# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多镜头视频是视觉叙事再正常不过的表达形式。
但在视频生成领域中,其高质量实现颇具挑战。

与单镜头视频不同,多镜头视频并不是简单地把几个片段拼接起来,而是要求模型同时处理两类信息:一类需要在不同镜头之间保持稳定,例如人物身份、环境主体和故事主线;另一类则需要随着叙事自然变化,例如视角切换、动作推进和场景转场。
这一任务通常可以定义为:给定每个shot的prompt,以及一个可选的初始图像作为首帧条件,模型需要生成多个shot,并维持跨shot的内容一致性和对每个shot prompt的准确遵循。
这意味着,模型必须能够持续维护长程的跨镜头上下文。然而,现有方法大致存在两类局限:一类方法依赖固定窗口,在窗口内同时生成多个shot,但随着窗口滑动,较早镜头的信息会被丢弃;另一类方法则仅依赖单张关键帧作为条件,难以有效传递shot内更复杂的叙事细节。
最近,来自Meta与University of Copenhagen的研究者提出了OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory(收录于CVPR 2026)。这项工作聚焦于一个核心问题:如何在生成多镜头视频时,有效保留长程跨镜头上下文,从而实现更强的叙事一致性。其核心思路,是为多镜头视频生成建立一种全局但紧凑的跨镜头记忆机制。
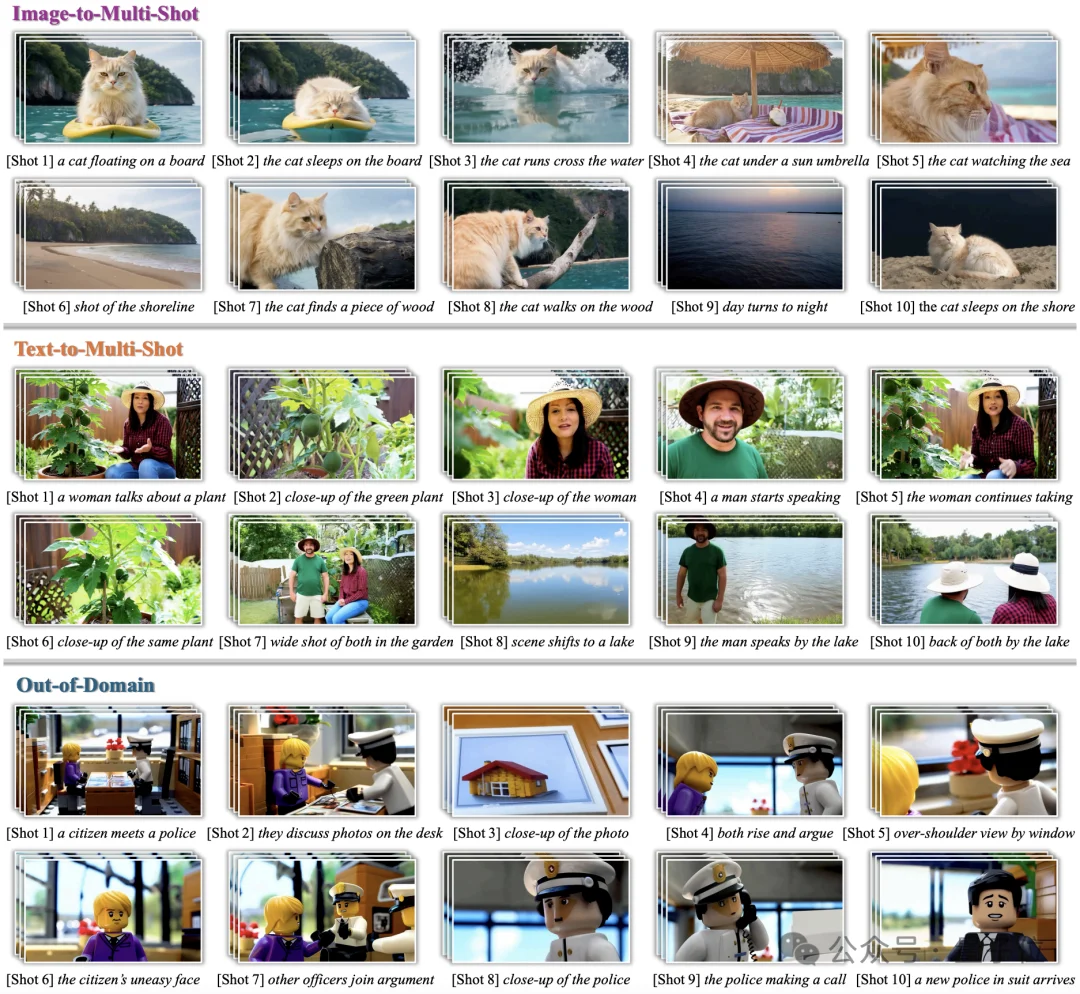
OneStory可生成分钟级、十镜头的长视频故事,在复杂叙事推进过程中保持人物与场景的一致性;同时支持image-to-multi-shot与text-to-multi-shot两种生成设置,并在out-of-domain场景中展现出良好的泛化能力。
OneStory首先将多镜头视频生成重新表述为一个更自然的问题:next-shot generation。也就是说,模型不再一次性生成整段长视频,而是像讲故事一样,基于前面已经生成的镜头,生成下一个镜头(每个镜头同时生成)。这样的设定实现了shot-by-shot的自回归式多镜头生成。
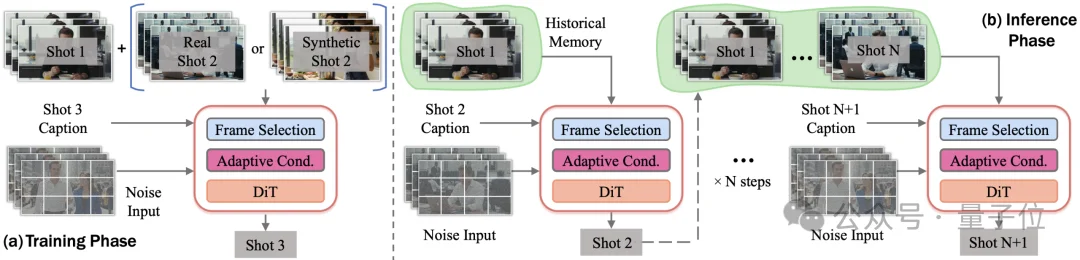
与此同时,OneStory以预训练的image-to-video基础模型作为初始化,因此可以自然继承基础模型本身强大的视觉条件生成能力。通过这样的任务重构,OneStory的第一个shot可以通过使用任何text-to-video或image-to-video模型得到,而后续shot则由OneStory根据输入的shot prompt逐步生成。
也正因如此,OneStory能够在同一个模型中统一支持text-to-multi-shot video和image-to-multi-shot video两种生成方式。
在此基础上,OneStory设计了两个关键模块。
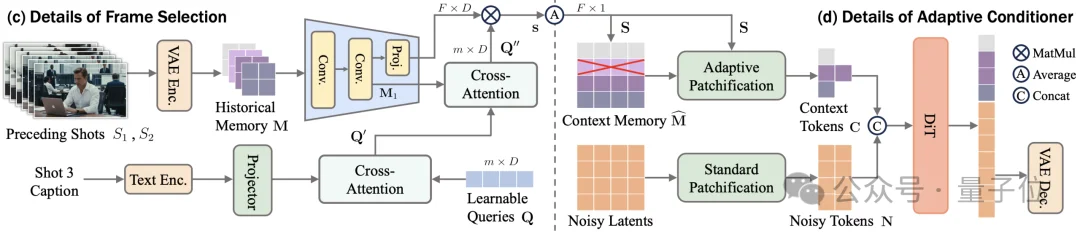
并不是所有前序镜头对当前镜头的生成都同等重要。
例如,第1个镜头中出现主角,第2个镜头切换到配角,第3个镜头又回到主角。那么在生成第3个镜头时,第1个镜头往往比第2个镜头更关键。基于这种跨镜头相关性不均等的现象,OneStory引入了Frame Selection模块,从所有历史镜头中自动挑选出与当前镜头prompt在语义上最相关的一些帧,作为当前shot生成时的memory。
这一设计不仅避免了固定窗口滑动带来的遗忘问题,也使模型能够真正构建起全局的跨镜头上下文。
仅仅“记住”还不够,如何高效地将这些历史信息输入生成器同样关键。
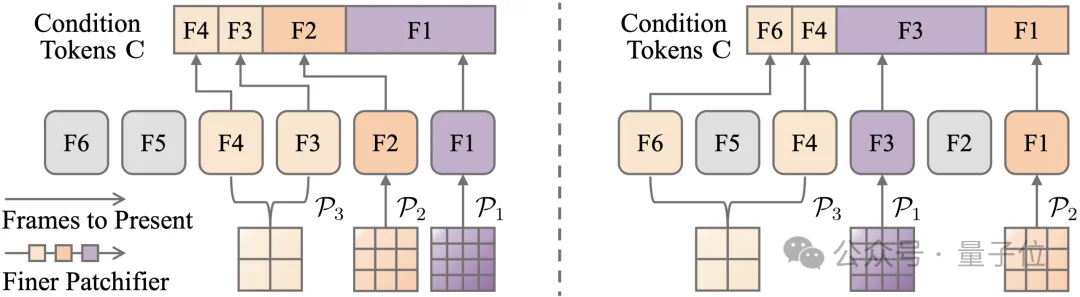
OneStory的Adaptive Conditioner会根据Frame Selection模块预测的重要性,对选中的历史帧进行自适应patchification:更重要的信息保留更细粒度的表示,不那么关键的信息则被更强地压缩。这样一来,模型就在计算成本可控的前提下,将历史上下文转化为紧凑而有效的条件信号,并直接注入生成过程。
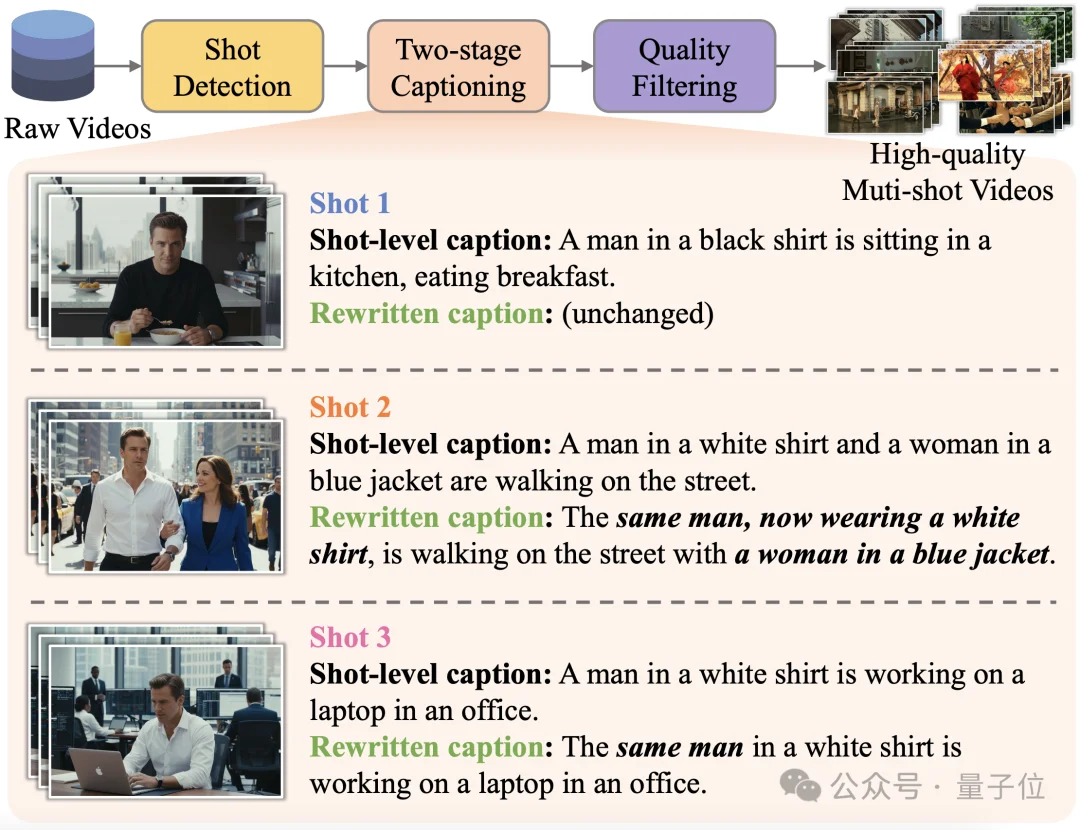
此外,论文没有沿用“整段故事需要一个总脚本,再辅以分镜头定义”的数据构建方式,而是仅保留分镜头prompt,并将每个镜头写成带有前文指代关系的描述。这样的数据形式更贴近真实的故事讲述逻辑,也让镜头之间能够形成更自然的叙事流。

各实验表明,OneStory能够在复杂提示不断变化的情况下持续推进叙事,同时保持人物和环境的一致性。论文中也提供了对OneStory在复杂叙事场景中的表现分析,包括:
这些现象说明,OneStory学到的并不只是表层的视觉连续性,而更接近于一种跨镜头叙事理解能力。
如果说单镜头视频生成解决的是“把一段画面做出来”,那么多镜头视频生成真正要解决的,就是“把一个故事讲下去”。
OneStory给出的答案是:不是一味拉长上下文窗口,也不是依赖单张关键帧,而是通过自适应记忆建模,在全局信息建模能力和计算效率之间找到平衡。它让模型在跨镜头生成时,既能够记住过去,又不会被冗余信息淹没。
对于长视频生成和可控世界模型而言,这是一条非常值得关注的方向,因为OneStory为视频模型提供了一种有效的自适应memory管理机制,也为更长时程、更高一致性的视频生成打开了新的可能。
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
