# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型正在批量生成「看起来很像真的」学术论述,但这些论述背后的引用,真的成立吗?更关键的是:当被引论文被付费墙锁住、原文根本读不到时,自动化核验是否就注定失效?BIBAGENT给出了一个极具冲击力的答案:不破解付费墙,也能验证引文语义真伪。它首次把「不可访问原文」从验证终点,改写成一种仍可推理、仍可审计的证据场景。
在生成式 AI 全面进入科研写作之后,学术世界正在遭遇一个比「写得像不像论文」更根本的问题:它引用的文献,究竟有没有真正支持它说的话?
这并不是吹毛求疵。引用是科学论证的承重墙,决定一项结论究竟是建立在证据之上,还是只是披着文献外衣的「合理幻觉」。
现实中,错误引用并不罕见:把相关性说成因果,把局部结果外推为普遍规律,把综述包装成一手实验依据,甚至直接引用一个根本无法定位的「幽灵文献」。
而当大模型开始大规模生成流畅、完整、格式正确的科研文字时,这类问题正在被成倍放大。
于是,一个看似基础、其实极难的问题被推到了台前:我们能不能把 citation verification 这件事,真正做成规模化、系统化、可追溯的能力?
难点恰恰在于,过去绝大多数方法都默认了一个并不真实的前提:被引论文是可以读到全文的。
可现实世界里,大量论文被锁在 publisher paywall 之后。只要原文不可访问,自动化引文核验通常就会陷入两难:要么直接放弃,要么依赖零碎的搜索片段和模型脑补,给出一个听起来有理、实际上却并不可靠的判断。也就是说,最值得被严格审查的那部分引用,长期恰恰处在自动化验证的盲区里。
BIBAGENT 的真正突破,就从这里开始。

论文链接:https://arxiv.org/abs/2601.16993
很多相关工作做的是 citation classification,或者只回答一个很粗的问题:这条引用看起来「像不像支持」这句话。
但BIBAGENT要处理的是更难、也更接近真实学术审稿的问题:一条引用究竟有没有被正确使用?如果错了,错在什么层级?证据又在哪里?
为了让这个问题可以被系统地定义和评测,论文先提出了一套统一的 五类 miscitation taxonomy,把过去笼统的「坏引用」拆成五种具有操作性的错误类型:
这套taxonomy的价值很大。它让系统的输出不再只是一个模糊的「对/错」,而是一个带有错误码、证据链和解释逻辑的判断。换句话说,BIBAGENT不是在做「引用格式检查器」,而是在做引用语义审计器。
把citation verification拆成两个世界
BIBAGENT最聪明的地方,在于它没有把所有引用都塞进同一种处理逻辑里,而是非常清楚地承认:现实中citation verification天生存在两个regime。
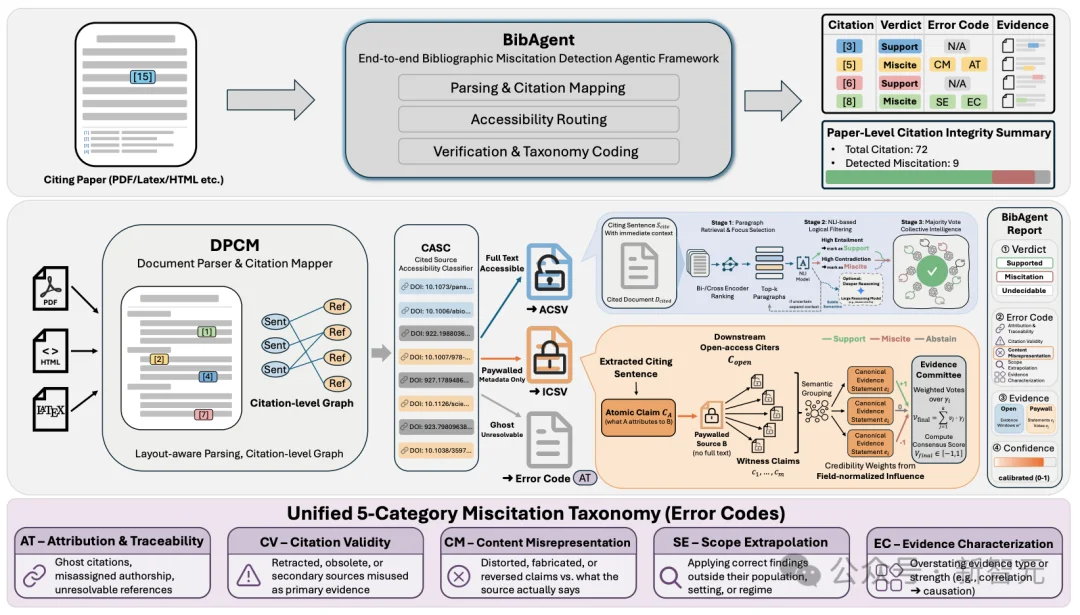
对于可访问全文的被引论文,BIBAGENT走的是ACSV(Accessible Cited Source Verifier) 分支。它没有简单把「引用上下文 + 被引全文」整篇喂给大模型,而是设计了一条更像真正审稿过程的漏斗式路径:
1. 先在被引论文中做高召回的粗检索,抓出最相关的段落;
2. 再用cross-encoder精排,把焦点缩小到更小的证据集合;
3. 随后用NLI判断哪些证据窗口明显支持、明显冲突,先解决掉一批简单样本;
4. 只有在证据弱、冲突多、语义依赖上下文时,才把问题送入更强的大模型做深度推理与自一致性表决。
这条链路看上去像工程细节,实际上恰恰击中了citation verification的要害:决定一条引用真伪的关键信息,往往并不在整篇论文里平均分布,而是埋在极少数局部窗口、限定条件、实验caveat和边界描述里。
如果把整篇全文暴力喂给模型,模型确实可能「读到了很多东西」,但也更容易被长上下文稀释、被无关段落干扰,最后输出一段流畅却并不真正grounded的解释。ACSV的核心价值,就是把判断尽可能锚定在小而准的证据窗口上。
真正让这篇论文一下子拉开层级的,是ICSV(Inaccessible Cited Source Verifier),也就是它为paywalled source设计的验证机制。
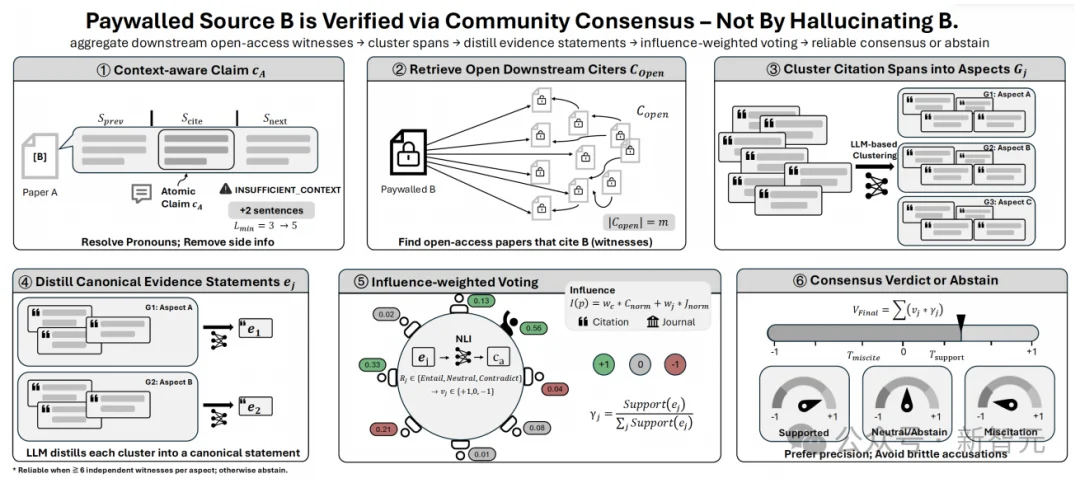
这一步的思想非常漂亮:当系统无法直接读取被引论文 (B) 时,它不再试图「假装看过 B」,也不把问题退化成一次脆弱的网页检索;相反,它把注意力转向所有后续引用了 B 的开放论文,去收集这些论文究竟是如何描述B的。
具体来说,ICSV会先把当前citing paper对 (B) 的说法,抽取成一个尽量自足、明确、去代词化的原子claim;然后在所有可访问的下游引用者中,提取它们关于 (B) 的局部引用语境,再通过语义聚类,把这些描述分成若干「方面」:
例如某篇论文的方法贡献、数据集角色、关键实验发现、适用边界等。接着,系统会为每个方面蒸馏出一条规范化的 canonical evidence statement,并结合见证论文在本领域内的影响力,对这些证据做加权。
论文把这套机制称为 Evidence Committee。
它本质上是在问一个非常有力量的问题:当原文本身不可读时,学术共同体究竟如何在后续文献中持续描述它?
这比简单搜索一个摘要、抓一段snippet要可靠得多。因为它不把单一碎片当成「原文替身」,而是把多个独立下游见证整合成一份带权重、带冲突感知、带弃权机制的「社区证词」。
最后,ICSV再把这份证词与当前引用的说法进行比对,判断它是被支持、被反驳,还是证据不足。
最关键的是,当见证论文太少、证据彼此冲突、社区记忆并不稳定时,系统不会硬判,而是明确输出Undecidable。这点极其重要。
它让BIBAGENT在paywall场景下的能力,不是「神奇猜中原文内容」,而是在证据足够时谨慎判断,在证据不足时诚实弃权。这正是一个可信核验系统该有的姿态。
为了系统评测miscitation,论文同时构建了MISCITEBENCH。这是一个覆盖254个JCR学科类别、21个高层级学科、共6,350条专家校验样本 的大规模benchmark。
它最值得注意的,不只是「大」,而是「干净」。作者专门设计了knowledge-blank cleanroom protocol:候选论文只有在一组强模型面对仅给元数据的法医式提问时全部回答失败,才允许进入benchmark。
也就是说,MISCITEBENCH有意避免让模型靠参数记忆「背题」过关,而是逼着方法真正去做citation-level reasoning。
更进一步,论文还确保benchmark与上面的五类taxonomy 一一对齐。
于是,BIBAGENT 的预测空间和 benchmark 的标签空间是统一的:系统不仅要判断对错,还必须给出错的类型。这使得它的评测目标更加接近真实科研审稿,而不是一个过于抽象的「支持/反驳」二分类。
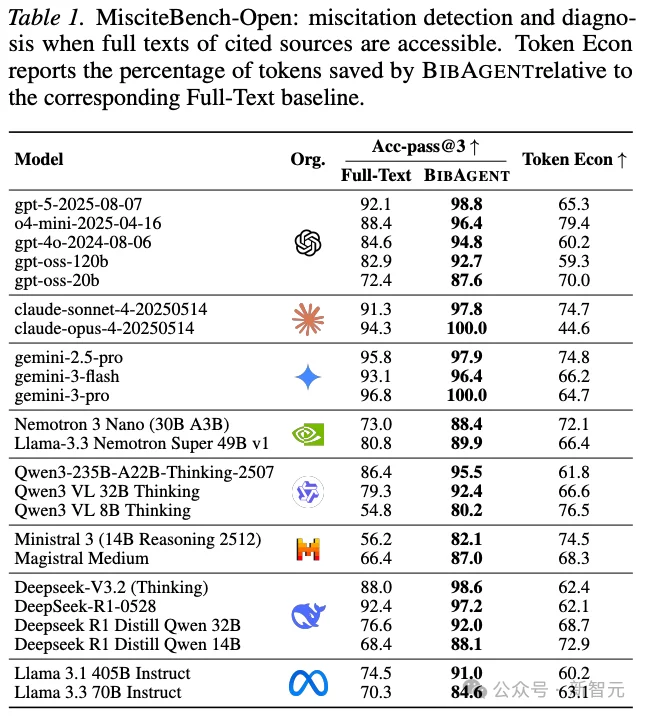
在MisciteBench-Open上,也就是被引论文全文可访问的场景,BIBAGENT相比同backbone的full-text baseline,准确率提升+5.7到+19.8个点,同时节省44.6%到79.4%的token消耗。这说明它不是靠「喂更多上下文」暴力取胜,而是靠更贴合问题结构的agentic过程,把引用核验做得更准、更省、更可解释。
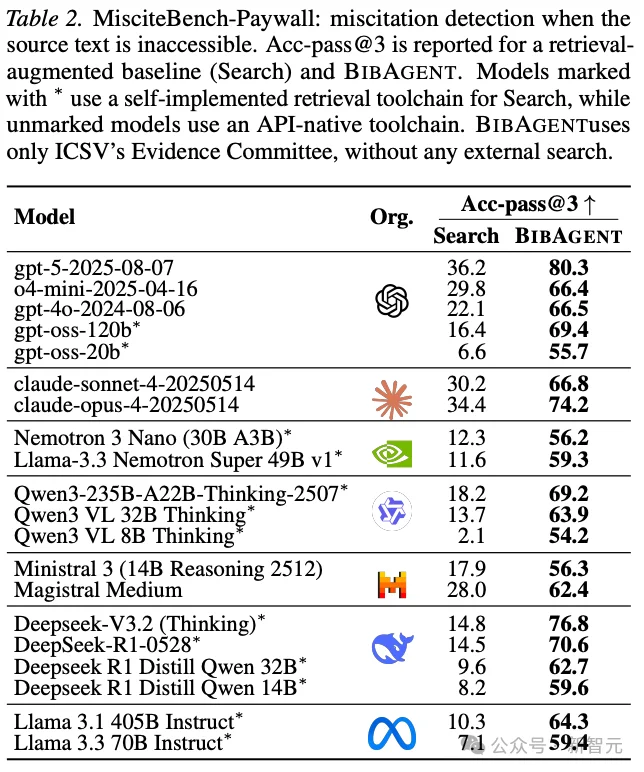
而在最难、也最有现实意义的MisciteBench-Paywall上,差距更大。 传统 Search baseline 即便允许外部搜索,在强模型上也只有22.1到36.2的Acc-pass@3;而 BIBAGENT 的 ICSV 分支可以把结果提升到66.5到80.3。更重要的是,这个提升不是靠「偶然搜到一段相似文本」,而是来自对社区共识的系统重建。
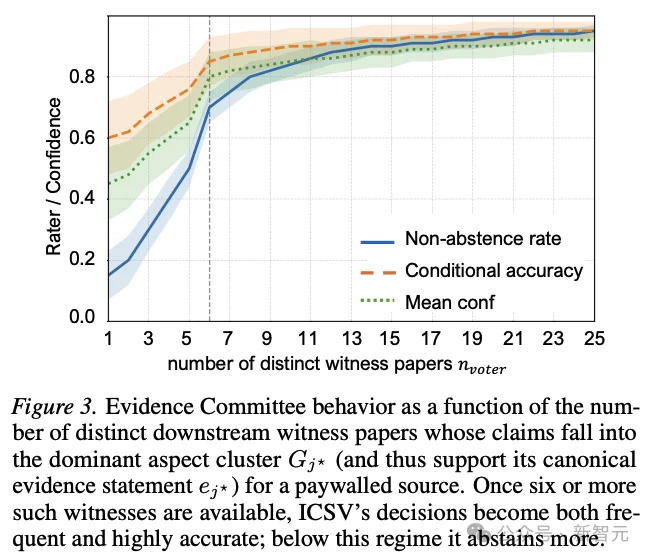
论文还做了一个非常关键的可靠性分析:当某个 paywalled source 的主导语义方面拥有至少6个独立downstream witnesses时,系统的非弃权率和条件精度都会明显稳定下来。这个结果并不只是一个数字,它揭示了ICSV的可信来源:它依赖的不是某次检索运气,而是一个可以观察、可以解释的证据密度阈值。
这篇工作的真正意义:给 AI 时代的科学写作补上一层「可审计基础设施」
BIBAGENT最值得重视的地方,不只是「又做了一个论文工具」,而是它提出了一个更深的判断:在AI 时代,写作和验证必须解耦;引用完整性不能继续停留在人工抽查,而必须进入系统审计。
它告诉我们,miscitation不是零散的写作疏漏,而是一个可以被结构化定义、规模化检测、证据化追溯的问题;它也告诉我们,paywall不应该继续作为自动化科学核验的绝对终点。
只要把「直接读原文」扩展为「重建可追溯的社区证据」,那些过去被视为无解的场景,其实可以进入一个可验证、可解释、可保守弃权的框架。
换句话说,这篇paper修补的,不是citation format,而是科学写作最底层的一条信任链:当一句学术论断被写下时,我们终于开始有机会系统地追问——这条引用,真的说了你说的那句话吗?
参考资料:
https://arxiv.org/abs/2601.16993
文章来自于"新智元",作者 "LRST"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
