# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的重要方向。
与传统 SfM、MVS、NeRF、3D Gaussian Splatting 等方法不同,前馈式 3D 场景建模(Feed-Forward 3D Scene Modeling)通过一次前向推理,直接从输入图像预测三维场景表示,从而显著降低测试阶段的优化成本,并具备更强的跨场景泛化能力与实际部署潜力。论文摘要和引言都强调,这一范式正快速发展,并逐渐成为连接效率、泛化和系统落地能力的重要路线。
近日,来自浙江大学、南洋理工大学、Monash University、ETH Zurich、图宾根大学等机构的研究者联合发布综述论文,系统梳理了前馈式 3D 场景建模的研究进展,并提出了一种区别于以往工作的全新组织方式:不再主要按 NeRF、3DGS、Pointmap 等表示形式划分方法,而是从模型试图解决的核心问题出发,构建 problem-driven 的统一分析框架。

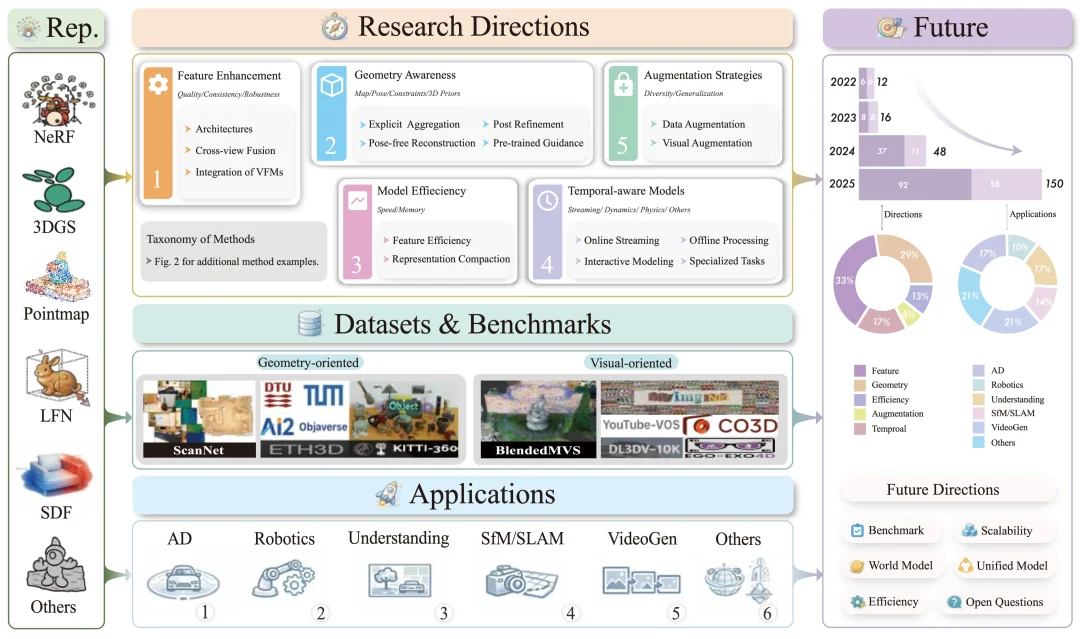
图 1:本文综述整体框架。从 3D 表示、五大研究方向,到数据集、应用场景与未来趋势,系统展示了前馈式 3D 场景建模的整体脉络。
为什么这篇综述值得关注?
前馈式 3D 方向发展很快,但长期以来,很多工作仍然主要按照 3D 表示形式来分类,例如 NeRF 一类、3DGS 一类、Pointmap 一类。论文指出,这种方式虽然直观,却往往掩盖了真正推动方法演进的关键因素。因为在现实中,使用同一种表示的方法,可能在解决完全不同的问题;而针对同一挑战的不同方法,也可能采用截然不同的表示。
基于这一观察,作者提出:与其围绕「输出是什么」来组织文献,不如围绕「方法到底在解决什么问题」来重新理解这一领域。论文摘要中明确提出,现有前馈式方法虽然输出表示多样,但在高层架构设计上共享大量共性,例如图像特征提取、多视图信息融合、几何感知设计等,因此更有解释力的组织方式,应当是围绕模型设计策略和核心挑战进行归纳。
也正因此,这篇综述最突出的贡献,不只是「总结得全」,而是给出了一个新的观察框架。它把前馈式 3D 场景建模总结为五个核心研究方向:特征增强、几何感知、模型效率、增强策略、时序感知模型。这一 problem-driven taxonomy 构成了全文的方法主线。
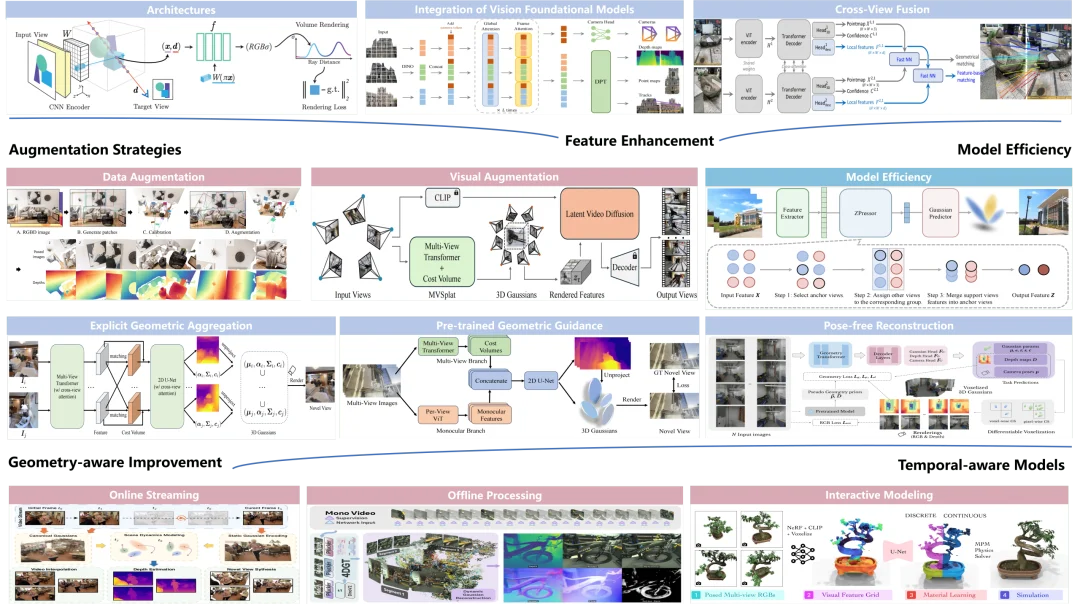
图 2:前馈式 3D 重建方法的 problem-driven 分类框架。作者将现有方法归纳为特征增强、几何感知、模型效率、增强策略和时序感知五大方向。
从「表示分类」走向「问题驱动」:
五大研究方向重新组织前馈式 3D
1. 特征增强:先把 2D 特征学好,才能更稳地 lift 到 3D
论文指出,前馈式 3D 系统中,隐式特征图质量直接决定后续 3D 解码效果。因此,大量工作首先围绕 feature enhancement 展开,包括 backbone 架构演进、跨视图特征融合,以及视觉基础模型的引入。换句话说,很多方法的关键改进,并不在输出层,而在「输入图像特征如何被建模、对齐并增强」这一层。
从论文的整理可以看到,这条路线已经从早期 CNN-based 条件建模,逐步发展到 Transformer、Mamba、ViT 等更强的编码架构,同时不断加强 cross-view fusion 和 foundation model priors 的引入。作者还专门总结了近期前馈式 3D 模型常见的 encoder taxonomy,覆盖 ResNet、ViT、U-Net、Mamba 以及 DINO、CLIP、CroCo、diffusion 等预训练先验。
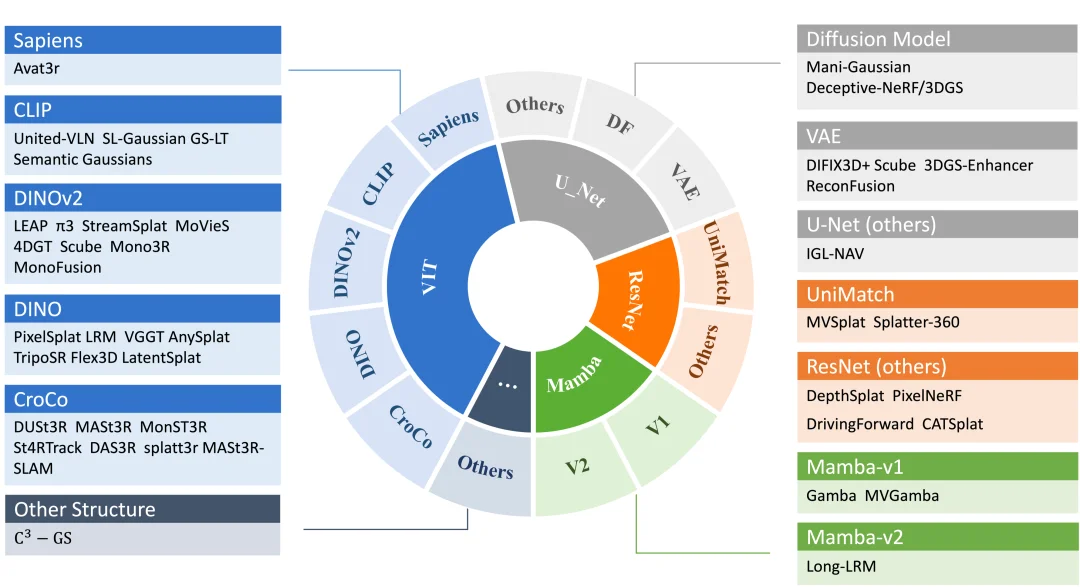
图 3:近期前馈式 3D 模型常见编码器与预训练先验的演化脉络。包括 ViT、ResNet、Mamba 等骨干网络,以及 DINO、CLIP、CroCo、diffusion 等基础模型先验。
2. 几何感知:前馈式 3D 的核心不只是看图,更是「懂几何」
如果说特征增强解决的是「看得更清楚」,那 geometry awareness 解决的就是「想得更对」。论文认为,仅依赖 2D 图像特征容易带来几何歧义,因此需要通过显式几何聚合、后处理细化、无位姿重建、预训练几何引导等策略,把更强的几何推理能力注入模型。
这部分的一个重要价值在于,它把 cost volume、epipolar constraints、surface-aware modeling、pose-free reconstruction 等看似分散的方法路线,统一放进了一个更高层的框架里。这样读者能更清楚地看到,这些方法虽然形式不同,但本质上都在回答同一个问题:前馈式 3D 模型如何在一次推理中恢复更可靠的场景几何。
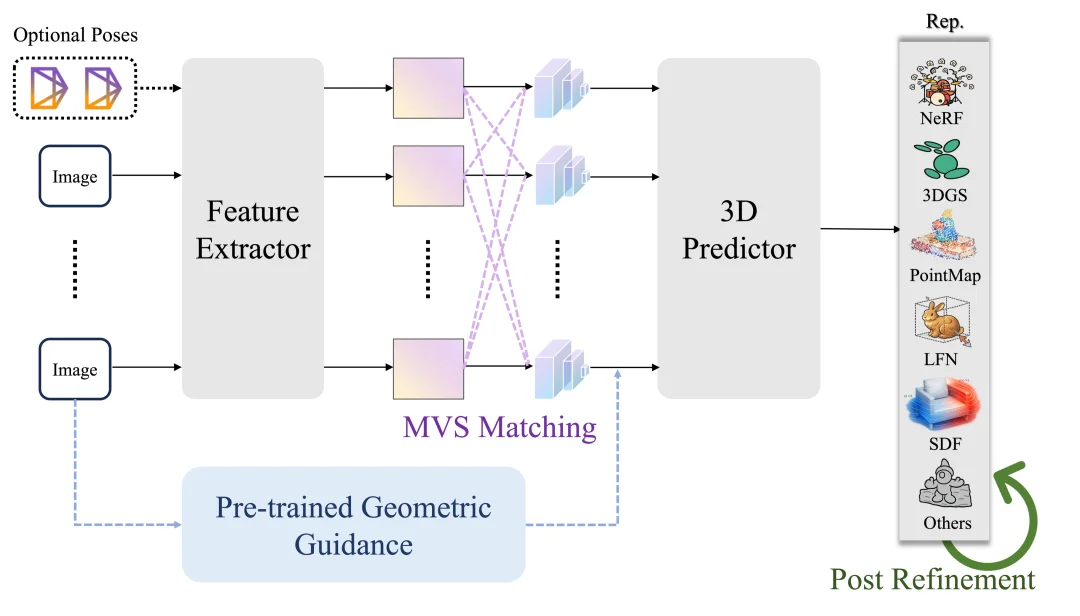
图 4:几何感知方向的主要改进路径。包括显式几何聚合、后处理细化、无位姿重建和预训练几何引导等几类代表性路线。
3. 模型效率:前馈式 3D 要真正落地,必须同时解决速度和内存问题
除了「准不准」,前馈式 3D 的另一个核心问题是「能不能真正用起来」。论文因此把 model efficiency 单独作为一条主线,并分成两类:一类关注 feature efficiency,即如何更高效地进行多视图特征聚合;另一类关注 representation compaction,即如何压缩显式 3D 表示,尤其是 Gaussian 的数量和存储开销。
这也反映出前馈式 3D 当前发展的现实目标:它不只是要在 benchmark 上提高指标,还要推动方法走向实时应用、资源受限场景和长序列重建。论文专门给出了不同代表性方法在显存占用、Gaussian 数量和推理时间上的对比,清楚展示了这一方向在效率层面的权衡关系。
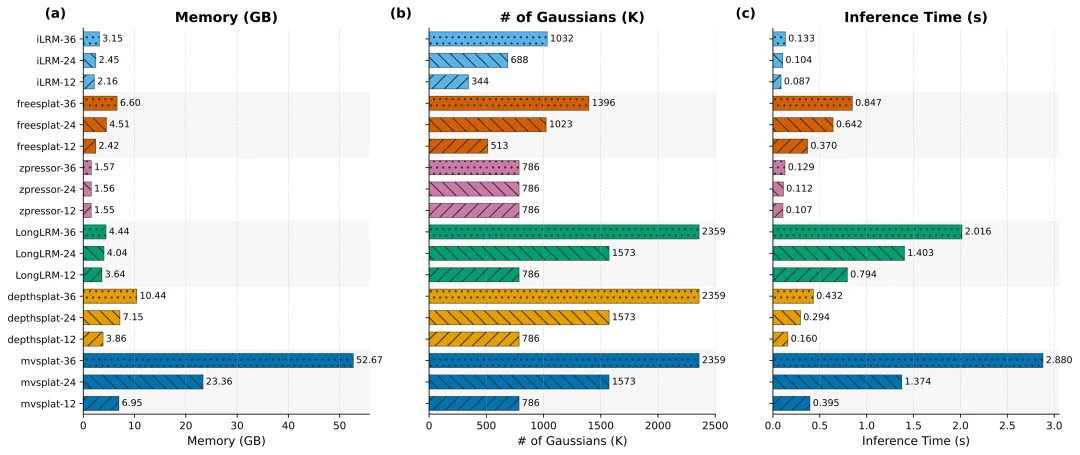
图 5:不同前馈式新视角合成方法在效率上的对比。从显存占用、Gaussian 数量和推理时间三个维度,展示不同方法在工程部署上的权衡。
4. 增强策略:不只扩训练数据,也借助生成模型补足视觉先验
论文中的 augmentation strategies 不是狭义的数据增强,而是被分成了两条互补路线:一条是 data augmentation,通过合成场景、伪标注、多视图生成等方式扩充训练分布;另一条是 visual augmentation,借助 diffusion 等生成模型增强渲染结果、去除伪影并补全缺失细节。这一点非常重要,因为它说明前馈式 3D 已不再只是一个纯几何建模问题,而是在逐渐和生成式建模融合。未来更强的前馈式 3D 系统,很可能既要恢复可靠几何,也要通过大规模视觉先验提升完整性与逼真度。
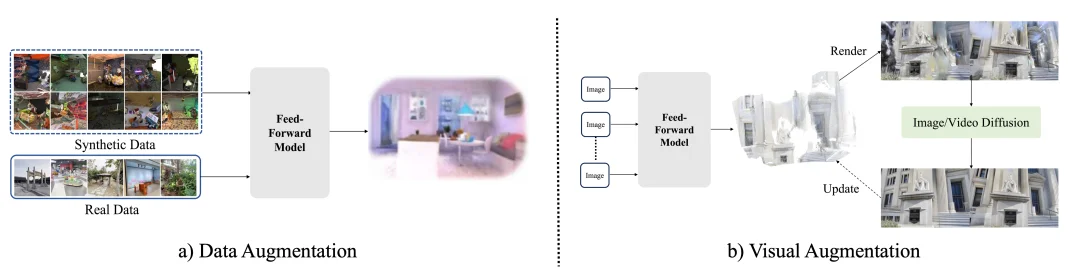
图 6:数据增强与视觉增强两类 augmentation 策略的区别。前者扩充训练分布,后者借助生成模型增强渲染结果,共同提升模型的泛化性与视觉质量。
5. 时序感知模型:从静态 3D 走向动态 4D 和持续世界建模
前馈式 3D 的最后一条关键方向,是 temporal-aware models。论文指出,这类方法通过建模跨帧几何与运动一致性,进一步把前馈式 3D 扩展到动态场景和低延迟 4D 建模。作者将其分为在线流式、离线处理、交互式建模以及面向特定任务的时序方法。
这部分也清楚表明,前馈式 3D 正在从「单个静态场景的快速重建」逐渐走向「持续建模世界」的能力形态。这对机器人、自动驾驶、动态场景理解以及空间智能系统都非常关键。
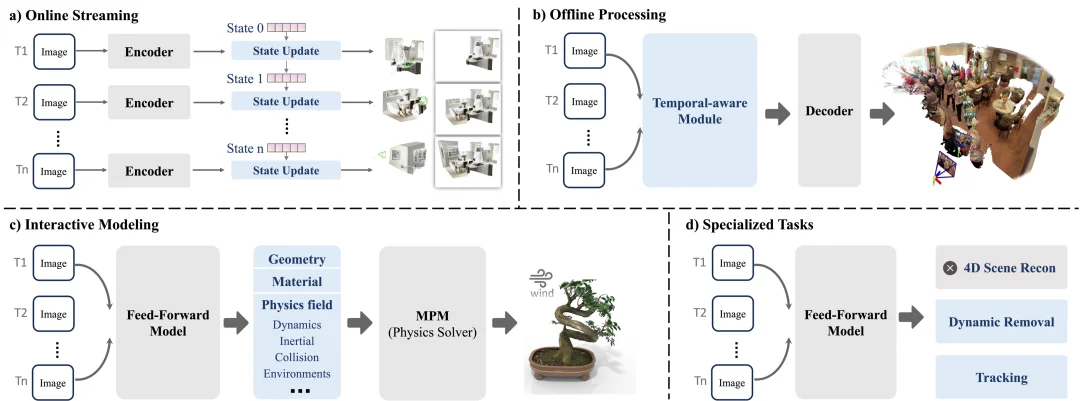
图 7:时序感知前馈式 3D 模型的主要范式。涵盖在线流式建模、离线时序处理、交互式建模以及面向特定任务的时序方法。
不只方法整理,这篇综述还
重新梳理了 benchmark 和应用全景
很多综述在数据集和 benchmark 部分往往只是罗列,而这篇文章进一步从评测目标出发,将数据集划分为 geometry-oriented 和 visual-oriented 两类。前者更强调点云、深度、位姿等几何质量,后者则更关注新视角合成中的视觉真实感。论文明确提到,这样的划分有助于更清晰地理解不同 benchmark 对方法发展的牵引作用。
与此同时,文章还系统总结了前馈式 3D 在自动驾驶、机器人、场景理解、SfM/SLAM、视频生成和视觉定位等方向上的应用。作者认为,这一范式已经从研究概念逐步走向实际技术能力组件,正在持续降低 3D 建模在真实系统中的使用门槛。
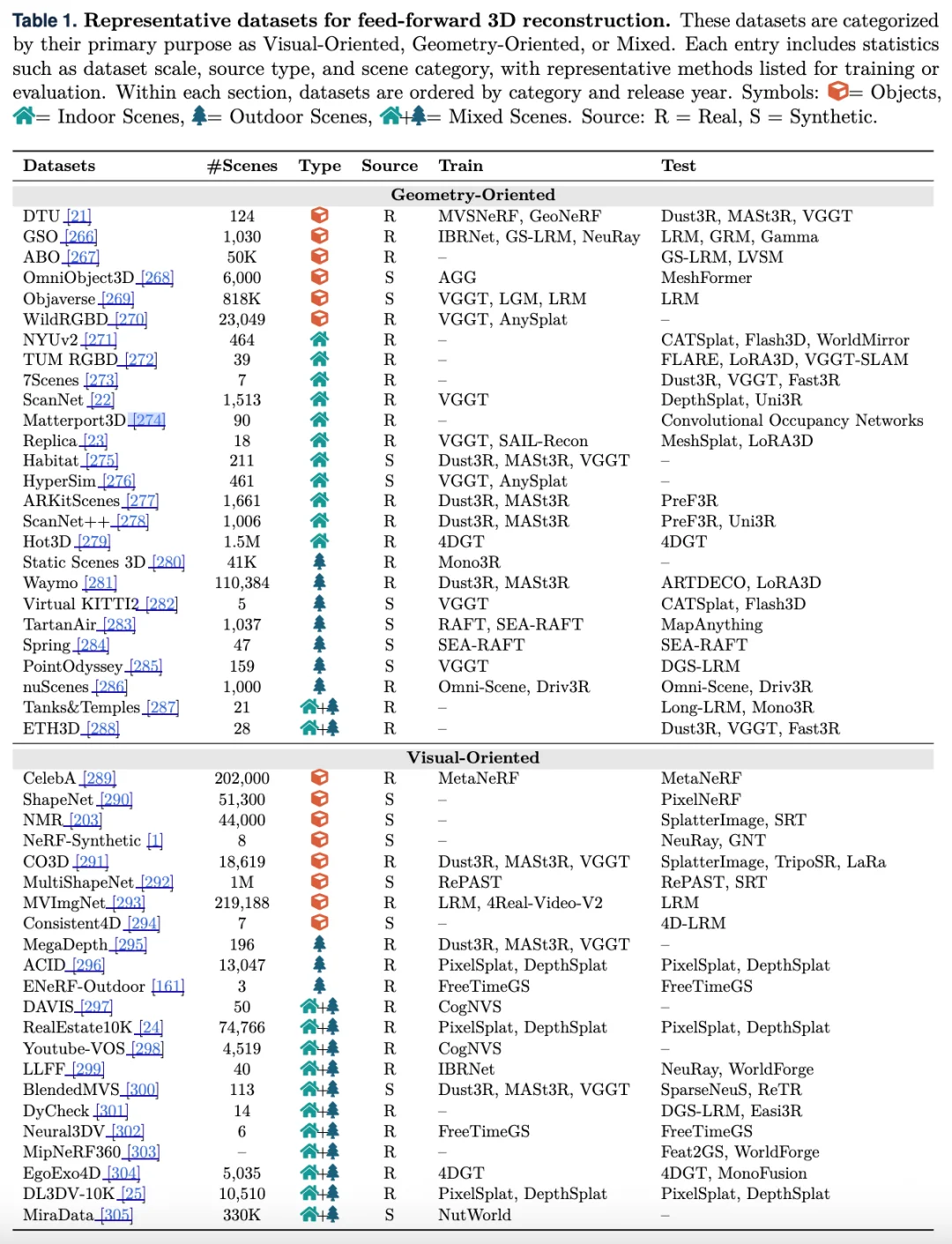
表 1:前馈式 3D 重建代表性数据集汇总。本文按照主要用途将现有数据集划分为几何导向、视觉导向和混合类型,并进一步统计其数据规模、来源类型、场景类别以及代表性的训练与测试方法,用于展示当前前馈式 3D 场景建模的数据基础与评测生态。
未来趋势:前馈式 3D 会走向哪里?
在最后的讨论中,论文将未来方向总结为 benchmark rigor、model efficiency、scalable scene representations、world models、unified perception and reconstruction 等几条主线。尤其值得注意的是,作者把 world models 纳入前馈式 3D 的未来图景中,这意味着前馈式 3D 不再只是「更快的三维重建」,而可能成为未来空间智能和世界建模系统中的基础模块。
总结
这篇综述最大的价值,不只是系统总结了前馈式 3D 场景建模的发展,更在于它提出了一个更具解释力的视角:相比按表示形式分类,围绕特征、几何、效率、增强和时序这些核心问题来理解方法演进,更能揭示这一领域真正的研究脉络。
从这个意义上说,这篇工作不仅为新进入这一方向的研究者提供了一张清晰的路线图,也为整个社区重新理解前馈式 3D 提供了一个更统一的分析框架。它让我们看到,前馈式 3D 的核心,不只是「输出什么三维表示」,而是「如何更稳、更准、更快地建立对三维世界的理解」。
作者介绍
本文由浙江大学、南洋理工大学、Monash 大学、苏黎世联邦理工学院(ETH Zurich)及图宾根大学等机构联合完成。作者包括:Weijie Wang(浙江大学博士生)、Qihang Cao(共同一作)、Sensen Gao(共同一作),Donny Y. Chen(Project Lead),Haofei Xu、Wenjing Bian、Songyou Peng、Tat-Jen Cham、Chuanxia Zheng、Andreas Geiger(图宾根大学教授)、Jianfei Cai(Monash 大学教授,IEEE Fellow),及通讯作者 Jiawang Bian 与 Bohan Zhuang。
文章来自于微信公众号 "机器之心",作者 "机器之心"


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
