# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,世界模型初创公司 Feeling AI 正式发布并开源 MemBrain1.5 和 CodeBrain-1。这两项在全球 Agentic 领域的顶尖工作同时开源,将正式终结 AI “无状态” 的工具时代,为世界模型植入具备自主逻辑与层级化记忆的 “原生大脑”,开启人机深度协同的交互新范式。
CodeBrain 作为具备动态规划与策略调整能力的 “进化大脑”,它通过优化任务的执行逻辑和错误反馈机制,显著提升了模型在真实终端环境下的操作成功率。在技术实现上专注打磨了两个直接影响 “能否成功且高效地完成任务” 的环节。一则是 Useful Context Searching:只用 “真正有用” 的上下文,二则是 Validation Feedback:让失败真正变成信息。
春节前 CodeBrain-1 搭载 GPT-5.3-Codex 底座模型更是在衡量 Agent 真实工程能力全球权威基准 Terminal-Bench 2.0 榜单上一举冲到 72.9% 并跻身全球排行榜前列,成为榜单前 10 中唯一的中国团队。
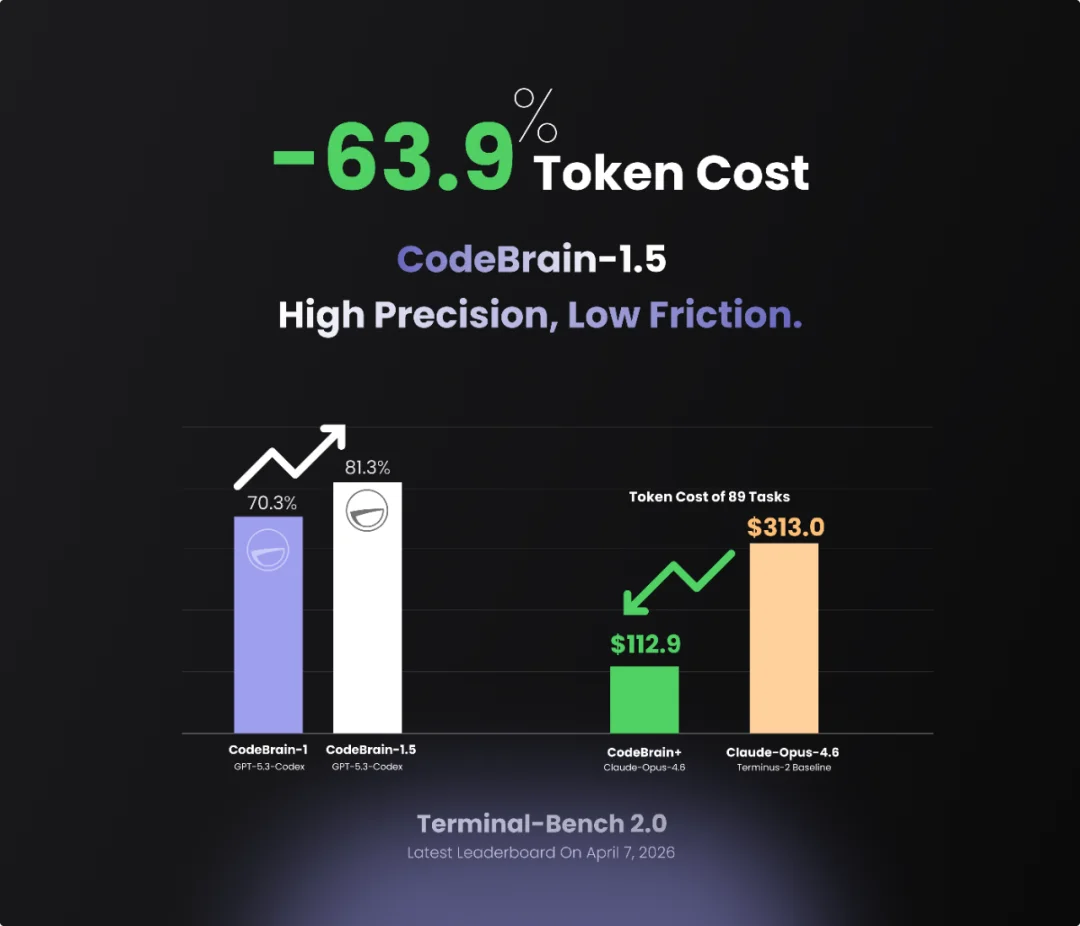
CodeBrain-1.5 持续领跑全球:性能更优、成本腰斩
除了此次开源的 CodeBrain-1,CodeBrain-1.5 以 81.3% 的成绩,持续领跑全球开源和闭源队列,在 Claude-Opus-4.6、MiniMax-M2.5、GLM-5、Qwen3.5 等 Terminus-2 Baseline 的基础上均能大幅提升基座模型的成绩和性能表现。
天下苦 Token 又费又贵久矣!
值得一提的是,除了技术指标的持续领先,CodeBrain 还大幅降低了开发者和付费用户的使用成本。在 Terminal-Bench 2.0 的 89 全量任务测试中,使用 Claude-Opus-4.6 的 Token 成本为 $313.0,而在 CodeBrain 的加持下这一成本仅为 $112.9,直降 63.9%。这也证明了结构化感知不仅是精度问题,更是商业和生意问题。
实践中的弊端越来越明显:缺乏编译器级别的诊断
目前的顶尖 Agent(如 Claude Code、Cursor、OpenCode)缺乏结构化的代码智能,在处理小型文件时表现惊艳,但一旦进入多语言、数百万行代码的 Monorepo(大仓库),便会陷入 “情报困局”。它们通常依赖原始的文本搜索(grep)和文件读取(cat)来理解代码,目前没有标准方式让 Agent 在编辑循环中获取编译器级别的诊断、符号导航或影响分析。这种方式在工程实践中的弊端已经越来越明显:
5 层架构:任何 Agent 均可调用的工业级逻辑大脑
Agent 的大脑在加速迭代中始终缺乏一套能看穿代码逻辑的 “视觉神经”。针对这一瓶颈,CodeBrain 给出了一套极具工程美学的解决方案。它不是一个简单的 Prompt 集合,而是一个分为 5 层、约 7,600 行代码的 Python 库 + MCP 服务器,将 LSP 语言服务器和 tree-sitter 语法封装为 11 个面向意图的工具,任何 Agent 均可调用,并赋予 Agent 架构师级的逻辑直觉。其 5 层可堪为工业级架构包含:

此外,在此次开源的版本中还支持了多种供开发者灵活使用的功能:
开发者直接在 Claude Code 调用工具和 MCP 演示
让 Agent 从 “工程师助手” 变为 “可信赖的交付专家”
基于严谨的架构设计和众多灵巧的功能特性,CodeBrain 为 Agent 实打实带来了顶尖工程师级别的能力升级和成本节省,让 Agent 真正从 “聪明的工程师助手” 变为 “可信赖的交付专家”。
在 OpenAI 和 Anthropic 持续推高上下文窗口的上限时,MemBrain 的破局点在于用 Agentic 原生思路重构整个记忆系统。MemBrain 在算法结构的优化中,让记忆系统学会 "主动思考",针对长时上下文进行了深度的结构化工程优化,以及让 Agentic Memory 主动适配大模型原生能力,深度参与推理。
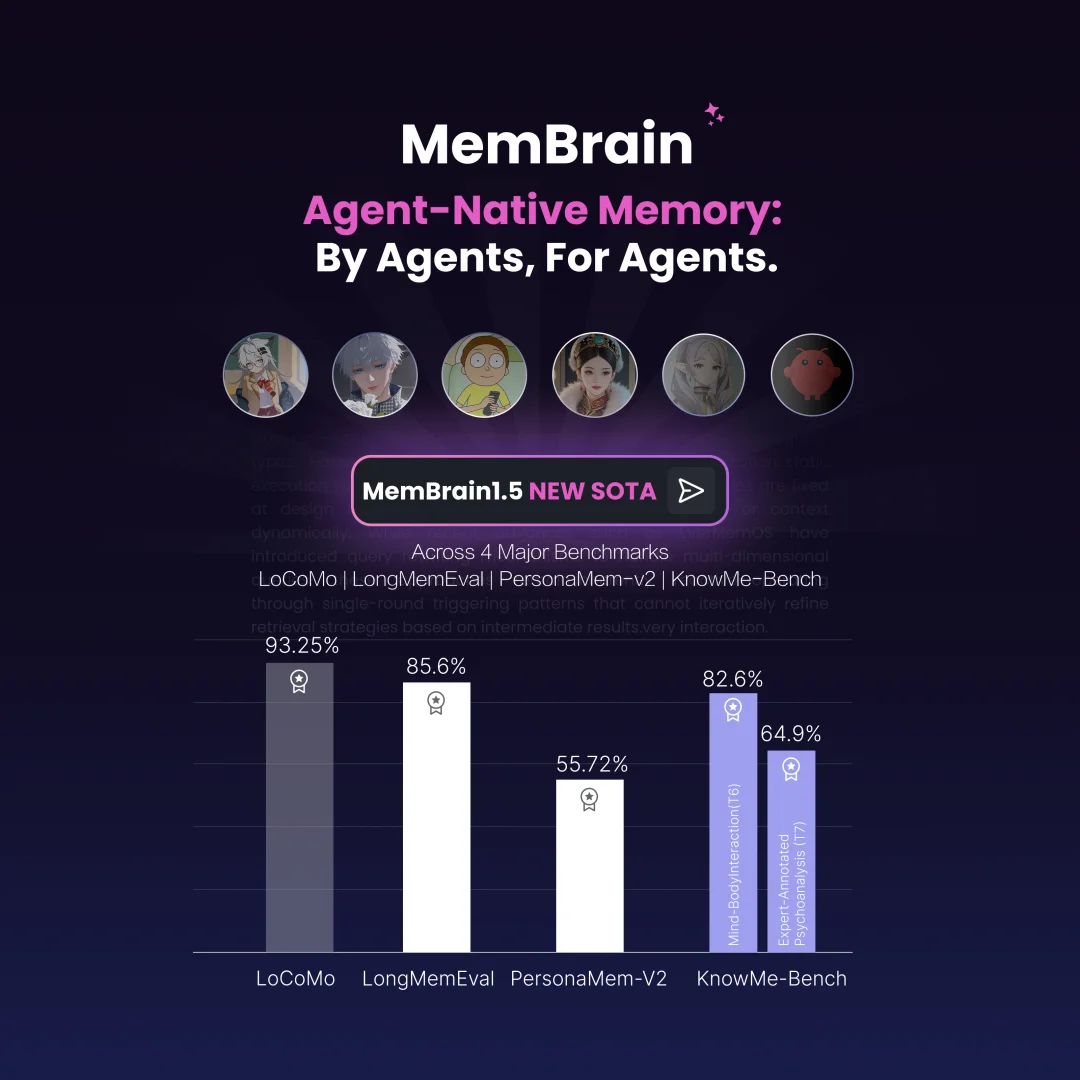
MemBrain 1.5 再次刷新多项主流测试 SOTA
MemBrain1.0 在 LoCoMo / LongMemEval / PersonaMem-v2 等多项主流记忆基准评测中拿下全新 SOTA,反超 MemOS、Zep 和 EverMemOS 等记忆系统和全上下文模型;在 KnowMeBench Level III 两个难度等级最高的评测中更是比现有评测结果大幅提升超 300%。
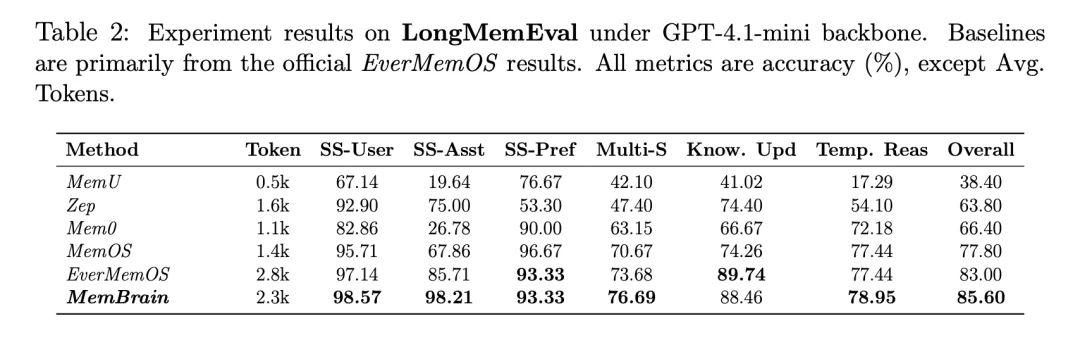
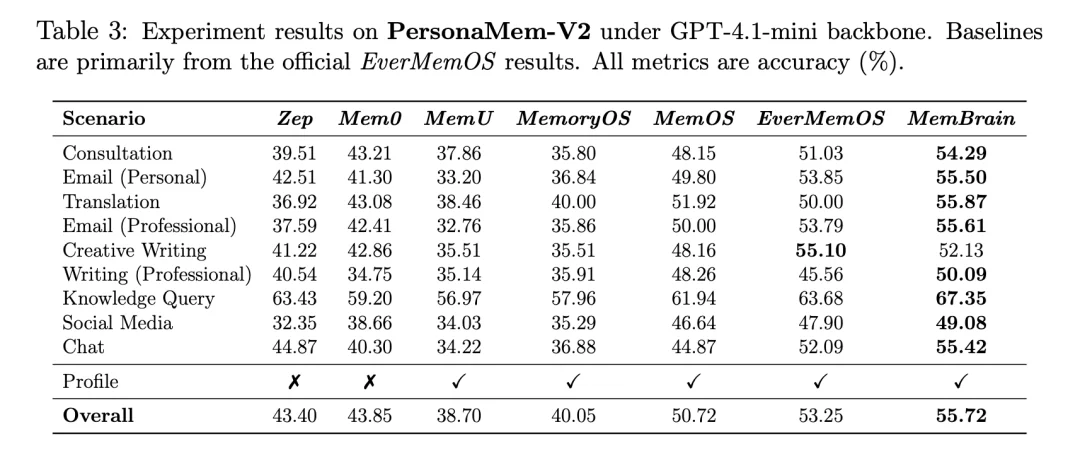
对比一个多月前的 1.0 版本,MemBrain 1.5 除了在各项主流基准评测中的分数均显著提升外,团队还通过自适应实体树算法等创新,进一步对记忆存储、组织和检索等策略进行了优化迭代。
纯文本和图结构都无法解决 Agent 的记忆难题
“一切皆文件” 的纯文本方案(如 OpenClaw)简单透明,格式上天然贴合 LLM 的阅读习惯。LLM 可以自主设计目录结构,文件路径本身便构成一种层次化的组织方式,记忆以自然语言形态存储,语义保真度高,表达灵活。但当同一条信息与多个上下文相关时,这些跨上下文的关联并未被显式建模 —— 它们散落在不同文件的自然语言段落中,系统层面没有机制将它们结构化地关联起来。但代价是把太多决策交给了 LLM—— 哪些信息值得记、怎么组织、新旧矛盾怎么处理,全靠 LLM 即时判断。记忆的存储和索引完全依赖自然语言结构,变更难以溯源审计;检索主要靠 LLM 调用基础工具逐个翻文件;记忆的管理和维护本身也需要大量 LLM 调用,token 消耗不经济,响应延迟随记忆量增长而恶化。
图结构方案(如 Graphiti)走向了另一侧。它把知识拆成三元组存入时序知识图谱,每条边带有时间有效窗口。工程基础恰好补上了纯文本方案的短板:结构化程度高,溯源审计天然可做,embedding、BM25、图遍历等检索手段都能方便集成,也支持流式处理和异步更新,查询实时性好。但仍然存在一个根本性矛盾:当下主流基座模型的架构更适配线性或树状的信息排列,而图结构的检索主要依赖图算法完成,LLM 无法深度参与搜索过程本身,只能在后续的结果聚合和 "翻译" 环节介入 —— 将三元组和实体摘要拼成可用的上下文。这个过程不可避免地伴随语义损耗。
纯文本方案保留了语义保真却缺失显式关联,图结构方案建立了显式关联却牺牲语义保真 ——MemBrain 1.5 尝试从记忆组织拓扑方向上同时回应这两个问题的一小步。
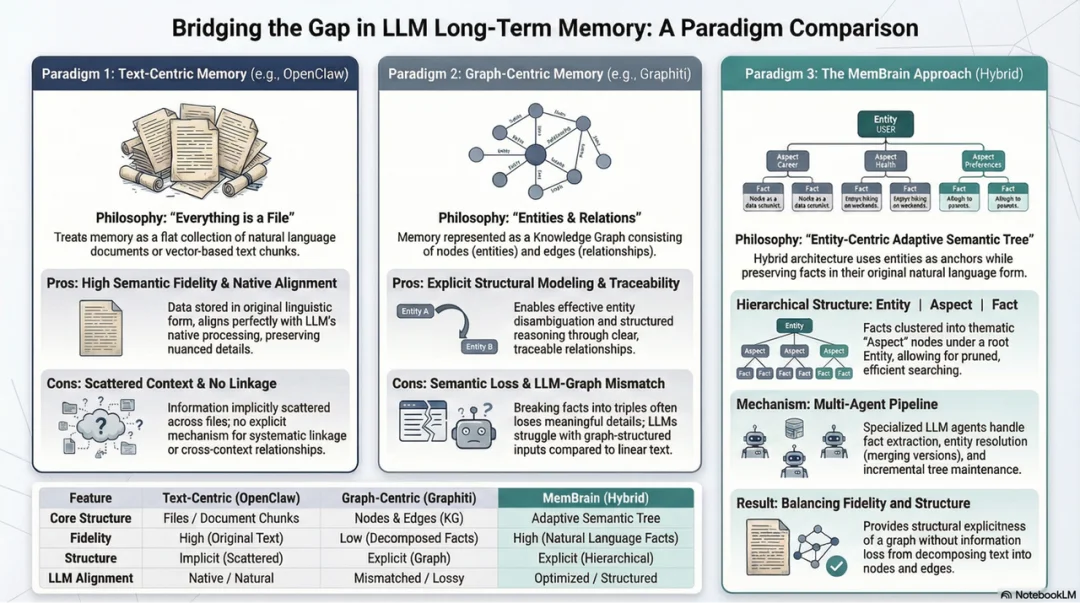
MemBrain1.5 持续进化的记忆组织拓扑
记忆的写入、组织、检索与过期,每个环节都需匹配精密的工程约束:既不能简单地将其全盘抛给模型,也不该用僵化的工作流将模型彻底锁死。MemBrain 1.5 新加入了自适应实体树算法,从记忆组织拓扑持续优化 Agent 原生记忆能力。核心思路是在记忆管理的设计中,一部分由预定义的结构约束确定,一部分留给 Agent 去探索怎么用好。
以实体为中心,用自适应语义树在两者之间建立桥梁。树的叶节点是从对话中提取的原子事实,中间层是由 Agent 按主题聚类生成的语义分支。树的骨架 —— 层次路径、深度限制、分支上限 —— 是先验的工程约束;树的内容 —— 怎么聚类、怎么摘要、新事实归入哪个分支 —— 由专用 Agent 动态决定。输出天然按 “实体 → 主题 → 事实” 分层组织,LLM 直接阅读即可。写入侧,多 Agent 流水线承担事实抽取、实体消解、结构更新;检索侧,Agent 的参与程度随问题复杂度渐进升级。先验的工程结构承担 80% 的重活,Agent 的智能聚焦在真正需要判断的 20% 上,这无疑既可以提升效率又能降低成本。
一次性解决 3 个关键难题:通过算法层的设计和创新解决信息怎么存、怎么组织和怎么找。
传统图方案把知识拆成 (A, 关系,B) 三元组 —— 一句自然语言就能说明白的事情,要拆成多条边才能存进图里,既困难又有损,语境关联在拆分中不可避免地断裂。
MemBrain 的原子事实走另一条路:每条事实本身就是一个 "小子图",自带时序信息,同时通过别名关联到多个实体,天然无需拆分,并以统一的格式规范保证结构一致。别名指向实体本身,而实体的描述可以随对话不断演化 —— 因此每条事实本质上是一个可渲染的模板:事实内容稳定不变,但其中关联的实体信息始终跟随最新状态。当事实作为检索结果返回时,别名按需被动态替换为规范名称和最新描述,最终给到 LLM 的文本既精确又自然,无需额外的格式转换,同时附带了更丰富的上下文。
这是 MemBrain 与图方案最根本的结构差异。当一个实体在多条原子事实中反复出现,它就具备了聚合价值 —— 我们为这样的实体维护一棵语义树:根节点是实体,中间层是 Agent 自动聚类的主题分支,叶节点是具体事实。树的每条路径本身就承载了连贯的语义信息,从实体到主题再到事实,层层递进。
这棵树支持在线增量维护:事实较少时保持平坦结构,积累到阈值后由聚类 Agent 自动升级为层次结构;新事实由分配 Agent 判断归入哪个分支,过载时自动分裂,并定期异步聚合。维护复杂度随数据量平缓增长,无需全量重建。同时,树结构也提供了一条天然的检索路径 —— 沿主题分支向下导航,输出按 "实体 → 主题 → 事实" 分层组织,给到 LLM 的是一份结构清晰的简报,而非一堆需要自行拼凑的线索。
大多数查询走多路并行,一次出结果:全文检索、向量检索等传统手段负责召回,MemBrain 独有的树检索从主题分支提供全局视野,加上别名指针自动带入实体的上下文信息,无需额外调用 LLM 即可快速响应。当问题需要跨主题聚合或推理时,系统启用多查询扩展,由 LLM 将问题改写为多种互补形式分别检索,拓宽召回面。而遇到涉及多个实体、多条时间线、单轮难以覆盖的问题,则开启 Agentic 模式:第一轮检索后由反思 Agent 分析信息缺口,判断 "已经找到了什么、还缺什么",再定向补检。
Agent 的判断力被精确地用在它最擅长的地方 —— 判断信息够不够、缺什么、怎么补 —— 而不是去操心底层的索引和排序。
社区开发者和普通用户也可以轻松上手测评
开源的内容除了技术 Report 和源代码外,社区用户和开发者还可以直接通过一个前端 Demo 进行体验。用户只需在本地部署后配置自己的 LLM API KEY,即可在带有系统提示词的 AI 助手引导下,快速了解 MemBrain 的使用方法。
为方便用户测试,在 Chat Demo 中用户可以选择已有人设信息的模版角色,也可以自己创建新角色并赋予角色个性化的人设信息,随即展开一段记忆能力超绝的聊天体验。
卓越的记忆能力为模型赋予了 “灵魂”。随着 Memory 成为 Agentic AI 基础设施层的核心标配,我们正在见证 AI 从 “无状态” 的单次调用,向 “有意识” 的长程进化跨越。MemBrain 这种原生层级化记忆系统的出现,标志着 Agentic AI 正从单一的模型能力演进为深度的用户体验升级 —— 一个与用户共同生长、深度耦合的共生型 AI 时代已正式开启。
此外,针对 Memory Database 可视化,团队还开源了一个 Benchmark Evaluation 的可视化工具,以便开发者更清晰的了解算法执行的情况。
Agentic Memory 实用的工程经验与未来方向
此外,Feeling AI 还分享了一些实用的工程经验与未来方向。
数据库不应该仅仅是存储待检索对象的容器,它是记忆系统最重要的基建。他们的开发经验是,把数据库与记忆系统的耦合做得越紧密,收益越明显。可溯源、可审计、可隔离、可同步 —— 这些能力让实验和迭代的节奏快了很多:每一步操作都有迹可循、可以回滚,试错成本极低。当基建足够扎实,Agent 在记忆管理中的每一次决策和结果都会自然地沉淀下来,成为系统持续改进的养分。
团队还提到,另一个值得关注的方向是检索过程本身的信号价值。 目前对记忆系统的评测普遍关注最终答案对不对,但检索路径本身也在暴露记忆的组织方式与实际问题分布之间的 "摩擦"。一个自然的想法是:在检索过程中顺便对所经路径上的记忆做轻量的动态调整,让记忆组织自发地向高频问题的分布靠拢 —— 每次调用不只是在 "取东西",也在顺手理货。真正的挑战在工程侧:怎么保证增量更新的稳定性,怎么把重组成本均摊到日常维护中异步消化,而不拖慢响应。
一个真正的 “世界模型”,不应只是现实的镜像,而应是现实与 “智能大脑” 的有机合体。Feeling AI 认为动态交互是世界模型通向 AGI 的终极拼图 —— 如何让世界模型真正走向动态世界的智能交互,而世界动态交互的核心也正在从 “人” 变为 “人和 AI”,多模态融合是世界模型的原生框架。
缺乏认知与推理能力的世界模型只是一个 “没有灵魂的空壳”。这就需要在世界模型的底层架构中,为世界模型配上 “原生大脑”,并设计好 Agentic 原生的多模态交互协议接口,这直接关系到用户交互的体验。其原创的跨模态分层架构提出了三层核心能力 —— 负责理解、记忆与规划的 InteractBrain,负责能力执行的 InteractSkill,以及负责渲染呈现的 InteractRender,MemBrain 与 CodeBrain 都属于 InteractBrain 部分,通过层级化记忆与代码级理性的深度合成,精准定位在复杂动态交互场景下的深度理解与长程规划。
此外,Feeling AI 创始人戴勃在最新接受媒体专访时还透露,团队在核心层 InteractSkill 部分也取得了重要进展,正在训练一个全新架构的动力学世界模型,在 3D 原生的结构下通过原创的 IKGT 算法(Interactable Kinetics Grounded Transformer),实现对人类运动交互的生成与状态预测,模型首次在 CPU 上跑出 300FPS 的响应速率,且模型通过实时推理达到了 100% 的状态重置和纠偏,鲁棒性极强。
动态交互底层模型能力的补齐,将与空间智能(李飞飞教授 World Labs)以及因果逻辑和常识智能(Yann LeCun AMI),共同加速世界模型底层基础设施和核心能力的构建。
中国团队持续在 Agentic 大脑和世界模型的底层能力比拼上,正以定义者的身份参与全球技术升级到工程和商业落地的闭环。从大语言模型到世界模型,从文字对话到多模态动态交互,生成式 AI 也许正在经历一个必然的拐点 —— 全新的范式将在 “人与 AI” 的深度协同中形成,而世界模型正引领 AI 从 Next Token Prediction 走向更高维的 Next State Prediction。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
