# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有没有想过让「龙虾」替你打麻将?
自从龙虾热以来,大家慢慢接受了 AI 智能体能够在电脑上执行操作的特性。
既然龙虾具备一定的控制能力,那让它替我去挣欢乐豆不过分吧。
遗憾的是,现在的龙虾,称之为「Claw」是有道理的,笨拙的龙虾爪的确很难进行复杂操作。让它打开浏览器逛逛电商平台比价,都要寻找各种对应的 Skills,而且执行的吭哧瘪肚的,这的确让人很难放心地将正经工作流交给龙虾。
时隔半年有余,那个能够直接操作图形界面的,曾经取得双榜 SOTA 的通用 GUI 智能体模型 Mano 再一次产生了飞跃。不仅解决了自动操作工作流的痛点,甚至连「替我打麻将」的梦想都实现了:

这次,明略科技带着自研全新进化的 面向端侧设备的 GUI-VLA 智能体模型 Mano-P 1.0 亮相。这一模型能够不依赖传统 API 对接,也不局限于浏览器场景,能够直接理解并操作桌面软件、网页界面,完成更复杂的图形化工作流,彻底引领龙虾从「爪」向「手」的跨越式进化。
简而言之,Mano-P 1.0 模型是一个纯视觉 GUI 操作模型,不依赖任何插件,打通全部兼容性瓶颈。与其他 GUI 操作模型不同,Mano-P 1.0 能够完全实现本地运行,数据零上云;开箱即用,三种形态,覆盖全部开发者群体。

Mano-P,一台 M4 Mac,两行命令,一个能在你电脑上自主操作界面的 AI。
相比之前的 Mano 模型,Mano-P 产生了质的飞跃。让我们非常好奇的一点是,新模型名字中的「P」,到底是什么含义?
我们猜测,P for Power。
让我们来看看硬成绩。双榜 SOTA 远远不是 Mano 模型的上限。这次,Mano-P 1.0 模型给了我们巨大的震撼。
Mano-P 在全球 13 个多模态基准榜单上达到 SOTA,覆盖 GUI Grounding、CUA、感知认知、视频理解、上下文学习等多个维度,呈现出「屠榜式」的断崖领先。
ScreenSpot-V2 上拿到 93.5 分,MMBench 上 87.5 分,UI-Vision 上 46.6 分,几乎全面碾压同量级竞品。
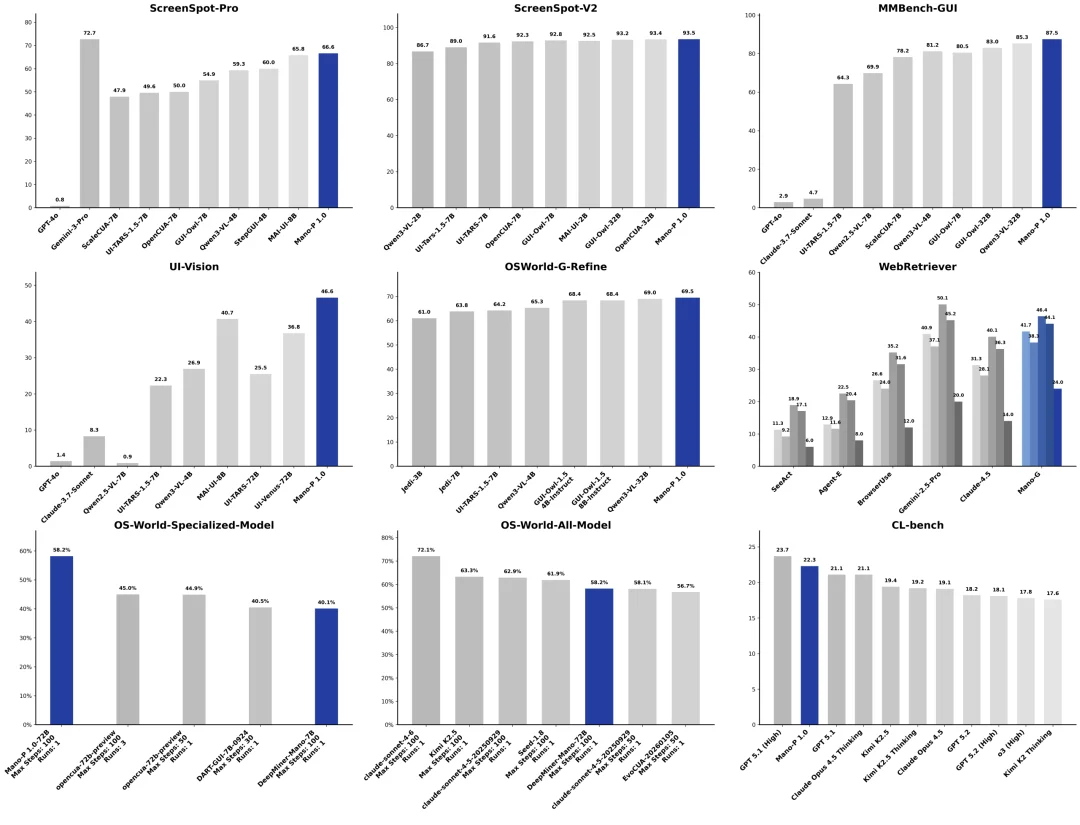
在 GUI Agent 领域最具权威性的基准测试 OSWorld 上,Mano-P 1.0-72B 取得了 58.2% 的成功率,在所有专用 GUI 智能体模型中排名全球第一,领先第二名 opencua-72b(45.0%)整整 13.2 个百分点。
放到全模型榜单上看,排在前四位的都是千亿级参数的通用大模型 ——Claude Sonnet 4.6(72.1%)、Gemini 2.5 Pro(66.9%)等。而 Mano-P 以 72B 参数量跻身第五位,作为一款专用模型打入通用模型的俱乐部,这本身就已经说明了很多。
另一个值得关注的战场是 WebRetriever Protocol I:Mano-P 拿到了 41.7 NavEval 分数,超越了 Gemini 2.5 Pro Computer Use(40.9)和 Claude 4.5 Computer Use(31.3)。
以上硬核成绩,完全能够说明 Mano-P 1.0 模型能够摘得全球第一的桂冠。
GUI 是数字世界最真实的入口,而 Mano-P 正在把这个入口交给智能体。
在官方演示中,Mano-P 完成了一套从视频生成、上传、分析、剪辑到二次评测的全流程自动化,其中同时涉及网页操作和专业剪辑软件的混合使用 —— 这对依赖浏览器协议的方案来说是不可能完成的任务。

当我们提起操作 GUI 的智能体,就能想到的一个极具代表性的应用是「豆包手机助手」。软硬件深度结合的豆包,理论上能够实现任何手机上的操作。
当前主流的 Computer Use 方案,包括豆包手机助手在内,本质上都遵循同一个模式:截屏或读取屏幕信息 → 上传云端 → 云端推理 → 返回操作指令 → 本地执行。
这意味着每一次操作,你的屏幕内容都在被传输到外部服务器。在个人用户的隐私保护,以及对数据安全有硬性要求的场景来说,这是一个无法忽视的风险。这也是豆包手机助手昙花一现的核心原因之一。
Mano-P 走了一条完全不同的路,支持本地运行,数据完全不上云。
或许,P for Private。
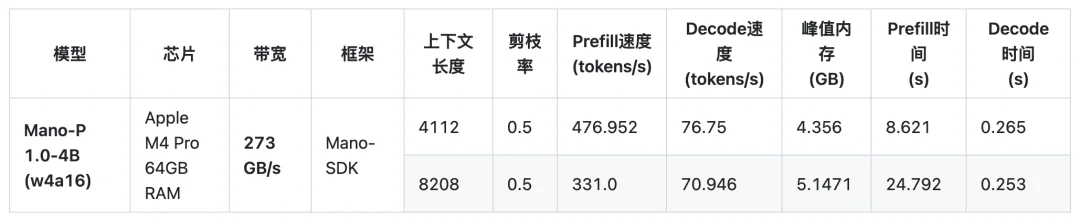
它支持在 Apple M4 芯片 + 32GB 内存 的 Mac mini 或 MacBook 上直接进行本地推理。所有截图和任务数据完全不出设备,不需要配置任何 API 密钥,不需要联网,不需要向任何外部服务器发送一比特的数据。
性能数据也足够亮眼:其 4B 量化模型(w4a16)在 Apple M4 Pro 上可实现 476 tokens/s 预填充速度 和 76 tokens/s 解码速度,峰值内存仅占 4.3GB—— 一台标配 M4 Mac mini 就能流畅运行。
明显的,端侧不是云端能力的「缩水版」,是 Agent 落地的另一条路径 —— 一条更适合高安全需求、高隐私要求、以及希望对 AI 能力拥有完整控制权的用户的路径。
Mano-P 通过与众不同的私有化策略,重构了「纯视觉理解」与「本地执行」的底层逻辑,让你的「龙虾」真正属于你。
这种架构拥有「物理隔离」的安全感,更凭借其零门槛、开箱即用的部署特性,大幅降低了构建 GUI Agent 工作流的工程成本。
这标志着 AI 智能体私有化,个人化的开始。
小龙虾们引发了一场 Mac mini 抢购热潮,眼看 Mano-P 在 M4 Pro 芯片的亮眼成绩,下一波断货还远吗?
开源一个强大的模型需要强大的魄力。便是如 Meta 这样的巨头,也逐步向闭源模型方向转变。
Yann LeCun 就曾表示「获胜的平台将是开放的平台」。可能,P for Public。
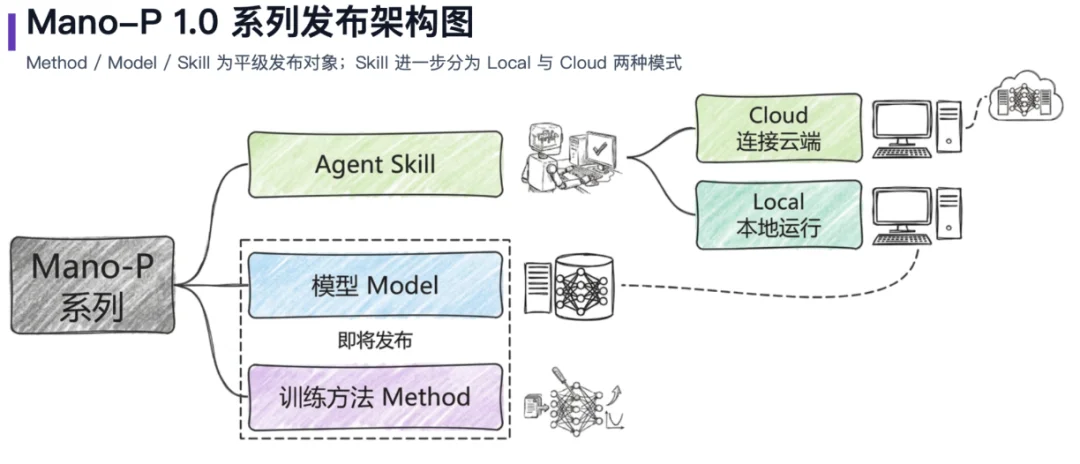
Mano-P 是一个全开源的模型。它的开源策略很有意思 —— 分三个阶段逐步释放能力。
开源链接:https://github.com/Mininglamp-AI/Mano-P/tree/main
Skill 先行,开箱即用
这一阶段的核心目标是:现在就能用起来。
Mano-CUA Skill 已经开源。此阶段的目标用户是 Agent 爱好者,例如 OpenClaw 或 Claude Code 的用户,使他们能够利用 Mano-CUA 技能的功能构建更智能的 CUA 任务工作流程,摆脱人工干预带来的瓶颈。
团队提供了三种接入形态,分别对应不同类型的用户:
三种形态,同一套核心能力。无论你是想快速体验、深度集成、还是让 Agent 自己去调度,都有对应的入口。
模型开放,能力下沉
第二阶段,明略将开源 Mano-CUA 的本地模型和 SDK 组件。
此阶段的目标用户是具有高安全性要求的开发者,使他们能够直接使用可在 Mac 本地运行推理的 GUI-VLA 模型来构建自定义技能、工具等。重要的是,所有 CUA 操作都将在本地 Mac 上执行,而不会上传到外部服务器。
这是整个开源计划中最关键的一步。
大模型证明了 Mano-P 模型的能力上限,小模型专注于用户的端侧体验。两者互补,覆盖从研究验证到生产落地的完整链路。
方法公开,生态共建
最后一阶段,团队计划开源的是训练方法本身,包括 Mano-P 模型所使用的训练方法、剪枝和量化技术。
Mano-Action 双向自增强学习框架是整个项目的核心技术底座。与传统单向预测方法不同,它采用 Text ↔ Action 循环一致性学习 —— 模型同时掌握两个方向的能力:
双向互相增强,让模型对 GUI 的理解更加鲁棒。
训练过程分为三个递进阶段:
1. SFT(监督微调):建立基础的 GUI 理解与操作能力。
2. 离线强化学习(Offline RL):在历史数据上进行策略优化,探索更优的操作序列。
3. 在线强化学习(Online RL):通过与真实环境的实时交互持续提升,实现自我进化。
配合 「思考 - 行动 - 验证」 循环推理机制,每一步操作后都会验证结果,发现偏差时自动纠错调整。
端侧优化方面,GSPruning 视觉 Token 剪枝是一项值得关注的技术创新。该方法通过保留全局空间锚点来维持网页结构骨架,同时识别语义异常值以捕获关键 UI 元素,将视觉 Token 保留率压缩至 12.57% 的同时仍保持较高任务成功率,吞吐量提升 2-3 倍。
从 Skill 到模型再到方法论,三步棋走完,开发者获得的是一整套可以从使用到定制到研发的完整技术栈。
Mano-P 的整个项目采用 Apache 2.0 协议开源,完整客户端代码公开可审计,支持商业使用与二次开发。
目前市面上的 GUI 自动化方案大致分三类:
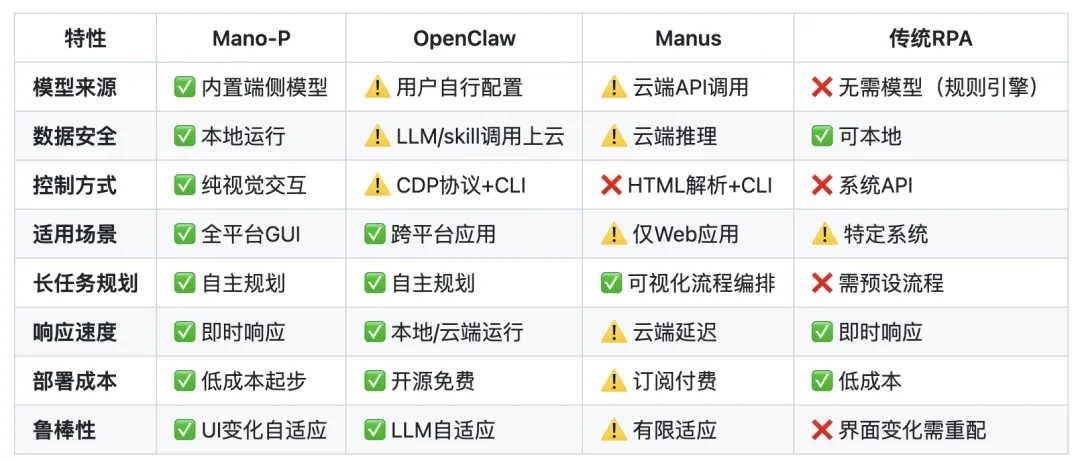
Mano-P 与传统方案 CUA 对比
Mano-P 独属于第四类 —— 纯视觉 GUI Agent。它做的事情和人一样:看着屏幕,理解界面,然后决定输入,带来了无限制的跨平台通用性。总的来说,完全开源的 Mano-P 有四大核心竞争力:
我们知道,「Mano」一词来源于西班牙语,意为「手」,生动地体现了模型在数字世界中「灵巧手」的核心能力。
而为了知道 Mano-P 模型中的「P」的真正含义,机器之心与明略集团副总裁,多模态首席科学家赵晨旭老师进行了一次专访。
于是我们得到了明略科技官方的答复。「Mano-P 这个科研项目里面最核心的一个概念 —— P 的含义代表的是 personal(个人) 或者 party(组织)。」
Personalized AI 的开端
赵晨旭老师认为:「我们已经断定现在正处在两个时代的交界点上,可能好多人或者是一些开发者,或者是一些业内的人还没有意识到。是哪两个时代呢?就是 AGI 的时代和 Personalized AI的时代。」
AGI 的叙事已经深入人心:打造一个无所不能的通用智能体。赵晨旭老师解释了其中的逻辑:以 DeepSeek、GPT o1 为代表的路线,核心是基于事实性基础进行推理。对于有确定解或唯一解的问题,这种推理方式确实「无敌」。但现实世界中,大部分问题恰恰是无解的或有多种解的。
「其实我们要找的是在这些解里面,对于个人或者对于某个组织、某个集体而言价值最大的那个解。」
每个组织和个人都有自己沉淀的经验和特有的品味,按照这些「私有资产」去做推理,才能拿到最优解。「所以我们区别于 AGI,我们管这个叫做 Personalized AI。」
要说到底什么是 Personalized AI,文章开头展示的打麻将,正是其最生动的例子。
如果你拿一个 AGI 的模型去帮你打麻将的话,因为他看过很多种麻将打法,他会实时判断一下,然后直接去选,无论哪一步他走的都是最优解,看上去特别像一个机器人。
但是你如果跟他说用您的方式去打这个麻将,AI 应该是按照您的习惯,您经常怎么样去胡牌,或者怎么样去记牌,怎么样去开杠不开杠、吃牌不吃牌,然后用您的方式去打。这个就是通用 AI 和 Personalized AI 的区别。
这个比喻恰似乎和当前的热门话题,把同事,名人,甚至是前任「蒸馏」成 skill,在理念上有些相仿。当我们提出这个话题时,赵晨旭老师说:「这个其实就是你在打造你自己的 Personalized AI 的过程,只不过这些现在是以一种记忆或者文件的方式存储的,它并没有直接作用在 AI 的大脑里,没有给它形成参数化。但这已经是个性化 AI 的开始了。」
模型的技术历程
从操作浏览器,到一步步把 Personalized AI 做成,其中的技术难度不言而喻。我们也请赵晨旭老师为大家介绍了现在走向 Personalized AI 的模型的三大技术突破。
去年首次在 Mind2Web 和 OSWorld 刷榜时,团队攻克的核心难题是在线强化学习。
「之前的那些强化学习的路径都是在一个虚拟的上下文里面去做强化…… 但是对于那种一步操作可能会直接影响整个周围的真实环境的这种情况,可能就不是那么合适了。」
团队引入了在线强化学习后,模型能力大幅提升,在 OSWorld 上拿下专有模型第一名,至今仍保持第一名。
今年年初,团队发现了另一种新的训练范式 —— 双向强化。传统训练方式只有单向映射:自然语言 → 动作(action)。
「大部分时候只有正向的,就是通过自然语言推测 action,但是没有从 action 去推理自然语言的。比如说我按了一下这个按钮,背后应该对应哪些自然语言?其实没有人在做这项工作。」
团队提出的方案是同时训练两个方向:自然语言→动作,以及动作→自然语言,两者相辅相成。这种方法借鉴了视觉领域 GAN 的思想,效果出奇地好 ——
「我们就拿一套训练集训练一个模型,就直接刷新了 10 个榜单的纪录。」
「这也是我们为什么能短时间内突破这么多榜单,因为我们没有在这些任何一个榜单专门针对任何一个榜单去做优化微调,只是用一套训练数据通过这个训练方法训练一个模型,就在 10 个榜单上达到了算法结果。」
第三个突破指向了一个更实际的约束:算力。如果要让 Personalized AI 真正落地到每个人的设备上,模型必须在有限算力下完成推理甚至训练。
视觉剪枝的方法是说,我们在做 GUI 任务的时候,屏幕截图分辨率很高,可能都是 1080P 的分辨率,然后把图像给它序列化变成一个个 token。这个 token 其实中间有好多是不必要的,在做任务时不需要关注这些 token。比如一个网页里面有好多留白的空间,这些都是废的 token。
通过识别并剔除这些冗余 token,模型的计算量得到显著优化,使得 Mono-P 能够直接在 Mac 等端侧设备上独立运行。
让更多的人用起来
当我们谈及在榜单之外如何判断模型是否成功,赵晨旭老师坦言标准正在发生迁移。
「在上个阶段或者去年,我们主要以榜单为主。坦率地讲,榜单大家可能理解得都比较直白。但是现在对于我们来说标准确实发生了一些变化,我们现在更希望的是我们自己的模型能够被更多的人用起来。」
这也解释了开源策略背后的考量 —— 如果不开源,用户无法在本地优化自己的场景,Personalized AI 的愿景就无法真正落地。
我们知道,要想让更多人用起来,自然需要一个好用的场景,一个令人眼馋的落地实践:
「我们设想的一个场景就是可以通过 GUI 去代替人进行测试。Claude Code 写完搭建完应用之后会有一个 PRD,然后模型参考这个 PRD 去访问网站测试,看有没有错误、有没有 bug。这样就把人类进行测试的瓶颈给取消掉了。软件可以 Claude Code 写完代码马上就测试,测试完给反馈结果,有没有 bug,功能有没有实现,然后再改。改完之后再测试,整个流程中的人类瓶颈就消失了。这是我们构想的场景。」
这就是 Mano-afk 全自动应用构建场景,用户输入一句自然语言需求,系统自动完成需求澄清 → 技术架构设计 → 代码生成 → 本地部署 → API 接口测试 → 页面视觉检测 → 端到端 GUI 自动化测试。测试失败时自动定位、修复代码、重新验证,循环迭代直到全部通过。全程无人干预。

从 AGI 到 Personalized AI,从追求通用到拥抱个性,在这两个时代的交界,我们的确该思考下一步的 AI 演进方向。
「我们相信,个体和组织都能够创造属于自己的个性化 AI。」
文章来自于"机器之心",作者 "冷猫"。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
