# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”

数据表现超级亮眼:
Cursor使用的“输出中心”的 Warp Decode直接把传统 MoE 模型的“专家中心”生成方式中内存使用效率低、准确性低等问题,一次性全部解决!
今天,我们来拆解一下:Cursor 的 Warp Decode 到底做了什么?为什么能同时实现速度和精度的双提升?
现在的顶级大模型,大多采用Mixture of Experts架构—— 一个模型里面有几十个甚至上百个“专家”子网络,输入的时候只激活其中一部分专家(例如在某一层从 128 个专家中选择 8 个来干活),这样既能保持超大参数量,又能控制实际计算量。
传统MoE的计算路径大概是这样的:
这种传统的MoE 路径在大批量场景下效果很好,因为每个专家上的共享工作足以摊薄整理数据的额外开销。
但在自回归解码阶段——也就是我们用AI生成代码时,由于一次只生成几个 token,没有足够的共享工作来支撑。传统路径中的八个阶段里,有五个阶段纯粹是“数据管理”,本身并不进行任何实际计算。
到了我们的实际的应用里,结果就是:在理论上MoE很高效,但实际上将太多时间用来运送数据,跑起来GPU带宽利用率低,速度慢。

既然搬运数据太慢,Cursor 直接换一条路走。
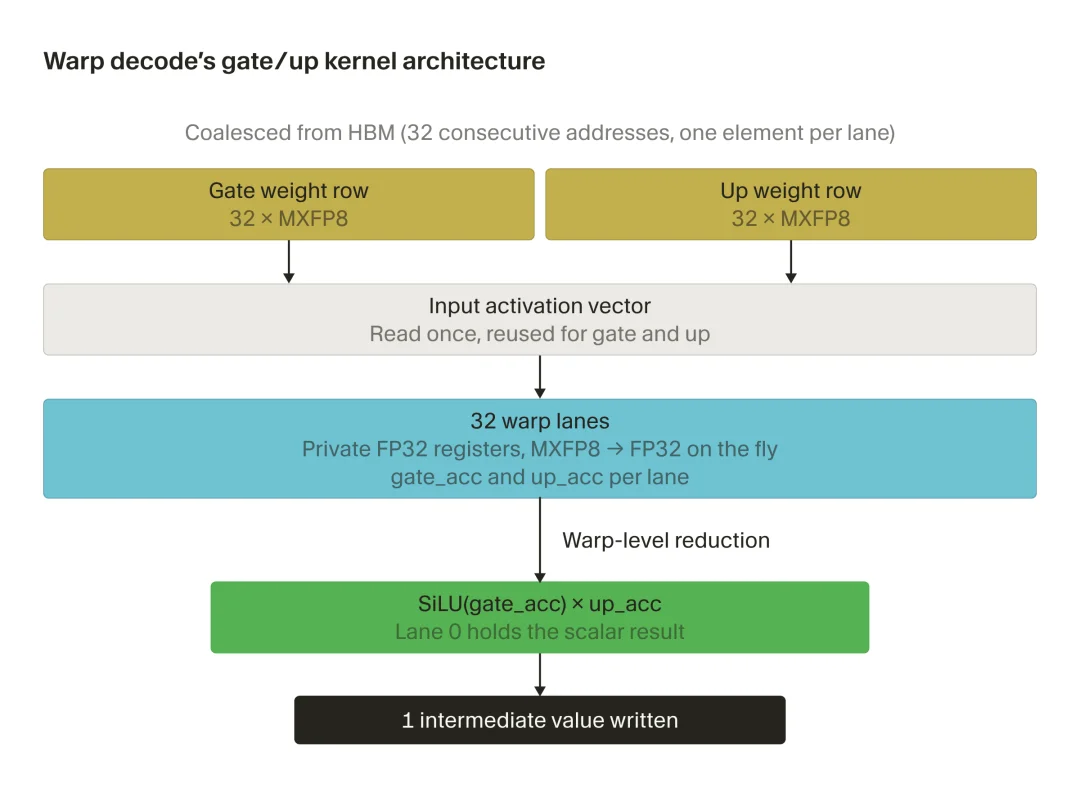
我们先来了解一下warp decode 具体是什么?根据官方描述:
在 Blackwell GPU 上进行小批量解码时,围绕输出而非专家来组织 kernel 效果更好。Cursor 将这种方法称为“warp decode”。
现代 GPU 会以由 32 条并行处理通道组成的组来执行指令,这样的一组称为一个 warp。在warp decode 中,每个 warp 都只负责计算一个输出值。warp 会直接从内存中流式读取所需的权重数据,将所有 8 个路由专家的结果汇总到一个持续累加的总值中,最后写出一个结果。
而 warp decode 是如何运行的呢?
简单来说,从围绕“专家”到围绕“输出”,中间的环节能砍则砍。
warp decode 主要通过两种机制提升性能:一是去掉传统路径所需的阶段和缓冲区,二是实现 warp 的独立性,从而带来更优的调度效果和更好的延迟隐藏能力。
具体做法:
Cursor 这套操作系统最大的好处是什么?
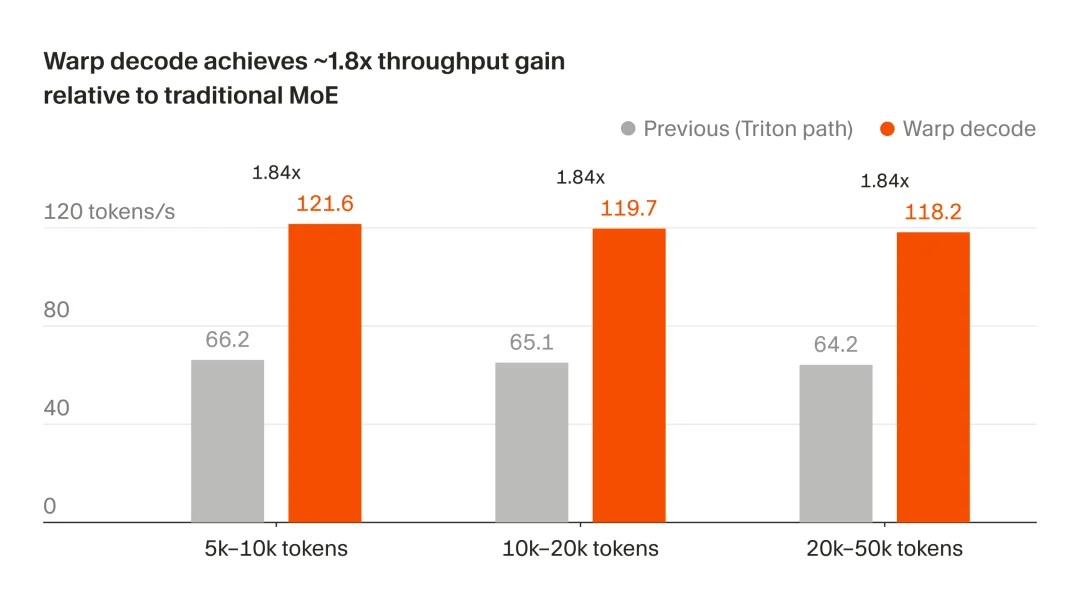
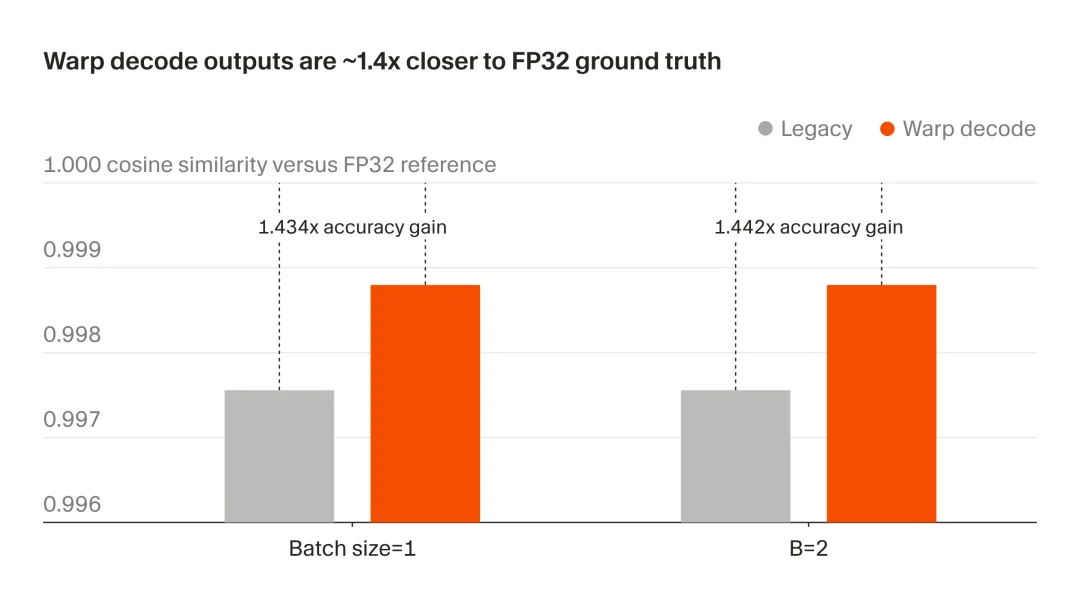
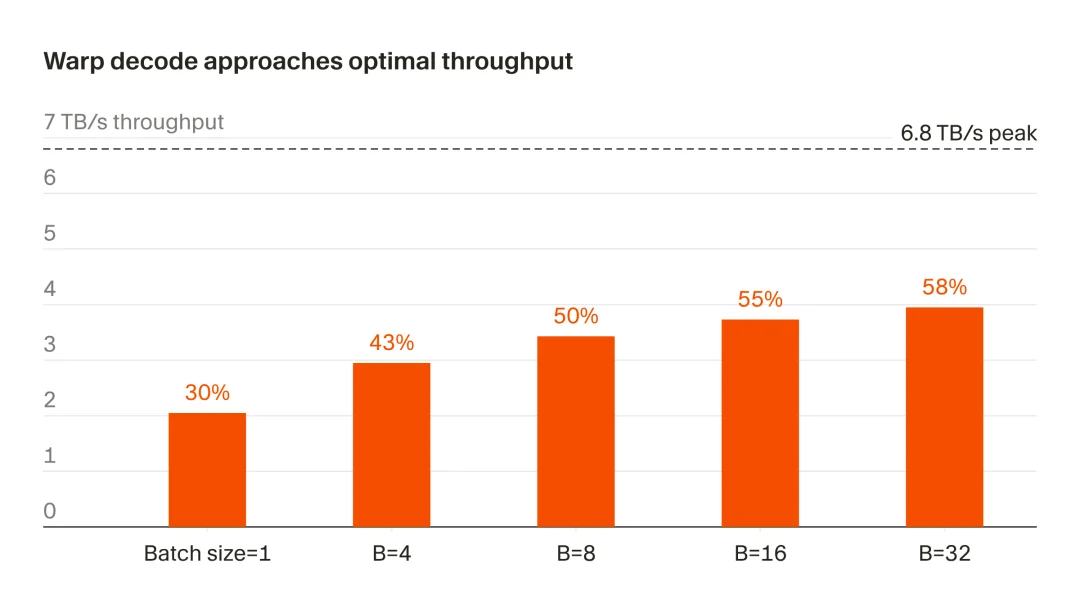
根据官方测试,效果简直好到爆炸!
在 Cursor 内部推理系统上,针对运行于NVIDIA B200的 Qwen-3 风格模型测试:
速度:端到端解码吞吐量提升1.84倍,在不同上下文长度下表现都很稳定(纯生成阶段优化)。
精度:输出与完整 FP32 参考值相比,接近程度提升1.4 倍
硬件效率:B200 在连续内存读取上的实测峰值为 6.8 TB/s (通过 copy kernel 测得) 。在 B=32 时,warp decode 可稳定达到 3.95 TB/s,相当于该峰值的 58%
在X上的网友也在体验之后表示出赞叹“这个模型非常棒。准确度提升了很多。”

也有网友提出关键问题,这个warp decode 是仅在 blackwell 上运行还是可以推广至其他平台?放到 Vera Rubin 上效果会怎么样?
根据 Cursor 官方博客,目前 warp decode 是专为 Blackwell GPU(B200)的小批量自回归解码场景量身打造的。大批量 prefill 阶段,传统MoE 方式可能还更有优势。至于未来能不能推广到其他 GPU,还得看 Cursor 后续会不会分享更多细节。
欢迎各位评论区的大佬交流,大家的Cursor速度更快了吗?
参考链接:
https://x.com/cursor_ai/status/2041260649267986643?s=20
文章来自于"51CTO技术栈",作者 "林芯"。


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
