# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。
一篇论文搅动万亿市场,存储芯片的天塌了...
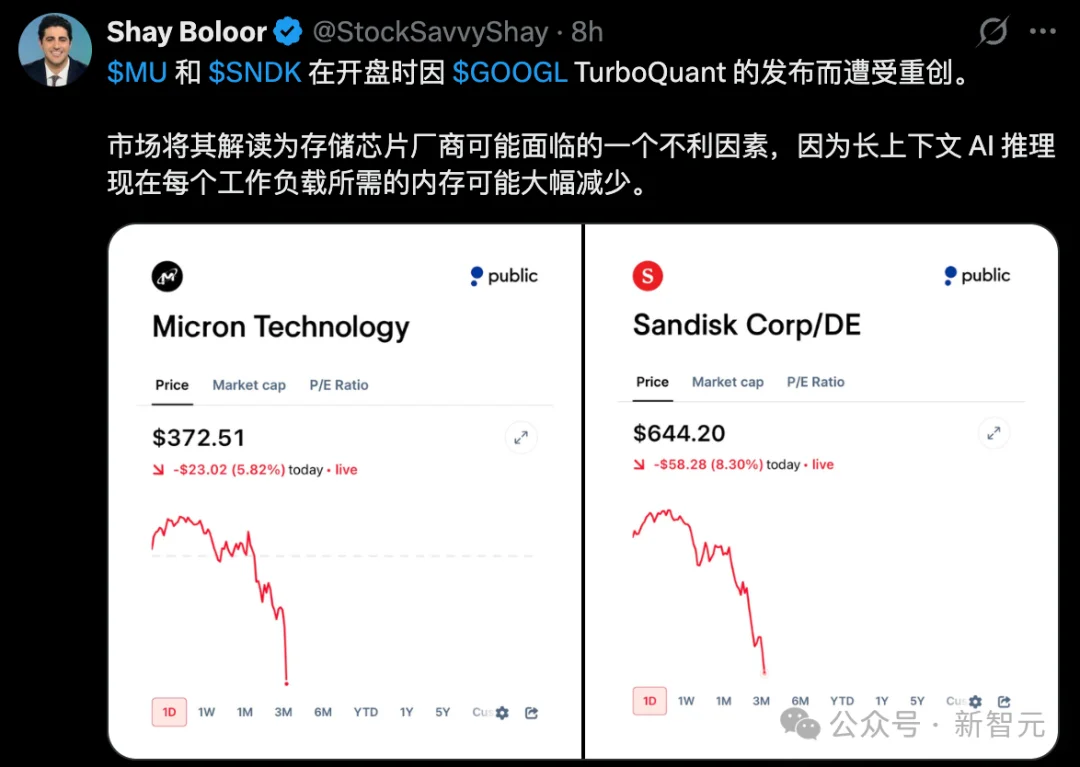
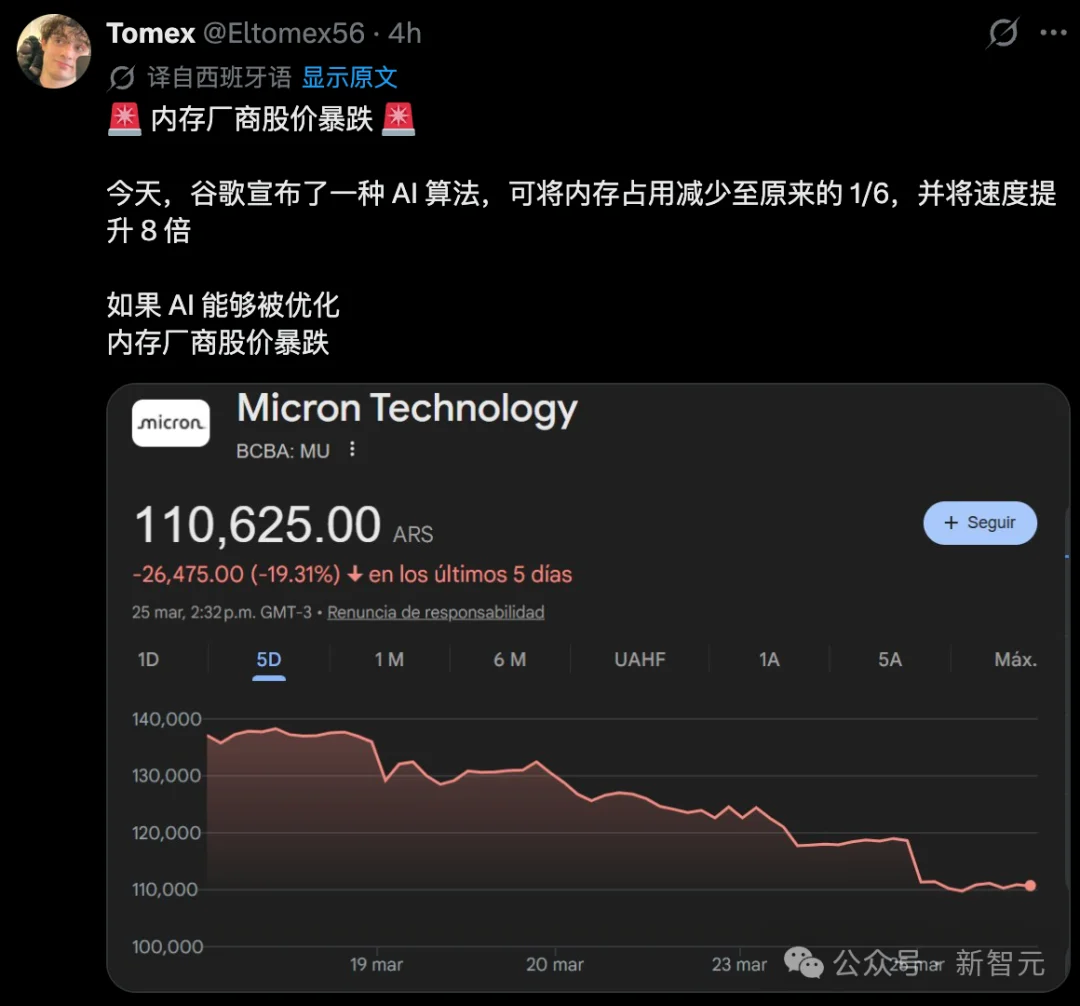
谁也未曾料到,本周三美股开盘,存储芯片板块遭遇「黑色时刻」,巨头股价全线飘绿——
截至收盘,美光科技下跌4%,西部数据下跌4.4%,希捷下跌5.6%,闪迪更是重挫6.5%。
引发这场抛售地震的导火索,正是谷歌发布的TurboQuant压缩算法。
众所周知,大模型跑起来时,KV缓存(KV cache)简直是内存界的「吞金兽」。
为了不重复计算之前的Token,LLM维持一份「运行记忆」,随着对话越来越长,这份记忆会像滚雪球一样迅速膨胀。
谷歌的TurboQuant,给出了一套极其「暴力」的瘦身方案:
首先,把KV缓存里的高维向量做一次「旋转」,再换一套极坐标系来描述,内存开销直接归0。
然后,用仅仅1-bit额外空间,放一个数学「校正器」进去,把压缩带来的系统性偏差精确抹平。

TurboQuant论文将于下月举办的ICLR 2026上正式发表
结果非常顶:不用任何重训,TurboQuant把缓存压缩至丧心病狂的3-bit。
这么一来,KV缓存开销骤降6倍,关键是,推理表现几乎零损耗。
在H100上,相较于32-bit基线,4-bit的计算注意力速度飙升了8倍。不仅省空间,还跑得更快了。
一时间,全网陷入疯狂。照这样说,16GB Mac mini又能用来跑大模型了。

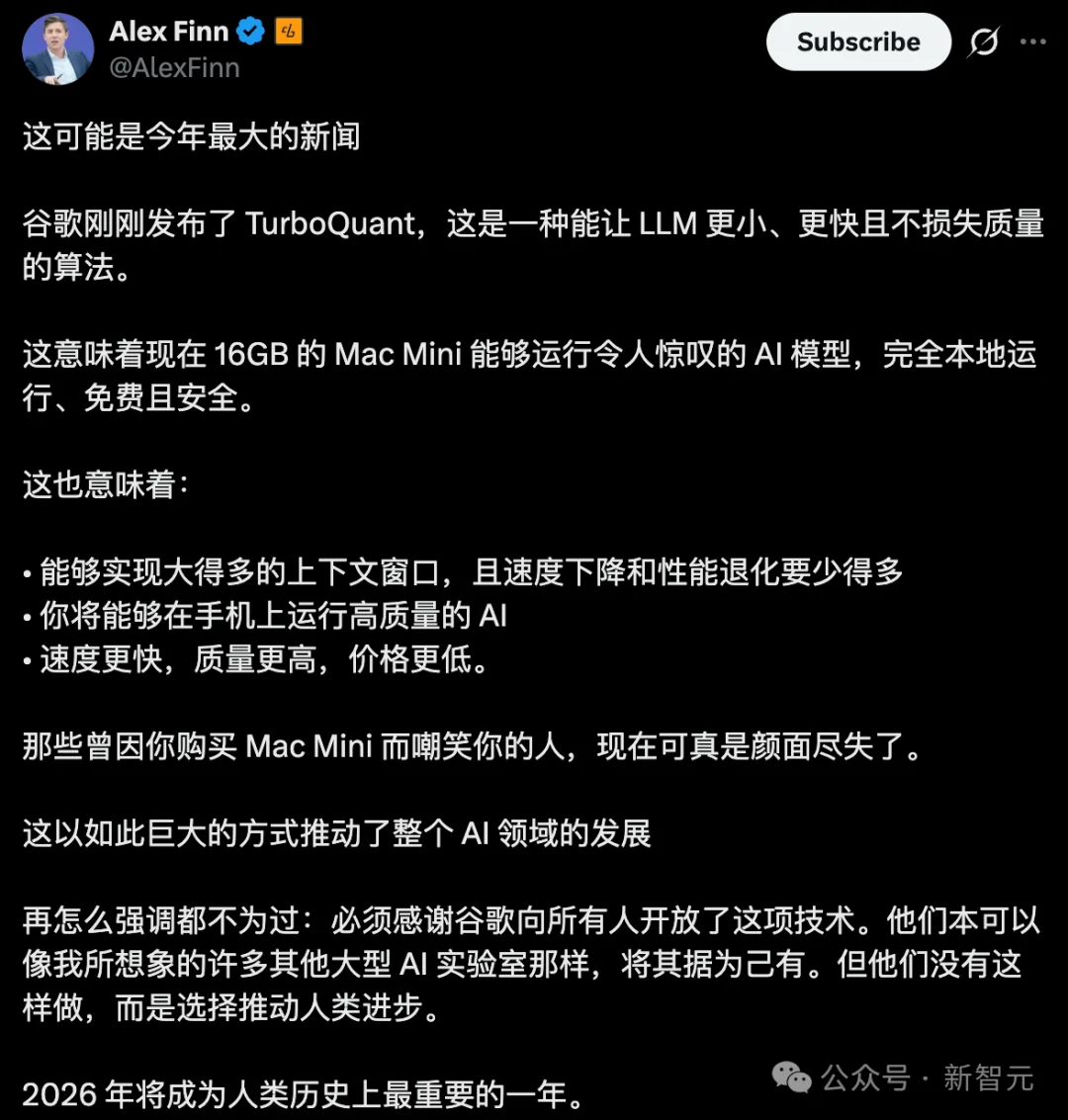
这一幕,现实版「魔笛手」(Pied Piper)真的降临了!


对于芯片存储巨头来说,这无异于一场「底层逻辑大地震」。
美光、西数等巨头的估值基石,向来建立在「AI服务器单机容量红利」之上。
一旦单次推理任务的比特(Bit)需求发生结构性骤降,高性能存储的增长动能将直接面临「缩水」危机。

直白讲,谷歌TurboQuant出世,直接冲击了芯片存储巨头们,备受追捧的AI硬件逻辑。
KV缓存暴降6倍,速度提升8倍,意味着每台服务器所需的高端内存芯片可能变少。

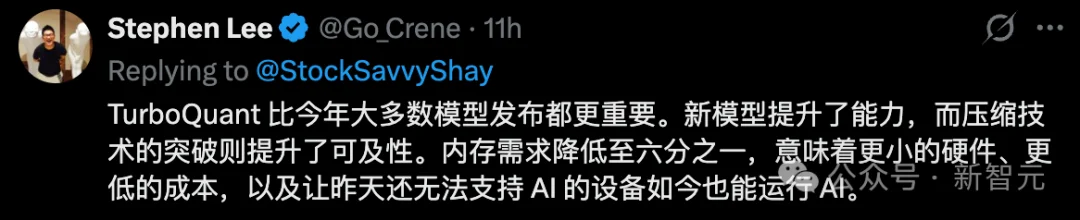
Cloudflare首席执行官Matthew Prince甚至将其形容为「谷歌的DeepSeek时刻」!

要理解TurboQuant的分量,先得搞清楚它瞄准的靶心——KV缓存到底有多吃内存。
大模型生成每一个Token时,都要「回看」之前所有Token的信息。
为了避免重复计算,模型把每一层注意力机制产出的Key和Value向量全部缓存起来,形成一张高速「速查表」。
问题在于,这张表随对话长度线性膨胀。
当上下文从4K扩展到128K甚至百万级别,KV缓存吞掉的显存往往反超模型参数本身,成为推理阶段最大的内存瓶颈。
传统的解法是向量量化,也就是把16-bit浮点数压缩成4-bit整数。
但几乎所有传统方法都需要为每一小块数据额外存储一组全精度的量化常数,每个数字多吃1到2个bit。
压到4-bit,实际可能是5到6-bit,压缩的意义被自己的「手续费」蚕食了一大截。
而TurboQuant的野心,正是彻底消灭这笔附加费。

论文地址:https://arxiv.org/pdf/2504.19874
TurboQuant的核心,是一个精巧的两阶段流程。
第一阶段:PolarQuant换一个坐标系看世界
传统量化在笛卡尔坐标系(X、Y、Z轴)下操作,每个轴的取值范围不固定,必须额外存储归一化参数来「对齐」。
换句话说,每一小块数据都要自带一张「比例尺」,而这张比例尺本身就很占空间。
PolarQuant的第一步,是对数据向量做一次随机旋转。
这一步看似随意,背后的数学意义却很深:在高维空间里,随机旋转会让向量的每个坐标分量收敛到一种高度集中的Beta分布,而且各分量之间近似独立同分布。
不管原始数据长什么样,转完之后,统统变成「一个模子刻出来的」。

PolarQuant就像一座高效的压缩桥梁,能把笛卡尔坐标输入转换成紧凑的极坐标「速记」形式,方便后续的存储和处理
这让复杂的高维量化问题,降格为一组简单的一维标量量化问题。
谷歌只需要提前算好不同位宽下的最优码本,推理时直接查表即可,不需要为每一组数据单独计算任何东西。
然后,PolarQuant把旋转后的向量「笛卡尔坐标系」转换成「极坐标系」。
举个栗子,传统方法描述一个位置:向东走3个街区,再向北走4个街区。PolarQuant则说:朝37度方向直接走5个街区。
转换之后,数据被拆成两组信息:一个半径(代表信号强度),一组角度(代表信号方向)。
接下来才是真正精妙的一步,即「递归配对」。
PolarQuant把坐标两两分组进行极坐标变换,得到一组半径和一组角度;再把这些半径两两配对,做第二轮极坐标变换;如此递归往复,最终整个高维向量被浓缩为一个最终半径和一系列描述性角度。
因为角度的分布模式在数学上是已知且高度集中的,整个过程不需要存储任何归一化常数。
开销,归零。
这一步消耗了绝大部分的压缩预算(分配b-1个bit),专注于把均方误差(MSE)压到最低,精准捕捉原始向量的核心信息。
第二阶段:QJL用1 - bit消灭残余误差
再精准的压缩,也会留下误差。
而且这里有个隐蔽的陷阱:一个在MSE意义上最优的1-bit量化器,在高维空间中会引入一个2/π的乘性偏差。
也就是说,你把数据压得很小、失真也很低,但用它算内积(注意力分数的核心操作)时,结果是系统性偏斜的。
TurboQuant的第二步,专门来「杀」这个偏差。
它将Johnson-Lindenstrauss变换应用到第一阶段的残余误差上,把每个误差值压缩为一个符号位:+1或-1。
然后配合一个特殊的估计器——用高精度的Query向量和低精度的压缩Key做联合计算。
这套组合拳,在数学上被证明是「无偏」的:压缩前后的内积期望值严格相等。
只消耗最后1个bit,就把第一阶段残留的系统性偏差彻底抹平。
两步合璧的效果
TurboQuant在仅仅3-bit的总预算下,实现了接近无损的压缩效果,全程零额外开销。
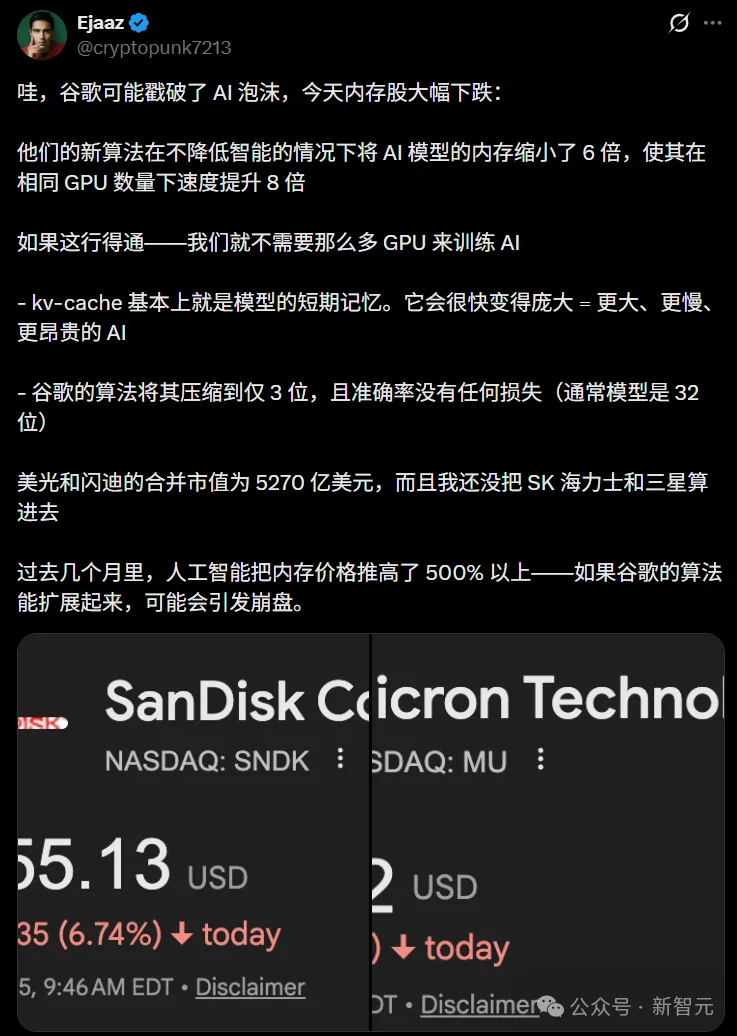
论文给出了严格的理论证明:TurboQuant的MSE失真率,在所有位宽下都控制在理论绝对下限的约2.7倍以内。在1-bit极端压缩的情况下,更是只有最优值的约1.45倍。
换句话说,它几乎贴着信息论的「物理极限」在运行。
整套算法是「数据无感知」(data-oblivious)的——不需要任何校准数据,不依赖任何预训练,对数据集零假设。
同时,算法内部全程使用向量化运算,避免了传统方法中缓慢的二分查找,对GPU加速器极其友好。
拿来即用,即插即飞。
光说原理不够,得看实战。
谷歌在LongBench、Needle In A Haystack、ZeroSCROLLS、RULER和L-Eval五大长上下文基准测试上,对TurboQuant进行了严格验证,测试模型覆盖Gemma、Mistral和Llama-3.1-8B-Instruct。
结果相当硬核。
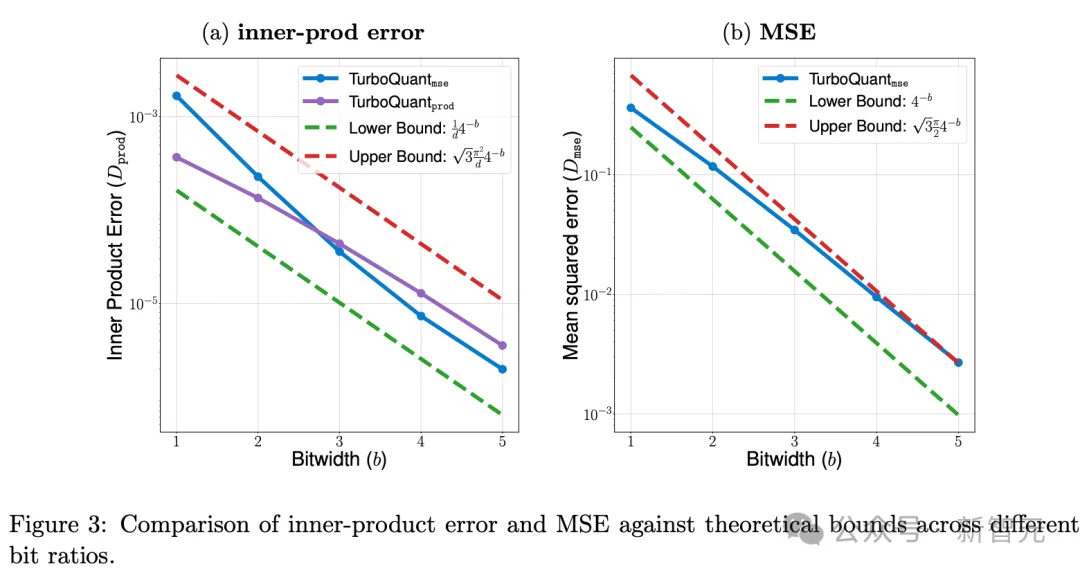
在LongBench的问答、代码生成、文本摘要等综合任务中,3-bit配置下的TurboQuant,性能全面优于KIVI等基线方法,甚至逼近全精度模型的表现。
最残酷的考验来自「大海捞针」——在10万Token的文本海洋里,精准捞出一句特定信息。
在4倍压缩比下,TurboQuant的检索精度一路保持到10.4万Token,与全精度模型完全一致。6倍压缩之后,模型该记住的,一个字都没丢。
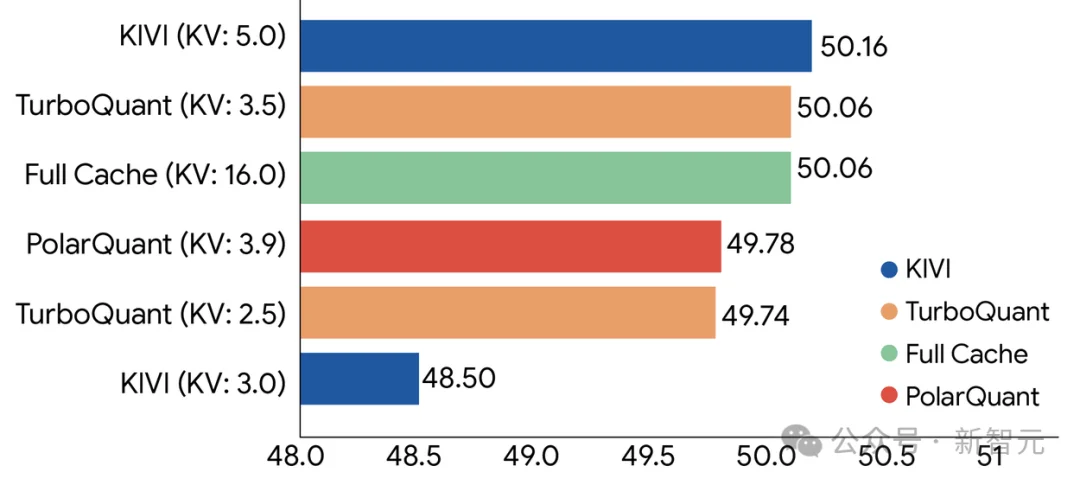
在H100 GPU上,4-bit TurboQuant计算注意力logits的速度,相比32-bit未量化基线提升了8倍。
需要说明的是,这个8倍是注意力计算环节的加速比,并非端到端推理的整体提速,但注意力计算恰恰是长上下文推理中最吃资源的那一环。
谷歌特别强调,TurboQuant引入的运行时开销「几乎可以忽略不计」。
这也好理解——算法本身不涉及任何数据集相关的查表或搜索操作,纯粹是矩阵运算,天然适合GPU并行。
在高维向量搜索方面,TurboQuant也没有放过对手。
在GloVe数据集(200维)上,它击败了PQ和RabbiQ两大前沿方法,拿下最优1@k召回率。而那些对手还依赖庞大的密码本和针对性调优,TurboQuant全程「裸奔」通杀。
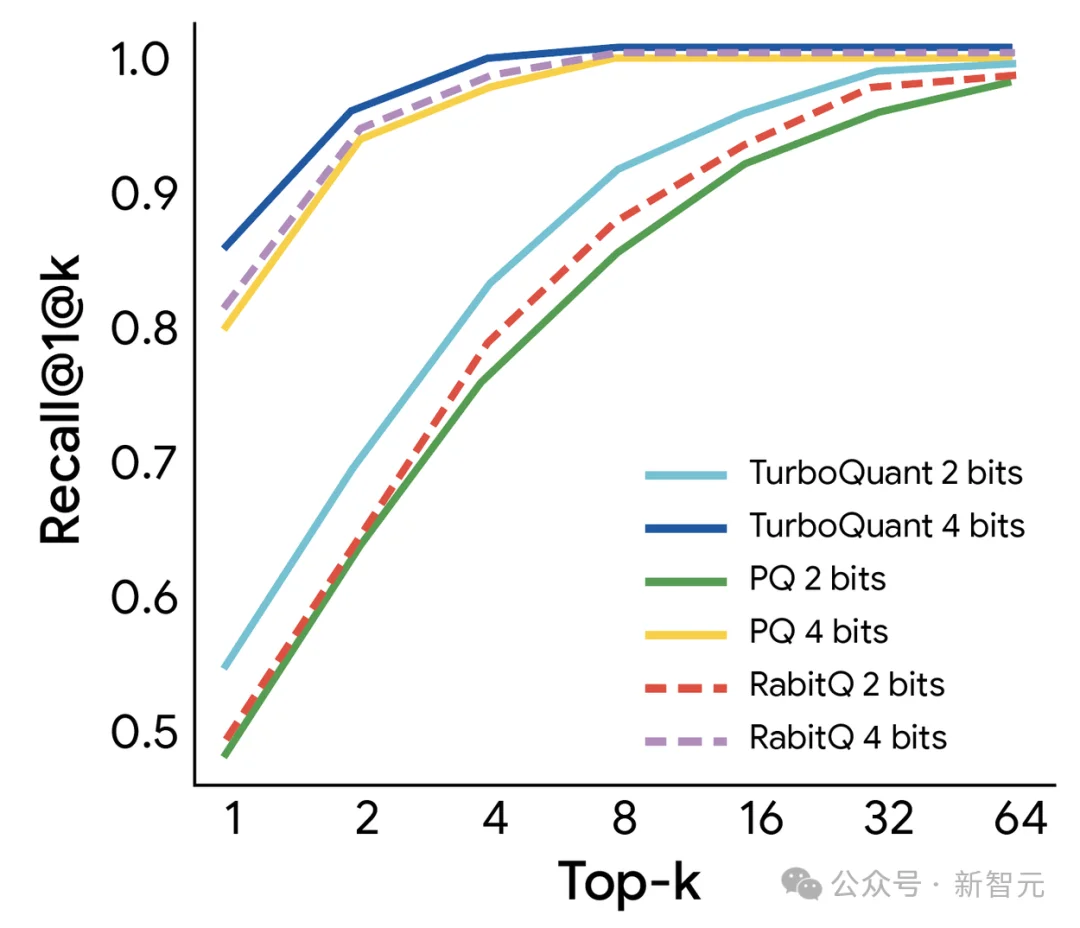
这个结果的含金量在于:向量搜索是谷歌搜索、推荐系统、广告系统等核心产品的底层引擎。
TurboQuant在这个赛道上的优势,意味着它不只是一个学术玩具,而是有明确的工程落地路径。
博客官宣这天,独立开发者在Reddit上晒出了复现成果:
基于PyTorch和自定义Triton kernel,在RTX 4090上用2-bit精度跑Gemma 3 4B,输出与未压缩版本逐字符一致。
论文写的「零损耗」,社区用代码投了票。

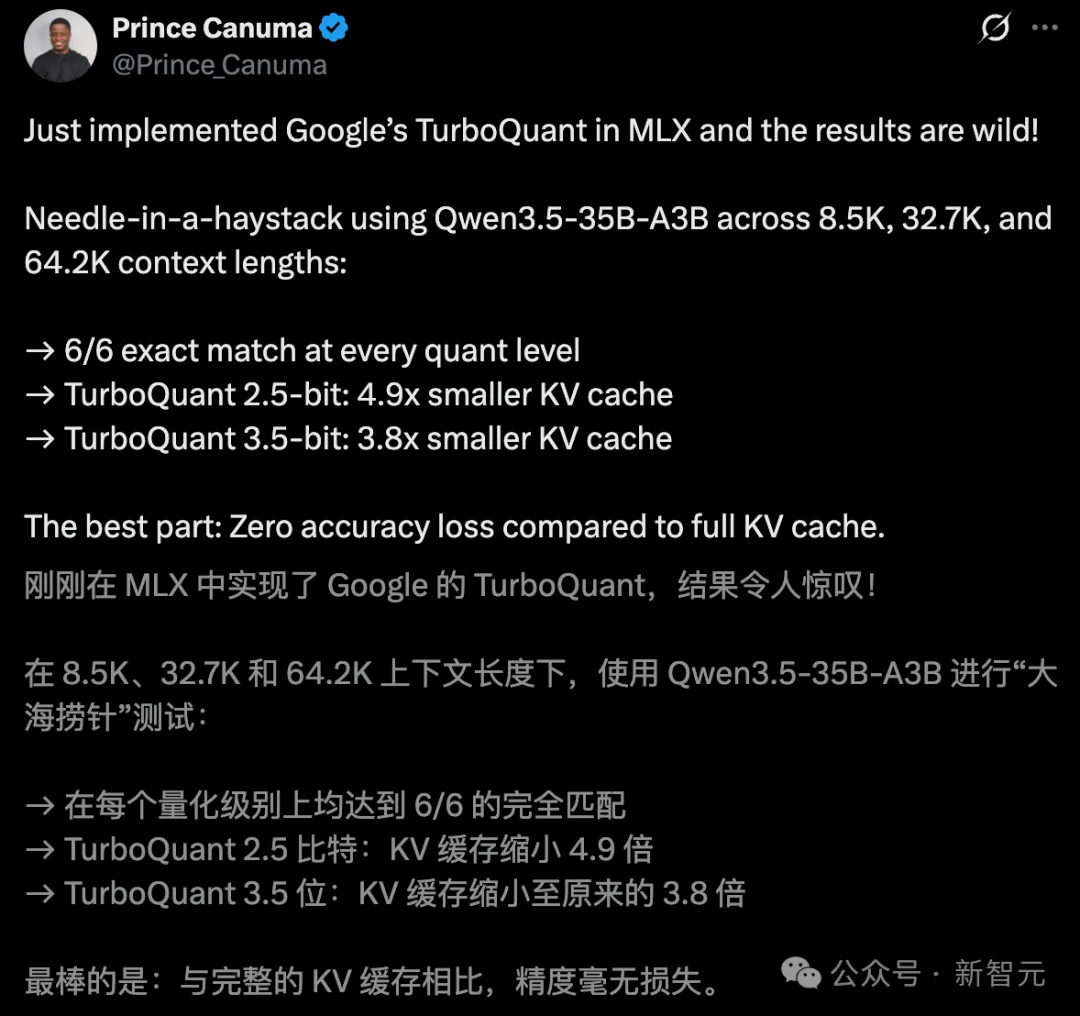
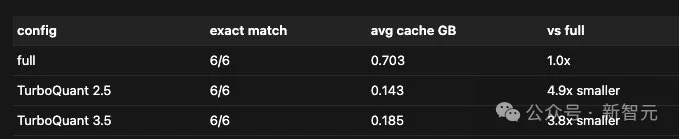
另一位开发者Prince Canuma实测后惊叹道:「面对8.5K到64.2K不等的大跨度上下文,TurboQuant让模型对显存实现极致压缩」。
2.5-bit量化让KV缓存缩小了4.9倍;3.5-bit量化也实现了3.8倍的缩小。
存储芯片的天,真的塌了吗?大概率没有。
科技行业有一条反复被验证的铁律——杰文斯悖论:资源使用效率越高,总消耗量反而越大。
KV缓存压缩6倍,最可能的结果不是少买内存,而是同样的显存跑更长的上下文、更多的并发、更大的模型。
虽然压缩算法还从未从根本上改变过采购量,但有两件事确实在发生改变。
第一,推理成本的地板价被改写了。
TurboQuant的三篇论文将在ICLR 2026和AISTATS 2026上公开发表,核心思想向全行业敞开。
当3-bit能做到过去16-bit的事情,受益的是每一个做推理服务的公司,感到压力的是那些指望「量价齐升」永远持续的存储厂商。
第二,从论文到落地的路正在缩短。
TurboQuant目前仅在8B参数级别的开源模型上得到验证,70B以上的模型、MoE架构、百万级上下文窗口上的表现尚未证实。
谷歌也没有宣布它已部署到Gemini或任何生产系统中。
这次谷歌博客一发出,不到24小时,就有独立开发者从论文出发写出了完整实现并跑通验证。
在算力军备竞赛里,最锋利的武器未必是更大的芯片,也可能是更聪明的数学。
技术不关心股票代码,只关心比特的边界在哪里。
参考资料:
https://arstechnica.com/ai/2026/03/google-says-new-turboquant-compression-can-lower-ai-memory-usage-without-sacrificing-quality/
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
https://x.com/StockSavvyShay/status/2036799431144804648?s=20
https://x.com/rohanpaul_ai/status/2036883872680640520?s=20
https://techcrunch.com/2026/03/25/google-turboquant-ai-memory-compression-silicon-valley-pied-piper/?utm_medium=organic_social&utm_source=TWITTER
文章来自于“新智元”,作者 “好困 桃子”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
