# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从 Sora,可灵到 seedance 2.0,AI 视频生成的浪潮正席卷而来,其惊人的视觉质量让人叹为观止。然而,当我们尝试用它创作一个真正的 “故事” 时,一个普遍的瓶颈浮出水面:连贯性。
为了攻克这一难题,我们提出了 STAGE,一个以 “电影分镜” 为核心的全新叙事生成框架。它不再预测孤立的关键帧,而是直接生成每个镜头的 “起始 - 结束帧对”,为多镜头视频的创作提供了前所未有的结构化控制力。

目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:
一、前言:AI 视频生成,从 “做动图” 到 “拍电影” 还差多远?
究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。
目前,主流的多镜头视频生成方法大致分为两派:
这些方法生成的视频,常常在镜头切换时出现 “灾难性” 的断裂:前一秒主角还穿着红衣,后一秒就换了颜色;或者一个流畅的开箱动作,在特写镜头里却变成了 “瞬移”(如下图中的戒指盒)。这些 “穿帮镜头” 的根源在于,模型只知道每个镜头 “大概长啥样”,却不懂得镜头与镜头之间该如何 “衔接”。

现有方法(上)在镜头切换时常出现动作不连贯、物体不一致的问题。STAGE(下)通过预测结构化的 “分镜”,实现了电影级的平滑过渡。
问题的本质是:我们一直在让 AI “画单帧”,而不是 “拍分镜”。一个真正的导演,脑海里不仅有高潮画面,更有每个镜头的起与承、转与合。
二、核心洞察:用 “起始 - 结束帧对” 重构叙事骨架
多镜头叙事的关键,不应是几个孤立的、稀疏的关键帧,而应是一个结构化的电影分镜 (Storyboard)。基于此,我们提出了一个创新性的想法:
将关键帧生成任务,重新定义为 “起始 - 结束帧对 (Start-End Frame Pairs)” 的预测任务。
也就是说,对于每一个镜头,我们不再只预测一个代表性的画面,而是直接预测出它的 “第一帧” 和 “最后一帧”。这个看似简单的改变,却带来了三大优势:
正是基于这一观察,设计了全新的多镜头叙事生成工作流 ——STAGE (SToryboard-Anchored GEneration)。
三、技术核心:STEP2,一个懂得 “拍分镜” 的 AI 导演
STAGE 工作流的核心,是我们提出的起始 - 结束帧对预测模型 ——STEP2 (STart-End frame-Pair Prediction model)。它就像一位 AI 导演,能将文字剧本精准地翻译成一系列可执行的视觉分镜。
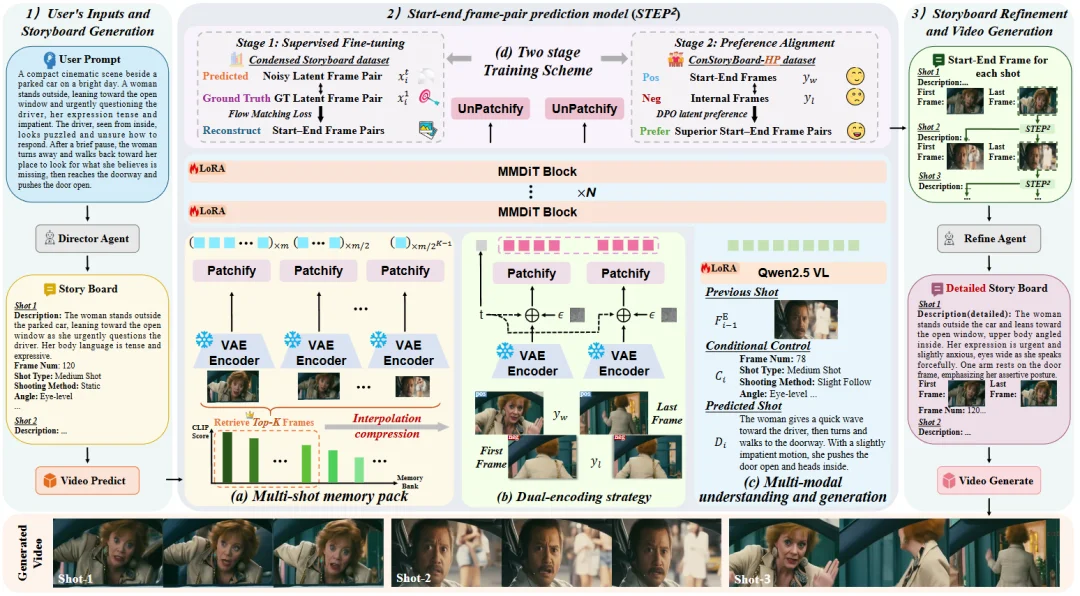
为了让这位 “AI 导演” 足够专业,我们为它配备了三大法宝:
1. 多镜头记忆包 (Multi-shot Memory Pack):过目不忘,确保角色不 “穿越”
为了在生成第 N 个镜头时还记得第一个镜头里主角长什么样,我们设计了一个高效的记忆压缩机制。它能将所有历史镜头的视觉信息压缩成一个紧凑的 “记忆包”,在保证长期一致性的同时,避免了巨大的计算开销。
2. 双重编码策略 (Dual-Encoding Strategy):运镜连贯,确保动作不 “瞬移”
为了保证单个镜头内部的逻辑自洽(例如,一个平滑的推镜头),我们将一个镜头的起始帧和结束帧 “捆绑” 在一起进行联合编码。这让模型在生成之初就对整个镜头的动态了然于胸。
3. 两阶段训练方案 (Two-stage Training Scheme):从 “会拍” 到 “拍得好”
光会拍还不够,还要有 “品味”。我们借鉴了电影学院的教学模式:第一阶段(SFT 监督微调):先让模型在海量的电影片段上学习基础的镜头语言,做到 “会拍”。第二阶段(DPO 偏好对齐):再用人类精选的 “好 / 坏” 镜头转场案例进行 “阅片” 训练,让模型学会什么是 “高级的、电影感的” 转场,最终实现 “拍得好”。
四、数据基石:让模型学会 “分镜” 的起点
要让 AI 学会电影语言,一本好的 “教科书” 必不可少。然而,现有数据集都只关注单帧,无法满足我们对 “分镜” 和 “转场” 的训练需求。为此,我们构建了大规模的 ConStoryBoard 数据集。我们从公开电影中筛选了 10 万个高质量多镜头片段,并为每个镜头都进行了精细化标注,包括:起始 - 结束帧对,故事进展描述,镜头尺度、机位、运镜等电影学属性。更进一步,我们还从中人工挑选出最优的转场案例,构建了包含人类偏好的子集 ConStoryBoard-HP,专门用于第二阶段的 “品味” 训练。
五、实验结果:不仅更连贯,还更懂 “电影感”
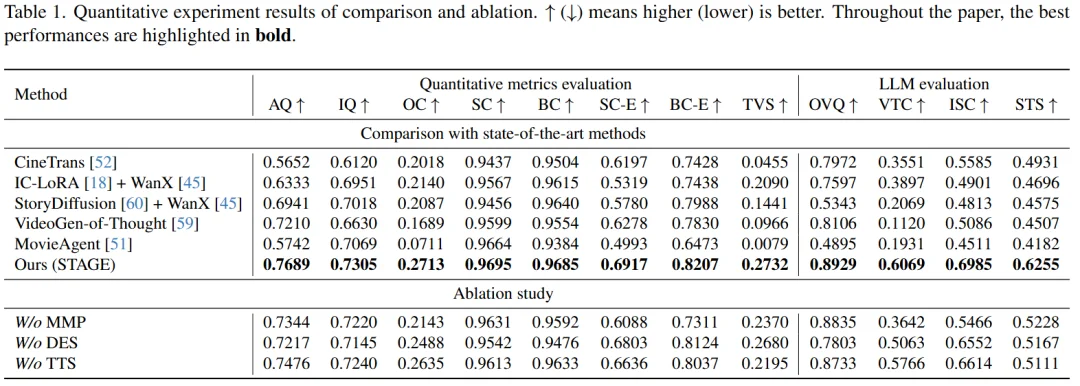
我们将 STAGE 与多种 SOTA 多镜头生成方法进行了全面对比。
视觉对比

在 “火车上的女人” 这一主题下,其他方法出现了场景不一致(CineTrans)、风格失真(StoryDiffusion)、动作断裂(VideoGen-of-Thought)等问题。STAGE 则完美保持了人物和环境的一致性,并实现了流畅的叙事。
定量指标
动态展示




六、意义与展望:让 AI 学会用镜头讲故事
这项工作传递了一个清晰的信号:多镜头视频生成的未来,在于结构化的叙事控制,而不仅仅是像素的堆砌。通过引入 “分镜” 这一电影工业的核心概念,STAGE 为 AI 视频生成开辟了一条从 “技术炫技” 迈向 “艺术创作” 的新路径。它让模型不再是一个只会画画的 “美工”,而更像一个懂得如何用镜头组织故事的 “导演”。
我们相信,当 AI 真正开始学会 “拍电影”,而不仅仅是 “做动图” 时,一个由 AI 辅助创作的、真正属于每个人的电影时代,才算真正到来。
更多细节请参阅原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
