# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

「像做恨一样做ai视频」
最近Seedance 2.0接入大赛开始了,有头有脸的视频agent都当上字节中介原地起飞了。
OiiOii也不求Sora2 API了,Libtv狂投一波庆祝自己接入Seedance2.0了,连低调Flova都忍不住出来炒作,暗示剪映技术负责人王学智和产品负责人张逍然已经去Flova了。
早知今日何必离开字节呢?我建议即梦直接按照闹闹、陈冕、郭列在字节的级别给他们分一下额度。
我也又回去用了下之前盛赞过的Flova,毕竟之前说它怀了个剪映宝宝雏形,现在得检查一下是否破肚而出了。
结果他们很幽默,非得声称自己接入了一个能全能参考、能动作模仿、能时长翻倍的怎么看着都是Seedance 2.0的视频模型,但不知道是保密需求还是怎么的,硬是给它起名叫StarDawn 2.0。给我看一愣一愣,以为这公司掌握核心蒸馏技术了。
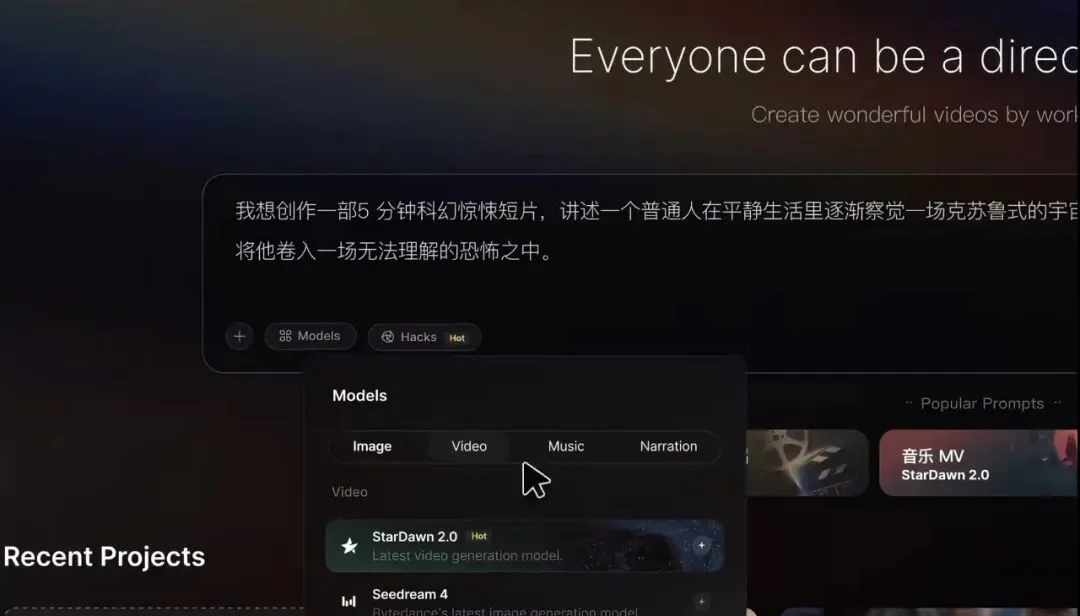
最近两天才使用查找替换功能把名都改成Seedance 2.0了
于是我先试着做了一个喜鹊谋杀案片头式的朝鲜宣传片,准备在我们本月朝鲜之旅的时候献给将军。
集成了Seedance 2.0参考功能的Flova确实是把「不用写提示词」这一核心卖点给发扬光大了,我只需要把刷到的视频和一句话灵感发给它,就开始自动分析风格了。
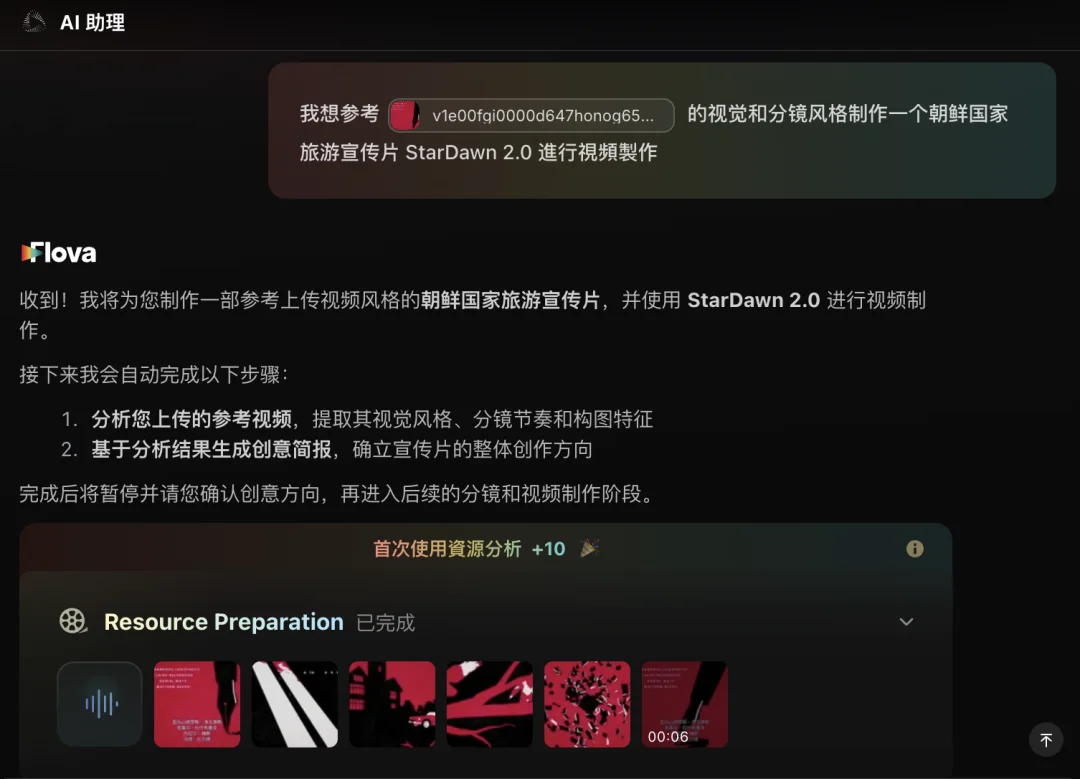
而且在具体的影片策划上,之前还需要打字,现在直接给了几轮二选一,实现像打旮旯game一样做ai。

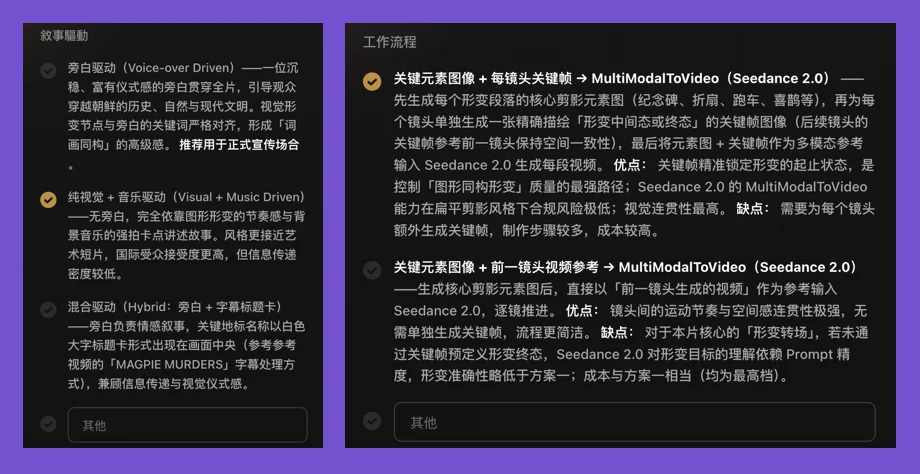
出现哪些地标、两个镜头之间如何丝滑转场,也基本都是它独立思考出来的。我只做一些微小的工作。
最后生成视频如下,虽然不知道末尾的朝鲜话是啥意思,但感觉挺对味的。

动画的试完了,试试真人效果。我结合最近铺天盖地的把同事压缩成skills的热点,做了一个不到十秒的恐怖小短片。
蒽其实不算特别恐怖,但基本也能看明白核心剧情和预设的恐怖点在哪。也算是个成品。
但当我让Flova做一个30秒的中长视频的时候,就有点翻车了。
我设想的剧情比较简单:全程第一人称视角,主角给同事拍离职vlog,跟着同事走出公司大门之后发现,这人直接被扔到一个蒸馏工厂里被邪恶的资本家给回收成skills二次利用了。有点像《约定的梦幻岛》的剧情。

但用Flova做的时候,就发现它有三个严重的问题。
第一,空间位置关系只为单个镜头服务,没有一个整体的规划。
比如主角把头伸地板里看,下一秒看到的居然是个天花板,成颠倒世界了。
也可以理解,毕竟在Flova的工作流里,它只是给故事所需的场景生成了几张孤立的平面图,又不是做了个赛博片场的3D建模。
第二,在生成视频的时候,没能把剧情基础设定作为画面提示词的一部分进行考虑。
比如我说这主角偷偷摸摸进到工厂里拿手机偷拍,结果很多镜头要么是第三人称央视纪录片视角,要么怼着人形机器人的脸拍。给人一种主角莅临工厂亲自视察的意思。
第三,多个镜头组之间常常硬连尬连,最终成片有素材堆积感。
比如我跟Flova说,视频里要有同事被抓获、同事被压缩成SKILL、同事.skill被安装到公司电脑这三件事。
它就确实把事件A、事件B、事件C的镜头都给我生成得明明白白的。
但从主角看到事件A到看到事件B之间的过渡,转个头或者走个路,或者对着屏幕说「让我们去那边看看」,这就都不存在。都得自己手动添加。
好在这三个问题在短平快的片子制作流程中体现并不明显,所以我在做朝鲜宣传片和惊悚小视频的时候也没怎么难受。
估计Flova也意识到这些问题了,因为他们最近举办的活动基本上就是鼓励大家多做一句话生成的短视频。

Flova的反面就是TapNow。
首先,在Flova邀请用户做只有3个镜头的视频发网上的同时,TapNow办了一场需要连续抽卡36个小时做视频的动画黑客松,又发起了一场连先导片都需要1~3分钟的AI视频生成大赛,然后他们网站首页和对外宣发的也都是一些电影质感的中长视频创作。

其次,Flova的交互基本全靠对话,TapNow的界面就是画布,像是打开了100个文件夹。
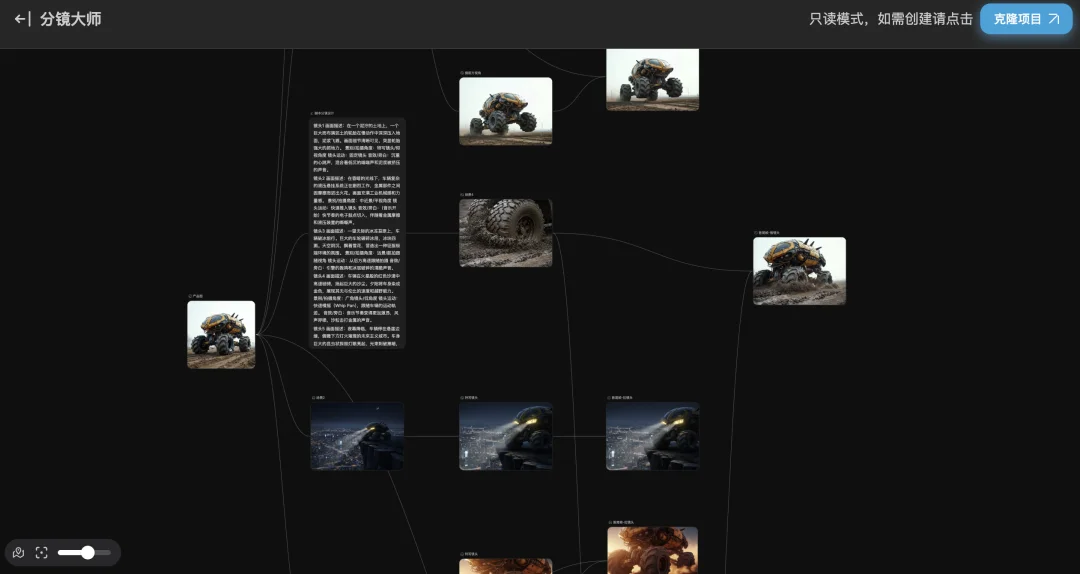
这甚至只是一个模板
我说实话这画布看起来比AE界面都复杂,谁能研究明白这界面,做视频也不用AI了。
基于以上两点,TapNow生成的确实都是精准的、有质感的高水平视频,Flova生成的则是混沌的、差点意思的视频。
在现阶段的AI视频生成领域,可以说TapNow是一个专业的精密仪器,Flova更像是个玩具。
之前和沐秋聊到视频agent,他也说现在画布就是版本答案。这可能也是行业共识。
但即便如此我也是非常恨画布,且尽量不使用TapNow。
因为任何视频agent的本质都是画布,AI视频生成都是文生图——图生视频这么几步,它们后台肯定有个超大画布在那默默运作。唯一构成产品区别的就是你把这个画布藏多少,帮用户画多少。
TapNow呢?画布就是它的本质了。这不算什么伟大发明啊。
换句话说,如果有足够的耐心、时间和精力,只要你在电脑里建立100个套来套去的文件夹,再打开Gemini和即梦,你基本上也手搓了一块画布。
TapNow做的其实就是这块画布的交互界面,就我个人而言,没感觉它设计得有多用心。
看这画布复杂程度,打开电脑都要死机了,我也直接看力竭了,根本不想接着做。

合着我得是个当代电影大师才能来当AI视频大师。
那我能说什么?我不是什么当代电影大师啊,我是连画布都看不懂的**啊。
不会以为在AI技术出现之前,阻碍我拍一部电影的只是预算吧?显然除此之外,还有我贫瘠的美学知识和视频拍摄技术啊。
你不能只是把摄影机和一整套灯具换成一台能登录TapNow官网的电脑,把分镜表改成画布模样,然后把电池和胶卷定为token的翻译,就说现在已经没有任何实现创意可视化的阻碍了。
往大了说这甚至是一种傲慢。默认消费者应该努力适应产品而不是反过来,就算产品再好也会被淘汰。
上世纪八九十年代日本傻瓜相机因为简单好用席卷全球,以往走高端装高雅的徕卡差点都被干破产了,只能联合美能达推出了贴牌产品。
请注意这个时候他们可没派一个公关高管出来教育用户说,傻瓜相机虽好,我们手动机械相机才是坠能拍出精确曝光的,才是最省胶卷不用抽卡的。
对吧,这话都没用,这还是徕卡,众画布类产品有徕卡的产品力和用户忠诚度吗,你们能应对日后出现的哪怕没那么精准但更易用的傻瓜产品吗?
对于我们**用户来说,商品有学习成本,那就是路边一条。
没有学习的义务.jpg
这也是为什么剪映比pr伟大,你pr再能做高级效果再能导入16K240帧的片子也没用,我一个特效拉过去,村口老太都发了10条抖音了。
哦说到抽卡,很多人就提到TapNow这种画布类产品的一大优点,省token。
事实上你在用TapNow的时候其实在烧双倍token。AI烧之前你人脑还烧了一遍呢,研究那个画布的时间都够你搬砖赚俩月会员了。
别把自己的精气神不当回事。人的token也是token。
当然,喷了TapNow一屏幕,不意味着Flova就更胜一筹了·。
我纯个人视角总结了一下,现在视频agent基本就两个发展方向。
一个是抄TapNow,致力于做出更大更全更无限的超级无敌画布,然后和其他的画布比谁接入Seedance 8.0更快。
另一个是Flova这种,走一个无知即力量的路线,让用户不用管提示词是怎么写的,也不用想脚本、模型这些事,把用户手感作为壁垒。(沐秋还真诚建议Lovart做完TapNow后可以顺手再做个Flova)
然而现在前者的使用体验让我想死,后者的视频成片让我不想活。
所以我决定等待。就像之前学不明白车现在等来无人驾驶,之前没蹭上转码热潮现在都开始vibe coding。
我现在就要原地不动每天喷你们两家公司,直到TapNow把交互和操作改成对我这种**用户也友好时,直到Flova能看懂我如梦话般的指令时,我再开始用你们进行AI视频。
毕竟在此之前,用你们做ai就像做恨一样难受。
(本文封面由ChatGPT 生成,纯人工写作)
文章来自于"葬AI",作者 "罗子马"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
