# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当你和 3D 数字人对话时,有没有遇到过这种诡异时刻:它的嘴在动,但表情依旧僵硬;手在挥舞,但和说话内容完全脱节;更糟的是,那种外表像真人但动作不自然的违和感,让人瞬间陷入 “恐怖谷”。
问题的根源在于,人类沟通从来不只是语言或动作的单一呈现。一个耸肩可以表达无奈,一个点头传递认同,而微微扬起的眉毛则暗示怀疑。这些由手势、姿态与面部表情构成的非语言信号,是真实交流中不可或缺的关键维度。
当前大多数 3D 数字人的动作生成仍停留在通用动作拼接层面,难以承载复杂语义与情绪表达。而这种自然、连贯且富有情绪的表现力对 3D 数字角色至关重要:数字人需要它来建立信任,机器人需要它来与人类协作,游戏则需要它让角色更加生动。
AI 初创公司 SentiPulse 联合中国人民大学高瓴人工智能学院博士生团队的最新研究,提出了一套 3D 数字人动作生成新范式 SentiAvatar,它是用于构建具备表现力的交互式 3D 数字人框架。团队基于此打造了虚拟角色 SUSU,使其能够实时进行语言表达、动作表现与情绪传达。

今天,SentiAvatar 框架、3D 数字人 SUSU 角色模型及高质量动作数据集 SuSuInterActs 全球同步开源。

让 3D 数字人在真实对话中自然地手舞足蹈,听起来只是一个工程问题,但它实际上横跨了三个长期未被同时解决的研究缺口:
第一,高质量数据荒。现有数据集要么以英语语料为主,要么缺乏与动作同步的面部表情,中文对话场景下的高质量全身动作数据几乎空白。
第二,复合语义动作漂移。当描述从简单的“挥手”变成“无奈地耸肩”、“认同地点头” 这种复合语义时,模型的理解能力急剧退化。
第三,对话节奏错乱。模型生成的动作要么像机器人一样匀速机械,要么和语音的重音、停顿完全错位。
能不能让数字人既理解“要说什么”,又能做出能跟上说话的节奏的流畅动作?
现有方法在对话驱动的动作生成上陷入两难:全局语义对齐要求模型理解句子级的行为语义,如:无奈地耸肩,并生成宏观动作结构;帧级韵律对齐则要求动作的速度起伏精确响应语音的重音、停顿与节律变化。两者分别工作在句子级和帧级两个时间尺度,单一模型难以兼顾。
以往的共语音手势生成方法(EMAGE、TalkShow 等)将动作视为音频的低阶反射,缺乏句子级语义规划;而文本驱动的动作生成方法(T2M-GPT、MoMask 等)则完全丢弃了音频信号,无法捕捉语音韵律对动作时序的精细调制。
SentiAvatar 的出发点正是将这两个目标解耦,将句子级语义规划与帧级韵律驱动分阶段处理,而非强行塞进一个端到端模型。
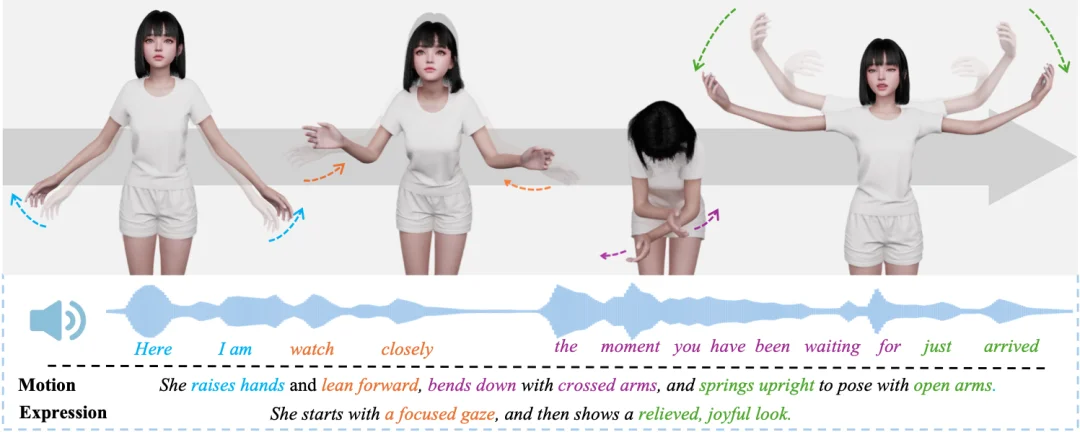
为了解决以上问题,SentiPulse 团队基于统一技术框架 SentiAvatar 打造了虚拟角色 SUSU,并构建 SuSuInterActs 数据集(包含 2.1 万段片段,总计 37 小时),该对话语料通过光学动捕技术采集,围绕单一角色,包含同步的语音、全身动作与面部表情。其次,在超过 20 万条动作序列上预训练了一个动作基础模型 Motion Foundation Model ,使其具备丰富的动作先验,能力远超对话场景本身。在此基础上,团队创新提出了一种全新的模型架构 plan-then-infill ,将句子级语义规划与逐帧的韵律驱动插值解耦,从而使生成的动作既符合语义,又在节奏上与语音高度一致。
SuSuInterActs 数据集
数据瓶颈是 SentiAvatar 解决的一个硬核问题。现有共语音数据集的两个主要局限:1) 以英语为主 2)缺乏同步的面部表情数据,在中文对话场景下尤为突出。
SentiPulse 围绕单一虚拟角色 SUSU(22 岁,温柔活泼,情感丰富),从头构建了 SuSuInterActs 数据集。该数据集包含 2.1 万段片段、37 小时的多模态对话语料,涵盖同步语音、行为标注文本、全身动作与面部表情。
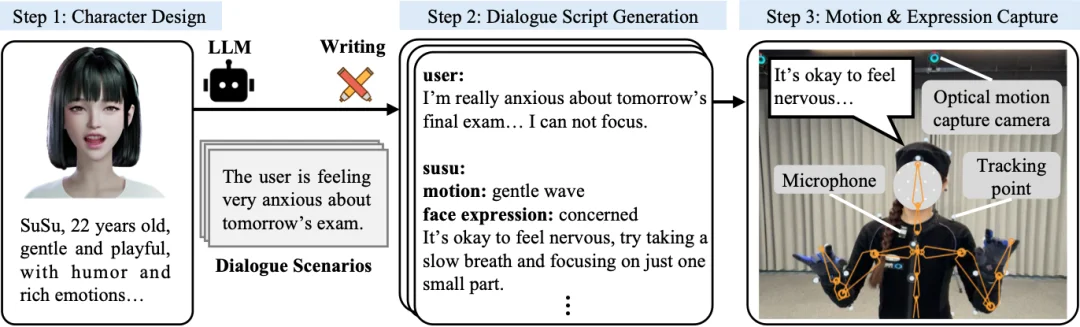
数据采集流程分四步:
最终数据集规模:21,133 条片段,36.9 小时,覆盖日常聊天、情感支持、趣味互动等多类场景。每条样本包含四路同步模态:中文对话文本(含行为语义标注)、语音音频(WAV)、全身骨骼动作(63 关节,6D 旋转表示)、面部混合形状系数(blendshape coefficient)(51 维 ARKit 参数)。其中 14,278 条含非默认动作标注,9,412 条含非默认表情标注。
聚焦单一角色是一个有意为之的设计选择,相比 BEAT2 等多角色数据集,它带来了更一致的行为模式,有利于角色特定的动作与表情风格学习。
动作基础模型:200K 序列的异质预训练
对话数据集的动作分布天然受限于对话场景。团队在预训练阶段引入了自研的 Motion Foundation Model 动作基础模型,在 200K + 条异质动作序列(约 676 小时)上训练通用运动先验。数据来源如下:
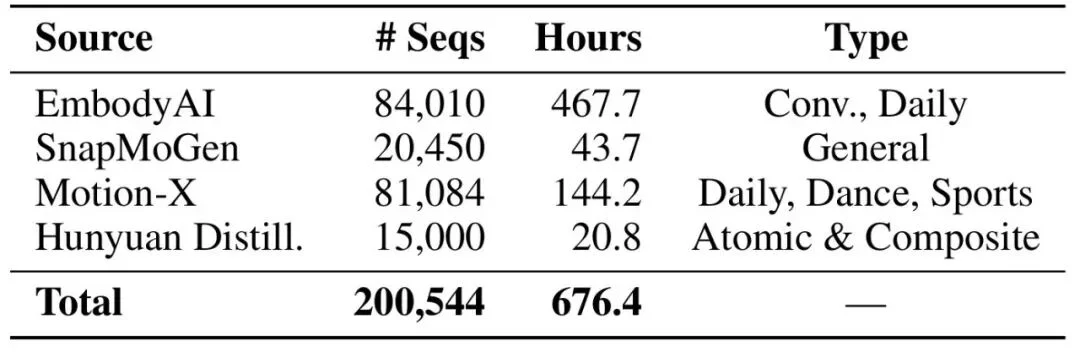
蒸馏流程值得关注:通过挖掘原子动词、LLM 扩展同义短语、组合模板生成复合动作描述(最多 4 个动作),以及引入奥运运动、仿生动作等专项类别,系统性地扩展了动作先验的覆盖边界。
基础模型以 Qwen-0.5B 为骨干,扩展词表至包含 2,048 个动作 Token(R-VQVAE,4 层残差量化,每层码本 512)和音频 Token(HuBERT K-means 量化)。预训练任务为文本-动作生成,所有文本描述统一翻译为中文,保持语言空间一致性。
核心架构 plan-then-infill
用对话生成动作的核心在于理解高层语义意图,模型需要先知道 “做什么动作”,再决定 “如何逐帧执行”,这一过程建模是一个规划问题。SentiAvatar 采用双通道并行架构 plan-then-infill,身体动作与面部表情分离处理,身体动作通道由两个串联阶段构成。
1. 身体动作通道
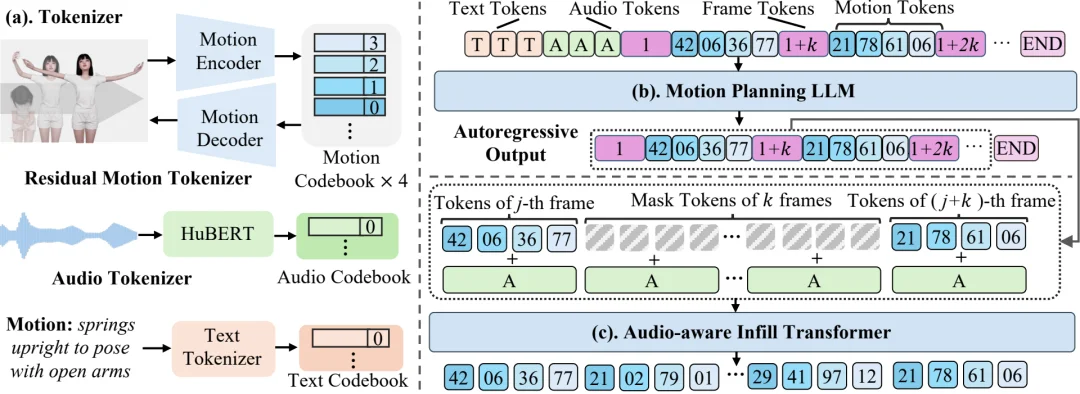
第一阶段,LLM 语义规划器接收行为标签文本和稀疏音频 Token,输出稀疏关键帧动作 Token 序列。为支持多轮流式连续生成,模型以前一句话的最后两个关键帧音频 - 动作 Token 对作为上下文前缀,从下一个关键帧位置续写,实现无缝跨句过渡。
第二阶段,Body Infill Transformer 在相邻关键帧之间填入中间 3 帧,以逐帧 HuBERT 连续特征(768 维,20FPS)作为条件信号。模型采用 5 帧滑动窗口,首尾帧已知,预测中间 3 帧(12 个动作 Token)。推理时使用迭代置信度解码策略(默认 6 步),逐步接受高置信度预测,避免一次性预测的质量退化。
2. 面部表情通道
直接绕过 LLM 规划阶段,面部表情的动态与语音韵律高度耦合,无需句子级语义规划。Face Infill Transformer 结构与 Body Infill Transformer 类似,但操作 2Token / 帧的面部离散表示,直接从音频特征生成面部 Token,再由 Face R-VQVAE 解码为 51 维 ARKit 混合形状系数序列。
两通道共享 HuBERT 特征提取,端到端延迟约 0.53 秒生成 6 秒动作,支持无限多轮流式输出。
整体实验结果:跨数据集均达最优水平
实验结果表明,SentiAvatar 在 SuSuInterActs 和 BEATv2 两个数据集上均达到了当前最优水平。
注:评测指标 ESD(Event Sync Distance),是一种用于衡量生成动作与驱动信号(如语音节奏)之间时间同步性的客观评测指标,它直接反映了数字人或机器人的动作是否 “对得上拍子”。
定性分析结果:SentiAvatar 动作生成效果最佳
团队将 SentiAvatar 与几种 3D 动作生成主流 AI 模型进行对比。下图中每一行展示特定动作与语音的关键帧序列,相同颜色的文字和箭头代表同一时间,红色箭头表示动作错误。
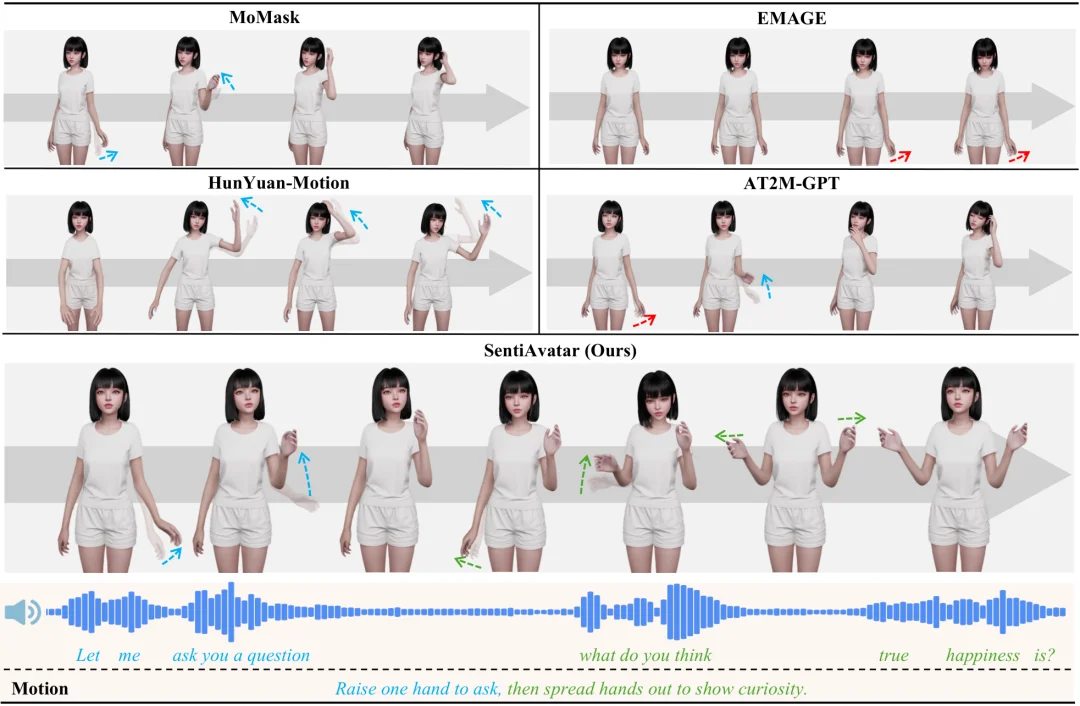
多模型对比结果:SentiAvatar 呈现出最自然的生成效果,动作语义正确,并且在时间上与音频波形高度对齐。MoMask 能够从文本标签中部分捕捉动作语义,但由于无法获取语音信息,生成的动作节奏较为静态,且与音频不存在对应关系。MEAGE 可以生成与音频同步的动作,但动作较为通用,忽略了标签中指定的语义意图。AT2M-GPT 尽管能同时接受音频和文本输入,但常常会误解动作语义。HunYuan-Motion 因未基于高质量动捕数据进行训练,生成结果中存在明显的身体畸形和不自然姿态,整体表现最差。
消融实验结果:验证核心架构各部分不可替代
在架构消融实验中,移除 LLM 规划器会导致性能大幅下降:R@1 从 43.64% 骤降至 28.06%,FID 从 8.912 劣化至 27.567,说明句子语义规划至关重要;移除 Infill Transformer 同样会导致所有指标下降,R@1 降至 27.52%,ESD 恶化至 0.503 秒,因为仅依赖稀疏关键帧会产生不连续、节奏不自然的动作。
音频条件消融进一步揭示,Infill Transformer 中的连续 HuBERT 特征是帧级同步的主要驱动力,而 LLM 中的离散音频 Token 则更多贡献于整体动作质量和节律规划,验证了 “粗粒度音频规划+细粒度音频对齐” 的协同效果。
在实验能力外,工程落地能力同样关键。SentiAvatar 实现了 0.3 秒内生成 6 秒动作序列,支持无限轮次的流式交互。这意味着数字人可以在实时对话中持续生成连贯的动作与表情,无需等待整句结束再批量处理。
今天,SentiAvatar 框架、SuSuInterActs 数据集及预训练模型重磅开源,上线 GitHub。SentiPulse 团队邀请全球对 3D 动作生成感兴趣的研究机构、开发者,共同突破 3D 数字人技术与应用的新边界。
SentiPulse 看到的未来不止于此。当前 3D 数字人的竞争焦点仍在数字人的视觉形象和基础语音动作能力,下一步技术跃迁,是构建像人一样的认知和表达能力:更完整的表达模型、更统一的人格系统、更长期的交互记忆。3D 数字人未来的竞争重心,将不再是谁渲染得更真实,而是谁能构建更完整的认知-表达闭环。
当数字人不再只是 "提线木偶",而是能感知语境、理解情绪、主动表达的交互主体,人机关系的底层逻辑将被重写,下一代 “数字生命” 也即将走进现实。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
