# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
米哈游蔡浩宇的AI公司Anuttacon,首个视频模型正式曝光!
Anuttacon技术团队成员@Ailing Zeng,在X上展示了全新视频角色表演生成模型——LPM 1.0。
主打一个让AI角色人物表现得更《出神入化》~
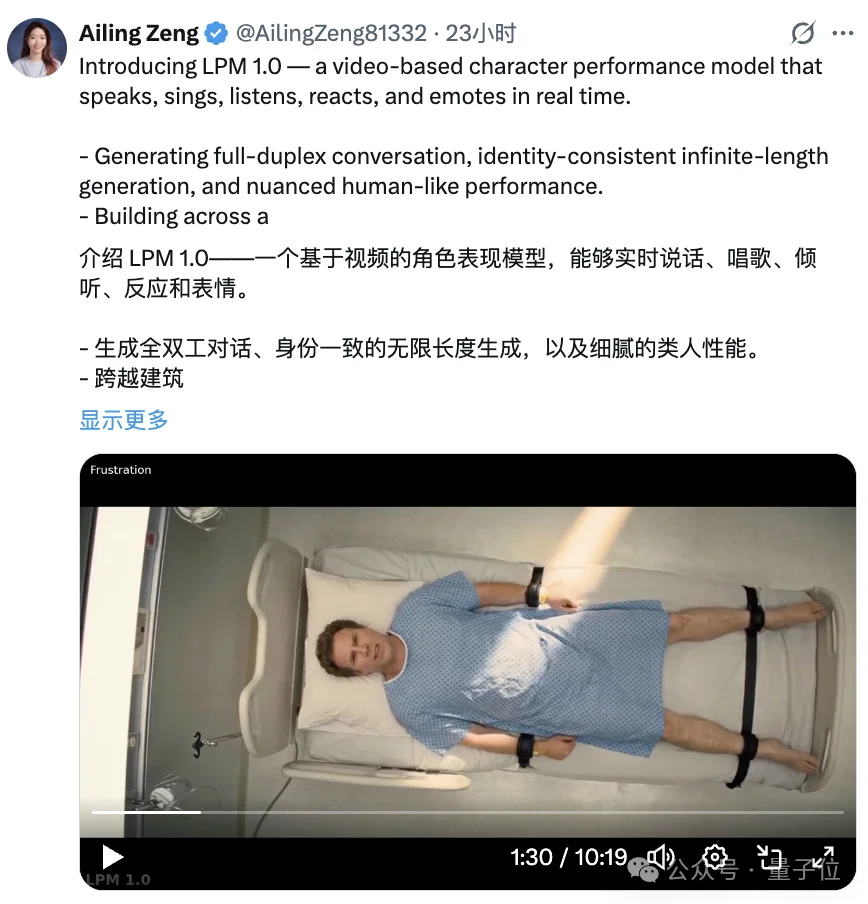
大家先看下面这位AI小哥,生动演绎了一场16秒变换N种情绪的超绝大戏,你就说这情绪拿捏到不到位吧:

不仅如此,在LPM 1.0模型中,连让AI人物「听别人说话」这事儿也同步进化了。(天呐.jpg)
哪怕不张口、只是安静坐着当一个认真聆听的人,角色的表情、眼神和情绪反馈也都在线,这情绪价值给的:

此外,我们还可以和AI进行「实时互动」。
只要对着电脑屏幕说一句自己的甲方需求,屏幕里的AI角色就能够根据指令当下做出反应。
哪怕是在长时间交互下,依旧能保证人物形象稳定一致,be like:
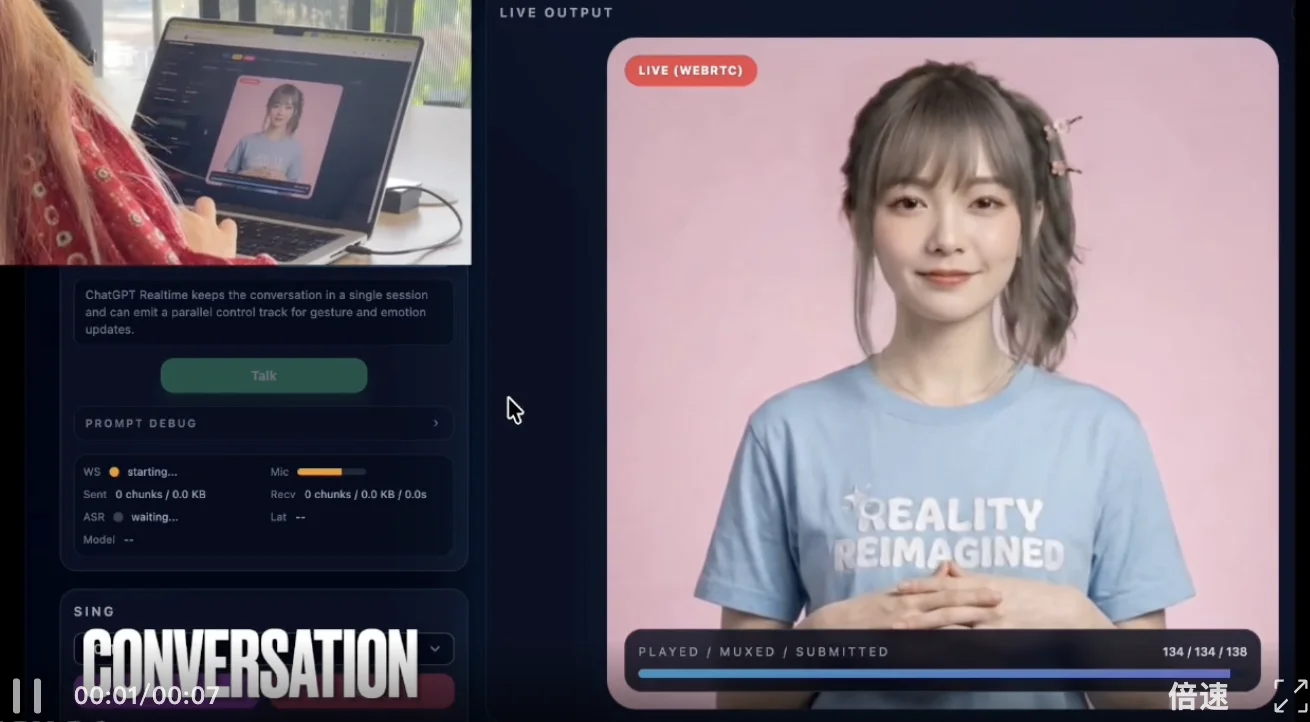
表情如此之自然、情绪如此之到位、交互如此之实时,网友直接就是一个《坐不住》,直言:
实时、支持无限长度的AI角色终于来了!!!(大声.jpg)

(说真的,我大早上在官网看了这几个demo效果后,属实快分不出来AI不AI了…)
其实对今天的AI视频产品来说,能把人物角色的表情生动演绎出来,早就不算什么新鲜事了。
但是LPM 1.0模型特殊就特殊在吧——
我们能通过文本、音频和图像三种多模态形式,轻松生成一个能实时对话、会听会说、还能持续保持人物一致性的动态角色。
让AI角色在视频里,更会演、更会听、更会说,还能一直像同一个人~

我也帮友友们浅浅总结了一下LPM 1.0模型最核心的几大「能力亮点」:
emm…这些能力是不是听上去有点乏味?没关系,我们直接让AI演员们上才艺!
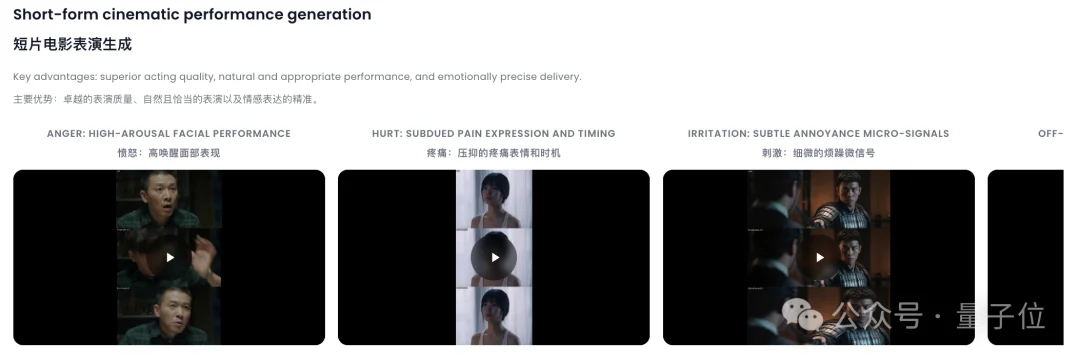
先来说说大家很感兴趣也很有意思的——「超绝情绪演绎能力」。
具体来说,模型在口型同步、呼吸节奏、情绪表达维度上的表现更贴近人类的表现方式,呈现效果也就更有层次。
比如在下面这个堪比好莱坞大片的视频,两位男子仅仅在几秒钟的时间,就生动演绎出了多个神态——

前一秒还是犹豫和迟疑,下一秒就出现抿嘴、咬牙、叹气这类更细小的动作,能让人明显感受到心理状态在变化。
(老戏骨啊老戏骨,建议送去参加AI版《演员的诞生》!)
再看下面这位老哥,短短9秒时间里,惊恐、紧张、愤怒几种情绪接连切换,整个过程还挺有压迫感??
此外不知道大家发没发现,当人物在说到重音位置时,嘴部开合幅度、面部发力方式也会跟着增强。
台词重心和表演重心是对得上的,融合度可以说是非常不错,be like:

除了对着镜头完成这类单人表演,LPM 1.0还有个更有意思的能力——
那就是角色在「倾听别人说话」时,会同步给出与当下情境相符的的表情和状态反馈。
让你觉得,眼前这个AI…好像真的在赛博世界和另一个人真实互动。
比如下面这个女人接孩子电话的片段。
当她听到电话那头的声音时,第一时间先是眼神变化,随后眼睛微微睁大,带出一点意外和牵挂,紧接着眉头收紧,像是在迅速判断电脑那头孩子是不是遇到了什么事。
emm…整段反应很像真人接电话时那种「边听边消化信息」的状态:

再看下面这个神情已经有点略微烦躁的男子。
对方一开口,他的脸上就同步出现了扶头、疲惫、轻微不耐烦这些反应,整个人的状态像是在强撑着把这段话听完。
(像极了我们上班开会听老板讲话时候的表情…狠狠共鸣住了。)

除了上面我们展示的这些单向视频生成能力外,LPM 1.0还有一个非常值得一提的能力——
那就是我们能与AI角色「实时互动」。
例如你说话时,角色会实时做出正在听的表情和动作,让整个互动看起来会更像真人视频通话。
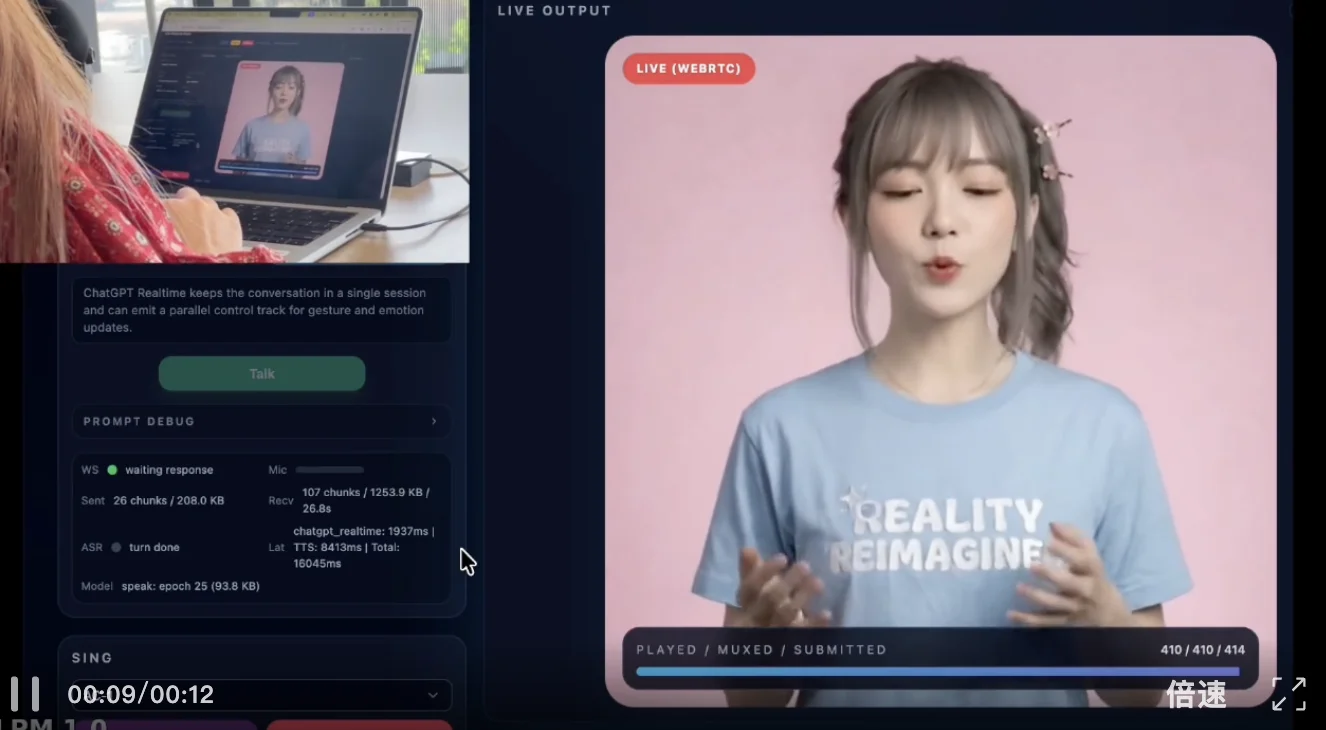
比如下面这个demo,在视频对话器中,女子只张口说了句「let’s sing a song」,屏幕里的AI女孩就能做到立刻开始大展歌喉~
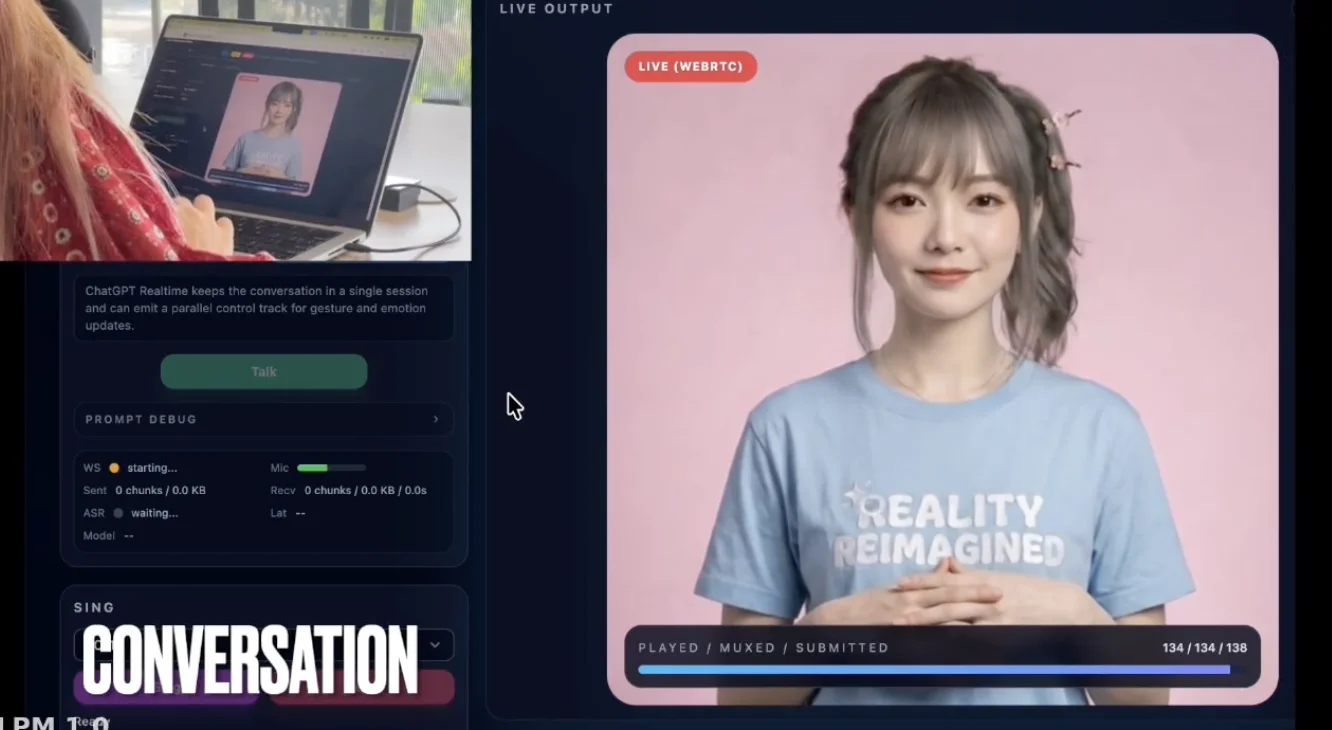
再比如,只说一句「请你做个自我介绍」,屏幕里的AI女孩也能快速做出相关反应,更接近真实交流该有的节奏:
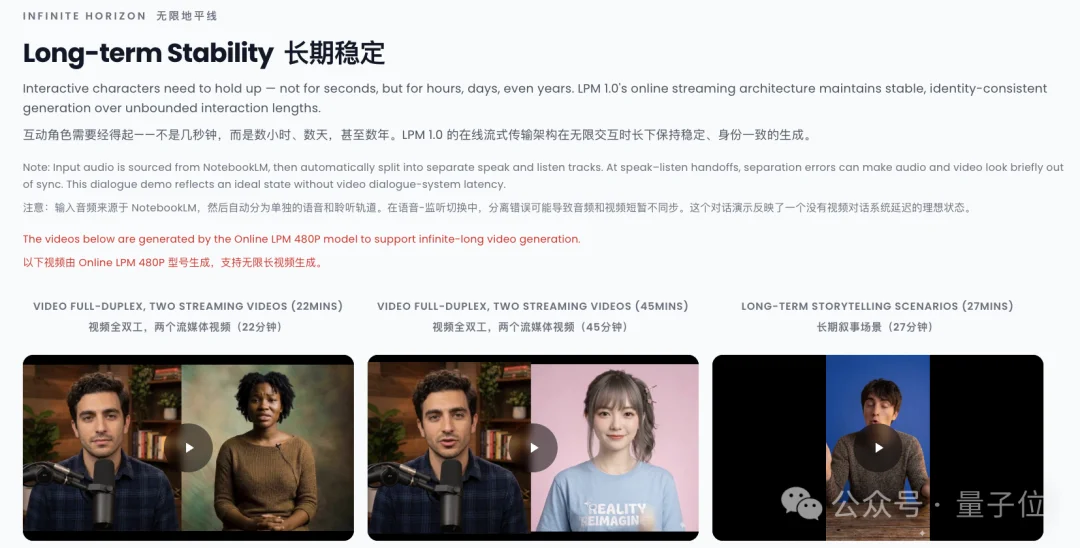
最后我们来说说LPM 1.0长时间视频生成中能力。
具体来说,LPM 1.0能够让AI角色在长时间互动里依旧保持稳定输出,既能持续对话,也能长时间讲故事,人物形象还不容易崩。
比如像下面官方案例中22分钟、48分钟的视频也能轻松生成,而且角色形象一致性依旧保持不错~
能让赛博世界里的人物角色表情神态和交互能力如此到位,LPM 1.0背后的技术架构自然也不简单。
我先给大家小小科普一下,其实目前行业内的视频模型,一直很难同时兼顾三件事儿——
那就是表现力、实时性、长视频的角色一致性。
这三项能力可以说是彼此牵制,水火不相容,这也构成了当下AI视频最核心难题之一…
而为了解决这个大难点,LPM 1.0团队先是构建了一套以人为中心的多模态数据集——
在这个过程中加入了表演理解,身份感知等多种参考信息内容,目的是让AI角色更像真人交流时的状态。
在此基础上,团队又给底层架构直接上了一套有着170亿参数的扩散Transformer。
这套架构更擅长处理视频里空间与时间之间的复杂关联,能借助强大的自注意力机制,把人物表情、口型、动作,以及前后帧之间的连续关系一起建模。
这样一来模型就能知道到底怎么演才能更自然更像人类~
而至于我们在刚才看到的能实时交互的模拟器,则是一个因果式流生成器,专门用于实现低延迟、可持续、无限长度的实时交互。
这样一来我们就和AI角人物进行实时交流了!(暗笑.jpg)

除了模型本身的能力外,LPM 1.0团队成员同样值得关注。
此次在X上披露LPM 1.0模型的@Ailing Zeng,身份为Anuttacon的技术团队成员,主要负责互动多模态视频生成模型的相关研究。
她博士毕业于香港中文大学,在加入Anuttacon之前,曾在腾讯混元团队和IDEA从事大模型相关研究。

此外,该模型的技术论文由20+位研究人员共同参与完成,感兴趣的uu可通过下方论文链接了解模型的详细技术内容~

Ps:目前,模型还没有正式对外上线,感兴趣的朋友可以蹲蹲。
参考链接:
[1]https://arxiv.org/html/2604.07823v1
[2]https://large-performance-model.github.io/#
文章来自于微信公众号 "量子位",作者 "量子位"


