# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。
but,真在实际场景应用起来,还是会面临一箩筐问题——
举个栗子,想把小说做成有声书,但配出来的声音怎么听都感觉很生硬,而且口语表达效果也是个大问题。
此外,像播客这种配音场景,光配音环节就要折腾大半天,合成音频时也会面临各种合成的bug!!!
也正因如此,面对传统语音合成的种种局限问题,小米大模型应用团队提出了——
Midasheng-audio-generate与Xiaomi Any2Speech两大真实世界音频生成框架。

在模型能力上,两个模型分别支持「沉浸式音频生成」与「无边界长音频合成」。
通过大模型对角色设定、情绪变化以及整体声学场景的统一建模,让AI能够真正理解一段自然场景下的音频应该如何呈现。
在这样的生成方式下,声音不仅能够被合成还原出来,还能一体式构建出来~
这下好了,人人都能当声音导演的时代来了??
传统TTS技术的评判标准一直很直白,那就是模型能不能念好一句话,把每个字读清楚。
而Xiaomi Any2Speech的核心突破,就是让AI不再只懂念字儿,而是学会理解声学空间与叙事逻辑,真正拥有了导戏的能力。

具体来说,在播客、相声、辩论、脱口秀等多种语音对话节目生成中,Xiaomi Any2Speech都表现出了极高的可用性和真实性:
话不多说,直接来听听下面这段由模型生成的罗永浩×豆包辩论的AI效果:

模型能懂声音、会叙事,说话还自然流畅,核心靠的当然是一套全新的技术创新能力:
首先,就是能让模型理解声学空间与叙事逻辑的「Global-Sentence-Token(GST)」标注体系。
具体来说,Global层级定全局,把控场景定位、说话人画像、整体的情绪走向;而Sentence层级管局部,调整每一句话的语气、语速、表达意图,适配当下的背景状态。
Token层级抠细节,精准处理重音、多音字,甚至是笑声、呼吸声这类贴近真人表达的小细节。
三层配合,让AI对声音的理解更到位~

其次,是模型使用的Labeling over Filtering的技术思路,可以说也是反着传统TTS的玩法来的。
大家都知道以往做TTS训练时,其实都会刻意过滤掉嘈杂数据,比如多人重叠的声音、录音质量参差的素材,只留干净的音频做训练,觉得这些杂数据会影响效果。
而Labeling over Filtering的思路,则选择保留传统TTS摒弃的嘈杂数据——
通过GST标注体系将其转化为训练燃料,使模型学会从人声背景中泛化纯音效(如磁带损坏感、旧广播感)。
这样的好处很直接,那就是模型自己能学会从复杂的人声背景中提炼、泛化出各种特色声学效果~
不仅如此,在CoT思维链合成方面,模型还基于全局指令进行深度「推理」,理解场景氛围与情绪走向,再生成音频,这样一来比传统TTS更贴合场景、更有感染力。

在具体的架构设计上,Xiaomi Any2Speech采用了双路拆分+维度Dropout的思路。
把传统TTS理解与发声合并的黑盒过程,拆解成了可追溯、可干预的步骤,让创作过程的可控性大幅提升。

也正因如此,Xiaomi Any2Speech在实际落地中,不管是多人分角色对话的塑造、背景环境与人声的融合建模,还是长文本的连贯处理、剧本结构的理解,都展现出了远超传统TTS的能力。
让音频创作不再是专业人士的专属,普通人也能轻松上手做出高质量的声音内容。
相较于Xiaomi Any2Speech的长音频合成能力,Midasheng-audio-generate的模型则更强调——
用一句话实现包括人声、场景音效、音乐等的「全场景声音」重建还原。
具体来说,模型在音频合成上的亮点主要包括以下几个方面:
再来听听下面这个「黑色电影侦探在雨中的独白」合成效果如何:

能实现真实沉浸感的声音效果,背后靠的则是Midasheng tokenizer技术在支持。
具体来说,基于Midasheng tokenizer,模型用Flow Matching作为主体框架来接收文本指令,驱动背后的全能编码器,直接合成包含语音、音乐、音效的复杂混合音频。
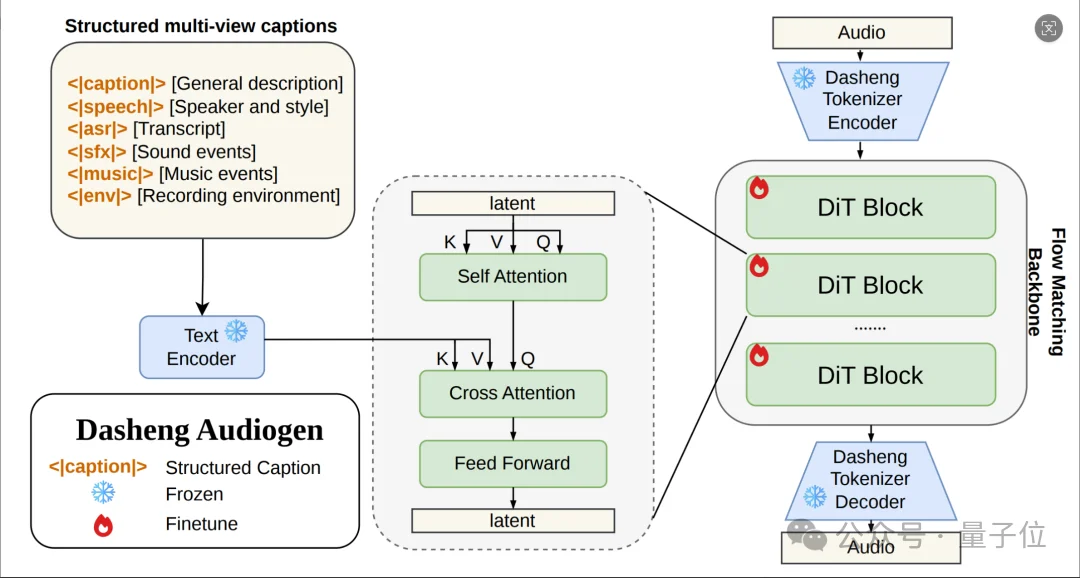
在一些官方展示和实测的效果case进行分析中,还可以看到两个模型所提出的新语音范式,也确实极大改变了语音合成的应用场景与使用思路。
最直观的例子就是在脱口秀场景中,深夜开放麦风格的演出里,起哄声与包袱抖出后观众的共鸣笑声能自然呼应。
再比如在武侠广播剧场景中,江湖夜雨、刀光剑影的氛围配合人物对白与环境音效,营造出沉浸式的武侠世界。
在原始输入中,不用像传统TTS一样标注明确的观众笑点、起哄声或者鼓掌声,模型均可以根据上下文语意自然推断,形成呼应,说明模型「场景语义」有深刻的建模理解。
模型通过语速、音量、混响的协同变化,可直接塑造角色压迫感与空间紧张感,省去传统配音中单独配乐的环节。
同时,语气词、拖音、断句节奏也不再是合成瑕疵,而是传递人物气质的重要介质,借由声音侧写,呈现与内容高度契合的人物人格。
而所有场景共享同一个自然语言instruction接口,一句话描述你想要的效果,无需切换模型或pipeline就能实现。
当模型能够基于语义自动生成情绪、环境与互动反馈,声音合成也就逐渐成为内容生产的一部分,甚至是内容本身。
可能未来的语音生成,不再需要复杂的多轨配音流程了,也不再依赖精细的人工标注,而是通过自然语言直接驱动完整的声音场景生成。
参考链接:
【Xiaomi Any2Speech相关链接】
[1]项目地址:https://Any2Speech.github.io/
[2]Openclaw技能:https://clawhub.ai/whiteshirt0429/xiaomi-Xiaomi Any2Speech-beyondtts
【Midasheng-audio-generate相关链接】
[1]Demo:https://nieeim.github.io/Dasheng-AudioGen-Web/
[2]Openclaw技能:https://clawhub.ai/jimbozhang/midasheng-audio-generate
文章来自于"量子位",作者 "小米大模型应用团队"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
