# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,正是促进该过程的关键技术。
然而,当下视频与文本描述间广泛存在的噪声关联现象严重阻碍了视频表征学习。因此本文中,研究者基于最优传输理论,提出鲁棒的长视频学习方案以应对该挑战。该论文被机器学习顶会 ICLR 2024 接收为了 Oral。

视频表征学习是多模态研究中最热门的问题之一。大规模视频 - 语言预训练已在多种视频理解任务中取得显著效果,例如视频检索、视觉问答、片段分割与定位等。目前大部分视频 - 语言预训练工作主要面向短视频的片段理解,忽略了长视频中存在的长时关联与依赖。
如下图 1 所示,长视频学习核心难点是如何去编码视频中的时序动态,目前的方案主要集中于设计定制化的视频网络编码器去捕捉长时依赖 [2],但通常面临很大的资源开销。

图 1:长视频数据示例 [2]。该视频中包含了复杂的故事情节和丰富的时序动态。每个句子只能描述一个简短的片段,理解整个视频需要具有长时关联推理能力。
由于长视频通常采用自动语言识别(ASR)得到相应的文本字幕,整个视频所对应的文本段落(Paragraph)可根据 ASR 文本时间戳切分为多个短的文本标题(Caption),同时长视频(Video)可相应切分为多个视频片段(Clip)。对视频片段与标题进行后期融合或对齐的策略相比直接编码整个视频更为高效,是长时时序关联学习的一种优选方案。
然而,视频片段与文本句子间广泛存在噪声关联现象(Noisy correspondence [3-4],NC),即视频内容与文本语料错误地对应 / 关联在一起。如下图 2 所示,视频与文本间会存在多粒度的噪声关联问题。
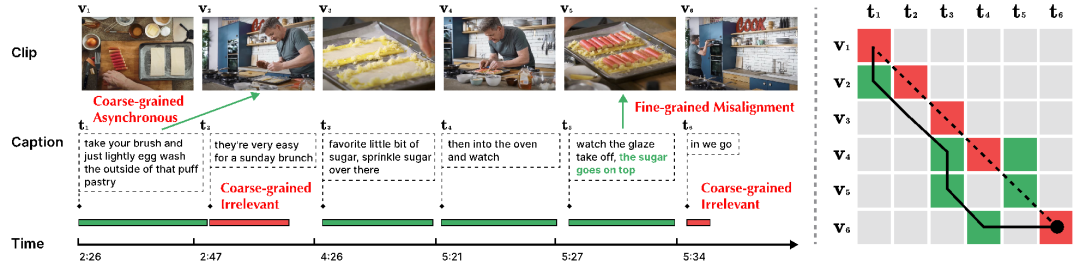
图 2:多粒度噪声关联。该示例中视频内容根据文本标题切分为 6 块。(左图)绿色时间线指示该文本可与视频内容对齐,红色时间线则指示该文本无法与整个视频中的内容对齐。t5 中的绿色文本表示与视频内容 v5 有关联的部分。(右图)虚线表示原本给定的对齐关系,红色指示原本对齐中错误的对齐关系,绿色则指示真实的对齐关系。实线表示通过 Dynamic Time Wraping 算法进行重新对齐的结果,其也未能很好地处理噪声关联挑战。
本文提出噪声鲁棒的时序最优传输(NOise Robust Temporal Optimal transport, Norton),通过视频 - 段落级对比学习与片段 - 标题级对比学习,以后期融合的方式从多个粒度学习视频表征,显著节省了训练时间开销。
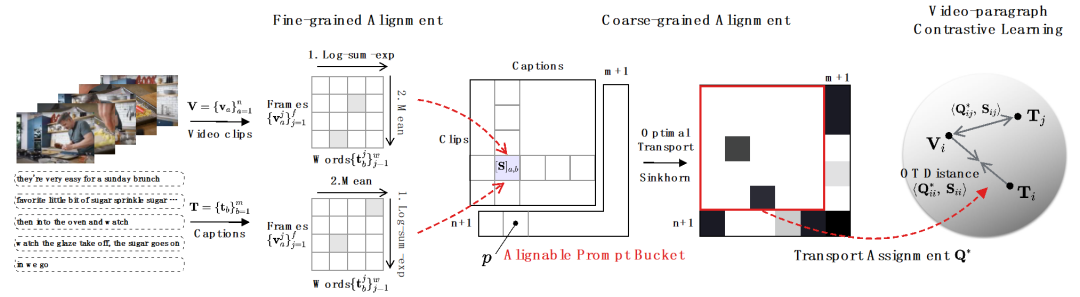
图 3 视频 - 段落对比算法框架图。
1)视频 - 段落对比。如图 3 所示,研究者以 fine-to-coarse 的策略进行多粒度关联学习。首先利用帧 - 词间相关性得到片段 - 标题间相关性,并进一步聚集得到视频 - 段落间相关性,最终通过视频级对比学习捕捉长时序关联。针对多粒度噪声关联挑战,具体应对如下:
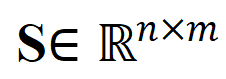 ,其中
,其中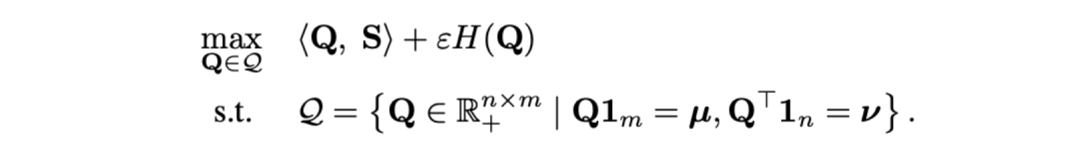
其中 ![]() 为均匀分布给予每个片段、标题同等权重,
为均匀分布给予每个片段、标题同等权重, ![]() 为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。
为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。
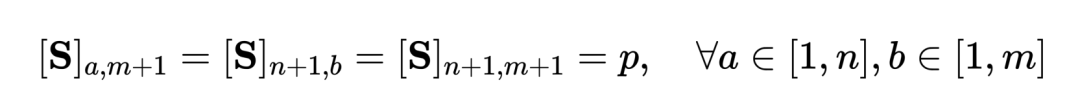
通过最优传输来度量序列距离,而非直接对长视频进行建模,可显著减少计算量。最终视频 - 段落损失函数如下,其中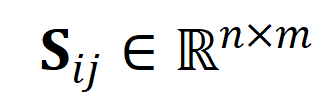 表示第
表示第![]() 个长视频与第
个长视频与第![]() 个文本段落间的相似性矩阵。
个文本段落间的相似性矩阵。
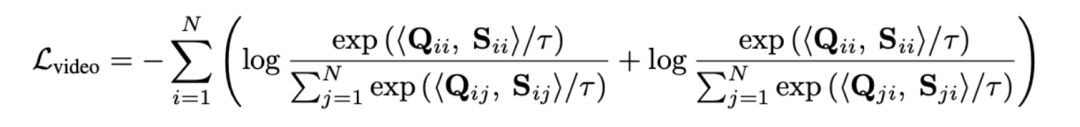
2)片段 - 标题对比。该损失确保视频 - 段落对比中片段与标题对齐的准确性。由于自监督对比学习会将语义相似的样本错误地作为负样本优化,我们利用最优传输识别并矫正潜在的假阴性样本:
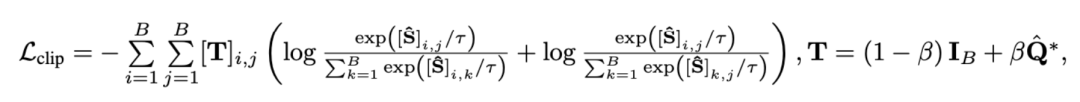
其中![]() 代表训练批次中的所有视频片段和标题个数,单位矩阵
代表训练批次中的所有视频片段和标题个数,单位矩阵![]() 代表对比学习交叉熵损失中的标准对齐目标,
代表对比学习交叉熵损失中的标准对齐目标,![]() 代表融入最优传输矫正目标
代表融入最优传输矫正目标![]() 后的重对齐目标,
后的重对齐目标,![]() 为权重系数。
为权重系数。
本文旨在克服噪声关联以提升模型对长视频的理解能力。我们通过视频检索、问答、动作分割等具体任务进行验证,部分实验结果如下。
1)长视频检索
该任务目标为给定文本段落,检索对应的长视频。在 YouCookII 数据集上,依据是否保留文本无关的视频片段,研究者测试了背景保留与背景移除两种场景。他们采用 Caption Average、DTW 与 OTAM 三种相似性度量准则。Caption Average 为文本段落中每个标题匹配一个最优视频片段,最终召回匹配数最多的长视频。DTW 和 OTAM 按时间顺序累计视频与文本段落间距离。结果如下表 1、2 所示。
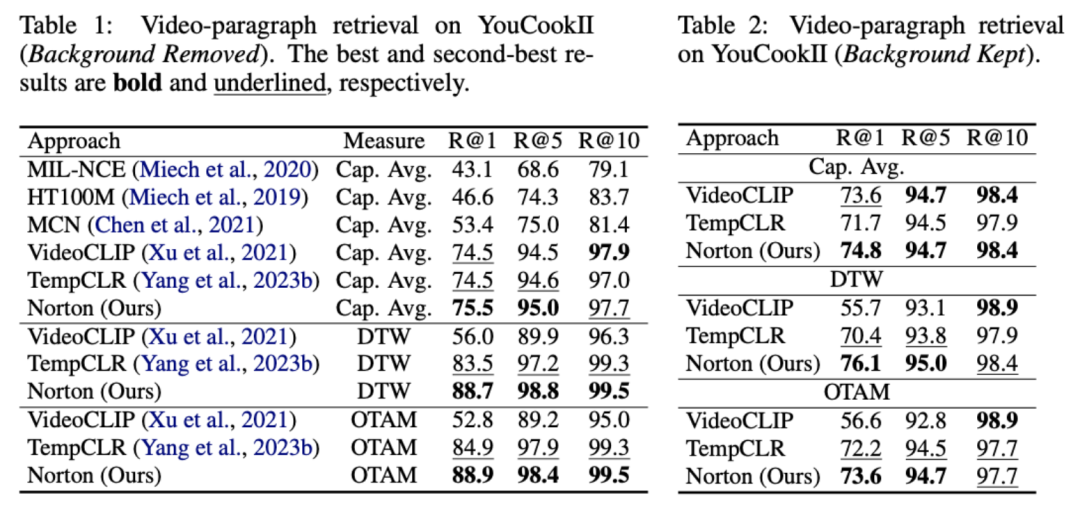
表 1、2 在 YouCookII 数据集上的长视频检索性能比较
2)噪声关联鲁棒性分析
牛津 Visual Geometry Group 对 HowTo100M 中的视频进行了手工重标注,对每个文本标题重新标注正确的时间戳。产出的 HTM-Align 数据集 [5] 包含 80 个视频与 49K 条文本。在该数据集上进行视频检索主要验证模型是否过度拟合了噪声关联,结果如下表 9 所示。

表 9 在 HTM-Align 数据集上针对噪声关联的有效性分析
本文是噪声关联学习 [3][4]—— 数据错配 / 错误关联的深入延续,研究多模态视频 - 文本预训练面临的多粒度噪声关联问题,所提出的长视频学习方法能够以较低资源开销扩展到更广泛的视频数据中。
展望未来,研究者可进一步探讨多种模态间的关联问题,例如视频往往包含视觉、文本及音频信号;可尝试结合外部大语言模型(LLM)或多模态模型(BLIP-2)来清洗和重组织文本语料;以及探索将噪声作为模型训练正激励的可能性,而非仅仅抑制噪声的负面影响。
参考文献:
1. 机器之心,“Yann LeCun:生成模型不适合处理视频,AI 得在抽象空间中进行预测”,2024-01-23.
2.Sun, Y., Xue, H., Song, R., Liu, B., Yang, H., & Fu, J. (2022). Long-form video-language pre-training with multimodal temporal contrastive learning. Advances in neural information processing systems, 35, 38032-38045.
3.Huang, Z., Niu, G., Liu, X., Ding, W., Xiao, X., Wu, H., & Peng, X. (2021). Learning with noisy correspondence for cross-modal matching. Advances in Neural Information Processing Systems, 34, 29406-29419.
4.Lin, Y., Yang, M., Yu, J., Hu, P., Zhang, C., & Peng, X. (2023). Graph matching with bi-level noisy correspondence. In Proceedings of the IEEE/CVF international conference on computer vision.
5.Han, T., Xie, W., & Zisserman, A. (2022). Temporal alignment networks for long-term video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2906-2916).
6.Sarlin, P. E., DeTone, D., Malisiewicz, T., & Rabinovich, A. (2020). Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4938-4947).
文章来自于微信公众号 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
