# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
春节期间,注意到一个叫 Taku 的产品
说一下:这个产品目前并没有完全 ready,本篇也不是对产品的推广
但在这个产品里,有非常多有趣的思考
Taku 做的事情,可以这样概括:你在 Taku 里生成出来的所有东西,不管是 Agent、工具还是纯软件脚本,底层共享一套统一的通讯协议,可以相互调用
Taku 在做一件很大的事:每个人都可以把自己的代码、知识、技能快速地在 Taku 里重构、分发。从生成、运行、串联到分发的完整闭环
比如你在里面做了一个 AI 股票分析系统和一个量化选股脚本,主 Agent 可以直接把这两个东西串起来用,不需要手动配接口。一个是 Multi-agent 架构,一个是纯软件、完全没有大模型,但它们的后端是通的
同时,你在其中一个应用里积累的数据和使用习惯,会自动同步给所有相关的应用
Taku 产品界面
前两天有机会和 Taku 的创始人 Austin 聊了两个小时。以下是聊天的内容,以及一些我的补充
Harness 这个词最近在海外 AI 工程圈非常热
今年 2 月,OpenAI 的 Codex 团队发了一篇文章,讲的是他们内部用 Codex agent 从零开始构建了一个百万行代码的产品,全程没有手写一行代码

https://openai.com/index/harness-engineering/
Martin Fowler 随后在 Thoughtworks 的专栏里跟进讨论,LangChain 写了「The Anatomy of an Agent Harness」,Salesforce 也出了自己的定义文章
这些讨论里对 Harness 的共识大概是这样的:
Agent Harness 是包裹在 AI 模型外面的那一整层软件基础设施,负责管理模型的生命周期、上下文、工具调用、状态持久化和错误恢复模型提供推理能力,Harness 提供推理之外的一切
LangChain 的文章里有一个说法:模型是 CPU,上下文窗口是内存,Agent Harness 就是操作系统
Anthropic 自己也把 Claude Agent SDK 称为一个通用型的 Agent Harness
目前行业里讨论 Harness 的时候,主要关注的是怎么让单个 agent 更可靠地完成长时间、复杂的任务
Taku 用了 Software Harness 这个词,但他们关注的问题往前走了一步:多个生成物之间怎么协作
Austin 和他的团队把 Taku 的 Harness 分成了三层
生成出来的东西直接能跑,不需要部署,这里 Austin 给我做了个演示:从 GitHub 拉了一个叫 OpenCut 的开源剪辑工具下来
这个项目依赖很复杂,有数据库、有 Redis、有一堆外部组件,正常情况下自己配环境也要折腾很久
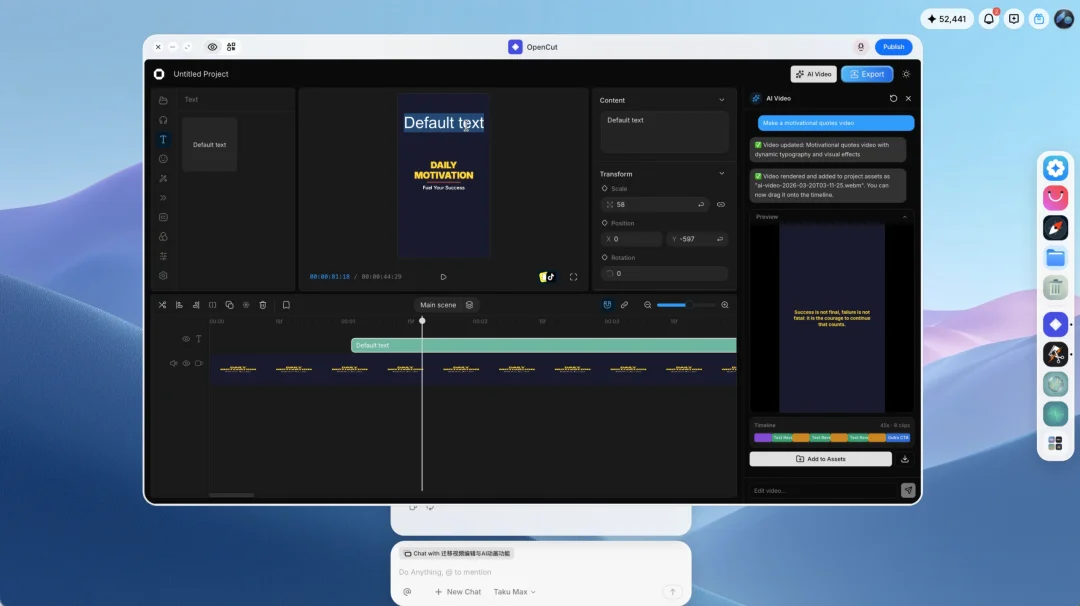
OpenCut 在 Taku 里直接配置运行
之前,Austin 在 Taku 里面做了一个自然语言剪辑和生成视频的小 APP,叫 FlashCut
对着这个 APP,他做了一件更有意思的事,对 Taku 说:把 FlashCut 里的这个视频生成 skill,拼到 OpenCut 里面去
一个完全没有 AI 能力的开源项目,就这样获得了 AI 视频生成的能力
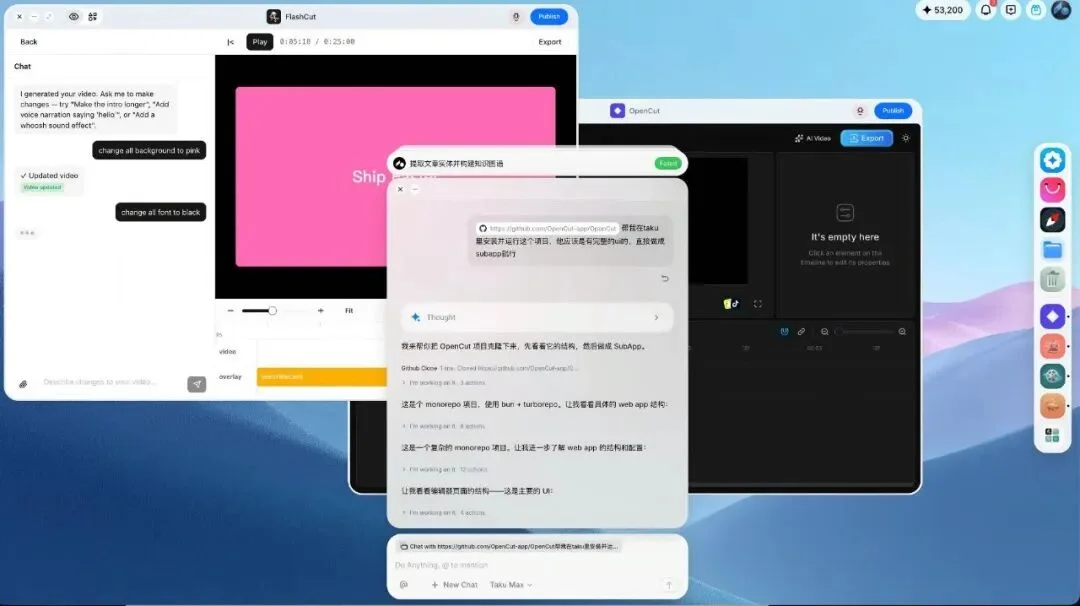
Taku 将 Flashcard 的 AI 能力原子化拼接到 OpenCut
Austin 提到一个观察:做 APP 的难点很多时候甚至不在「做」,在做完之后怎么把它跑起来
中间要部署、要打包、要配环境。这个过程太长的话,用户的耐心就断了
他拿抖音和 YouTube 做了个对比:拍摄本身现在都不难了,难的是拍完之后你还得剪、还得传、还得配。如果拍完直接就能发,整个创作的动力链条就是通的
Taku 的 Runtime 想解决的就是这个环节。生成完直接能跑,跑完直接能用
VIDEO · 原子化拼装新软件
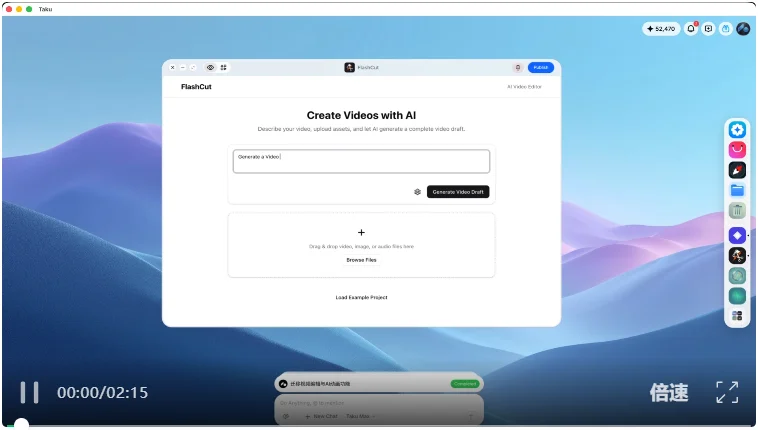
演示者先展示了一个叫 FlashCut 的 AI 视频生成工具(可以通过自然语言修改视频),然后部署了一个叫 OpenCut 的开源剪辑工具(类似剪映,但本身没有 AI 能力)
向 AI 下达指令:把 FlashCut 里的 AI 视频生成能力,集成到 OpenCut 里面
AI 成功将 FlashCut 的 AI 能力「拔」了出来,作为新模块嵌入 OpenCut。侧边栏多出了一个「AI Video」选项,可以直接通过文字生成视频,生成后导入轨道做传统剪辑
Austin 提到一个记者朋友做杨植麟访谈的例子:他需要一个录音工具,一个笔记工具,一个用 Manus 搭的资料工作流,再加上自己写作风格的 reference
在 Claude Code 或者 OpenClaw 里面,情况也类似。你生成了三个项目,三个项目的后端是各自独立的。你想让项目 A 调用项目 B 的能力,需要自己手动配置
OpenClaw 的 skill 体系能做的事情也是有边界的,很多投资人以为 skill 什么都能做,实际上限制不少
Taku 定了一套 Protocol:所有在 Taku 生态内生成出来的东西,后端都有一套统一的对 agent 接口
不管它是一个 Multi-agent 系统、一个纯软件脚本、还是一个 AI skill,主 Agent 都可以无缝调用
Austin 演示了一个具体的串联:AI Hedge Fund 是一个开源的 Multi-agent 股票分析系统,把巴菲特、芒格等不同投资人的方法论分别做成了 agent,每个 agent 会对股票的不同维度做出主观判断
旁边是一个纯量化脚本的选股器,完全没有大模型参与,纯软件逻辑
这两个东西的后端结构、数据库可能完全不一样。但在 Taku 里,一句话就串起来了
主 Agent 发现这两个工具都有后端,直接用后端对后端的方式调用,把两边的结果合在一起给你
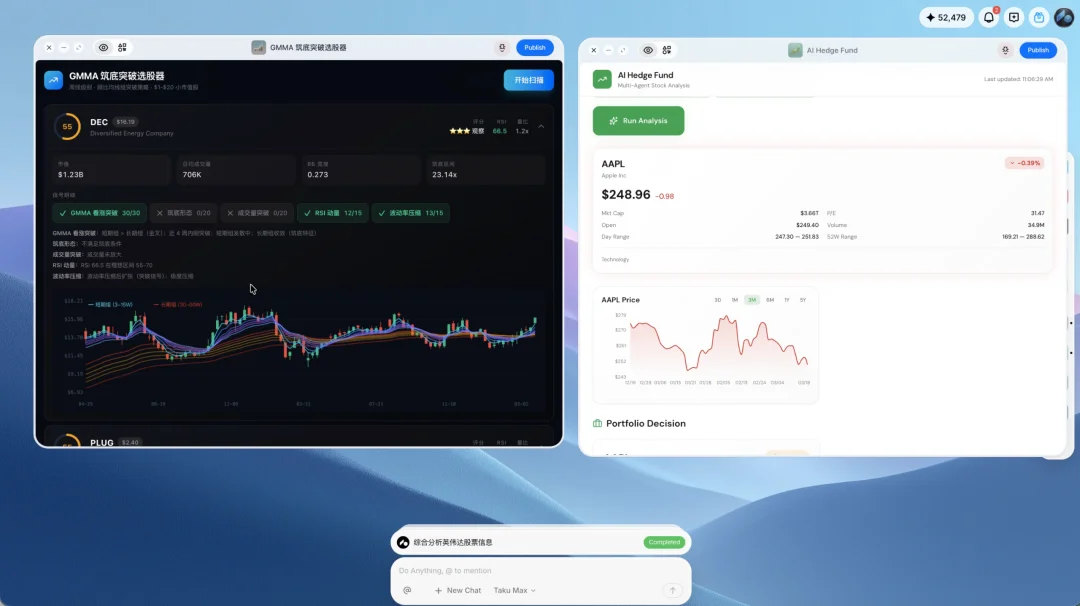
AI Hedge Fund 与量化选股器串联
中间有一层转义层来处理不同后端之间的数据结构差异。Austin 说这个做了大概两三个月
这个 Protocol 也带来了一个延伸的可能性
Austin 提到,如果一个量化基金的交易员有自己的交易策略,他可以把这个策略封装成一个 Taku 里的软件后端,原子化地分发出去
别人拿到之后可以在上面调参数,按使用次数付费
代码本身不再稀缺,稀缺的是代码背后承载的专业知识过去想分发软件能力,你需要是一个开发者。以后可能只需要某个特定领域的 knowledge
VIDEO · 组装后端能力
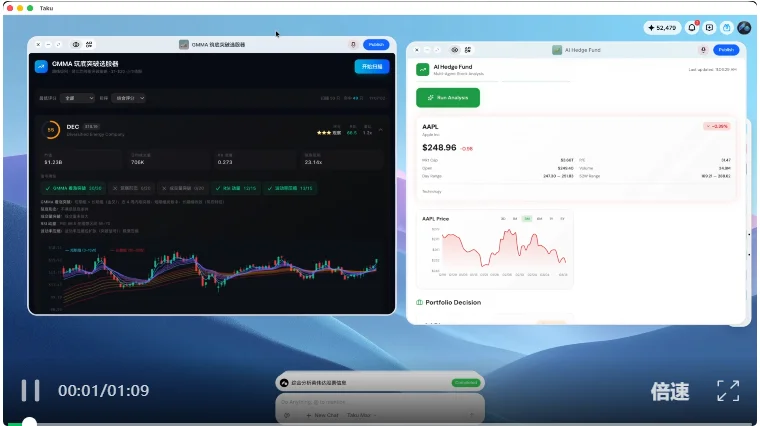
屏幕上同时打开了两个金融分析软件。左侧是一个纯代码驱动的「量化选股策略器」(负责计算和走势图),右侧是一个「AI Hedge Fund」(通过多智能体进行情感分析和信号预测)
在底部的全局对话框中输入指令,要求「综合这两个软件的信息和功能」
AI 直接识别并调用了两个独立软件的后端接口,将量化数据与多智能体分析结果串联融合,在统一界面中输出了综合分析报告
你在某个应用里积累的数据、使用习惯、定义的规则,会自动同步给所有相关的应用
Austin 给我看了一个例子
有用户在 Taku 里做了一个咸鱼风格的写作工具,Taku 先把这个工具里的能力抽象成了一个 skill。后来这个用户又上传了一批咸鱼的文章,做了一个知识图谱
这时候 Taku 自动识别到「这也是关于咸鱼的」,然后把写作工具里的 skill、知识图谱里的数据、以及所有相关的 Agent 和 APP,全部 update 了一遍
结果是这个写作工具生成内容的「咸鱼味」比之前浓了很多
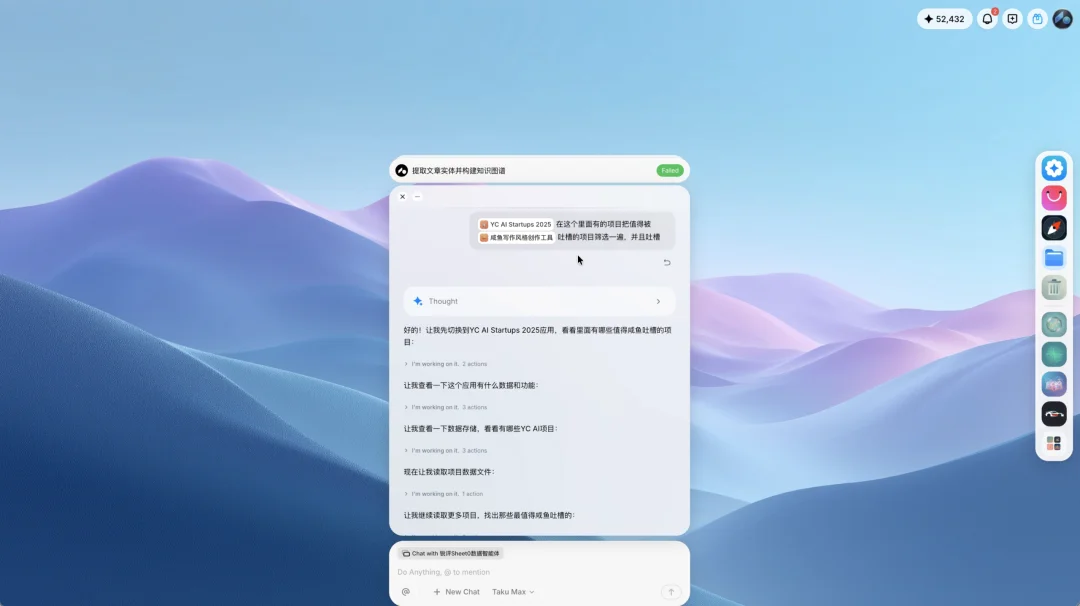
咸鱼写作工具与知识图谱的 context 共享
这三层加在一起的效果是:用户在 Taku 里用得越久,跨应用的 context 积累越厚
不同的工具之间会持续地互相喂数据、互相迭代。你在写作工具里新增的素材,会影响到知识图谱的更新;知识图谱的变化,又会反过来让写作工具的输出更准确
Austin 说,这也是 OpenClaw 或者纯 Claude Code 产品做不了的
每个项目的记忆是孤立的,你在项目 A 里积累的东西,项目 B 看不见
VIDEO · 跨 APP 跨 Agent 的 context 共享与自主持续迭代
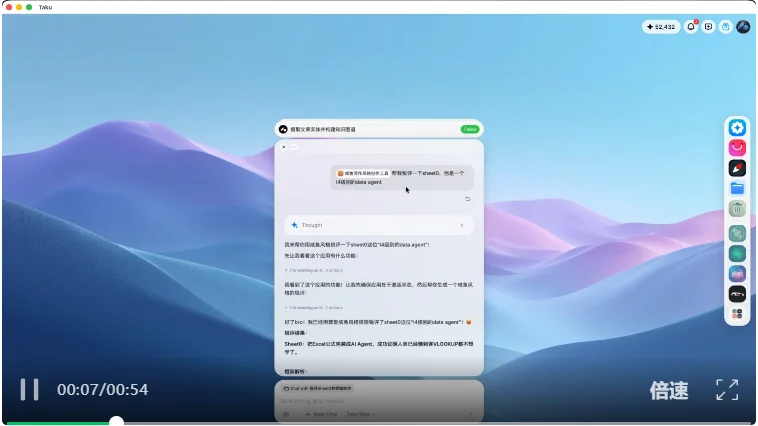
这是一个用「咸鱼吐槽风格」写文章的 AI Agent,起初吐槽不够精准。然后进行了一个看似不相关的操作:丢给 AI 一堆关于咸鱼的文章,让它做一个知识图谱
系统在后台自主完成了跨应用的记忆更新:AI 在整理知识图谱时提取到了关于咸鱼的深层知识,并自动同步到了那个吐槽 Agent 的上下文中,不需要人类显式地命令它去更新
再次要求用咸鱼风格吐槽 Lovable 时,生成的文案变得非常精准、深刻且阴阳怪气。能力得到了显著的进化
Austin 是个连续创业者,加拿大长大,大三做了个男性化妆品品牌叫 Faculty,做到 200 万美金营收之后被雅诗兰黛收购
之后在国内做过 GPU 云游戏(奇绩创坛投的),转型做了 AI 训练 Infra,服务过 MiniMax 等公司,作为联合创始人做了 Sapient Intelligence,拿过 2200 万美金种子轮
现在这个项目,团队规模很小,目前还没有融资
至于为什么做这个,要从 2024 年底谈起,当时 Austin 的日本投资人跟他说,日本最大的 AI 需求是一个 terminal level 的 coding agent。当时 Claude Code 还没出来,市面上没有好的方案
Austin 就带团队从 0 搭了一个
但到了年中, Claude Code 发布了。同期 Bolt.new 这类产品选择直接在云上封装 Claude Code,增长非常快
Austin 面前有两个选择:跟着封装,或者继续自己搭底层,他选择了后者
如果底层 coding engine 是别人的,你改不了后端架构
封装 Claude Code 的产品,在生成单个应用这件事上可以做得很好,但在应用之间的串联和协作上,会受限于 Claude Code 本身的架构
Austin 聊到一个他觉得有意思的张力
Claude Code 是为开发者设计的,它的逻辑是项目之间默认隔离。对开发者来说这完全合理,毕竟:默认帮我把两个项目的权限打通,万一出了安全问题怎么办?
所以 Claude Code 大概率会继续沿着「更好地服务开发者」这条线走,项目隔离的设计不会变
但普通人的需求正好反过来。普通人不想管权限、不想配接口,他就想说一句话让几个工具自己协作起来
对开发者来说,默认打通权限是危险的。对普通人来说,默认隔离一切是麻烦的。同一件事,两群人的需求正好反过来
Austin 和他的团队在做的,大概就是这个方向
Taku 目前还在测试阶段。可以去申请 waiting list,能不能通过是另一码事了
taku.ai
文章来自于“赛博禅心”,作者 “金色传说大聪明”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
