# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。
作为面向大语言模型长上下文场景的通用高效推理技术,LCA 突破传统注意力机制效率瓶颈,以轻量化、无侵入、高性能的架构设计,为长文本大模型工业化部署提供通用解决方案。在 128K 超长上下文场景下,LCA 实现 2.5 倍预填充加速、90% KV 缓存缩减、1.8 倍解码延迟降低,同时保持原有性能。
该技术可通用适配 MiniCPM、Qwen 等不同规模、不同注意力架构的大模型,具备极强的扩展性与落地性,能够显著降低长上下文大模型的硬件门槛、推理成本与部署难度,全面提升推理效率与用户体验。
目前,LCA 论文与代码已开源,欢迎学术界与产业界共同推进技术迭代与落地应用。

在使用 DeepSeek、Qwen 等大语言模型处理长文档、进行深度对话时,我们常常遇到两个令人头疼的问题:
为了应对这些挑战,先前的研究提出了两条技术路线:
然而,现有方案往往「顾此失彼」。MLA 成功省下了显存,却未能摆脱计算量随上下文平方级增长的困境;稀疏注意力虽能跳过冗余计算,却依赖完整的 Q/K/V 矩阵。如果强行将两者拼凑,就必须先把 MLA 压缩的数据「解压」还原,无异于「先压缩再解压」,白白浪费了 MLA 轻量化设计的红利。
在长上下文高效注意力领域,近期业界也提出了多项优秀方案,如 DeepSeek 发布的稀疏注意力(DSA)和 Kimi 提出的 KDA。但与这些方法相比,LCA 在技术设计上具有三个关键差异点:

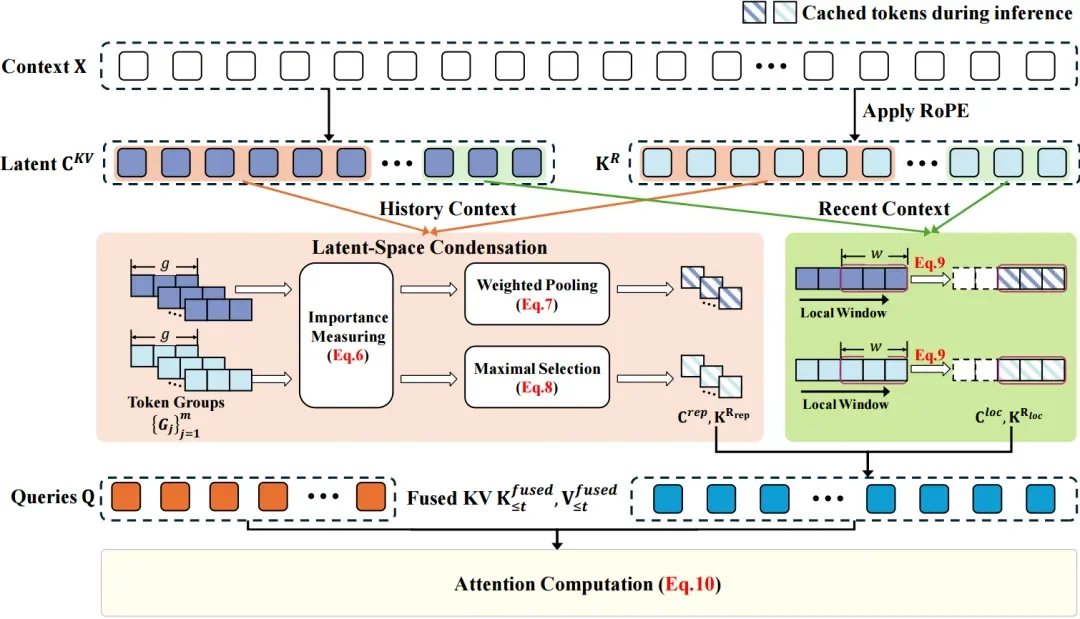
图 1. LCA 架构示意图
为了解决上述问题,本文提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),如图 1 所示。LCA 的核心思想是:直接在 MLA 的「压缩空间」中进行信息精简,而不是先解压再筛选。
1. 关键信息压缩三步走
将长文本分成多个小组,每个小组 16 个 token。最近 1024 个 token 会完整保留,确保最新信息不丢失细节。
采用「智能加权」方法:根据当前查询的重要性,对组内信息进行加权合并,突出最相关的内容。就像根据考试重点做笔记,重点内容更详细。具体而言,对于每个分组内的语义潜在向量,LCA 采用加权池化的方式生成一个代表性向量:
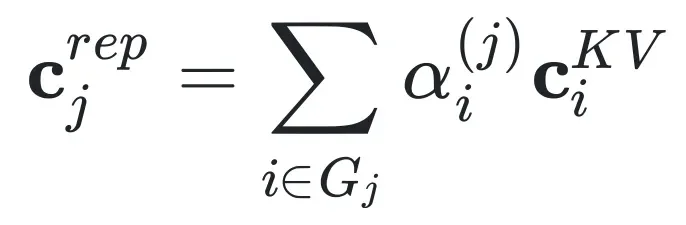

对于位置键向量,选择每个组中注意力得分最高的 token 作为「位置锚点」:
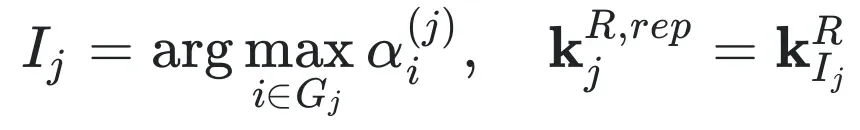

2. 保留细粒度局部上下文
除了长距离上下文的压缩外,LCA 还保留一个局部窗口(默认 1024 个 token)的完整潜在向量,确保最近的关键信息不被压缩,维持模型对局部细节的敏感性。
3. 理论保证:长度无关的误差上界
本文从理论上证明了 LCA 的近似误差具有与上下文长度无关的均匀上界:
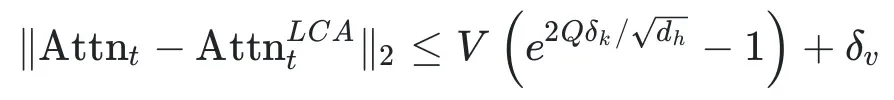

1. 效率提升
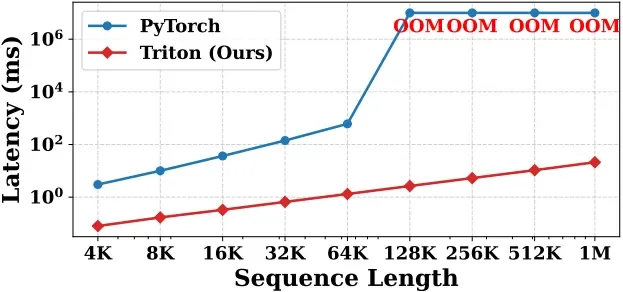
图 2. Triton 内核加速效果对比
作者通过 Triton 进行了硬件友好的高效实现,相比 PyTorch 实现,在 64K 上下文能够实现 24.4 倍加速。
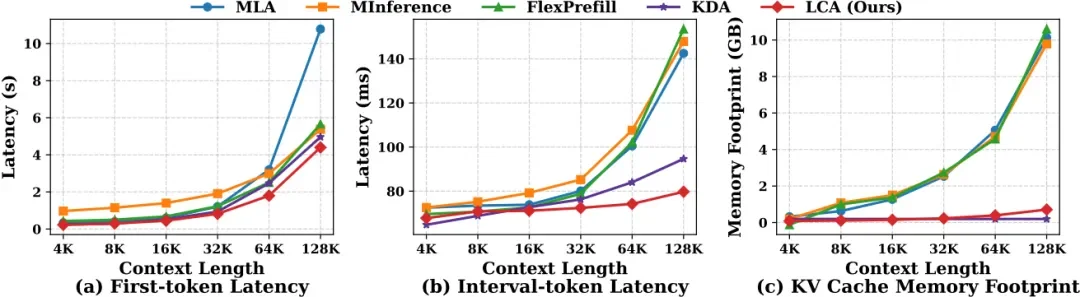
在 128K 上下文长度下,高效 LCA 相比原始 MLA 实现了 2.5 倍预填充加速,减少了 90% KV 缓存,每 token 解码延迟降低 1.8 倍。
2. 长上下文性能保持
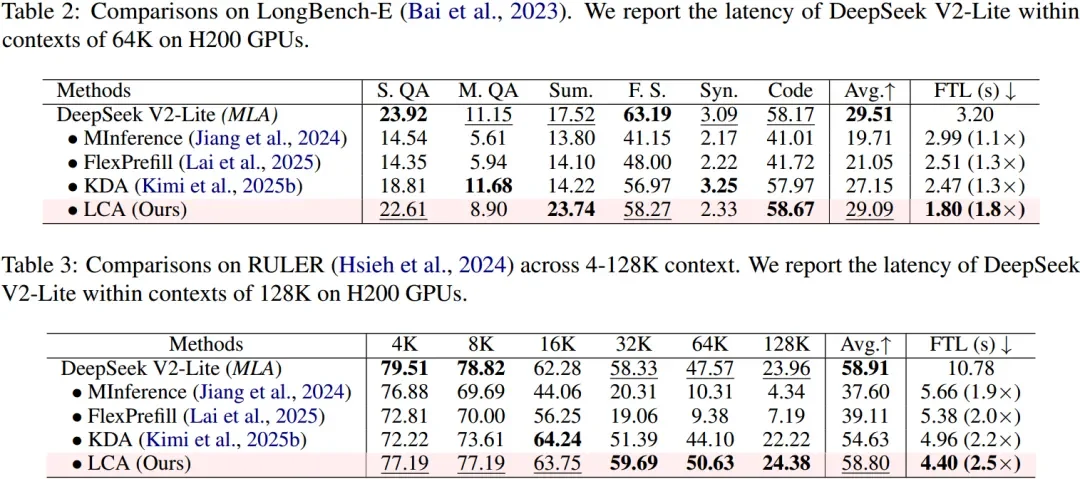
在 LongBench-E、RULER 等长上下文基准测试中,LCA 在获得显著效率提升的同时,保持了与原始 MLA 相当的性能。其中 LongBench-E 性能与标准 MLA 几乎持平,RULER 128K 结果上甚至略有提升。
3. 短上下文任务无损
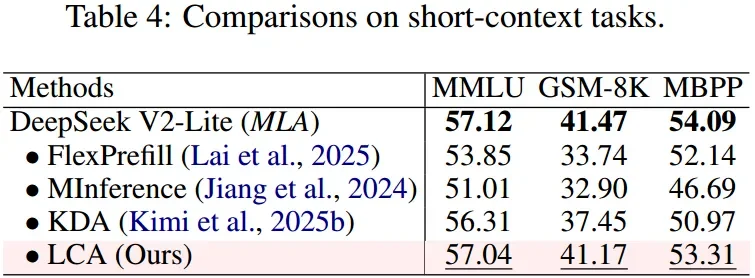
短上下文标准任务性能对比
在 MMLU、GSM8K、MBPP 等短上下文标准测试中,LCA 的性能与原始 MLA 几乎相同,表明其压缩机制不会损害模型的基础能力。
4. 兼容不同模型规模
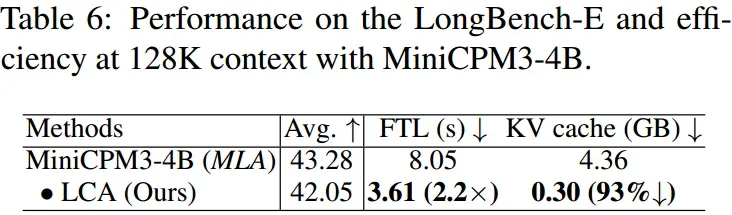
MiniCPM3-4B 模型扩展性验证
LCA 在 MiniCPM3-4B 模型上同样有效,实现 2.2 倍预填充加速和 93% KV 缓存减少,验证了其在不同规模模型上的通用性。
5. 适配其他注意力变体
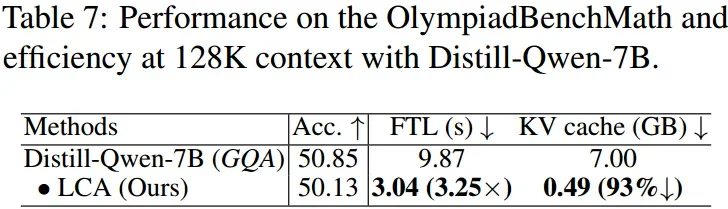
GQA 架构适配验证
LCA 的设计不依赖于 MLA,可推广到其他注意力机制。实验表明,将其适配到分组查询注意力(GQA)后,在 DeepSeek-R1-Distill-Qwen-7B 模型上仍能实现 3.25 倍推理加速和 93% 缓存减少。
LCA 为长上下文 LLM 的实际部署提供了重要支持:
LCA 通过直接在潜在空间进行上下文压缩,巧妙地将 KV 缓存减少与计算复杂度降低统一到一个框架中。其解耦的语义-位置处理策略、理论保证的近似误差界,以及广泛的实验验证,使其成为长上下文高效建模的一个有力解决方案。这项工作已被 ACL 2026 接收,期待更多研究者与开发者在此基础上进一步推动长上下文技术的发展。
文章来自微信公众号 ” 机器之心 “


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
