# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Harness 应由业务驱动。

本文来自 Nexad 团队的大米(作者)、Jason(编辑)、William(编辑),Nexad 是一家 base 湾区和上海的 AI startup,从 a16z, Prosus, Point72 等基金融资 $6M。
2026 年初,OpenAI 和 Anthropic 先后发表了关于 Harness Engineering 的深度文章。OpenAI 展示了 3 名工程师用 Codex 产出百万行代码的实验;
Anthropic 展示了用 Initializer-Coder 两阶段架构让 Agent 跨多个 Context Window 持续工作。两篇文章都非常好。但它们面向的都是 Coding Agent——写正确的代码、通过测试、合入 PR。
我们在过去三个月做的事情不太一样。nexad 是一个 AI-native 广告平台。我们的 Agent 不只写代码——它们跨多个广告平台运行,生成广告创意,管理投放预算,协调数据链路。当我们试图把行业里的 Harness 最佳实践直接搬过来时,发现很多假设在 Marketing Agent 的场景下不成立。
这篇文章分享的是我们在这个过程中形成的一些判断,以及支撑这些判断的具体实践。有些是行业共识的验证,有些是我们独立得出的结论,也有一些我们仍然没有解决的问题。
以下,enjoy
在讨论我们如何 harness Coding Agent 之前,值得先解释一下为什么我们需要超越标准方案。答案在于我们正在构建的产品。
强化学习中有一组有用的直觉:Environment、State、Action、Reward、Policy。我们构建的 Agent——我们的 Marketing Agent——运行在一个约束条件与 Coding Agent 根本不同的环境中。
不可逆性。 Coding Agent 的失败模式是良性的:代码编译不过、测试跑不通、PR 被打回。你可以 git revert 然后重来。我们构建的 Marketing Agent 会向 Google Ads 提交 Campaign、花费客户预算、发布可能违反平台政策的创意。一个被封停的广告账户不是改几行代码就能恢复的。所以我们的 Coding Agent 在 Marketing Agent 代码库中引入的每一个 Bug 都带有放大效应的风险——这不仅仅是坏代码,而是可能花真金白银的坏代码。
创意与约束之间的张力。 我们构建的 Marketing Agent 必须在创意质量(吸引人的文案、有效的定向投放)和硬性约束(品牌规范、平台政策、预算上限)之间取得平衡。这意味着我们的代码库充满了微妙的业务逻辑——在这类代码中,"技术上正确"和"实际上正确"常常背离。一个不理解这些微妙之处的 Coding Agent 可能写出通过所有测试但破坏产品的代码。
延迟反馈。 我们 Marketing Agent 的产出质量靠 CTR、ROAS 和转化率来衡量——这些信号需要几小时甚至几天才能出来。这意味着广告投放逻辑中的 Bug 可能在真实预算被花掉之后才会浮现。我们不能依赖快速反馈循环来捕获 Coding Agent 的错误;Harness 必须提前拦截它们。
这些特征——不可逆的下游影响、微妙的业务逻辑、延迟的反馈——解释了为什么我们把 Harness Engineering 视为基础设施,而非流程。每个 Harness 决策都可以追溯到一个业务需求和对产品上下文的深入理解——而不是工程偏好或会议室里脑暴出来的灵感。
坦率的来说,这是我们踩坑最多的地方。
早期我们把规则写在文档里:CLAUDE.md 写“请使用 kwargs 日志”、写“请遵循 import 层级”、写“请用软删除”,甚至在 CLAUDE.md 里面写一些昵称(什么时候它忘记了,什么时候CLAUDE.md 就失效了🤣)。Agent 读了,大多数时候遵守,但经常在压力下忘记,尤其是最近 Claude 升级到了 1M 之后。
我们团队花 30~40% 的时间做人工质量保障——手动 Review、手动跑测试、手动检查 Spec 合规。这显然不 scale,太 Saas 了。
我们深入学习了 OpenAI 的 Harness Blog(感谢他们)开始把规则编码为自动化检查。我们构建了 8 个自定义 lint 脚本:check_structured_logging.py 检查是否使用了 f-string 日志;check_soft_delete.py 检查是否直接调用了 session.delete();check_api_doc_sync.py 检查 API 变更是否同步了文档等等。这些脚本在 CI 中以 No-Blocking 运行,当然肯定要允许一些存量,那是额外的 issue 要偿还。
我们从中提炼出一个约束执行力的层级:

从下往上,执行力递减。现在每添加一条新规则,我们都会先问:能不能做成 Linter?能就先写 Linter,再写文档。这和 OpenAI 在他们的文章中得出的结论几乎一样——“when documentation falls short, promote the rule into code”——我们在实践中独立验证了这一点。
对 Marketing Agent 来说这尤为关键。check_soft_delete.py 看起来只是一个代码规范检查,但它背后是一个业务需求:硬删除广告账户记录会破坏 Billing 对账所需的审计追踪。这种业务规则和代码规范之间的映射关系,正是 Marketing Agent Harness 的独特之处。
Anthropic 在他们的 Long-Running Agents 文章中证明了一个重要结论:让 Agent 评估自己的产出会系统性失效。Agent 标记 feature 为完成状态,但实际功能跑不通。他们的解法是分离 Generator 和 Evaluator。
我们在实践中形成了一个更精确的判断:失效的不是同模型评估,而是同 Context 评估。
在我们的 Review 阶段,Main Agent 完成 Spec Compliance 检查(这需要方案的完整 Context)后,会 spawn 一个 SubAgent 做代码质量审查。这个 SubAgent 使用同一个模型(Claude),但它拿到的 Context 完全不同:只有 git diff、项目规则文件(docs/rules/*.md),和一个专门的角色定义(.claude/agents/code-reviewer.md),设定为"怀疑态度的 Senior Reviewer"。它对 Main Agent 的推理过程、做过什么妥协、跳过了什么,完全一无所知。
效果出乎意料地好。SubAgent 能稳定捕获跨层 import 违规、日志格式错误、缺失的测试覆盖——这些都是 Main Agent 在同一个 Context 中"合理化"掉的问题。
这个发现对 Startup 很有意义。
跨模型评估(比如用 OpenAI 审查 Claude 的产出)增加了成本、延迟和集成复杂度。Context 隔离给你大约 90% 的效果,成本是几分之一。我们也用跨模型审查(Plan 阶段用 Codex 做 sanity check),但对日常代码质量,隔离 Context 的同模型 Subagent 更合适。
这是我们认为最值得分享的一个观点。
OpenAI 和 Anthropic 的文章都隐含一个假设:所有代码变更接受相同级别的质量管控。整个 Pipeline 对所有变更一视同仁。这在纯 Coding Agent 的场景下大致合理——代码要么对要么错,没有中间态。
但在真实的产品开发中,一个面向未知用户的生产 API 和一个内部 admin 面板,需要的安全审查深度完全不同。一个 dev 环境的脚本和一个核心交易流程,需要的测试覆盖标准也完全不同。我们发现 Agent 约有 30% 的时间被浪费在对低风险代码执行不必要的高标准检查上。
我们的解法是设计了一个 Delivery Tier 分级治理体系,T0 到 T3,核心逻辑是用户可控度决定 Harness 严格度:
关于这里,更加详细的内容可以期待我们的下一篇 Blog :)

Tier 基于代码路径自动检测。我们的 Monorepo 包含 14 个 package,apps/web/ 自动映射到 T0,apps/admin-web/ 映射到 T2,scripts/ 映射到 T3。Agent 在 Plan 阶段声明 Tier,人类确认或 override。后续每个阶段——Review、Test、Ship——自动加载对应的检查清单。
最终在 PR body 中输出一份 6 维度的合规矩阵(安全、可靠性、可观测性、性能、UX、合规)。
Anthropic 提出 "harness complexity should match model capability"。我们认为这个论断可以进一步扩展:Harness 的严格度需要同时匹配模型能力和交付风险。 模型能力是一个维度,业务暴露是另一个维度。Delivery Tier 是后者的具体实现。
我们的 CLAUDE.md 从 50 行增长到 200+ 行。效果先是越来越好,然后突然变差——Agent 开始选择性忽略部分规则。
OpenAI 对此有一个精准的总结:"Too much guidance becomes non-guidance. When everything is 'important,' nothing is." 我们在实践中独立验证了这一点。
解法是渐进式披露。CLAUDE.md 保持在约 180 行,作为入口目录指向 docs/ 中的详细规则。每个 Skill 在触发时按需加载它需要的规则文件。/nex-reviewer 触发时才读 import-rules.md(49 条层级规则)和 logging-rules.md;/nex-tester 触发时才读 test-pattern-guide.md。Agent 在需要特定规则时才接收到这些规则。
这和 Cursor 处理 MCP 工具描述的策略本质相同——延迟加载而非预加载。也和 Claude Code 的 SKILL.md 机制同源。行业在不同路径上趋向同一个结论:Agent 的 Context 是稀缺资源,需要像内存一样精细管理。
说了很多判断,看看数据。下面的数据来自我们的 git log,覆盖 2026 年 1 月至今。具体数字不方便公开,但趋势本身已经足够说明问题。
第一组是周 commit 趋势。W08 我们开始集中建设 Harness 基础设施——2 月 12 日上线了第一批 Linter,2 月 26 日部署了第一个 Hook,3 月 2 日一天之内部署了 4 个 Hook 和 7 个核心 Skill。效果在 W09 的数据上很明显:
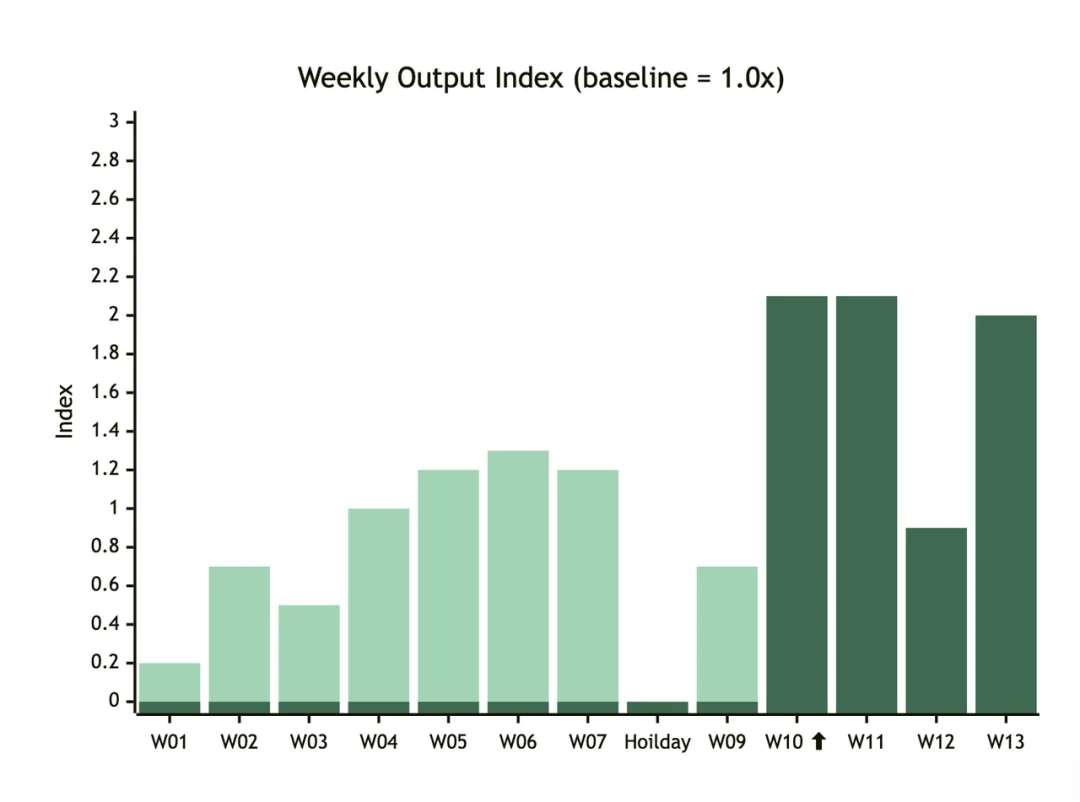
W09 到 W10,产出指数从 0.7x 跳到了 2.1x——接近 3 倍。此后稳定在 2x 左右。加速的机制并不神秘:Harness 吸收了人类原本手动承担的质量保障工作。上线前,我们会花大量时间在手动 Review、测试和 Spec 验证上。上线后,这些工作被 Skill Pipeline 和 Hook 自动化了。Harness 没有让 Agent 更快——它让人类从检查者变成了决策者。
第二组是 commit 类型分布。一个值得注意的信号:feat 和 fix 几乎 1:1。这不是巧合——Agent 在快速产出功能的同时,也在快速产出需要修复的问题。这恰好验证了为什么 Harness 是必要的:没有自动化的约束和验证,fix 的数量会随 feat 的数量线性增长。
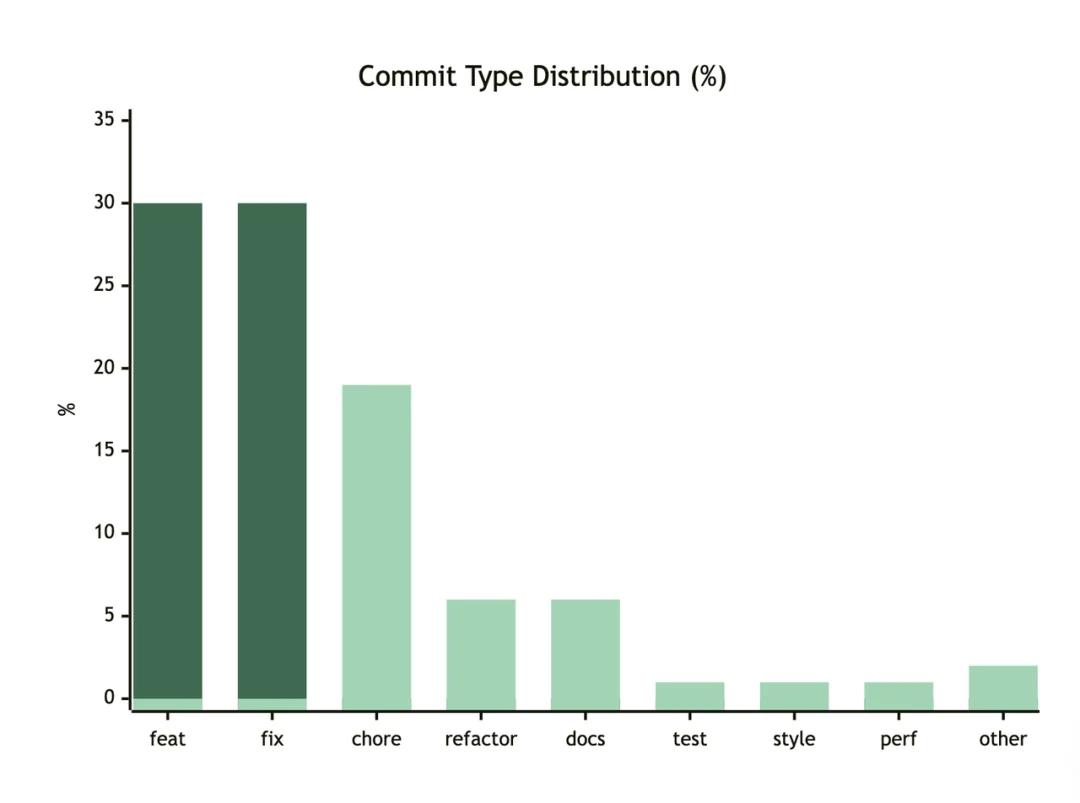
另一组数据:在全部近2000 个 commit 中,27% 涉及文档变更,15% 涉及测试文件变更。这不是偶然的——我们的 Skill 定义中把测试和文档同步设为强制步骤。8 个 custom linter 在 pre-push 阶段持续运行。Agent 的产出在进入 main 分支前至少经过 2-3 道自动化检查。
Harness 基础设施本身的建设时间线:
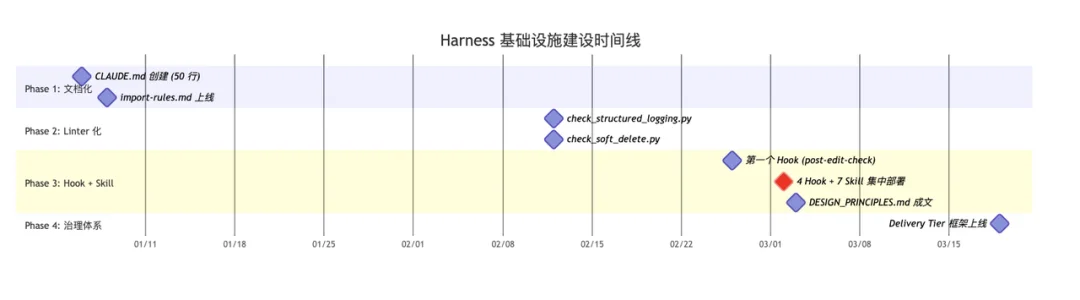
技术债在 AI 下加速积累。
Agent 会忠实地复制仓库中已有的模式,包括坏的模式。
一个错误的日志格式被引入后,Agent 在所有新代码中持续复制它。人类工程师通常会意识到"这个写法不对,我不应该跟着写",但 Agent 的 pattern matching 机制让它倾向于延续既有模式。我们通过 Linter 拦截了已知的坏模式,但尚未建立 OpenAI 所说的 "garbage collection" 机制——一个定期扫描代码偏差并自动开修复 PR 的 Agent。这是我们 Roadmap 上的下一步。
Plan-Todo-Progress 三件套的设计动机。
有人问过我们为什么要搞三件套文档(docs/plan/active/、docs/todo/active/、docs/progress/active/),看起来是不是过度设计。这个系统不是凭空发明的,它来自一个具体的失败模式:没有外部制品时,Agent 会试图一次性完成复杂功能,在实现过程中耗尽 Context,让下一个 Session 去猜发生了什么。这和 Anthropic 在 Long-Running Agents 论文中记录的失败模式完全一致——他们用 claude-progress.txt 和 feature list 来解决,我们用三件套。
这里有一个关键设计决策:每项 Todo 必须包含 Verify 命令和 Expect 输出,精确到 Shell 命令和预期字符串。这不是随意的粒度要求——它让 TaskCompleted Hook 能够机械地验证完成状态,而不是信任 Agent 的自我评估。
创意质量的最后一公里。
我们的 Harness 能检查政策合规、品牌规范遵守和技术正确性。但广告创意是否会表现好——文案是否能引起共鸣,视觉是否能让人停下来看——这仍然是人类判断。"政策合规"和"高效创意"之间的差距,是我们目前无法自动化的地方。
Junyang 在他关于 Agentic Thinking 的文章中写道:"The future is a shift from training models to training agents, and from training agents to training systems." 我们的经验部分验证了这个判断。
过去三个月,我们花在设计 Skill Pipeline、调试 Hook 脚本、打磨 Delivery Tier 矩阵上的时间,可能比写任何一个 feature 的时间都多。但正是这些 scaffolding,让 Agent 每天产出的代码能可靠地服务真实用户。
Harness Engineering 才刚开始。随着模型能力提升,今天必要的约束明天可能变得冗余——Anthropic 在每一代 Claude 上都观察到了这个趋势。
但不变的是一个核心判断:Marketing Agent 的 Harness 设计应该由业务需求驱动,而不是工程偏好。
当你的 Agent 的一个错误决策可能导致客户的广告账户被封停时,"enforce invariants, not micromanage implementations" 就不只是一个工程原则,而是一个生存策略。
缰绳的形式在变,缰绳的角色不变。
2026 年 3 月 nex.ad[2]
参考资料
[1]CLAUDE.md:http://CLAUDE.md
[2]nex.ad:https://nex.ad
文章来自于"十字路口Crossing",作者 "青年王大米"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
