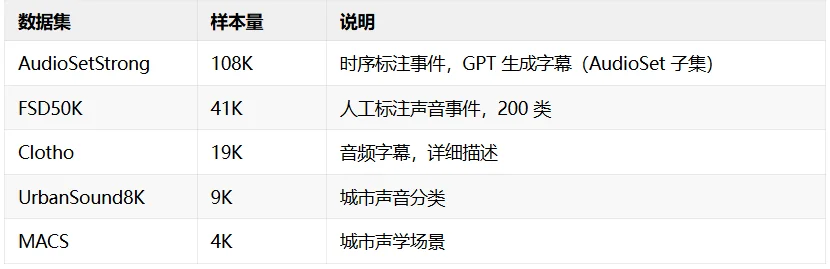
CLAP 用了完整 AudioSet(200 万+音频)加上其他来源,总计 460 万对。我们只用了 AudioSetStrong 约 10 万条,数据量差了 25 倍。
为什么能少这么多?因为 CLAP 需要从零建立跨模态对齐,460 万对数据大部分精力花在教模型"什么声音对应什么文字"。而我们的起点是一个已经听懂音频的 MLLM,跨模态的桥已经造好了,训练只需要把这座桥从"生成"重新校准到"向量检索"。这是一个 fine-grained calibration,不是 from-scratch alignment。
def load_sample(audio_path, caption):
waveform, sr = torchaudio.load(audio_path)
waveform = torchaudio.transforms.Resample(sr, 16000)(waveform)
audio_inputs = processor.feature_extractor(
waveform, sampling_rate=16000, return_tensors="pt"
)
text_inputs = processor.tokenizer(caption, padding=True, return_tensors="pt")
return audio_inputs, text_inputs
我们的目标很明确:参数量压到 1.2B 以下,性能超过 CLAP。我们试了四种做法,前三种各有各的问题,在第四种拿到了结果,但过程本身比结果更有价值。
Qwen2.5-Omni-7B 直接在音频-文本对上做对比学习微调,结果不出意外地好:AudioCaps T2A cvR@5 = 63.2,Clotho T2A = 39.2。这个分数远超 CLAP 的 42.0,证明了思路本身是对的。但 7B 参数量摆在那里,推理成本和延迟都不现实。这条路的价值是给后面所有实验画了一条上限。
值得对比的是其他团队的类似尝试:Tevatron 2.0 也做全模型微调,但只用 AudioCaps 一个数据集,AudioCaps 上拿了 61.2,Clotho 上暴跌到 11.9。单数据集训练在分布内表现好看,出了分布立刻垮掉,这是向量模型老生常谈的问题了。还有 ColQwen-Omni,在视觉文档任务上微调、零音频数据,纯靠跨模态迁移拿到了 37.4。逼近 CLAP 但没超过。零数据能做到这一步,本身也说明 MLLM 的跨模态对齐的能力。
既然 7B 太大,能不能直接砍层?每个 Transformer 层约 0.2B 参数,从 28 层砍到 10 层就剩 3.5B,砍到 5 层剩 2.3B。
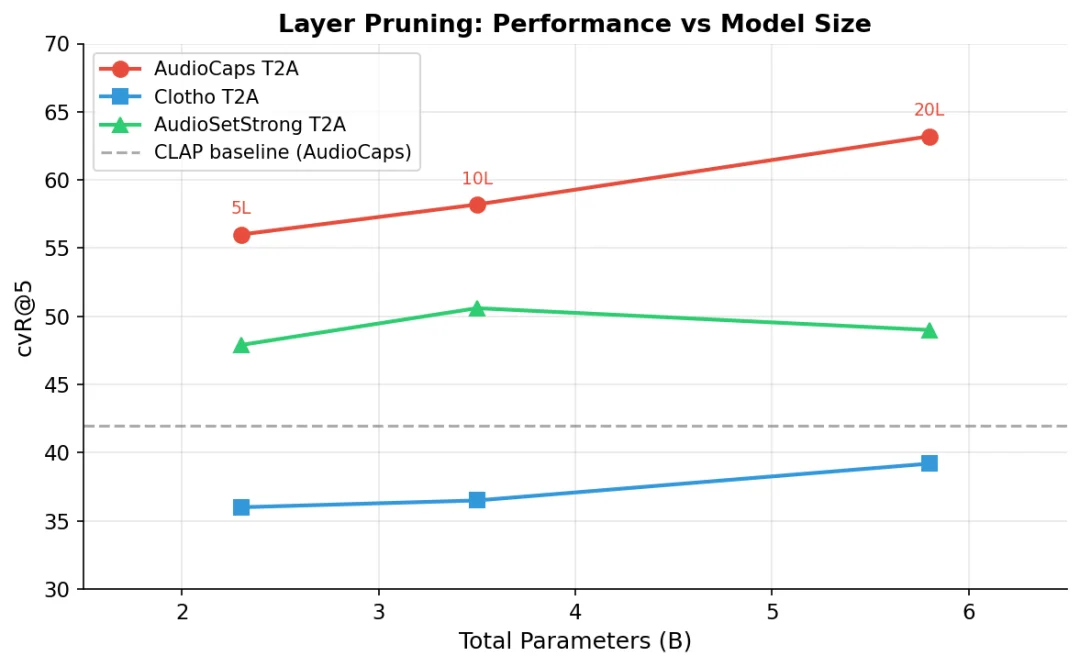
随 Transformer 层数减少的性能变化。
AudioCaps(红线)从 20 层的 63.2 降到 5 层的 56.0 cvR@5。所有配置仍然高于 CLAP baseline(虚线)。但即使砍到 5 层(2.3B 参数),离 1B 目标差了一倍多。

性能下降是平滑的,说明信息在各层间分布比较均匀,没有哪几层是可以无痛摘掉的。
另外一个有意思的观察是 Batch size(32、64、128)几乎没有影响最终性能。大 batch 在训练初期有优势,但后期可能过拟合负样本分布,batch 128 在 2K 步时 Clotho NDCG 打到 31.3,到 10K 步反而掉到 29.3。这说明在数据量有限的情况下,大 batch 带来的 hard negative 数量优势敌不过分布偏移的风险。
层剪枝的根本限制是:音频编码器本身就有 0.6-0.8B,加上投影层和 Embedding 层的固定开销,即使 LLM backbone 砍到零,模型也至少 1B 起步。此路不通。
这个思路更激进:完全不用任何音频-文本配对数据,只用纯文本 NLI 数据集(MultiNLI、SNLI、FEVER、SciFact)做微调。逻辑是这样的,MLLM 预训练时已经建立了音频和文本的对齐,那我只训练文本侧的向量质量,音频侧应该能搭上便车。
在完整 7B 上,这个赌注居然赢了:AudioCaps 46.1,超过了 CLAP 的 42.0。零音频训练数据,纯靠文本 NLI 就能做出一个比 CLAP 更好的音频向量模型,这本身就很说明问题,MLLM 预训练建立的跨模态对齐做得很深,不是表面功夫。
但在剪枝后的 10 层模型上,同样的做法直接塌了:cvR@5 = 5.9,几乎等于随机。
这里的 insight 很重要:跨模态对齐不是一个集中存储在某几层的对齐模块,而是分布在整个网络的每一层中。28 层的完整网络里,每一层都参与了音频和文本表示的渐进对齐。你砍掉大部分层,对齐就碎了。文本侧靠 NLI 数据还能补回来,但音频侧没有任何数据兜底,直接归零。
这条路教会我们的是:模态迁移的可行性和模型压缩的可行性是矛盾的。你不能同时既要又要。
前三条路的共同问题是都从同一个 7B 模型出发往小了做。路径四我们换了一个思路:不从大模型上减,从小组件上加。 从一个模型里摘出音频编码器,从另一个模型里拿一个小 LLM backbone,拼在一起,甚至可以跨模型家族拼装。
为什么这也能行呢? 因为 Qwen2.5-Omni 的训练分了三阶段:1. 冻结 LLM,只训练音频/视觉编码器的投影层;2. 全参数解冻联合训练;3. 扩展到 32K 上下文。
关键在于第一阶段,音频编码器学会了如何把波形转成 LLM 能读懂的 token。这种说 LLM 语言的能力是通用的,不绑定某一个特定的 LLM。所以我们大胆假设:一个在第一阶段训练好的音频编码器,应该能直接插到任何 Qwen 系列的小 LLM 上。
我们测试了四种组合:
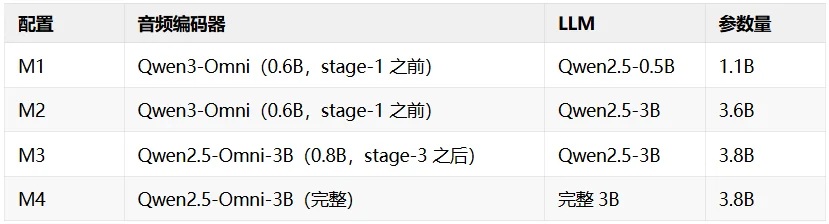
实现细节上有个坑,Qwen3-Omni 用的是 Qwen3OmniMoePreTrainedModel,standalone Qwen3 用的是 Qwen3ForCausalLM,两者的模型壳子不一样。我们的做法是初始化一个维度匹配的 Omni 模型壳子,然后把权重拷贝到对应位置。
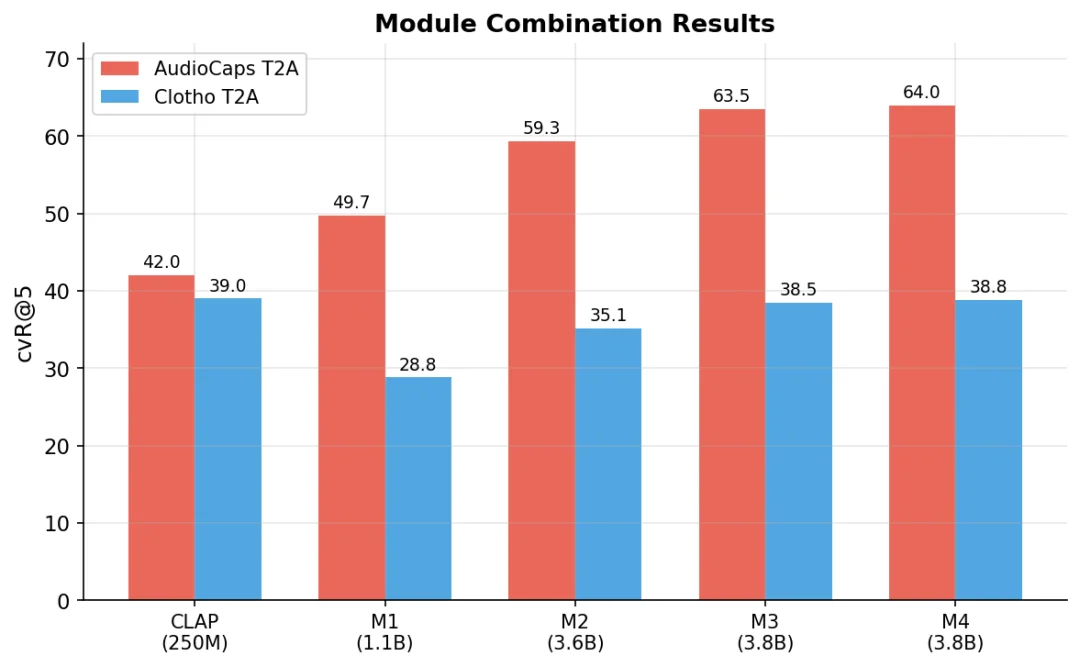
各配置在 AudioCaps 和 Clotho T2A cvR@5 上的表现
用 stage-3 之后对齐更好的音频编码器效果更好(M3 vs M2:AudioCaps +4.2)。LLM 预训练的 stage 2-3 对 Embedding 质量影响不大(M3 vs M4 在误差范围内)。
结果里有三个发现:
第一,M1(1.1B)在 AudioCaps 上就打到了 49.7,超过 CLAP 的 42.0 整整 18%。 我们目标达成:参数量 1.1B,低于 1.2B 的目标线,性能大幅领先 CLAP,并且只用了 CLAP 1/25 的训练数据。
第二,音频编码器的对齐质量决定上限。 M3 用的是第三阶段之后完整训练过的音频编码器,M2 用的是 stage-1 之前的初始版本,两者 LLM backbone 相同(Qwen2.5-3B),但 M3 在 AudioCaps 上比 M2 高了 4.2 个点。这说明音频编码器在多阶段训练中获得的对齐精度直接传导到了最终的 Embedding 质量。
第三,LLM 的 stage 2-3 训练对 Embedding 质量几乎没有影响。 M3(拼装的 LLM)和 M4(原装完整 3B)的性能在误差范围内。这也意味着 LLM backbone 在 stage 2-3 学到的那些能力:更好的指令跟随、更长的上下文处理,对向量化任务没有贡献。向量模型需要的是表示能力,不是生成能力。
音频 Embedding 的评测本质上就是看检索质量:给一段文本 query,能不能找到对的音频?
难点在于对的定义因数据集而异。
AudioCaps 的描述很具象("一个男人说话,然后门关上了"),这种描述和声学特征是一一对应的,模型只要记住声学 pattern 就能得分。
而 Clotho 的描述更抽象("安静的氛围中远处有隆隆声")。这需要模型理解场景级别的语义,而不只是频谱特征。一个只记住表面声学特征的模型在 AudioCaps 上跑分好看,到 Clotho 上就原形毕露。我们最看重的是跨描述风格的泛化能力,这才能反映模型真正理解了什么。
CV-Recall@5(cvR@5):对每个文本 query,看 top-5 结果中是否命中正确音频。二值打分,所有 query 取平均。这是 MTEB 音频检索的标准 metric。
def evaluate_cvr_at_k(model, dataset, k=5):
audio_embeds = model.encode_audio(dataset.audio_clips)
text_embeds = model.encode_text(dataset.text_queries)
sim = F.normalize(audio_embeds) @ F.normalize(text_embeds).T
hits = 0
for i in range(len(dataset.text_queries)):
top_k = sim[:, i].argsort(descending=True)[:k]
if dataset.ground_truth[i] in top_k:
hits += 1
return hits / len(dataset.text_queries)
三个评测集均来自 MTEB:AudioCaps(视频衍生,人工字幕)、AudioSetStrong(时序标注,GPT 描述)、Clotho(多样化,抽象字幕)。CLAP 用了完整 AudioSet(200 万+),我们只用了 AudioSetStrong 约 10 万条,这在一定程度上解释了 CLAP 在该 benchmark 上的优势。
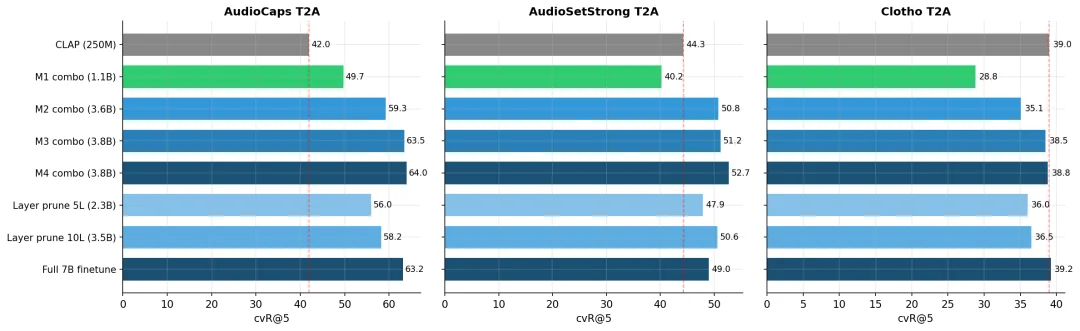
所有配置在 AudioCaps、AudioSetStrong、Clotho T2A 检索上的横向对比
红色虚线为 CLAP baseline。模块组合方案(绿色)以远远更小的模型尺寸取得了有强竞争力的结果。全量微调的 7B 模型(深蓝)是性能上限。
传统的音频检索里,输入文字找音效当然是最直接的场景。但更值得关注的是音频 Embedding 在 Agentic 系统中的角色。当语音成为 Agent 的主要输入方式时,第一步往往是 ASR 转文字再处理。但 ASR 有延迟、会丢失语气语调信息、还依赖转写质量。如果 Agent 能直接对语音输入做向量化,根据语义相似度分发到正确的工具或子 Agent,就跳过了 ASR 这个瓶颈。不是所有语音输入都需要逐字转写,很多时候你只需要知道"这段话的意图是什么"。
工业场景里的声音事件分类也是一个被低估的方向。设备异响检测、安防系统、智能家居,这些场景需要的不是转写,而是"这个声音像什么",这正是 Embeddings 的强项。
更远一步看,当 Omni Embedding 做成了,文本、图像、音频、视频都在一个向量空间里,Agent 就获得了一个统一的感知接口。不管输入是什么模态,都转成向量后统一检索、比较、推理。这是多模态 Agent 能真正 scale 的前提。
而这一切有个硬性前提:模型要够小,能在端侧跑。 语音交互容不下云端传输带来的延迟损耗,而且语音数据的隐私敏感度远高于文本。所以高性能的小模型不是加分项,而是入场券。这也是我们把目标定在 1.2B 以下的原因。
预训练 MLLM 是做新模态 Embedding 最大的杠杆。 它一次性提供了跨模态对齐、强文本编码器和能力不错的音频编码器。
模块化组合是目前最有前景的方向。 从不同模型、不同训练阶段里拆出组件自由拼装,我们在音频向量任务上验证了可行性。实验结果也指向了一个清晰优先级:音频编码器的对齐质量是第一位的(stage-3 vs pre-stage-1 差了 4.2 个点),LLM backbone 的生成能力对向量化任务没有贡献(stage 2-3 训练前后没有差异)。这也意味着构建向量模型时,选组件的优先级是:编码器对齐 > LLM 的表示能力 > LLM 的其他能力。
跨模态迁移和模型压缩不能既要又要。 文本模态迁移在完整 7B 上漂亮地跑通了(46.1 vs CLAP 42.0),但在 10 层剪枝模型上直接归零(5.9)。对齐分布在整个网络中,压缩就碎。
AudioCaps 领跑不代表问题解决了。 我们模型在 AudioCaps 上大幅领先 CLAP,但在更依赖抽象语义的 Clotho 榜单上只是持平。暴露了模型的场景级语义理解不够。只看 AudioCaps 你会觉得模型已经很好了;加上 Clotho 就知道还差得远。
这项工作是我们迈向 Omni Embedding(全模态向量模型)的关键一步,模块化组合让我们找到了无需大规模烧数据即可开启新模态的方法,但 Clotho 的结果提醒我们:光靠复用预训练组件还不够,数据质量和多样性仍然是底层硬约束。
接下来我们会探索 MoE 架构把激活参数压到 500M 以下,尝试模块组合和模态迁移的深度结合,引入 WavCaps、MusicCaps 和语音数据集做数据扩充,重点补上抽象描述的短板。
我们开源社区见!https://github.com/jina-ai/audio-embedding-kickstarter
文章来自于“Jina AI”,作者 “Jina AI”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
