# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些个例问题,其中“模型无法说出马嘉祺”这个问题引发了较多讨论。
我们也注意到,社区中有不少开发者对这个现象进行了高质量的分析和论证工作。内部排查后,我们认为这个问题背后的机制值得做一次系统梳理,决定将排查过程和实验结果整理出来,希望能为社区讨论提供更多参考。
01
大模型为什么说不出马嘉祺?
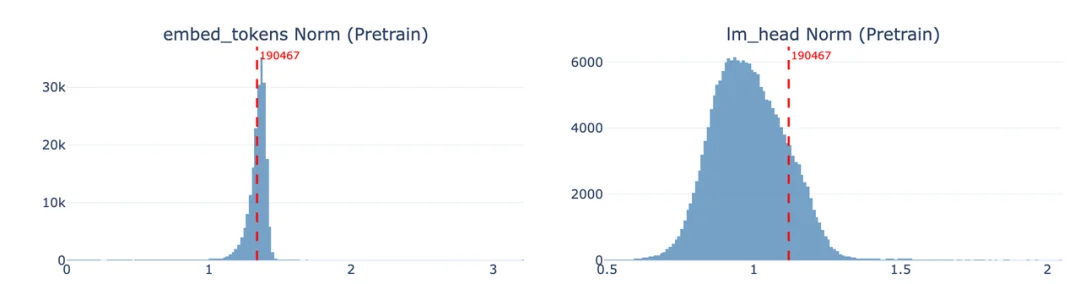
我们从分词器版本对齐、embedding 统计分布、语义近邻检索、预训练与后训练模型的 few-shot 对比实验、后训练数据频次统计以及对全词表 lm_head 变化幅度的排序扫描等多个维度进行了排查。最终定位到的原因是:“嘉祺”在分词器中被合并为一个独立 token,但该 token 在后训练数据中出现频次极低,导致模型在后训练中逐渐遗忘了对该 token 的生成能力。

展开来讲,我们知道大模型不是逐字读写文本的,而是先将文字切分成不同的词元(token),再以 token 为单位进行处理。在排查过程中我们发现,“马嘉祺”被切成了两个 token:['马','嘉祺']。
“嘉祺”两个字平时在中文里很少连用,分词器(tokenizer)在训练时基于大规模文本的统计频次决定如何合并字符——“嘉祺”作为人名整体出现的次数足够高,以至于让它被合并成一个独立 token。模型要输出这个名字,必须把“嘉祺”作为一个整体输出。
大家也了解,大模型的训练分两个阶段。第一阶段是预训练,模型阅读海量互联网文本,什么都学。第二阶段是后训练,用精选的对话数据教模型怎么聊天、怎么遵循指令。预训练阶段,模型见过关于马嘉祺的内容,学会了“嘉祺”这个 token;
但后训练的对话数据里,包含“嘉祺”的样本不到 5 条,导致后训练过程中,“嘉祺”这个 token 几乎没有被模型练习过,而后训练时大量频繁出现的 token(如 tool_call 标记、代码符号)会持续更新自己周围的向量空间,把“嘉祺”这种没被练到的低频 token 挤压到了不该去的方向。到了该输出名字的时候,模型说不出“嘉祺”,转而选了发音相近的“佳琪”、“琪琪”等被练习过的 token。
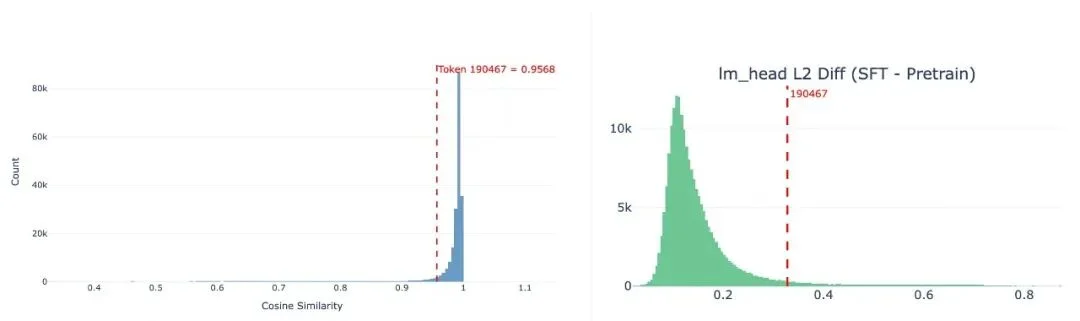
我们通过对比实验验证了这一判断:同样的问题,预训练阶段的模型能正常输出“马嘉祺”,后训练之后就不行了。同时,模型仍然能准确回答马嘉祺的所有信息,也说明理解能力没有受损,丢失的只是输出这个 token 的能力。
到这一步,补数据就可以修复。但我们更想知道:这种退化只发生在“嘉祺”上吗?
02
系统性审视退化问题
我们对约 20 万 token 的整个词表进行了全量扫描,计算每个 token 在后训练前后输出参数的变化幅度,发现约 4.9% 的 token 发生了显著退化。
退化 token 大致分为四类:预训练阶段的特殊标记(如代码填充符号)、LaTeX 公式与维基百科源码标记、中文 SEO 垃圾内容、以及日文口语和博客模板表达(最大类别,占比 40%+)。其中特殊标记和格式标记的退化是预期内的,这些 token 在预训练和后训练的用途本就不同。
按退化程度排序,排第 6 的是“传奇私服”,排第 17 的是“无痛人流”,排第 166 的是“外墙涂装”。这些是典型的互联网 SEO 垃圾关键词,在预训练的互联网数据里大量出现,分词器为它们分配了独立的 token 编号,但在后训练的对话数据里完全没有出现过。它们和“嘉祺”的退化机制完全一致:预训练时学会了,后训练时因为没有被练到而遗忘了。
日文口语和博客模板类占比最大,引起了我们更多的关注。我们也联想到一个一直未能定位根因的已知问题:此前模型在处理日语对话时,偶尔会在回答中混入俄语或韩语字符。这个现象曾被归类为“小语种语言混杂”,尝试过多种排查方向但一直没有找到确切原因。

顺着这次的发现,答案浮出了水面。我们按语种统计了 token 退化比例:29.7% 的日语 token 发生了显著退化,韩语 3.3%,俄语 3.7%,中文 3.9%,英文 3.5%。日语的退化程度远超其他语种。
结合此次的分析,我们发现两个问题可能共享同一机制:
由于后训练数据中日文内容的覆盖严重不足,导致这些日文 token 参数发生漂移,与其他语言的 token 在向量空间中发生混淆,既可能导致日文 token 在不该出现时被错误激活(语言混杂),也可能导致与之空间相邻的低频中文 token(如“嘉祺”)被挤出正常的生成概率范围(token 遗忘)。
这一发现将原本看似独立的两个问题统一到了同一个框架下,也为后续的修复方案提供了更清晰的方向。
03
解决方案与思考
定位到根因之后,修复思路就很清晰了:确保每个 token 在后训练阶段都能被练到。
我们构造了一份覆盖全词表的合成数据,核心思想是:通过一个简单的复读任务,为全词表建立一个生成频率的“下限保障”,防止任何 token 因为完全缺失而退化,且效果是显著的:
除了这一方案之外,我们也在探索其他方向,具体方向包括:
上述修复策略都是在后训练阶段进行补救。从更根本的角度看,这一问题的深层原因在于分词器的设计与下游使用场景之间的脱节。
当前大模型的分词器通常基于大规模预训练语料训练而成,词表中不可避免地包含大量仅在特定领域或语言中出现的 token。这些 token 在预训练阶段能够获得充分的训练,但进入后训练阶段后,由于后训练数据与预训练数据的分布差异,这些 token 的生成能力会逐渐衰退。
因此,后训练阶段的数据覆盖策略需要同时考虑两个维度:一是从业务角度确保不同任务类型和领域的覆盖(语义层面),二是从更底层的统计角度确保词表中每个 token 都有足够的生成频率(token 层面)。将 token 覆盖度作为后训练数据质量的一项常规监控指标,可以在早期发现潜在的稀疏 token 退化风险,避免类似问题在线上复现。
以上是我们对“嘉祺识别”问题的完整排查过程和技术思考。感谢社区开发者的关注和分析,这些讨论对我们定位问题方向有很大帮助。完整的排查细节、实验数据和方法论,可以在技术博客原文中查阅。
Intelligence with Everyone.
文章来自于微信公众号 "MiniMax 稀宇科技",作者 "MiniMax 稀宇科技"



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
