# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现有大模型评测分数日趋饱和,但与真实体验差距显著。南京大学傅朝友团队牵头,在Google Gemini评测团队邀约下推出视频理解新基准Video-MME-v2。凭借创新的分层能力体系与组级非线性评分,以及3300+人工时高质量标注,揭示模型与人类的巨大鸿沟(49vs90)、传统Acc指标虚高、以及「Thinking」并非总是增益等现象。
一年多前,傅朝友带领的Video-MME团队发布了其第一版Benchmark,被Gemini、GPT等广泛用于视频理解评测。
根据Paper Digest统计,Video-MME在CVPR 2025所有录用论文中影响力排名第一(引用1100+次)。
近年来,团队进一步对多模态大模型评测进行了系统梳理,并发布综述工作MME-Survey,从能力覆盖、评测方式到指标设计,对现有Benchmark进行了全面分析。
正因如此,团队更早、更清晰地意识到:现有评测范式,开始逐渐「失真」了。多模态大模型在视频理解上进步神速,各类Benchmark上的分数都在趋于饱和,但真实体验依然不足。在这样的背景下,Video-MME-v2正式发布。

论文:https://arxiv.org/pdf/2604.05015
主页:https://video-mme-v2.netlify.app/
MME-Survey: https://arxiv.org/pdf/2411.15296
Video-MME-v2是一个面向下一代视频理解能力的评测基准,历经近一年时间准备,由12名标注人员和50位独立审核人员共同完成,投入超过3300人工时标注时间。
与传统Benchmark的不同在于,一个精心设计的逐层递进三层能力体系以及分组非线性评分方法。
评测结果显示:人类专家的非线性得分为90.7(传统Acc为94.9),而当前最强的商业模型Gemini-3-Pro得分仅为49.4,开源模型Qwen最佳结果为39.1。
Video-MME-v2的第一个核心设计,是把视频理解拆成一个逐层递进的三层能力体系。
第一层:信息检索与聚合。这是视频理解最基础的一层,关注模型能否从跨帧、跨模态的信息中,准确识别并提取关键事实。
第二层:时序理解。基于第一层,第二层进一步考察模型是否真正理解了时间维度。要求模型不仅能看懂不同帧的静态画面,更要抓住动作发生的先后关系、状态如何变化、事件为何发生。
第三层:复杂推理。基于第二层,第三层则更接近真实世界任务,要求模型在更复杂、更开放的场景中进行推理。这也是最接近「人类式理解」的一层:不仅要看懂,还要能推断、能解释、能综合。图1直观展示了这三层能力结构。
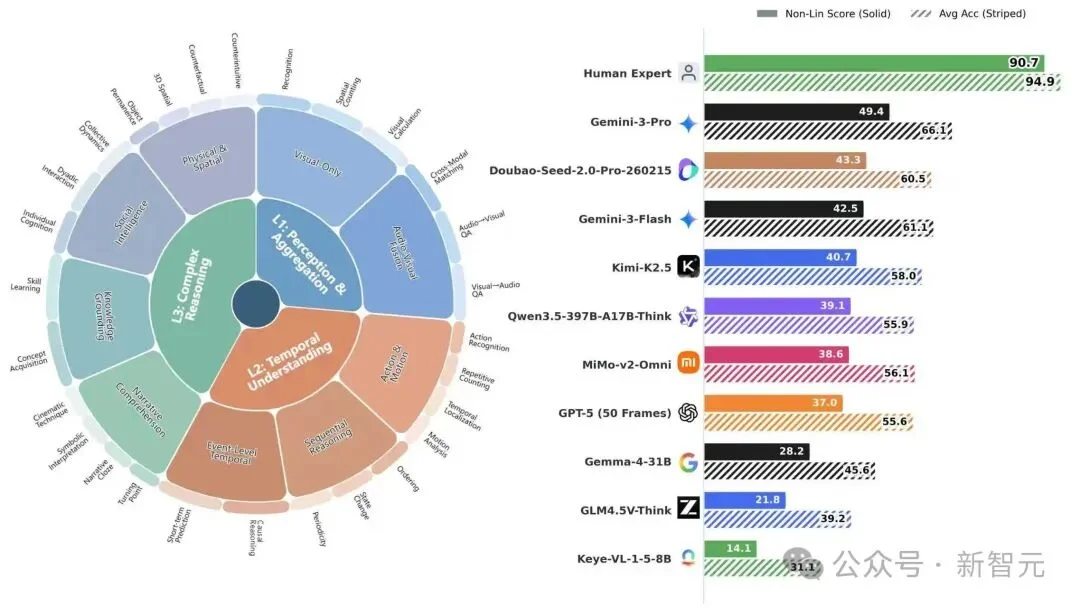
图1 Video-MME-v2能力层级分布以及部分模型能力排行
Video-MME-v2的第二个关键创新,回答的是「怎么测」。
这项工作没有继续沿用「每题独立计分」的传统方法,而是引入了组级评测。即,不再只看模型某一道题答没答对,而是看它在一组相关问题上是否表现出一致性和连贯性。
能力一致性组:
看模型是不是「真的会」
它关注的是:同一种能力,模型在不同问法、不同粒度、不同侧面上,能不能都保持稳定。
举个简单的例子:如果一个模型真的具备空间理解能力,那它不仅应该能回答「物体在哪里」,也应该能回答「它和另一个物体的相对位置如何变化」。
推理连贯性组:
看模型是不是「真正在推理」
它关注的是:当一个复杂问题需要多步推理时,模型能不能沿着合理的逻辑链条,一步一步走到结论。
比如,在一个复杂剧情视频里,模型可能需要先发现一个关键视觉线索,再识别异常细节,再推断人物目的,最后才能得出结论。
如果中间某一环错了,最终即使「碰巧选对了」,这种正确也不能算作真正可信的推理。
为了和组级评测相配套,Video-MME团队进一步采用了非线性评分机制。这也是Video-MME-v2代表性的设计之一。
对于能力一致性组,四道相关问题不是简单平均,而是采用激励计分(一个Group里答对越多奖励也多)。这意味着:零散地答对几道题,并不能拿到很高分;只有当模型在同组问题中保持稳定表现,分数才会真正上来。
对于推理连贯性组,则是进一步采用「首错截断」机制。即,一旦某一步做错,后面即使答对,也不再计分。
一个Benchmark的说服力,不只在于「设计巧」,也在于「数据够不够扎实」。
团队严格把控Video-MME-v2的数据源、标注流程、质检标准等各方面,投入了极高的人力成本。
数据集最终包含800个视频、3200个问题;共有12名标注者和50位独立审核人员参与,经过5轮交叉审核与闭环修订,累计投入超过3300人工时。更多细节请查看主页和技术报告。
在主榜结果中,人类的组级非线性得分达到90.7,平均准确率达到94.9;而当前表现最好的商业模型Gemini-3-Pro,组级非线性得分为49.4。
开源模型中,Qwen3.5-397B-A17B-Think(512 frames),组级得分为39.1。
它意味着:哪怕是当前最强的视频模型,在更严格、更强调一致性与连贯性的评测框架下,与人类仍存在巨大的差距。
论文也特别指出,模型从Level 1到Level 3呈现出明显的性能递减,说明高层复杂推理的薄弱,并不只是「推理模块不够强」,而往往是前面的信息聚合和时序建模已经出了问题,最终层层累积,拖垮了复杂理解。
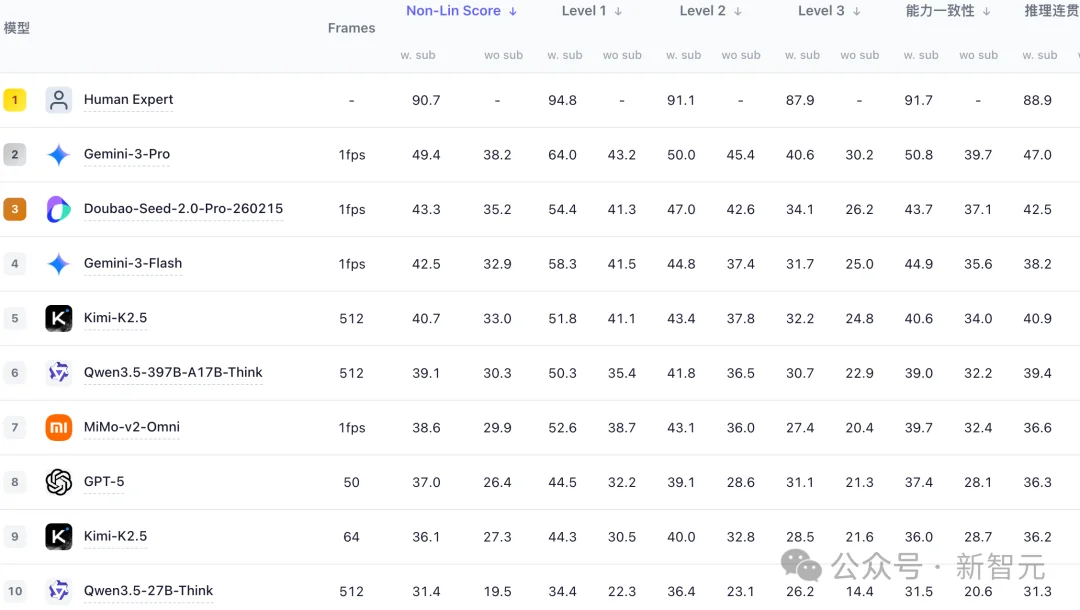
图2 当前评测前10名(完整请查看主页)
在传统评测中,平均准确率(Avg Acc)是最常用的指标,但它本质上是逐题独立统计的结果,容易受到「零散命中」的影响。
相比之下,团队提出的组级非线性评分(Non-Lin Score),通过对问题之间的结构关系进行建模,更强调模型在同一能力维度下的整体表现,从而能够更真实地刻画模型是否「稳定地理解了视频」。
进一步来看,非线性评分还揭示了模型能力中的一个重要现象:从「单题正确」到「组内稳定正确」之间存在显著能力折损。
为此,团队引入了一个具有解释力的指标——Non-Lin Score/Avg Acc的比值,用于衡量这一折损程度。
实验结果显示,当前最强的模型的比值Gemini-3-Pro的比值约为75%;Doubao-Seed-2.0-Pro的比值约为72%;而部分中小模型(如LLaVA-Video-7B)甚至低至约40%。
比值越低,说明模型越容易出现「组内只能答对部分题」的现象,稳定性与鲁棒性越弱。由此可见非线性打分在真实刻画能力水平、揭示模型鲁棒性方面的优势。
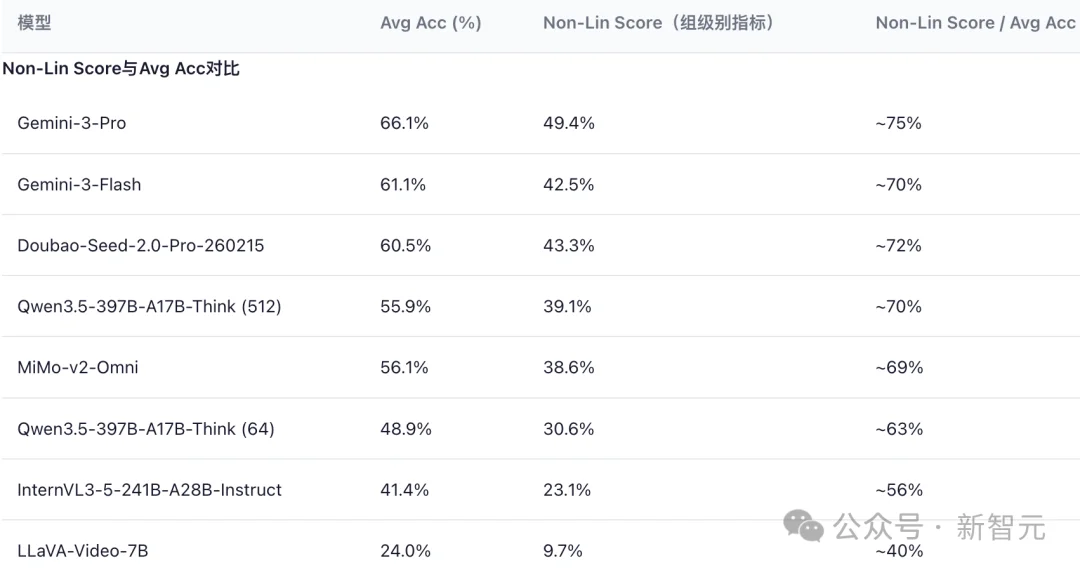
图3 不同模型Non-Lin Sore/Avg Acc的比值结果
在今天的大模型语境下,「Thinking」几乎已经成了默认增强选项。但Video-MME-v2 的一个非常有意思、也非常重要的发现是:Thinking的收益不是无条件成立的,它高度依赖文本线索。
论文实验显示,开启Thinking后,模型在「有字幕」的设定下,通常比在「纯视觉」设定下获得更明显的提升。
例如,Qwen3.5-122B-A10B-Think(64 frames)在无字幕和有字幕设置下,分别带来+3.8/+5.8的提升。这说明,显式文本语义仍然是很多模型完成多步推理时重要的「锚点」。
但另一方面,Thinking也可能带来退化。Qwen3-VL-8B在无字幕设定下出现了-0.6的下降,而KimiVL-16B在整体上出现了-3.3/-3.3的性能回落,在更强调复杂推理的Level 3上,退化甚至达到-4.0/-3.9。
这说明一件事:当前一些模型的「推理增强」,本质上仍然更擅长利用语言线索,而不是稳定地从视觉、音频中抽取支撑推理的证据。一旦文本锚点不足,Thinking不但未必增益,反而可能引入更多噪声。
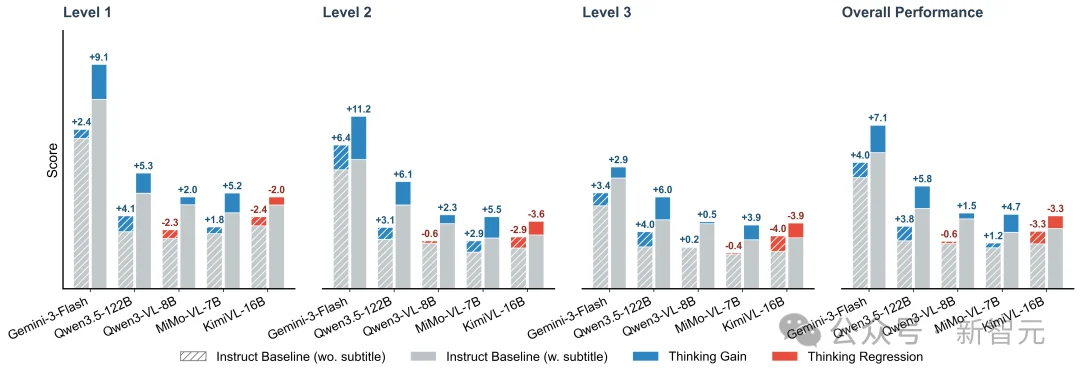
图4 在有无字幕设定下,是否开启Thinking对模型性能影响
在视频理解的下一阶段,Video-MME-v2想推动的是一次评测理念上的转变,强调真正需要比较的是谁能够在连续、动态、多模态的信息中,像人一样,真正理解正在和已经发生的事情。更多内容和细节请查看主页和技术报告。
作者介绍
Video-MME系列Project Lead为南京大学傅朝友老师:

傅朝友,南京大学模式识别实验室研究员、助理教授、博导,入选中国科协「青年人才托举工程」。
2022年博士毕业于中科院自动化所模式识别实验室。研究方向为多模态内容分析,谷歌学术引用8700余次,两篇一作单篇引用过千次,六篇一作单篇引用过百次。
开源项目累计获得2万余次GitHub Stars,代表性工作包括VITA多模态大模型系列(VITA-1.0/-1.5、Long-VITA、VITA-Audio),MME多模态评测基准系列(MME、Video-MME、MME-RealWorld)和Awesome-MLLM社区等。
担任Pattern Recognition/IEEE T-BIOM期刊编委、ICLR/ICML会议领域主席、CSIG青工委委员、CCF-AI/-CV专委会执行委员。
曾获小米青年学者-科技创新奖、华为紫金学者、世界人工智能大会云帆奖、中科院院长特别奖、IEEE Biometrics Council Best Doctoral Dissertation Award、北京市优博、中科院优博、CVPR 2023 Outstanding Reviewer。
文章来自于"新智元",作者 "YHluck"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
