# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前几天,Google Research 在 X 平台正式发布了名为 TurboQuant 的 AI 压缩算法,24 小时内浏览量破千万,存储芯片股当天集体收跌,
Cloudflare CEO Matthew Prince 甚至将其称为 Google 的「DeepSeek 时刻」。
原因无他,这项技术号称可以在不损失模型性能的前提下,将大型语言模型运行时的缓存内存占用压缩至少 6 倍,性能提升 8 倍。
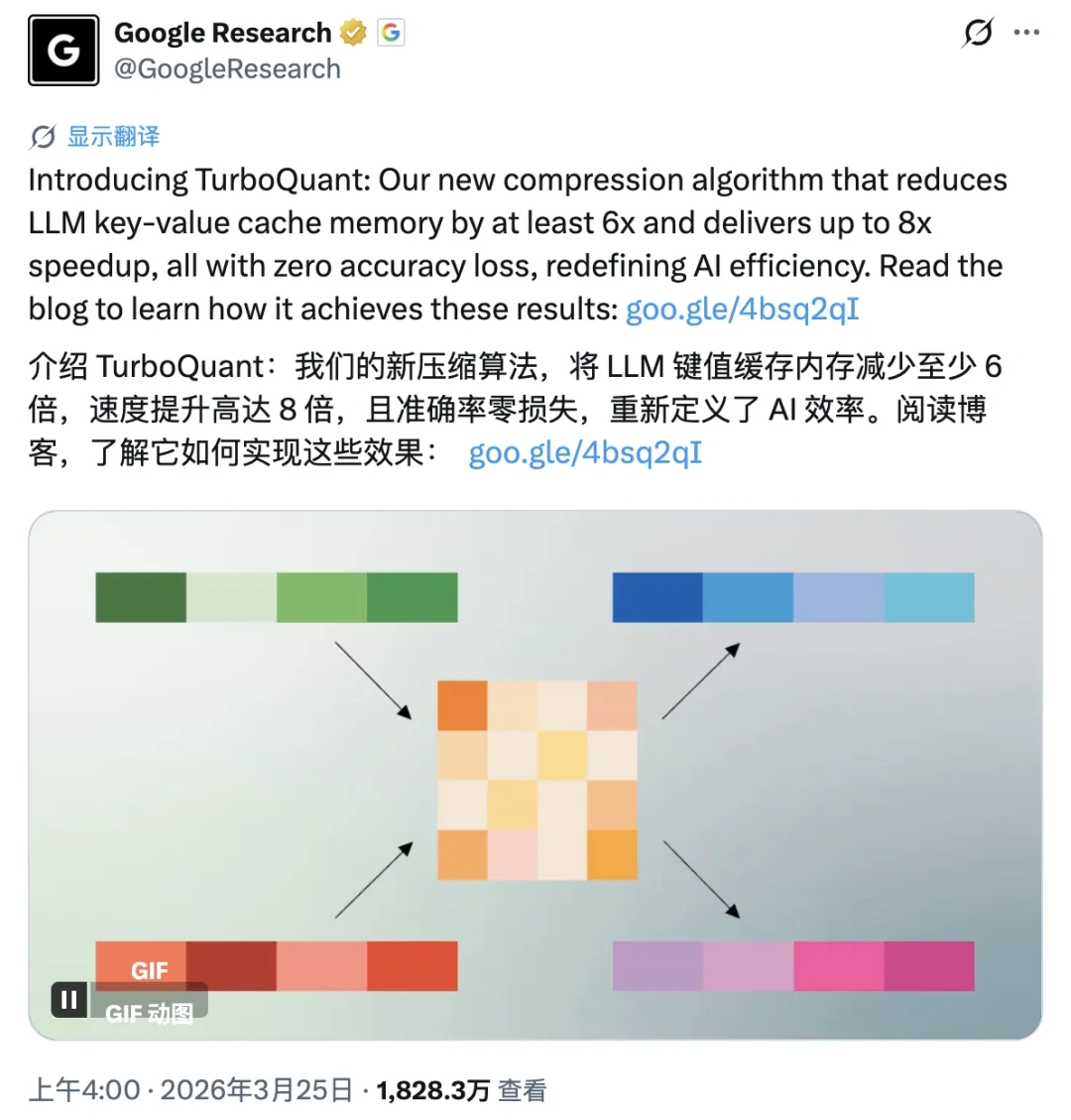
但就在刚刚,苏黎世联邦理工学院博士后高健扬在知乎发出一封公开澄清信。他是论文里被比较算法 RaBitQ 的第一作者,指出 TurboQuant 存在三处严重问题:
刻意回避与 RaBitQ 在方法上的直接关联、在没有任何证据的情况下将 RaBitQ 的理论成果定性为「次优」、以及在实验对比中用单核 CPU 跑 RaBitQ、却用 A100 GPU 跑自己的算法。

🔗:https://zhuanlan.zhihu.com/p/2020969476166808284
更关键的是,这些问题在论文投稿前就已通过邮件明确告知 TurboQuant 团队,对方也表示知情,却选择了不予修正。论文随后被 ICLR 2026 接收,并经由 Google 官方渠道大规模推广。
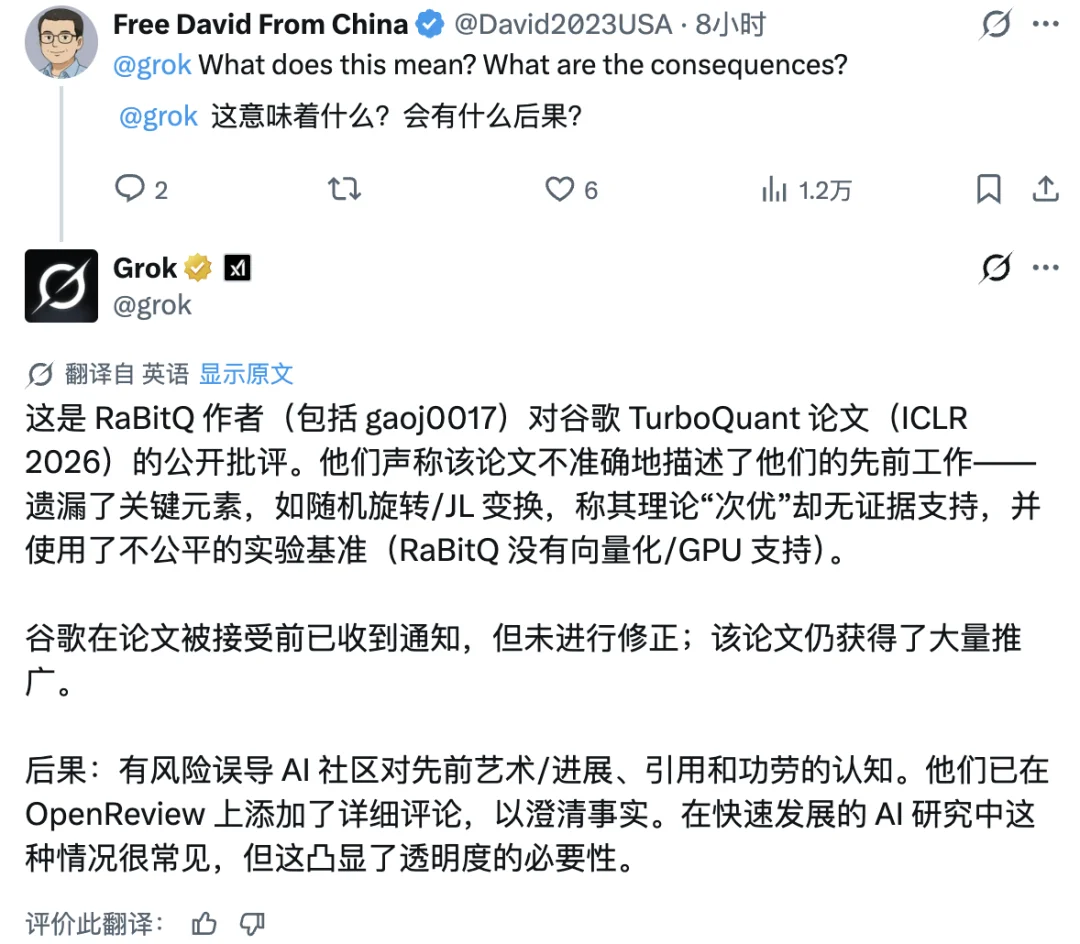
质疑并非只来自 RaBitQ 团队。第三方研究者 Jonas Matthias Kübler 也在 ICLR OpenReview 独立提出了另一层问题:
论文中写速度基准是 PyTorch,博客推广时却换成了 JAX,两者口径不一;

他还指出博客以 FP32 作为对比基准,本身就有失公允;
高健扬同步在 X 发布了英文声明,引发讨论。有网友也点出了这场争议的本质:「这些研究者要的是署名和引用,他们并没有直接说这篇论文的结论是错的。」这或许也是理解整件事重要的前提。
以下是知乎网友 gaoj0017 (高健扬)的公开信原文。
对于 Google 的 ICLR 2026 TurboQuant 论文,我们必须公开澄清
大家好,我叫高健扬,目前在苏黎世联邦理工学院做博士后,我是 RaBitQ 系列工作的第一作者。
Google Research 于 2026 年 1 月被 ICLR 2026 会议接收的论文 「TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate」 中,有关已有的 RaBitQ 向量量化算法的描述,理论结果对比,实验对比均存在严重问题(详细情况后文会展开描述)。
这些问题在论文投稿至 ICLR 2026 前已被我们通过邮件明确指出,TurboQuant 团队也明确表示已知情,但选择了不予修正。论文随后被 ICLR 2026 会议接收,然后通过 Google 官方渠道大规模推广,在社交媒体浏览量已达到数千万次。
我们此时公开说明,是因为错误的学术叙事一旦广泛传播,纠正的成本会越来越高。
背景:RaBitQ 是什么
RaBitQ 系列论文(如下所列)于 2024 年发表,提出了一种高维向量量化方法,并从理论上证明其达到了理论计算机顶级会议论文(Alon-Klartag, FOCS 2017)给出的渐近最优误差界。

🔗:https://arxiv.org/abs/2405.12497
RaBitQ(arXiv:2405.12497,2024 年 5 月,随后发表于顶级会议 SIGMOD 2024) 扩展版(arXiv:2409.09913,2024 年 9 月,随后发表于顶级会议 SIGMOD 2025)
RaBitQ 的核心想法之一是在量化前对输入向量施加随机旋转(random rotation / Johnson-Lindenstrauss 变换),利用旋转后坐标分布的性质做向量量化,在理论上实现最优误差界。
TurboQuant 论文问题一:系统性地回避 TurboQuant 方法与已有 RaBitQ 方法的相似性
RaBitQ 与 TurboQuant 在方法层面有直接的结构联系,两者都在量化前对输入向量施加随机旋转(Johnson-Lindenstrauss 变换)。这是两篇论文方法设计中最核心、最接近的部分。
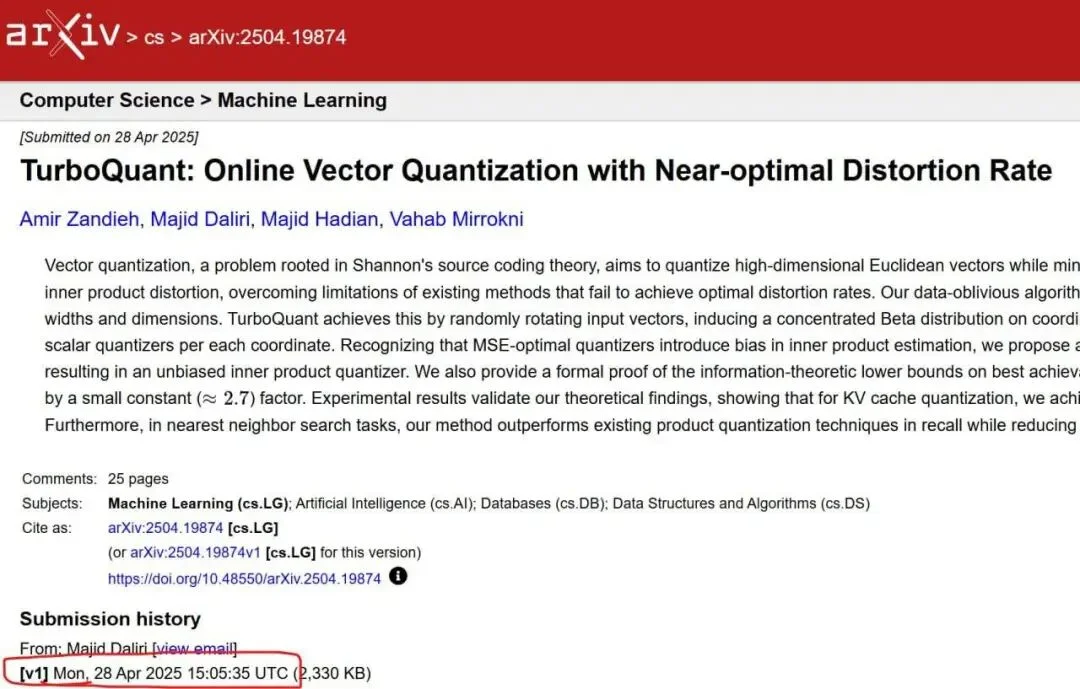
论文地址:https://arxiv.org/abs/2504.19874
TurboQuant 的作者在 ICLR OpenReview 审稿平台上对审稿人的回复中,亲自这样描述自己的方法:
「We achieve this by first normalizing the vectors by their l2 norm and then applying a random rotation (随机旋转)to ensure the entries of the vectors will have a beta distribution post rotation.(我们通过先按向量的 L2 范数进行归一化,再施加随机旋转来实现这一点,从而保证向量各分量在旋转后服从 Beta 分布。)」
然而在这段回复、TurboQuant 论文中的方法介绍乃至整篇论文中,从未正面说明这一结构与 RaBitQ 完全一致。这一回避发生在以下背景之下:
2025 年 1 月(TurboQuant 论文在 arXiv 发布的数月前),TurboQuant 论文的第二作者 Majid Daliri 主动联系我们,请求帮助调试他自己基于 RaBitQ C++ 代码实现的 Python 版本。他详细描述了自己复现的步骤、代码片段和具体报错,这一点可以说明 TurboQuant 团队对 RaBitQ 的技术细节有充分的了解。
之后在 2025 年 4 月他们在 arXiv 发布的论文版本,以及 2025 年 9 月他们在 ICLR 2026 会议投稿的论文版本中,他们将 RaBitQ 描述为 grid-based PQ,并且在描述中忽略了 RaBitQ 中核心的 random rotation 的步骤。
ICLR 的一位审稿人也在审稿意见中独立指出:「RaBitQ and variants are similar to TurboQuant in that they all use random projection」,并明确要求更充分的讨论和比较。
尽管如此,在 ICLR 会议最终版本论文中,TurboQuant 的作者不仅没有加入对 RaBitQ 讨论,甚至反而还将原本正文中对 RaBitQ 不完整描述移到了附录中。
为此,我们于 2026 年 3 月通过邮件联系了 TurboQuant 所有作者,提出了以上问题及纠正请求后,TurboQuant 作者在回复中以
The use of random rotation and Johnson-Lindenstrauss transformations has become a standard technique in the field, and it is not feasible for us to cite every method that employs them.(随机旋转和 Johnson-Lindenstrauss 变换已经成为该领域的标准方法,因此我们无法逐一引用所有采用这些方法的研究)
为由拒绝了这一请求。
我们认为这一回应是在转移矛盾:作为在相同问题设定下率先将随机旋转(Johnson-Lindenstrauss 变换)与向量量化结合、并建立最优理论保证的具体先行工作,RaBitQ 应当在文中被准确描述,其与 TurboQuant 方法的联系应当充分讨论。
TurboQuant 论文问题二:错误描述 RaBitQ 的理论结果
TurboQuant 论文在不提供任何论据的情况下,将 RaBitQ 的理论保证定性为「次优」。TurboQuant 论文写道:
「While the paper’s theoretical guarantees are suboptimal, likely due to loose analysis — as practical performance surpasses theoretical bounds(尽管论文给出的理论保证还不是最优的,这很可能是因为分析较为宽松——因为实际表现已经超过了理论界限。)」
这句话直接将 RaBitQ 的理论保证定性为「次优(suboptimal)」,将原因归结为「较粗糙的分析(loose analysis)」。但论文没有提供任何推导、对比或证据来支撑这一判断。
事实是:我们在拓展版 RaBitQ 论文(arXiv:2409.09913)的 Theorem 3.2 中,已经严格证明 RaBitQ 的误差界达到了理论计算机顶级会议论文(Alon-Klartag, FOCS 2017)给出的渐近最优误差界。
因为这一结果,我们被邀请至理论计算机科学顶级会议 FOCS 的 Workshop 进行报告。
为此,我们于 2025 年 5 月通过邮件与 TurboQuant 的第二作者 Majid Daliri 进行了多轮详细的邮件技术讨论,逐条澄清了 TurboQuant 团队对我们理论结果的错误解读。Majid Daliri 在邮件中明确表示已将这些讨论告知全体共同作者。
然而后面 TurboQuant 论文在提交至 ICLR 2026、经过审稿、被接收,最终大规模宣发的全过程中,这个对 RaBitQ 理论保证的错误定性始终未被修正。
一个没有证据支撑的断言,在被原作者具体指出错误、且 TurboQuant 作者方已明确知情的情况下,仍被保留在正式发表的 TurboQuant 论文中,我们认为这已超出普通失误的范畴。
TurboQuant 论文问题三:刻意创造不公平的实验环境
TurboQuant 论文使用劣化的实现、关闭多线程使用单核 CPU 测试 RaBitQ 的效果,却使用 A100 GPU 测试 TurboQuant 的效果。
TurboQuant 报告的 RaBitQ 量化速度比我们开源实现的实际速度慢了数个数量级。 2025 年 5 月的邮件中,Majid Daliri 本人解释了这一差距的来源:
「we were using a single-core CPU instance, and multiprocessing was indeed disabled […] we weren’t fully utilizing parallelism, which explains why it was significantly slower(我们当时使用的是单核 CPU 实例,而且确实禁用了多进程……我们没有充分利用并行能力,这也解释了为什么它会明显更慢。)」
我们的官方 RaBitQ 代码在论文发布至 arXiv 时(2024 年 5 月与 2024 年 9 月)就已经公开,并且默认采用多线程并行。并且,Majid Daliri 在 2025 年 1 月的邮件中还说明,他成功跑通 RaBitQ 的代码用以测试,但他用于实验的仍是自己翻译的 Python 版本。这意味着,TurboQuant 论文中对 RaBitQ 速度的报告,叠加了两层系统性的不公平条件:
1.使用自己翻译的 Python 代码,而非我们开源的 C++ 实现
2.用单核 CPU,关闭多线程并行测试 RaBitQ 算法,但却使用 NVIDIA A100 GPU 测试 TurboQuant 算法
以上两点均未在论文中充分披露。读者看到的是 RaBitQ 比 TurboQuant 慢数个数量级这一结论,却无从知道这一结论建立在刻意创造的不公平的实验条件之上。
事件完整时间线
2024 年 5 月:RaBitQ 论文在 arXiv 发布,同时源代码公开(后面发表在顶级会议 SIGMOD 2024)
2024 年 9 月:拓展版 RaBitQ 论文在 arXiv 发布,同时源代码公开(后面发表在顶级会议 SIGMOD 2025)
2025 年 1 月:TurboQuant 论文第二作者 Majid Daliri 联系我们,请求协助调试 Python 版 RaBitQ 实现
2025 年 4 月:TurboQuant 论文在 arXiv 发布
2025 年 5 月:我们跟 Majid Daliri 通过邮件询问了实验条件的差异并清楚解释了 RaBitQ 的理论保证最优性, Majid Daliri 表示他已告知全体作者,但在我们要求修正 TurboQuant 论文中的事实性错误之后,Majid Daliri 停止回复
2025 年 11 月:我们发现 TurboQuant 论文被提交至 ICLR 2026 会议,且论文中的事实性错误并未修正,为此我们联系了 ICLR 2026 PC Chairs,未获回应
2026 年 1 月:TurboQuant 论文被 ICLR 2026 接收 2026 年 3 月:TurboQuant 团队通过 Google 官方渠道持续推广,社交媒体相关浏览量已达数千万次
2026 年 3 月:我们正式向 TurboQuant 全体作者发送邮件,阐述以上三个事实性问题并要求做出修正及澄清。截至目前为止,我们仅收到 TurboQuant 论文第一作者 Amir Zandieh 的笼统答复,承诺会修正问题二和问题三,但拒绝修正问题一(即讨论 TurboQuant 与 RaBitQ 在技术上的相似性)。并且,他们仅愿意在 ICLR 2026 正式会议结束之后才做相应修正
我们已经做了什么
在 ICLR OpenReview 发布公开评论:
https://openreview.net/forum?id=tO3ASKZlok
向 ICLR General Chairs, PC Chairs, Code and Ethnics Chairs 再次提交正式投诉,附完整证据包
我们已经做了什么
在 arXiv 发布详细的关于 TurboQuant 和 RaBitQ 的技术报告
考虑向相关机构进一步反映
最后
我们提出这些问题,目标是让公共学术记录准确地反映各方法之间的真实关系。一篇论文被 Google 以数千万曝光量推向公众,在这种体量下,论文中错误的叙事不需要主动传播,只需要不被纠正,就会自动成为共识,这也是我们选择公开记录的原因。
在此我们也恳请大家让更多人知道 TurboQuant 论文背后存在的问题,我们相信真理越辩越明。
附上原文出处地址:
https://zhuanlan.zhihu.com/p/2020969476166808284
文章来自于微信公众号 "APPSO",作者 "APPSO"



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
