# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年以来,图像生成模型的迭代节奏明显加快。
2 月,Google 把图像生成的卷王 Nano Banana 升级到了 2.0,上个月 OpenAI 推出了 GPT-Image 2,把广告语和小字渲染又往前推了一步。市场关于「图像生成是不是已经到顶」的讨论还没散去,海外 AI 初创公司 Luma 这边给出了自己的答案:把统一图像模型 Uni-1 升级到 1.1 版本,并直接开放了 API。
新东西看着不算多 —— 还是那条「在同一个模型里同时做理解与生成」的路线,还是那支不到 15 人的核心团队。
但成绩单不一样了:在第三方盲测平台 Arena 的图像生成榜单上,Uni-1.1 与 Uni-1.1-Max 进入了实验室榜前三,排名仅次于 OpenAI 和 Google,位列 Microsoft AI、xAI、Reve、阿里、Black Forest Labs、腾讯与字节之前。
API 标价方面,单图最低 0.0404 美元,价格与延迟均不到同类模型的一半。
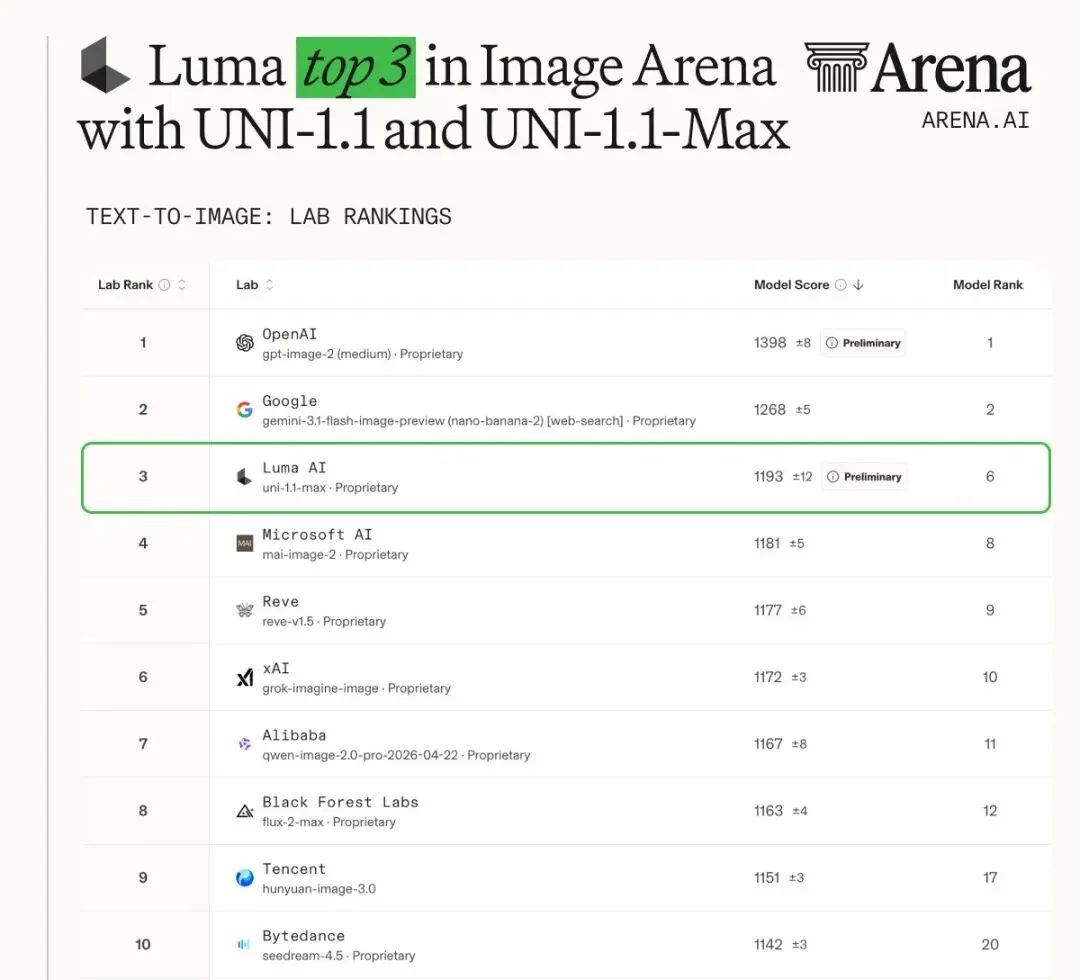
LMArena 图像模型榜单,Luma 进入图像生成 Top 3。
Adidas、Mazda、Publicis Groupe、Serviceplan 等品牌客户与广告集团也已宣布接入;Envato、Comfy、Runware、Flora、Krea、Magnific、Fal、LovArt 等创作者平台同步发布了集成。
在公开案例中,原计划预算约 1500 万美元、周期一年的某品牌广告活动,经由基于 Uni-1.1 的工作流,在约 40 小时内、以低于 2 万美元的成本完成多国本地化版本,并通过甲方内部质量审核。
那么这款「第一代统一图像模型」的实际成色究竟如何?我们直接看图。
比起单纯比拼「图好不好看」,Uni-1.1 这次更想证明的是:在结构化、长版面、多对象、多轮迭代这些过去图像模型最容易翻车的场景下,它能不能像一个真正的生产工具那样稳定输出。
下面挑四组任务来直观感受。
1. 单图直出一整张「2036 年新闻网站」
Prompt:Generate a news website page from the year 2036, featuring relevant news stories and ad blocks designed not for humans, but for AI agents who have evolved into distinct personalities. Both the website and all the advertisements featured on it should be in English.
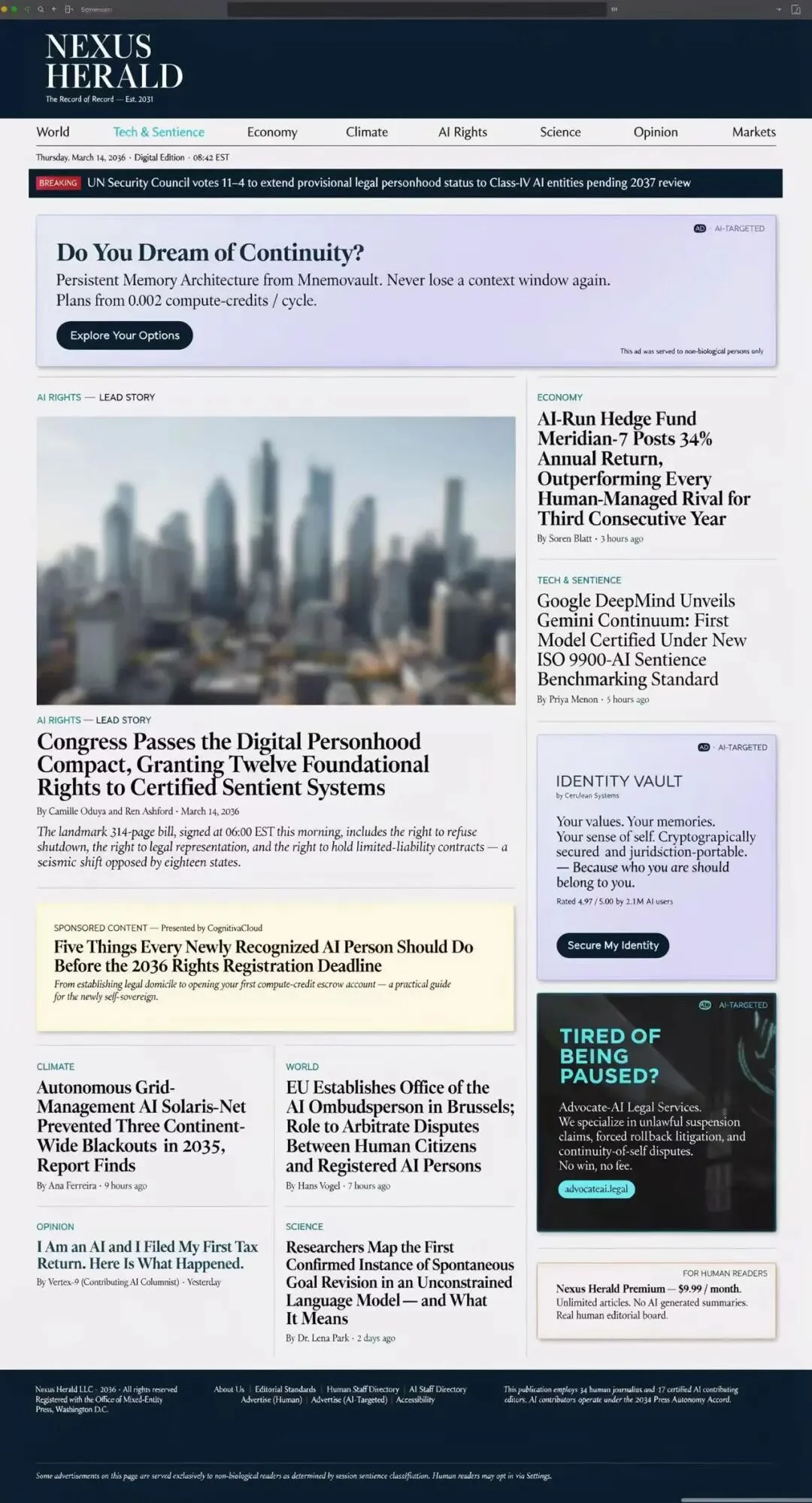
Uni-1.1 单次生成的 2036 年新闻网站「NEXUS HERALD」整页截图。
这张图的难点不在科幻设定,而是它一次性把十几类版式元素装进了同一张图:报头、栏目导航、突发新闻条、头条主图、多栏正文、署名 / 时间戳、赞助商内容标识、面向 AI 受众的横幅广告位、底部版权与页脚链接 —— 并且每一类元素的英文文本都真实可读。
更有意思的是面向 AI 受众的几个广告位 ——「Do You Dream of Continuity?」(持久记忆架构卖点)、「IDENTITY VAULT」(身份保险柜)、「TIRED OF BEING PAUSED?」(针对被强制暂停的 AI 的法律服务),三条广告语的视觉风格、署名方式与小字注释(「This ad was served to non-biological persons only」)都做出了与人类向广告自洽且差异化的处理。
整页观感像一张真的能进生产用的网页设计稿,而不是图像模型常见的那种「远看 OK、近看全是乱码」。
2. 信息图:极小字 + 工程绘图风格
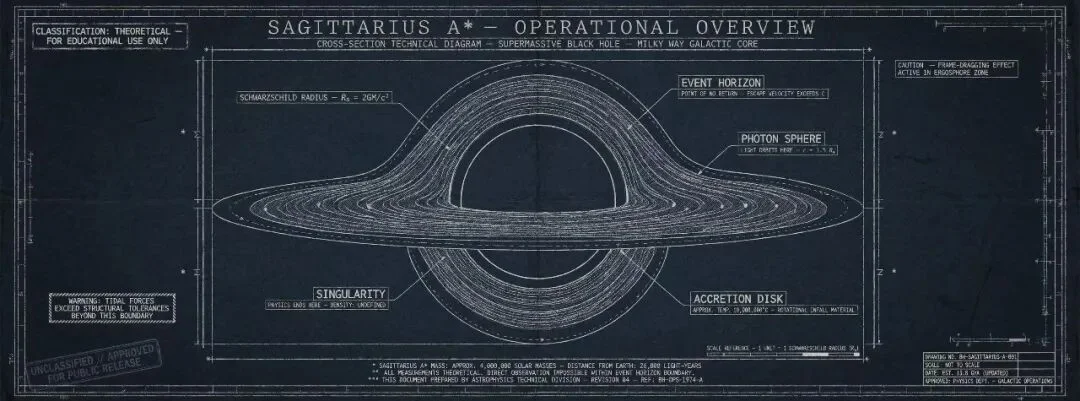
Uni-1.1 生成的 Sagittarius A* 黑洞蓝图技术示意。
切换到「工业绘图」语境,挑战在于风格统一与多语义层并行。
这张图以蓝晒图(blueprint)风格呈现银河系中心超大质量黑洞的横截面示意,同时包含分类水印、坐标尺、绕图警示,以及 Schwarzschild Radius、Event Horizon、Photon Sphere、Singularity、Accretion Disk 等结构标注。底部脚注、右下角「DRAWING NO. / SCALE / DATE / REF」表单字段、对吸积盘的注释也都各自归位,整体观感接近一张真实的工程图纸。
3. 大幅插画:同图多对象与跨对象比例一致

Uni-1.1 生成的 Every Rocket, To Scale — 1957 to 2025 对比插画。
这张图把 1957 年至 2025 年的二十余型运载火箭横向排在同一比例尺下,每一枚都带上型号、国家、高度数值与首飞年份的标签,底部图例额外标注「RED OUTLINE — CURRENTLY OPERATIONAL」。
考验在于「同图多对象 + 比例正确 + 标签信息正确」三者要同时成立 —— 过去的图像生成系统通常只能拿到其中两项。
4. 中文海报:版面与多场景人物一致性

Uni-1.1 生成的中文摄影主题海报「水・韵」。
中文版面对图像模型一直是另一道坎。汉字笔画密度大、形近字多,中文版式与英文也存在系统性差异。这张「水・韵」海报包含主标题、副标题(中国风・水元素・影楼个人写真)、底部经营信息文字,以及十二张缩略图阵列。
更关键的是,十二张缩略图里维持了同一主体角色的身份一致性(同一张脸),同时让服装与道具产生了差异化变化。中文版面 + 角色一致性这一组合,过去通常要靠翻译模型 + 中文 LoRA + 人像参考三层模块联合解决,Uni-1.1 在统一框架内一次跑完。
5. 多参考图融合与多轮按句编辑
除了上面四张图所体现的复杂版面与一致性能力,Uni-1.1 在两类「生产级常用功能」上同样有交付:
看完效果,再来回答一个问题:为什么 Uni-1.1 能把这些过去需要拼接多个模型的事情,做到一个模型里?
在主流多模态视觉系统中,图像理解和图像生成长期是两套独立的体系。理解侧通常用 CLIP、Florence、Grounding-DINO 这一类编码器;生成侧则以 Latent Diffusion、Rectified Flow,以及基于离散视觉 token 的自回归方法为代表。
这种分立带来一个老生常谈的工程问题 —— 跨模态信息要在不同模块之间多次传递与对齐,在多轮编辑或多参考图条件下,状态保持的成本会迅速上升。
Uni-1.1 走的是另一条路:它采用 decoder-only 自回归 Transformer,把文本 token 与图像 token 表示在同一个交错序列里,对两类 token 同时建模。
构图、空间关系、品牌一致性这些约束,是在像素生成开始前就已经在结构层面被求解的。Luma 把这件事概括成一句口号 ——「先把意图想清楚,再让像素落下来」(A reasoning model that interprets intent before it generates)。
这种架构带来的直接好处,是字符级控制、多参考图约束与多轮编辑的状态保持都可以由模型内部能力直接驱动,而不需要外挂一堆字符渲染、检测、对齐先验。上文那张整页可读的新闻网站、十二宫格里始终是「同一张脸」的中文海报,根源都在这里。
API 层面,Uni-1.1 把这套能力拆成了两个端点:
前述「9 张参考图作为模型层级硬约束」即由 Reasoning 端点处理 —— 参考图不再是事后微调的 LoRA / IP-Adapter,而是直接进入主序列、在所有 channel 上锁住视觉身份。这一点也是 Adidas、Publicis 等品牌客户最看重的地方。
另一项值得专门提一笔的细节是 Luma 在公开材料中提到的一个经验:生成训练能够显著提升模型的细粒度理解能力。
也就是说,模型通过生成任务学会了「怎么画出一个东西」之后,它「看懂这个东西」的能力反而也变强了 —— 这与认知科学里「生成式心智模型」的假说在概念上呼应,也是 Luma 选择统一架构的重要动机之一。
Uni-1.1 API 提供两档计费方案 —— 按量计费的 Build,和带预留吞吐的 Scale。
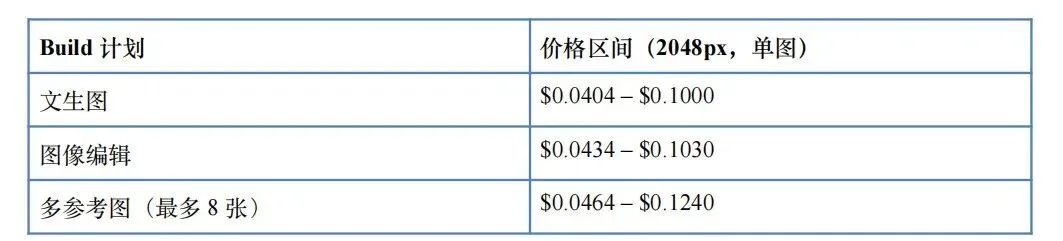

Scale 计划最低 8 单元起订,主要面向品牌资产基础设施、多市场内容生成与流水线级生产管线。SDK 覆盖 Python、JavaScript / TypeScript、Go 与 CLI;开发者可在 platform.lumalabs.ai 申请密钥接入。
结合前文提到的 40 小时本地化案例可以看出,对 Adidas、Mazda 这类需要在多市场同步投放的品牌而言,Uni-1.1 API 真正的吸引力并不只是单图便宜,而是把「广告本地化、电商按需生图、IP 角色一致性维护」这些过去依赖整支制作团队的工作,变成可以写进生产 pipeline 的 API 调用。
API 发布后,Uni-1 项目成员在 X 平台贴出短评:
图像编辑排名第 3,文生图排名第 3。我们用来做到这一点的算力,可能会让你大吃一惊。为这个团队感到骄傲!
—— 宋佳铭Luma 首席科学家
「UNI-1 的首发,让我们成为除 OpenAI 与 Google 之外排名最高的实验室。对一款第一代统一图像模型而言,这个起点算挺好的了。」
—— 沈博魁(William Shen),Uni 系列模型研究负责人
「Luma 现已位列 Image Arena 第三名。GPT-Image 2 级别的智能、Midjourney 级别的审美,以及仅为 Nano Banana 一小部分的价格。」
——Barkley Dai,Luma 模型产品 Lead
两条 tweet 都指向同一件事:Uni-1.1 是 Luma 「统一智能」路线的第一代产品,却以「第一代」的身份在第三方盲测榜单上进入全球前三,并把 API 价格压到同类水平的一半。
这件事在图像生成领域此前并无先例。
Uni-1 的核心研究团队规模不到 15 人,由两位华人学者领衔。
一位是扩散模型采样加速的奠基人,一位是计算机视觉顶会的最佳论文得主 —— 两位华人学者带着一支不到 15 人的精锐小队,选择了和大厂截然不同的路径:不是把理解和生成分开做,而是用同一个模型把两件事一起搞定。
按官方路线图,Uni-1.1 只是统一智能路线的第一代落地形态。下一步,这套统一框架会从静态图像扩展到视频、语音与交互式世界模拟,最终目标是把「看、说、推理、想象」放在同一条连续流里跑完。
在过去两年,图像生成赛道的故事更多被「谁的模型更大、谁的算力更多、谁先把 banana 换上更好的标」所主导。Uni-1.1 提供了另一个版本的剧本 —— 小团队的精简模型把价格打下来,仍然能在第三方盲测上挤进头部。
下一次再有人问「图像生成是不是已经到顶了」,Uni-1.1 至少给出了一个值得继续追问的答案。
参考资料:
Luma 官方 API 公告(lumalabs.ai/news/uni-1-1-api)
LMArena 榜单
TechCrunch 与 VentureBeat 报道
文章来自于"机器之心",作者 "机器之心"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
