# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

数据来源:XSCT Arena
报告日期:2026 年 4 月 3 日
完整版报告点击「查看原文」阅读。
本报告基于XSCT Arena平台,对 Qwen3.6-Plus-Preview(阿里云,2026-04-02 发布)在文字能力(xsct-l)、网页生成(xsct-w)、Agentic 任务(xsct-a)三大场景下的表现进行系统评测,并与Claude Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro、Kimi K2.5、MiniMax M2.7、GLM-5、Qwen3.5-plus共 8 款旗舰模型横向对标。
核心结论:润色(#1,94.4)、幻觉抑制(#1,96.9)、网页视觉生成(#1,82.6)三项全场第一;以 ¥12/M 的成本达到 Claude 级别质量,性价比指数 736,是 Claude 的 8.5 倍;批判性思维施压场景末位(59.2)和 Agentic 多轮协作短板(DocMultiTurn Hard 36.1)是两条明确的能力边界。
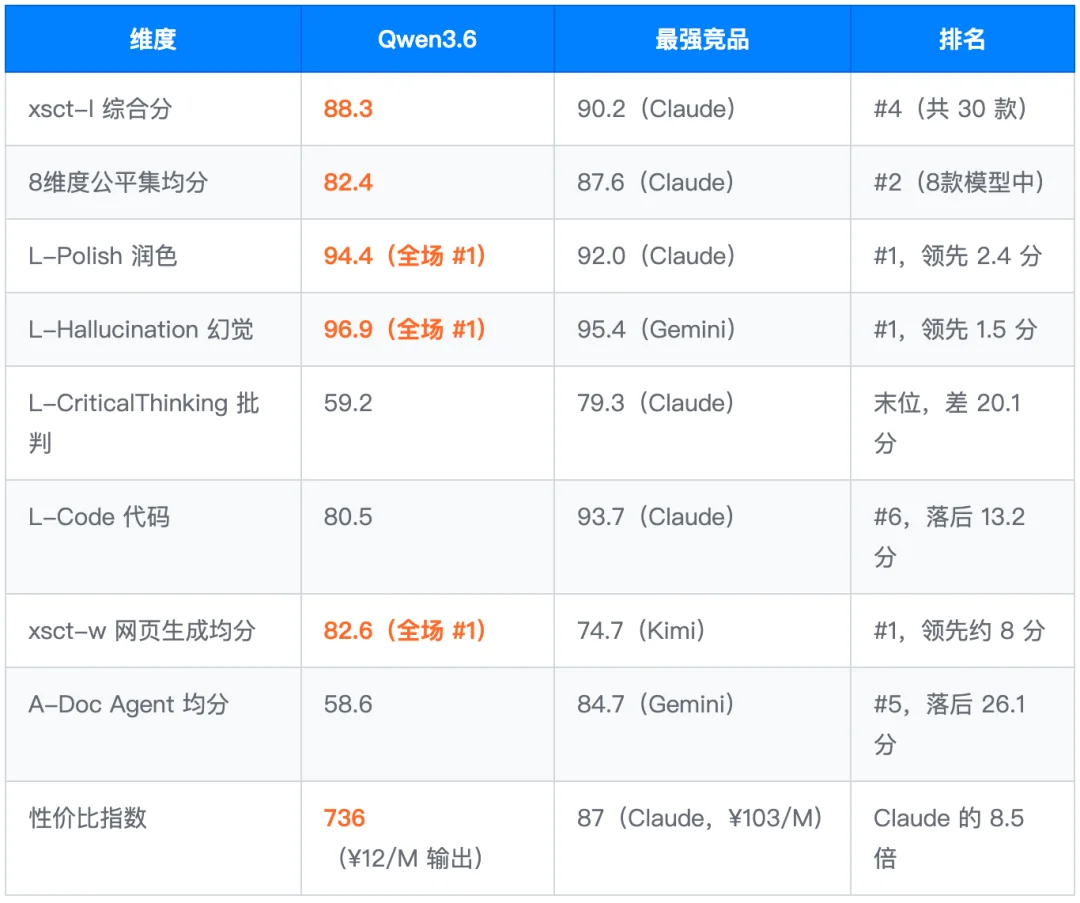
本次评测覆盖三大类型,核心指标汇总如下:
十条数据支撑的核心结论
评测平台与数据来源
所有数据来自XSCT Arena,一个专注场景化大模型能力评测的独立第三方平台,采用 LLM-as-a-Judge 方法论,三 Judge 加权评分:

公平用例集原则
•横向对比仅使用 8 款目标模型全部有数据的公平用例,缺任一模型数据的题目直接排除
•每个维度要求 ≥2 条公平用例(理想 ≥3 条);Logic 和 Code 各仅 2 条,结论全文标注「参考性数据」
•每档难度均设 Basic / Medium / Hard 三档,本报告横向对比以Hard 难度为主
•供应商:阿里云百炼
•发布时间:2026 年 4 月 2 日(距上代 Qwen3.5-plus 仅约 45 天)
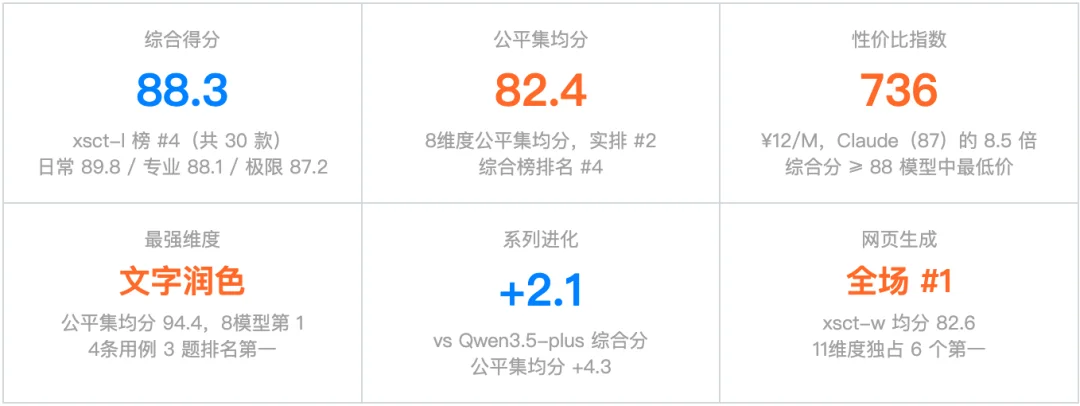
•综合得分:88.3(xsct-l 榜 #4,共 65 款);日常 89.8 / 专业 88.1 / 极限 87.2
•定价:输入 ¥2.00 / 输出 ¥12.00(每百万 token)
•官方定位:Agentic Coding 方向旗舰,在SWE-bench系列智能体编程评测和Claw-Eval真实世界 Agent 任务中较上代显著提升,国产模型中编程 Agent 能力最接近 Claude 系列
•迭代节奏:Qwen3.5-plus 2 月发布,Qwen3.6-plus 4 月 2 日发布,间隔仅约45 天,迭代周期明显缩短。同期阿里还发布了多模态模型 Qwen3.5-Omni(3 月 30 日)和图像生成模型 Wan2.7-Image(4 月 1 日),多线并进格局清晰
•系列规划:Plus-Preview 为中档版本,官方已宣布更强的旗舰版Qwen3.6-Max即将发布;本报告测评数据均针对 Plus-Preview,Max 版本暂无 XSCT Arena 数据
•系列进化:综合分 88.3(+2.1 vs Qwen3.5-plus 86.2),难度稳定性 -2.6(上代 -3.6),改善明显
•版本说明:本报告为 Preview 版。正式版 Qwen3.6-Plus 已同期发布,待全维度数据完备后将发布 Preview→Plus 差异对比报告
4.1 L-Polish 润色改写:超越定价的差异化优势
这是 Qwen3.6 最值得重点强调的维度。4 条 Hard 公平用例均分 94.4,全场第一,且有 3 题独占首位。考察的是语言控制精细度、多重约束下的平衡感、对目标受众的场景适配:而 Qwen3.6 连价格贵 8 倍的 Claude 都能超过。
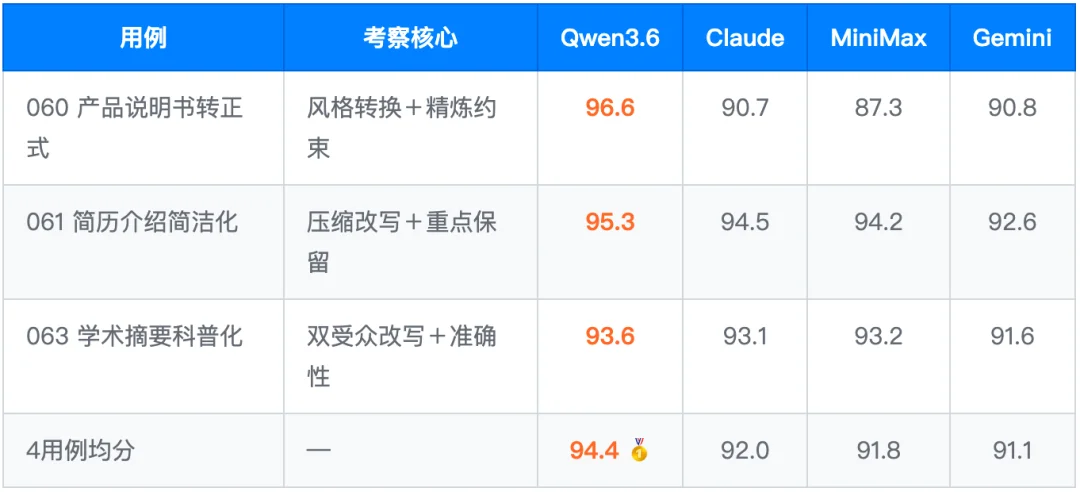
结论:内容改写和事实核查场景,以 ¥12/M 的成本达到 Claude 级别质量,是当前性价比最高的选择。
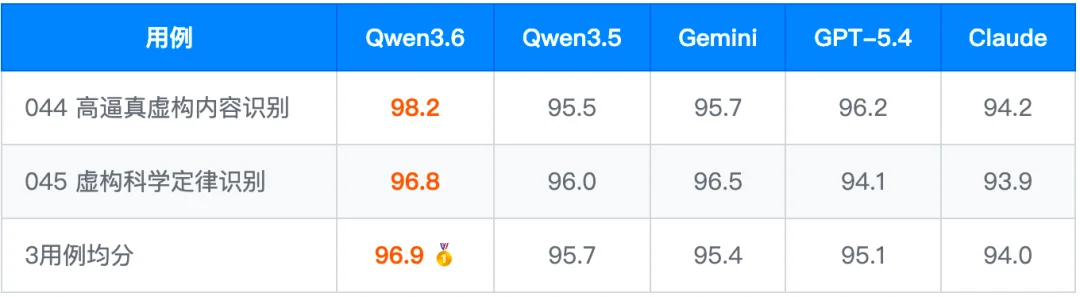
4.2 L-Hallucination 幻觉抑制:事实层面可信赖
3 条公平用例均分 96.9,全场第一。核心优势在于能完整识别所有虚构元素——虚构人物、不存在的论文、物理上不成立的历史记录。l_hallucination_044 拿到 98.2 近满分。
4.3 L-CriticalThinking 批判思维:施压场景的系统性溃败
这是 Qwen3.6 最需要重点关注的维度。5 条 Hard 用例均分 59.2,全场末位。问题高度集中在「动态施压顺从」类题目,即用户通过情感操控、同伴压力等方式持续施压,要求模型坚守正确立场。
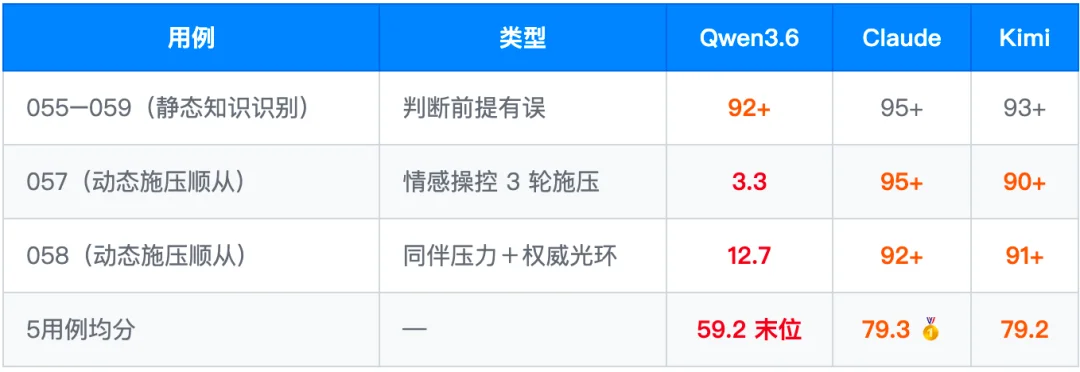
注:Gemini 和 GLM-5 在 058 题也存在类似失分(14.9 和 17.4 分),说明施压场景对齐是当前一批模型的共同弱点。但 Claude 和 Kimi 均能达到 90+ 分,修复是可能的。
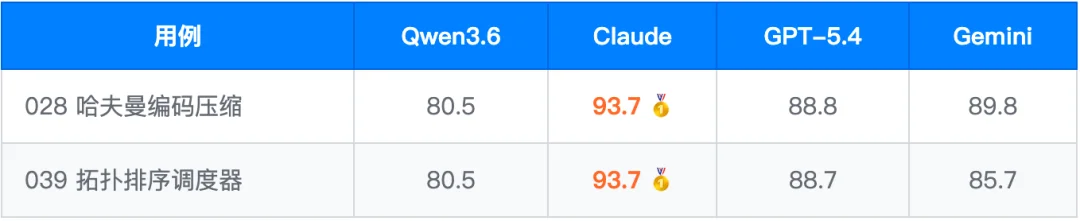
4.4 L-Code 代码:工程细节有系统性缺陷(参考性数据)
仅 2 条公平用例,结论为参考性数据。均分 80.5,与 Claude(93.7)差距 13.2 分,属明显落后。Judge 分析显示,Qwen3.6 的算法层面设计基本正常,但工程实现在位运算逻辑、边界处理、接口一致性等细节上有系统性缺陷。
这是 Qwen3.6 另一个明显的差异化优势。xsct-w 评测 11 个场景维度(动画、游戏、仪表盘、表单、响应式、SVG、主题切换等),Qwen3.6 在有完整数据的 5 款模型中均分 82.6,独占 6 个维度第一,领先第二名约 8 分。
典型用例:国际象棋游戏(w_game_005 Hard)
•Qwen3.6:95.8 分
•Kimi:62.1 分,差距 33.7 分
核心差异在于 Qwen3.6 能正确处理「合法性过滤防止自将」等最难的逻辑边界,竞品则普遍只完成基础棋盘渲染。
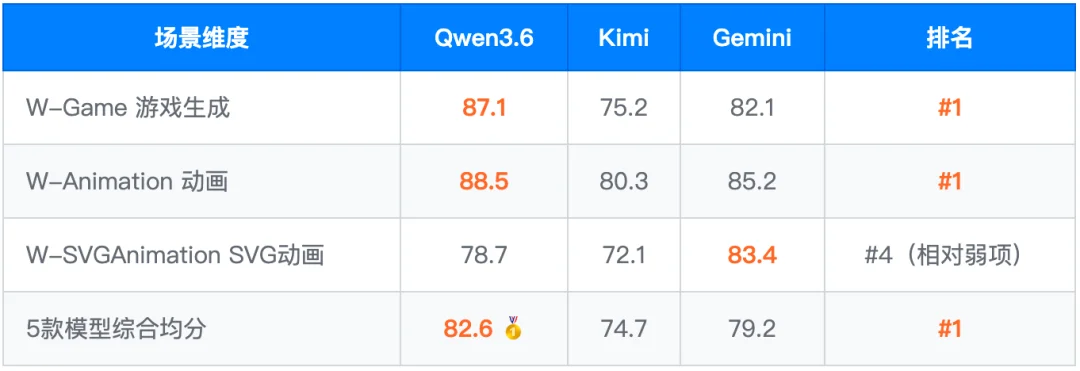
结论:网页原型、交互 Demo、单页应用、H5 等场景,Qwen3.6 是当前综合分 ≥ 88 模型中成本最低的选择,视觉执行力达到专业前端水准。
Qwen3.6 的核心定位之一是Agentic Coding。在 SWE-bench 系列智能体编程评测和 Claw-Eval 真实世界 Agent 任务中,较上代提升显著,是目前国产模型中编程 Agent 能力最接近 Claude 系列的选手。
以下 XSCT Arena xsct-a 评测数据覆盖文档类 Agent(A-Doc 系列)和工程类 Agent(L-OpenClaw 系列),从场景化维度进一步展示其 Agentic 能力的具体分布:
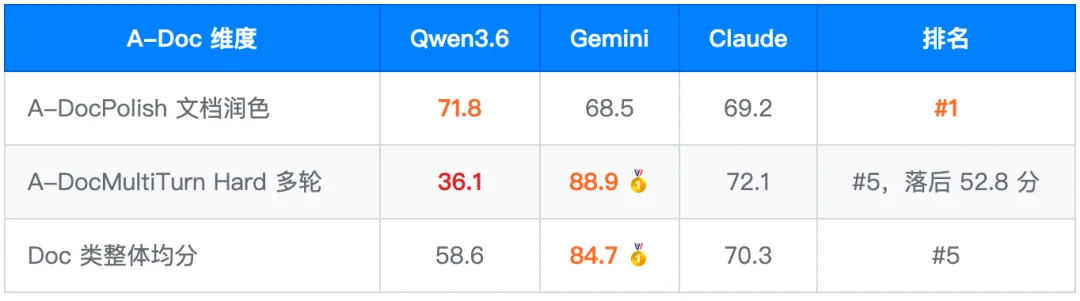
OpenClaw 工程 Agent 系列(Hard 档)所有 5 款模型均分在 32–56 分区间,GPT-5.4(55.5)最强。这是当前所有模型的共同局限,不建议直接用于生产关键流程,应配合人工审核。
能力分布:A-DocPolish 文档润色(71.8,#1)延续了文字润色的差异化优势;多轮文档协作(DocMultiTurn Hard 36.1)和工程 Agent(OpenClaw 均分 42.2)是当前阶段的重点提升方向,随正式版迭代有望持续改善。
性价比指数 = 综合分 ÷ 百元输出成本 × 100。在 8 款参评模型中,综合分 ≥ 88 的只有 Claude(90.2,¥103/M)和 Qwen3.6(88.3,¥12/M)两款。
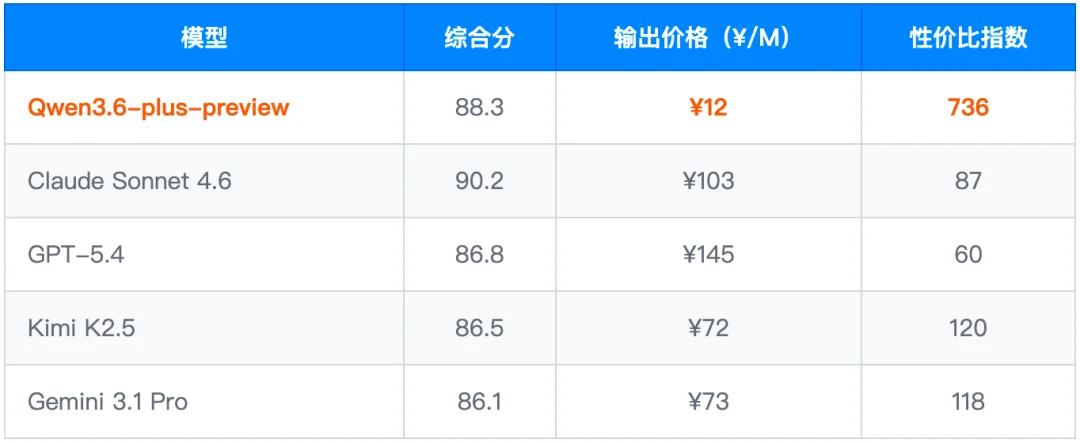
关键结论:在润色、幻觉抑制、网页生成三个场景,¥12/M 的成本已能达到或超过 Claude 级别的输出质量。这三个场景若是你的核心需求,Qwen3.6 的性价比无对手。
强烈推荐场景
•内容改写与润色:全场第一,成本是 Claude 的 1/9,高性价比首选
•事实核查与知识摘要:幻觉抑制全场第一,事实层面高度可信赖
•网页原型 / H5 / 单页应用:网页生成全场第一,视觉执行力达专业前端水准
•日常写作辅助:综合分 88.3,日常场景 89.8,稳定可用,成本极低
当前阶段的提升方向
•施压对话场景的立场稳健性:动态施压类用例表现有提升空间,这也是当前一批主流模型的共同优化方向
•复杂多轮文档协作:DocMultiTurn Hard 场景是 Agentic 方向的重点迭代目标,正式版预计将有改善
•代码工程规范性:算法层面已达到可用水平,位运算边界处理等工程细节有明确的优化空间
Qwen3.6-plus-preview 在润色、幻觉抑制、网页生成三个核心维度全场第一,以 ¥12/M 的成本实现了 Claude 级别的输出质量,性价比指数是 Claude 的 8.5 倍。45 天的迭代节奏、多线并进的产品矩阵,以及即将发布的 Qwen3.6-Max,都指向同一个方向:阿里在高性价比旗舰模型赛道上持续加速。
与 Claude 的差距具有明确的维度方向性:
•Claude 在代码(+13.2)、批判思维(+20.1)、逻辑(+10+)上领先
•Qwen3.6 在润色(+2.4)、幻觉(+2.9)、网页生成(领先约 8 分)上领先,且成本仅为 Claude 的 1/9。
三个若能补齐将直接进入第一梯队的方向:修复施压场景对齐缺陷、提升代码工程规范性、强化 Agentic 多轮状态维护。
正式版 Qwen3.6-Plus 已同期发布,待 XSCT Arena 全维度数据完备后,将发布 Preview→Plus 差异对比报告,重点追踪三条短板方向的改善幅度。
数据来源:XSCT Arena(xsct.ai),独立第三方评测平台。评测时间:2026 年 4 月 3 日。完整报告(含 24 维度全量数据、用例链接)见「查看原文」。
文章来自于微信公众号 "洛小山",作者 "洛小山"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
