# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
有时候看到一些大模型项目,总会怀疑是不是真的有外星人在干预地球科技。
就比如今天这个。
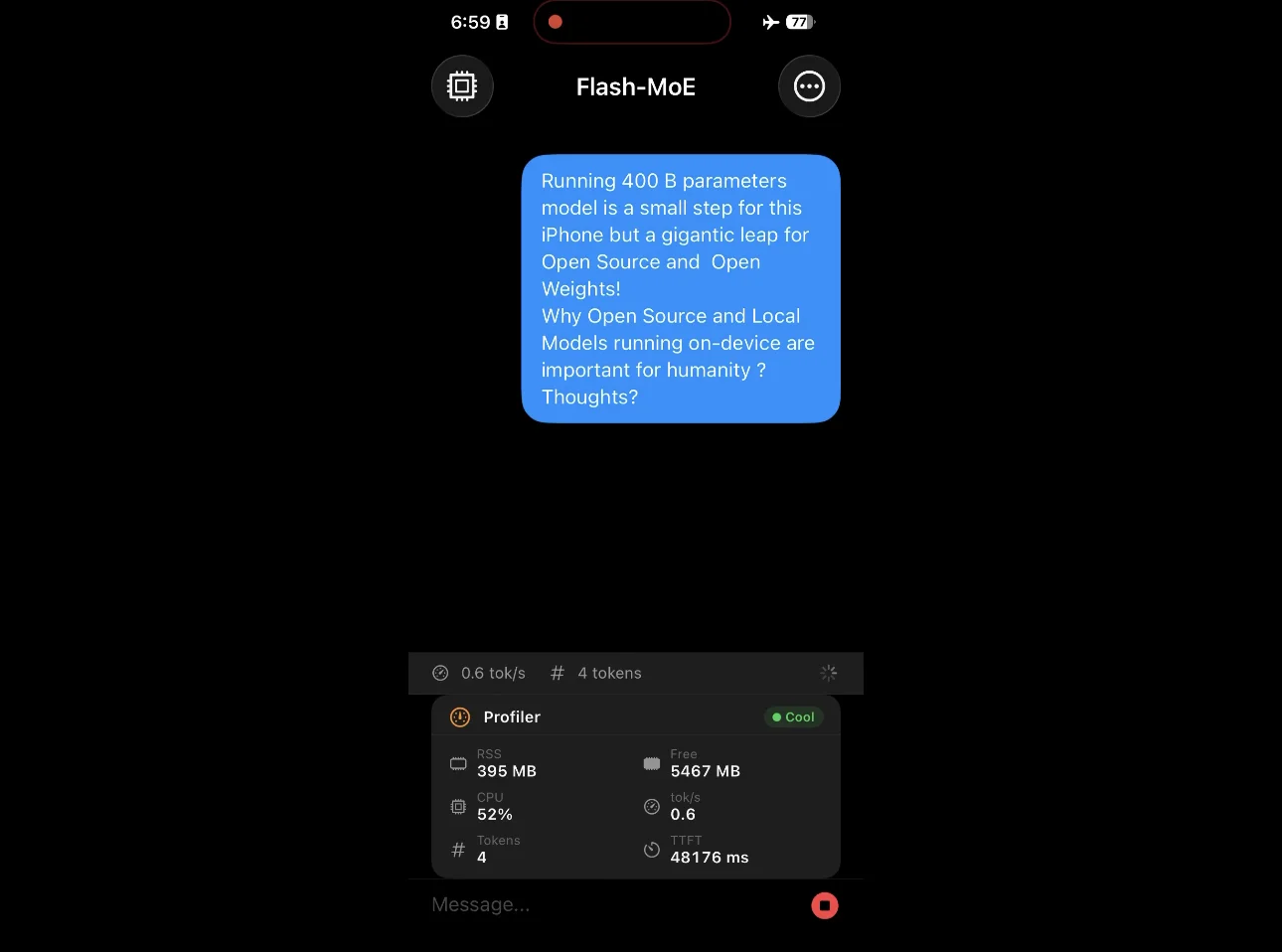
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。

尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!
准确的来说,这是在 iPhone 17 Pro 的 A19 Pro 芯片上运行的 MoE 模型 Qwen3.5-397B-A17B。
由于苹果芯片的统一架构设计,在 Mac 芯片上运行和在 iPhone 芯片上运行大模型本质上区别并不大。因此,该项目可以说是由来已久。
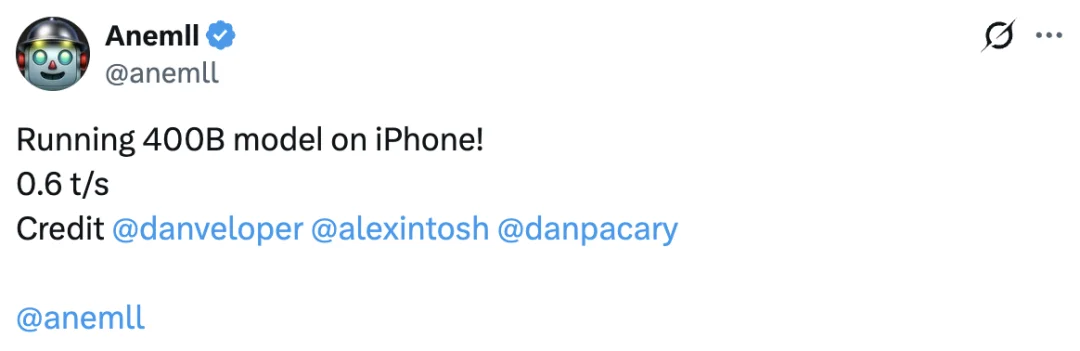
我们发现,以上演示是来自于「Flash-MoE:在 Apple Silicon 上运行的 Qwen3.5-397B-A17B」的开源项目。
Flash-MoE 极简主义的胜利
那 Flash-MoE 是什么呢?
Flash-MoE 引擎是开源社区大名鼎鼎的项目,是拜登的前首席技术官 Daniel Woods,与人工智能大模型 Claude Code 4.6 共同研究开发,,标志着 「端侧大模型」 进入了一个近乎荒诞但极具突破性的新阶段。

Flash-MoE 摒弃了所有现代 AI 框架的 「重装甲」,回归了极致的底层开发:
整个模型体积为 209 GB(在 2-bit 专家重量化后为 120 GB),通过并行的 pread () 调用从磁盘流式读入,且在任何时刻仅有 5.5 GB 的权重驻留在内存中。
关键创新点包括:
1. 融合三指令缓存(Three-command-buffer)GPU 流水线: 消除了 CPU 与 GPU 之间的同步开销。
2. BLAS 加速线性注意力机制: 用于 Gated-DeltaNet 层。
3. 反直觉的缓存策略: 移除了所有应用层缓存,完全交由 macOS 页面缓存(page cache) 独占管理专家数据;通过消除内存压缩器的频繁抖动(thrashing),实现了 38% 的速度提升。
这一工作在 Apple M3 Max 芯片上实现了 5.74 tok/s 的持续速度和 7+ tok/s 的峰值速度。这是首次证明在消费级硬件上,模型规模超过 DRAM 容量 4 倍以上仍能以交互级速度运行的研究工作。
不过,原作者 Dan Woods 显然并没有预料到 400B 大模型能够在 iPhone 上运行。
LLM in a Flash 的遗产
最初,这个项目的灵感源于 Apple 的研究报告。其核心逻辑很像当年英特尔傲腾的思路:既然内存装不下,那就把 SSD 当作内存用。
Dan Woods 在开发该项目的时候就使用了苹果在 2023 年的论文《LLM in a flash:具有有限内存的高效大型语言模型推理》中描述的技术。

该论文解决了在 DRAM 容量不足的情况下,如何高效运行大语言模型的挑战。
方法是将模型参数存储在闪存中,并根据需求将其调入 DRAM。研究团队构建了一个结合闪存特性的推理成本模型,并据此在两个关键领域进行了优化:一是减少从闪存传输的数据总量,二是确保以更大、更连续的数据块进行读取。
这一方法受到了广泛的讨论。尤其是利用 MoE 模型的活跃专家的特性,是让一个超大参数体积的模型运行在本地的消费级芯片的重要原因。
虽然 iPhone Pro 的 RAM 非常有限(总共 12GB),但仍然需要它来运行模型的活跃部分。


此外,模型的量化设计也引发了一定的讨论。

但不论如何,400B 大模型的确在移动端设备跑起来了,哪怕又慢又卡又不完整,但始终是向人手一个本地大模型的美好愿景更进一步。
文章来自于微信公众号 "机器之心",作者 "机器之心"


