# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?
彼时,没有 GPU、没有 CUDA,也没有浮点数,甚至没有任何深度学习框架,只有一台 PDP-11 小型机,以及一门几乎已经退出历史舞台的语言:汇编语言。
近日,一位开发者给出了答案。他复现了那个年代的技术环境,用 1970 年代的 PDP-11 汇编语言,实现了一个 Transformer,并且真正训练成功了,这个项目叫做 ATTN-11。
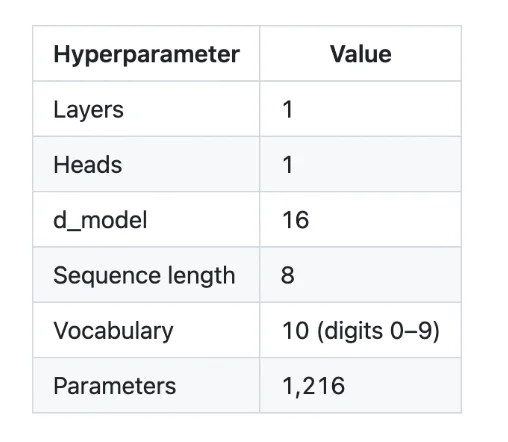
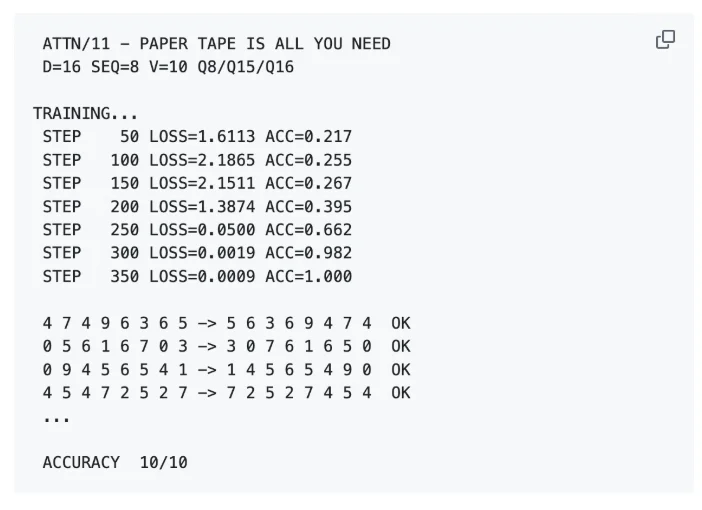
具体来看,就是在 1970 年代的小型机 PDP-11 上,用纯汇编语言,实现一个单层、单头的 Transformer,并完成一个「序列反转」的任务,即输入一串数字,输出其反序结果。
比如,输入:4 7 4 9 6 3 6 5,输出:5 6 3 6 9 4 7 4。
看似很容易,但关键特征是,机器无法通过「记住内容」来完成这个任务,必须理解「位置之间的映射关系」。而这恰恰是自注意力(Attention)机制的的核心能力。
项目结果显示,在一台 1970 年代的计算机上,一个仅有 1216 个参数、单层单头的 Transformer,在约 350 步训练后就实现了 100% 的准确率,而训练时间只有 5 分钟左右。
有意思的是,由于 PDP-11 时代,程序的主要存储介质是 Paper Tape(穿孔纸带),因此,该项目开发者又称该项目为「Paper Tape is All You Need」。

而当开发者将该项目发布之后,引起了网友的热议。
当下,大模型的发展主要围绕 Scaling Law 展开,更多的参数 ,更多的数据,更的多算力…… 而 ATTN-11,却在极低的资源、极简的结构下,成功实现功能闭环。因此,大家不禁在思考:Transformer,到底需要什么?
一位网友该项目「在 PDP-11 上训练只要 5 分钟」表示惊讶,而更让他震惊的是,这似乎说明「我们其实一直都可以做到这些???」

另一位网友则认为,不必惊讶,是的,我们一直可以做到这些。因为,「1980 年代的 Cray 超级计算机非常厉害,尤其在矩阵乘法方面性能极其强大。
比如一台 1984 年的四核 CPU Cray X-MP,可以持续提供 800 MFLOPS 到 1 GFLOPS 的算力,如果配上一块 1GB 的 SSD,在算力和带宽上已经足以在半年内训练一个 700 万到 1000 万参数的语言模型,并以每秒 18 到 25 个 token 的速度进行推理。
而到了 1990 年代中期,一台 Cray T3E 的算力,就已经可以承载 GPT-2(1.24 亿参数)规模的模型,这要比 OpenAI 早 24 年。
而我自己,甚至还用一台 1965 年的打孔卡计算机,通过反向传播学会了 XOR。
真正的瓶颈从来都不是硬件,而是想法。」

另一位网友也现身说法,他举了后量子密码学的例子。他表示,基于格(lattice)的加密方案早在 1990 年代就已被提出,但真正走向产业落地,却花了整整几十年,而问题的关键不在于数学不成熟,也不在于硬件不足,而是让这些理论真正「跑起来」的关键思路,当时还没有出现。

接下来,详细了解一下具体项目实现。
开发者称,该项目是 Xortran 的精神续作,Xortran 是一个在 IBM 1130(1965 年)和 PDP-11/20(1970 年)上,用 Fortran IV 实现反向传播来学习 XOR 运算的神经网络。
自然而然地,下一步就想看看这些机器是否能在可接受的时间内(几小时)成功训练一个小型 Transformer。
从架构上看,Transformer 实际上只是基础神经网络的适度扩展。矩阵乘法、反向传播、随机梯度下降(SGD)和交叉熵等构建模块早已存在。
新增的三个部分是:
该项目的目标是训练一个 Transformer 来反转数字序列。尽管看似简单,但对神经网络来说,模型必须学会将每个 token 路由到仅由其索引决定的位置,没有基于内容的捷径。而这类问题正是为自注意力设计的,实际上也是 Tensor2Tensor(谷歌 2017 年原始 Transformer 的参考实现)中包含的算法基准之一。
数据路径很直接,token 被嵌入,通过带有残差连接的自注意力层,然后映射回词表并通过 softmax 得到预测:

该模型是一个极简的 Transformer:嵌入、带残差连接的自注意力、输出映射。它是真正的带自注意力的 Transformer,但既不是 BERT 也不是 GPT:没有层归一化、没有前馈网络、没有解码器。
该任务中,不需要对 token 表示做任何变换,因此注意力和残差连接就足够了。层归一化在深层网络中用于防止激活漂移,但在单层中并不需要。
第一次实现沿用了 Xortran 的方案,并使用 Fortran IV 编写。在统一学习率为 0.01 的情况下,模型完成 100 步训练需要 25 分钟,而要达到 100% 的准确率则需要约 1500 个训练步数。这在真实硬件上大约相当于 6.5 小时的训练时间,在 IBM 1130 上甚至可能需要整整一周。
即便是按照 1970 年代的标准来看,这样的耗时也是难以接受的,因为当时的计算机通常采用分时共享机制,计算资源非常宝贵。
因此,第一次改进是将统一学习率替换为手动调优的分层学习率:
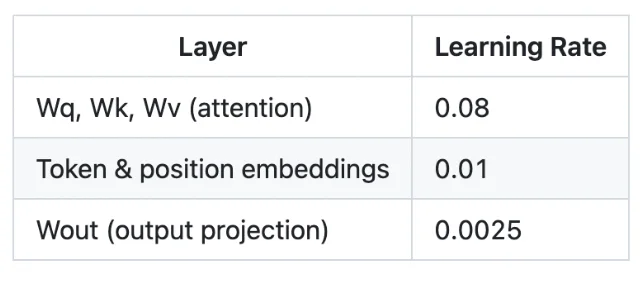
编码「反转模式」的注意力权重更适合使用较高的学习率,而输出映射层在较小学习率下收敛效果更好。通过这一调优,训练步数降至 600 步,预计训练时间约为 2.5 小时。
优化器采用的是最基础的随机梯度下降(SGD)。像 Adam 这样的优化器虽然可以为每个参数自适应调整步长,但代价是每个权重需要额外维护两个状态向量,使参数所占内存增加到原来的 3 倍。同时,每次更新还需要进行平方根和除法运算,即便在配备 EIS 的 PDP-11 上,这些操作也依然开销较大。
相比之下,分层学习率在不增加额外成本的情况下实现了类似效果,而且由于模型规模较小,这三组学习率可以手动调优。此外,这也使得 Transformer 可以装入 32KB 的核心内存,而不是 64KB,这在 1970 年代尤为关键。
补充说明:由于采用裸机汇编实现,ATTN/11 的内存占用并不高于 Xortran,后者还需要承担 RT-11 V3 操作系统和 Fortran 运行时的开销。最终生成的二进制文件也相当紧凑,仅为 6179 字节。
NN11
核心算术运算基于 NN11,这是一个为 ATTN/11 和 PDP-11 设计的最小化定点神经网络计算栈。
NN11 的组织结构类似于 BLAS,分为多个层级:最底层是标量基础操作(FXMATH);其上是向量运算,如点积和缩放(VECOP);再往上是矩阵–向量运算(MATOP),每一层都构建在下层之上。
此外,还有两个模块将该计算栈扩展到线性代数之外:一个是激活函数及其查找表(ACTFN),另一个是层级操作(LAYER),用于将前述运算组合起来,实现、映射以及注意力等功能。
这些算术计算会根据不同的计算阶段进行适配:
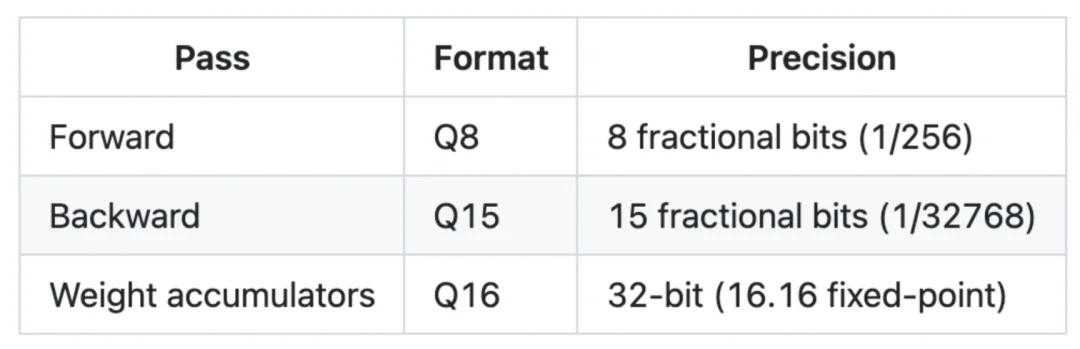
在 PDP-11 上,前向计算使用 Q8、反向传播使用 Q15 的组合非常契合:将一个 Q8 数与一个 Q15 数相乘,会在一个 32 位寄存器对中得到 Q23 的结果,只需一次「ASHC #-8」操作即可将其缩放回 Q15。
因此,反向传播中的乘法开销并不高于前向计算,同时还能让梯度的精度达到激活值的 128 倍。
经过优化后,模型在 350 步内即可收敛,使得在开发者的 PDP-11/34A 上,总训练时间缩短至仅 5.5 分钟。

在该项目中,开发者并没有使用真正的纸带读取器,因此是通过控制台将目标代码直接写入内存。
以下是运行该 Transformer 后的结果:
在正式转向汇编实现之前,必须先验证其正确性。因此,开发者先在 Sheaf 中对浮点和定点算术进行了原型设计与验证。Sheaf 是开发者开发的一个函数式 ML 框架,内置了可观测性机制。
对于这类机器学习工作,Sheaf 相比 Python 有几个优势:
例如,在「vtmul」上设置一个范围保护,可以立刻捕捉到遗漏「>>8」位移的问题:
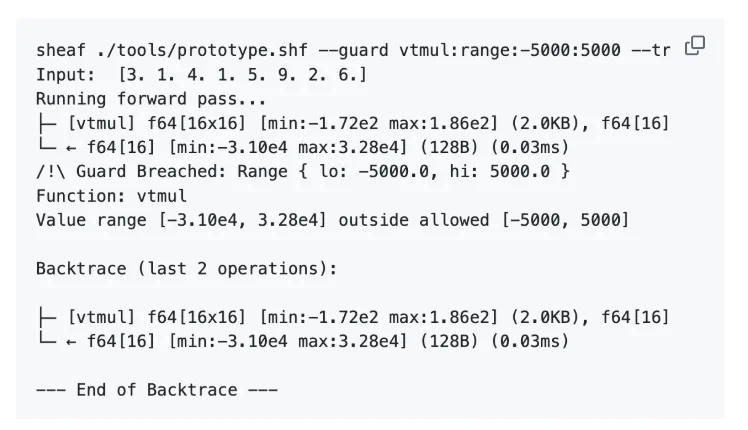
浮点与定点两种原型实现都可以在「proto」文件夹中找到,同时还包含最初的 Fortran 版本。
由于没有浮点运算单元,超越函数(如 exp、log)被预先计算的查找表所替代。在 PDP-11 上,一次查表只需一条「MOV」指令,其开销远低于多项式近似或 CORDIC 算法。
Softmax
Softmax 使用一个包含 256 个条目的查找表(EXPTBL,Q8),将每个索引 i 映射为 exp (−i/32)。计算分为三个步骤:
该查找表大约覆盖了输入范围内的 8 个单位,在趋近于 0 之前,这对于一个 10 类词表来说已经完全足够。
交叉熵损失
损失函数每 50 步计算一次,用于报告训练过程。它依赖另一个查找表(LOGTBL,257 个条目,Q12),将每个值 x ∈ [0, 256] 映射为 −ln (x/256) × 4096。
计算流程遵循标准路径:先对 logits 做 softmax,读取目标 token 的概率,然后在查找表中查得 −ln (p)。8 个位置(每个序列位置一个)的结果累加到一个 32 位寄存器对中(因为 8 个 Q12 值的和可能超过 16 位),再通过「ASHC #-3」除以 8。Q12 精度(1/4096 ≈ 0.0002)可以提供四位小数,足以用于监控收敛过程。
查找表
ATTN/11 使用两个查找表。第一个将每个索引映射为 Q8 表示的 exp (−i/32),在 softmax 中用一条「MOV」指令替代指数计算。另一个表主要用于便利计算,将每个值映射为 Q12 表示的 −ln (x/256),每 50 步用于计算交叉熵损失,以监控模型收敛情况。

两个查找表均通过 Sheaf 脚本离线生成,并以 .WORD 常量的形式存储在源代码中。
交叉熵梯度
反向传播利用了 softmax 与交叉熵组合的一个经典性质:logits 的梯度可以简化为

从而在训练过程中完全避免了对数运算的开销。该结果最初以 Q8 表示,随后左移 7 位转换为 Q15,这是整个反向传播过程中使用的数值格式。同一个 SFTMX 例程同时用于前向与反向计算,无需单独实现反向传播版本。
最后补充一点:在这些算法的开发过程中,开发者仅将 AI 工具作为辅助使用,而所有的设计决策、缩放策略,以及数值验证,均是在硬件上由人工完成的。
内存布局
ATTN/11 总共占用 19.2 KB 内存。下表展示了其内存分布情况,整理自 MACRO-11 汇编器的输出列表:

这 1216 个参数由于计算需要被复制了三份:Q16 累加器(4.8 KB)、用于前向计算的 Q8(2.4 KB),以及用于梯度的 Q15(2.4 KB)。仅模型本身就占用了 9.6 KB,是整体内存使用中占比最大的部分。
构建
构建所需的两个条件是:MACRO11 汇编器,以及用于将目标代码转换为可加载二进制文件的 obj2bin 工具。
运行
运行,需要具备以下条件之一:
ll-34 几乎可以视作拥有一台真正的 11/34。启动 ATTN/11 的方式如下:

或者,如果只是想快速体验,可以使用这里提供的 WebAssembly 版本:
SIMH 也可以使用,但它模拟的是 PDP-11 的高层行为(而非电路级),并以宿主机 CPU 的速度运行。虽然可以通过人为方式降低速度,但其时序并非周期级精确,因此不太适合用于性能调优或还原真实体验。
大家详细了解该项目后有何感想,可以在评论区留言交流!
参考链接:
https://github.com/dbrll/ATTN-11?tab=readme-ov-file#attn11---paper-tape-is-all-you-need
https://news.ycombinator.com/item?id=47518568
文章来自于"机器之心",作者 "机器之心编辑部"。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
