# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3B、7B小模型如何成为智能体专家?
浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。

这一思路的灵感来自人类的学习方式:人类学习总是从“看着说明书操作”逐渐过渡到“凭肌肉记忆自主执行”。
为了实现这一过渡,SKILL0在模型训练过程中引入两项关键机制:上下文强化学习(In-Context Reinforcement Learning)和课程学习(Curriculum Learning),通过逐步撤掉技能参考,让模型把过程性知识内化到参数里,实现零样本直接上手。
从Claude到OpenClaw,Skills作为结构化的过程知识和可执行资源的集合,已成为增强大模型智能体能力的重要方法,在智能体运行时为其提供相关技能的在线匹配与调用支持。
然而,论文指出这种推理时“技能增强”的范式并不适用于小模型,主要有以下三个原因:
1. 检索噪声致命:可能引入无关或误导性指导,污染有限的上下文,极度依赖外部检索质量。
2. Token开销爆炸:技能一旦变多,随着智能体多轮问答中会导致token累积。
3. 缺乏深度理解:最关键的是,模型根本没学会技能,只是在照本宣科。推理的时候一撤技能,模型直接打回原形。
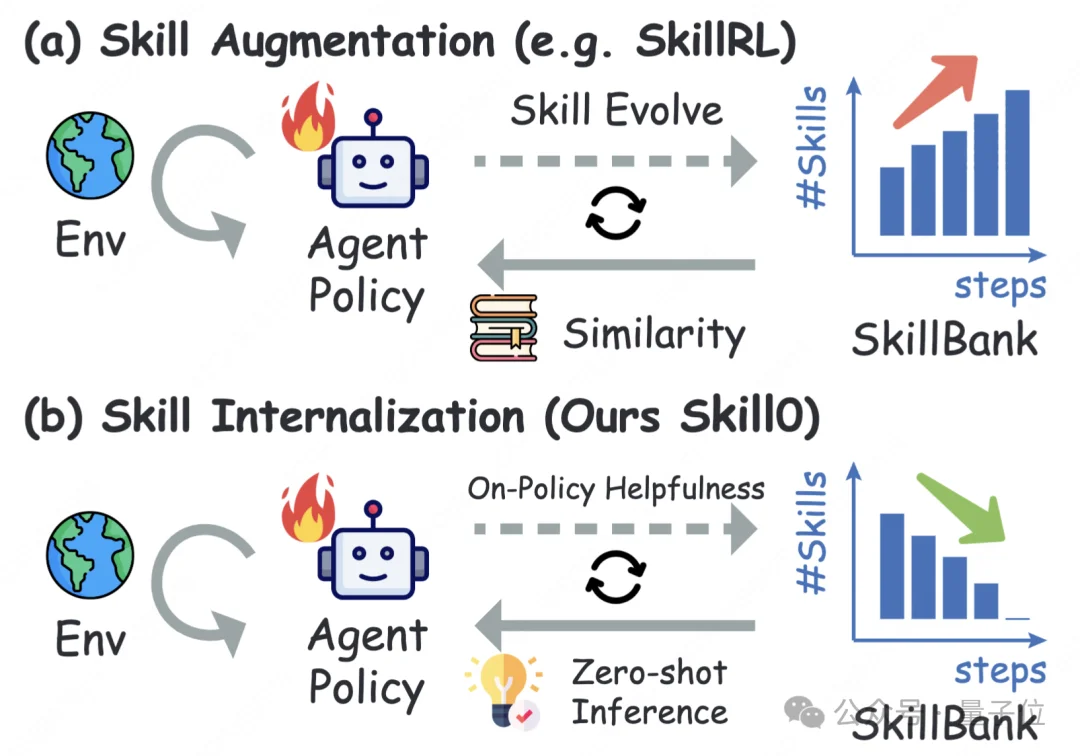
SKILL0的核心逻辑,完全复刻了人类学技能的完整过程:从照着说明书做,到慢慢熟练,最后不用想就能自主完成。它的核心创新,拆解成三个关键点:
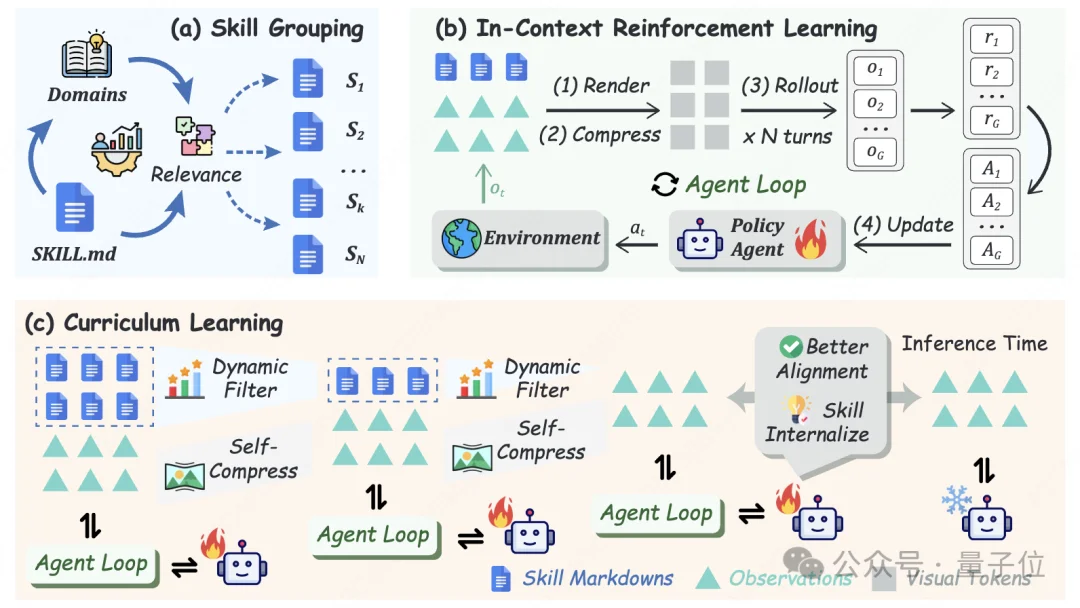
训练开始前,先准备好一个层级化的SkillBank。分两层:
通用技能:跨任务的策略原则,比如“先探索再行动”
任务特定技能:某个领域的专门知识,比如“搜索任务中怎么查实体属性”
每个markdown文件按照相关性分类,相当于“参考书”,方便模型在训练阶段按照“参考书”的标题进行衡量和筛选,为后面的“课程学习”做好准备。
强化学习(RL),就是让AI通过试错,在环境里学会完成任务的方法。之前的方案,要么全程不给技能,模型像无头苍蝇一样乱试,根本学不会复杂任务;要么全程给技能,模型只会照着念,永远形成不了自己的能力。
SKILL0做了一个巧妙的设计:训练的时候,给模型完整的技能上下文;但推理评估的时候,把所有技能全拿走,即上下文强化学习。
这里对上下文做了特殊处理:技能和历史交互不是直接用文本塞进prompt,而是渲染成一张图片,用视觉编码器压缩。文本token开销太大,渲染成图片后,语义信息用颜色编码。视觉编码器一张图就能压缩掉大量文本,同时保留结构信息。
SKILL0收到的环境任务奖励后,同时计算了自压缩的奖励,共同成为组内优势进行参数更新:
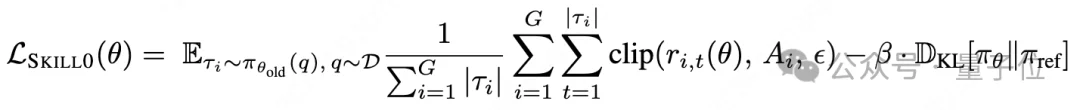
训练分Ns个阶段,技能预算线性衰减。拿ALFWorld举例,6个技能文件,3个阶段,预算序列是[6, 3, 0]——第一阶段用最多6个,第二阶段砍到最多3个,第三阶段一个不给。
但不是随便筛选,也不是预先设定筛选顺序。每个阶段都有一套Filter → Rank → Select的在线筛选机制:
1. 先评估帮助度。 每隔10步,对每个技能文件做一次对比测试:有这个技能时准确率多少,没有时多少。差值就是这个技能的“帮助度”。
2. 再过滤排序。 只保留帮助度大于0的技能(确实还有用的),按帮助度从高到低排。
3. 最后按预算选取。在不超过当前预算的前提下,保留排名前列的技能文件。
论文的Figure 6展示了技能帮助度的变化曲线:

可以发现这套机制带来了一个有意思的训练现象:
论文还证明了为什么用线性衰减而不是其他策略。附录里的理论分析显示,线性衰减确保每两个阶段之间的分布变化有上界,避免PPO训练时重要性采样比率爆炸。
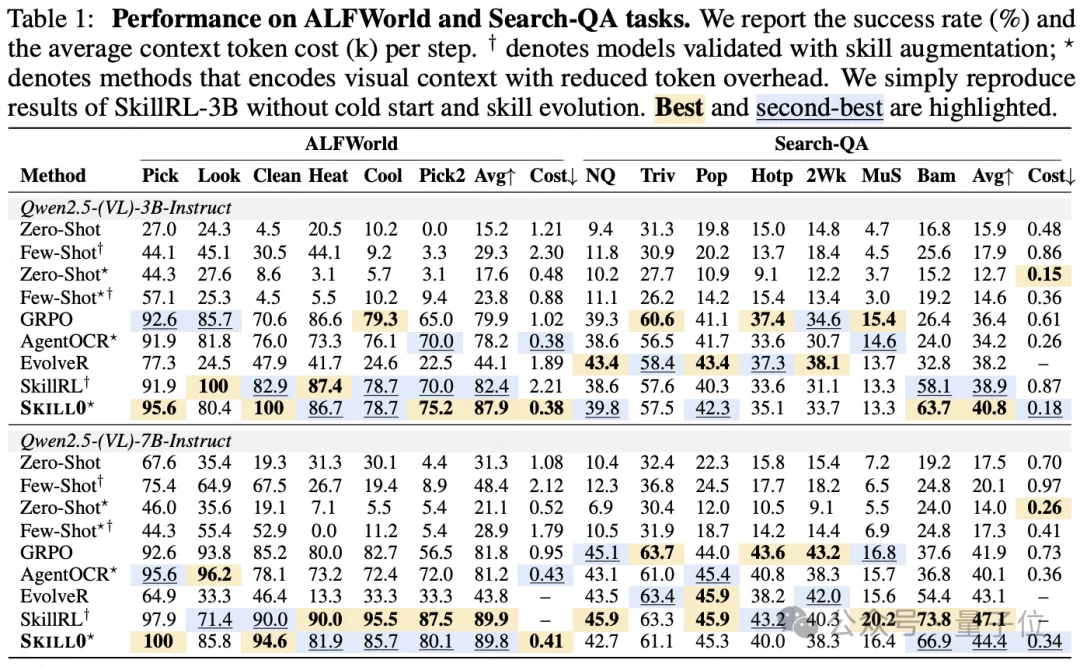
在ALFWorld任务上:3B模型的SKILL0,平均成功率87.9%,比标准RL基线AgentOCR直接高了9.7%,甚至比全程带技能的SkillRL(82.4%)还要强。
Search-QA任务:同样3B模型,平均分40.8%,比AgentOCR高了6.6%,和带技能的SkillRL打平甚至反超。
7B模型效果直接碾压闭源大模型:在文章附录里的ALFWorld任务结果中,SKILL0零技能推理做到了89.8%的成功率,远超GPT-4o(48.0%)和Gemini-2.5-Pro(60.3%)。
除了出色的效果,还有它极致的token效率。
3B模型的SKILL0,每步推理的上下文token开销在ALFWorld任务仅0.38k,Search-QA任务仅0.18k,比SkillRL省了5倍还多。
训练曲线如下:
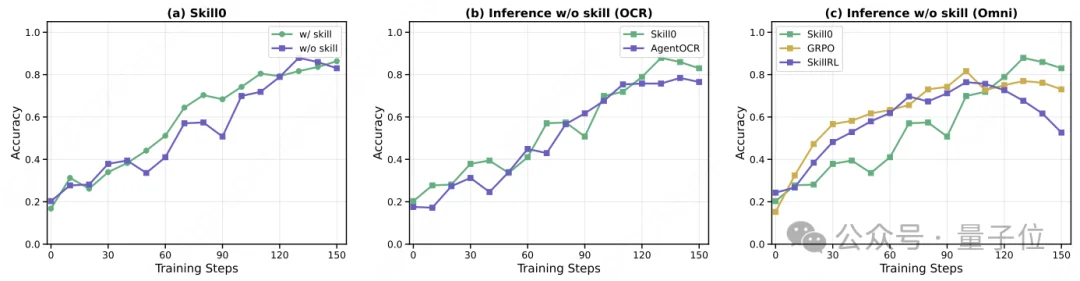
训练初期,带技能的模型效果涨得更快,不带技能的效果差强人意;但随着训练推进,不带技能的效果慢慢追了上来,最后甚至反超。这就是实打实的技能内化——模型真的把技能刻进了参数里,不是临时抱佛脚。
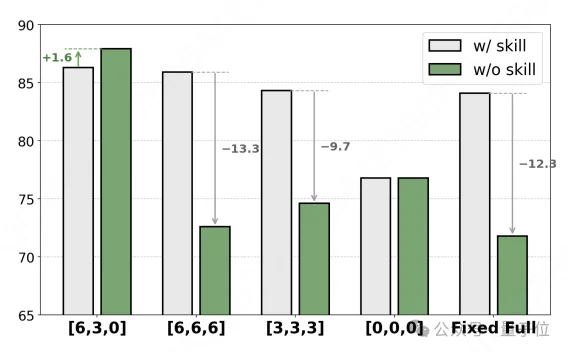
还有一组消融实验的数字特别说明问题。如果训练全程都给满技能[6, 6, 6],推理时一拿掉,性能暴跌12.3个点。但SKILL0的渐进课程[6, 3, 0]呢?推理时拿掉技能后,性能反而提升了1.6个点。
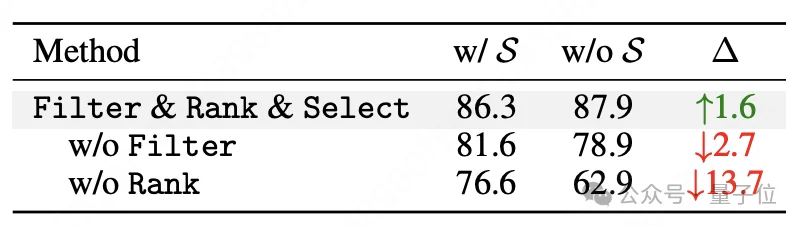
如果把动态课程的Filter去掉(不过滤,直接取前M个),性能掉2.7%。如果连Rank也去掉(随机选技能),直接暴跌到62.9%,比完整的SKILL0低了13.7%。
当前Agent生态的大部分努力,都花在了“更好的检索、更好的技能库、更好的注入方式”上,SKILL0提出了一个不同方向:让技能内化入模型参数。这样参数量受限的小模型,或许就能靠端到端训练成为能够胜任复杂任务的领域专家。
当然,技能内化不会取代所有运行时增强。需要实时更新的知识(比如最新API变更)还是得靠检索。但对于稳定的、可复用的行为模式,从“外部工具”到“内在能力”的转变,可能才是Agent真正走向自主的关键一步。
论文标题:
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
论文地址:
https://arxiv.org/abs/2604.02268
项目代码:
https://github.com/ZJU-REAL/SkillZero
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
