# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
Next-Token Prediction(NTP)无疑是一个英雄,它与Transformer一起,开启了大模型时代。每一步只预测一个 token,看似「盲人摸象」,却让模型学会了语言规律,吸收了海量世界知识,也提供了一个稳定、可扩展的训练范式。
可以说,没有NTP,就没有今天的 LLM。
但问题在于,昨日的英雄,往往也最容易成为今日的枷锁。
作为一种本质上「短视」的训练目标,NTP 与人类的思考存在着微妙却深刻的错位。我们不妨想一个有点荒诞的场景:
你在下棋,对手已经布好了一个明显的陷阱。而你却只盯着:「下一步这颗子下哪最顺手?「
你不看未来走向,不看对方意图,只求当前一步「最合理」。这像不像今天很多大模型?
局部极其自信:「这一步,我非常确定」;但下一步、下下步,整个链条却可能跑偏。稍加追问,又收敛为谨慎甚至回避的姿态。
局部很流畅,全局却常常离谱。这种「自信而短视」的特征,尤其是在数学推理、代码生成、多步规划等依赖长程一致性的任务中,往往成为大模型表现的瓶颈。那么,问题到底出在哪里?
华东师范大学与复旦大学团队在 ICLR 2026 的工作中给出了他们的回答:大模型未必不会「想远一点」,它只是被长期训练成了「只能看下一步」。
换句话说,问题或许不在大模型能力本身,而在于我们究竟如何去「教」它。作者提出了一个耐人寻味的视角:与其执着于 Next-Token,不如尝试 Next-ToBE — Next Token-Bag Exploitation。

论文链接:https://openreview.net/pdf?id=T8IJojfaOh
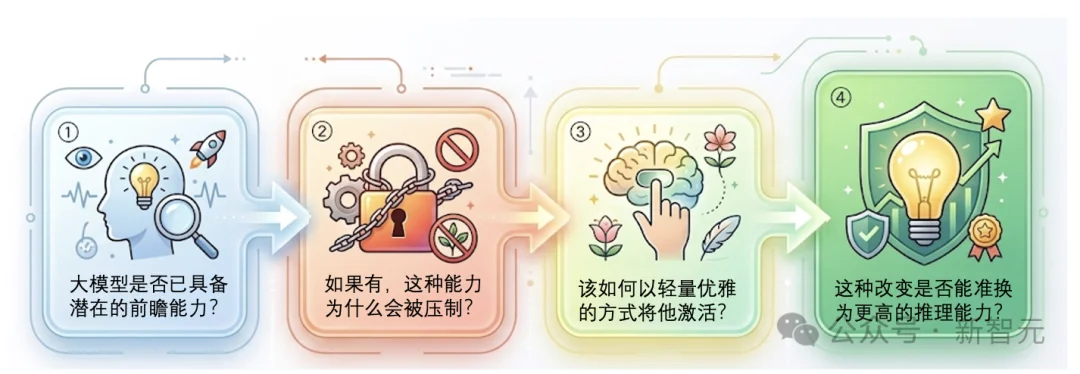
图 1:Next-ToBE的整体研究框架
这个名字本身就很有意味。它不再要求模型只盯着「下一个词」,而是同时感知「将要成为(to be)」的内容。
工作沿着清晰的链条(如图1)展开:
①大模型是否已具备潜在的前瞻能力?
②如果有,这种能力为什么被压制?
③又该如何用优雅轻量的方式将其「激活」?
④这些改变是否能够转化为更高的推理能力?
这一切背后,还有更深的问题 — 当模型不再把全部确定性押在当下,而开始为未来分配概率时,置信度与推理之间的博弈,能否重新达成一种更有利于智能涌现的平衡?
实际推理中,大模型作为一个高维概率系统,每一步输出并不是一个点,而是一整个概率分布。作者发现,这个分布早已隐含了大模型对未来若干token的预判。
为了刻画这种「前瞻性」,论文提出了一个简单而直观的指标:Future-tokens Hit Rate(FtHR)。具体来说,在当前时刻t,取模型输出分布中概率最高的L个token,观察它们是否能够覆盖未来窗口[t, t+k]中真实出现的 token。
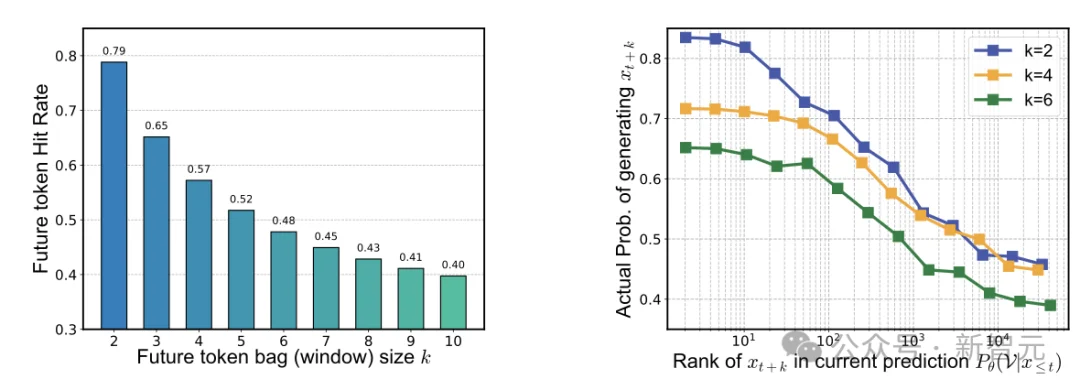
图 2:左)当前一步的输出分布也已经覆盖了相当比例的未来 token;右 )未来 token 在当前预测中的排名越高,后续被正确生成的概率越大。
实验结果(图 2)揭示了两个关键现象:
LLM的前瞻能力不仅客观存在,而且非常容易量化,并且与生成质量直接相关。
既然「看得更远」意味着「生成更准」,为什么不优化这一目标,让模型在每一步的预测中,不仅关注当前 token,也对未来若干步形成更合理的布局?
症结恰恰是NTP范式中one-hot 的目标分布:它太霸道,将全部概率质量集中在唯一token,压制了其他潜在路径。这让模型在表达上变得「非此即彼」,也使其变得短视,难以形成连续的长程规划。
当然,已有工作尝试突破这一限制。如Multi-Token Prediction(MTP)通过引入多个预测头(Medusa并行头),一次预测多步未来token。从本质上看,这类方法仍然是在并行地拟合多个one-hot分布,并没有真正改变刚性的目标分布,和「单步最优」的训练逻辑。
Next-ToBE的做法非常简单 — 它不改变模型结构,直接修改训练目标。
它将传统NTP中单一正确答案的one-hot分布,替换为一个覆盖未来窗口的软目标分布: 与其让模型把 100% 的概率都压在下一个token上,不如分出一小部分「注意力」去覆盖未来k个token,让模型在当前就开始形成对后续多步内容的感知。这正是Next Token-Bag Exploitation的核心 — 不是学习「下一个token」,而是学习「下一段token(token bag)的分布」。
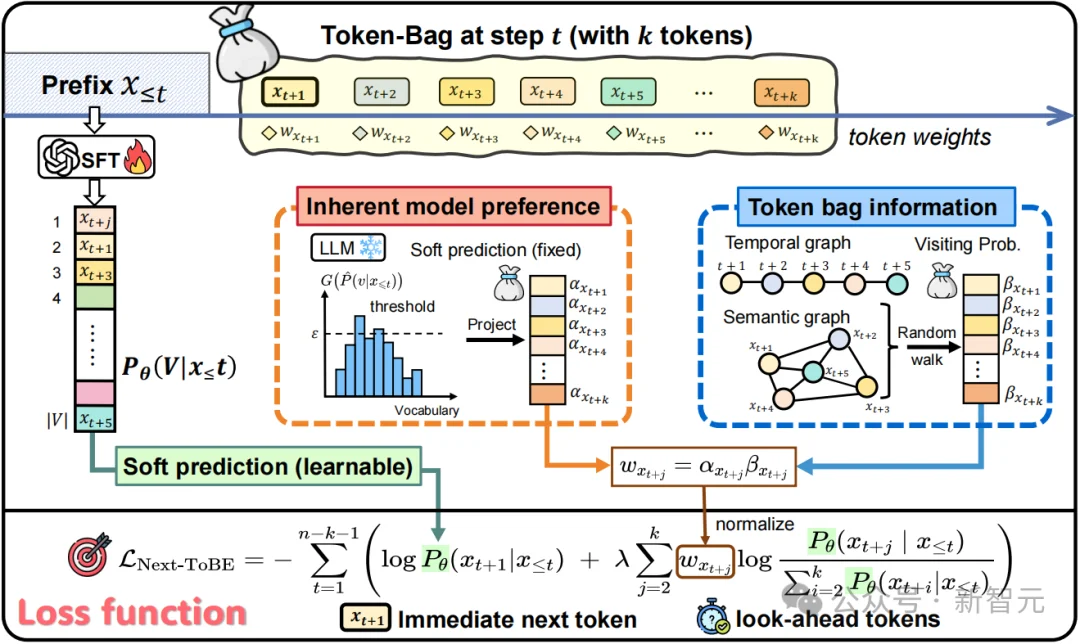
图 3:Next-ToBE 架构。损失函数由「下一 token」主项与「未来窗口 token」软目标项辅助而成;后者的权重由模型自身的前瞻偏好(α)和 token 间的时间-语义关系(β,通过随机游走得到)共同决定。
构造「未来token分布」所遵循的原则(如图 3所示):

与 Multi-Token Prediction(MTP)不同,Next-ToBE不增加预测头,不修改模型,推理仍是标准的单步自回归。如果说MTP是「给模型多长几个脑袋」,Next-ToBE 做的,则是告诉模型:「下一步最重要,但你也得留点余光看未来「—就像高手下棋,子落之处,目光已在三步之外。
作者围绕三个问题展开实验:(1)Next-ToBE 是否真的提升了模型对未来 token 的提前感知?(2)这种前瞻能力能否进一步转化为更准确的后续生成?(3)这种提升最终是否会反映到复杂推理任务上?图 4 给出了前两个问题的答案。
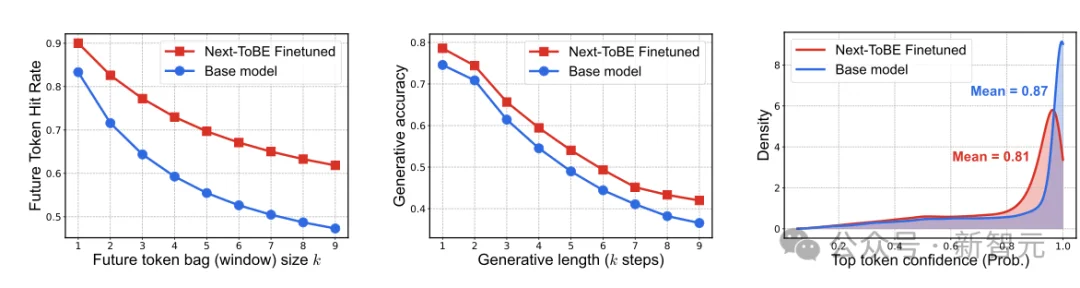
图 4:经 Next-ToBE 微调后,(a)未来 token 命中率显著提升;(b)自回归下未来 k 步生成准确率同步上升;(c)下一 token 置信度略有下降(0.87 → 0.81),即模型变得不那么「一锤定音」。
最关键的是第三个问题:前瞻能力能否落实到下游任务。为回答这一问题,作者基于三个基座模型(Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Llama3.1-8B-Instruct)和三类任务(数学推理、代码生成、常识推理)通过微调训练共开展了 36 组对比实验。实验结果显示,经过Next-ToBE微调后的模型 在 35 组实验中均取得最优结果(表1)。
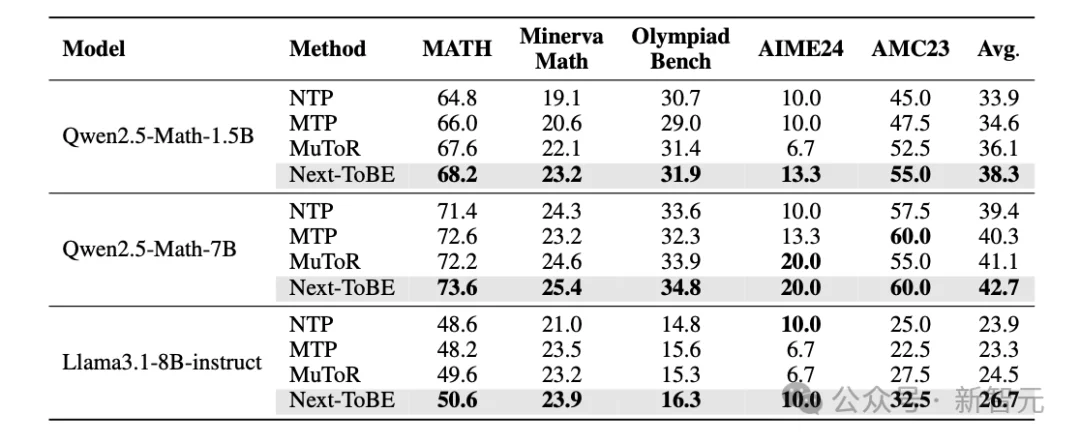
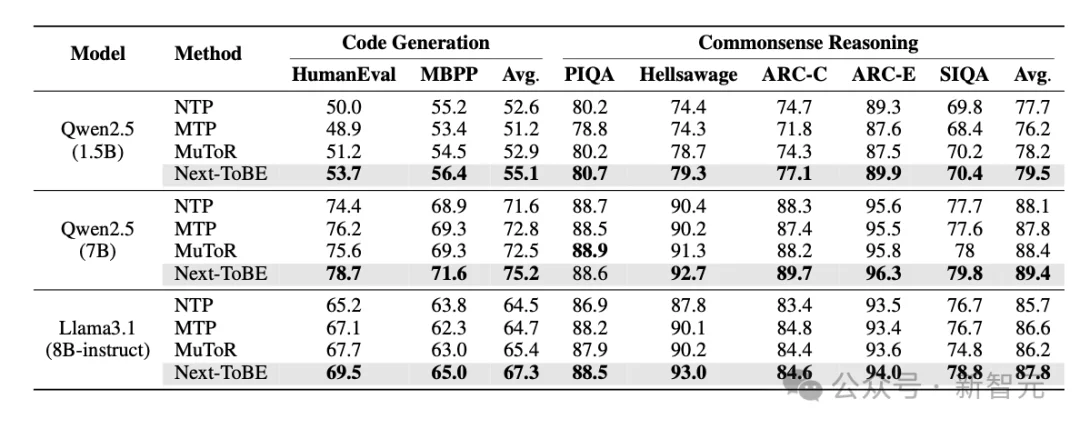
表 1:数学推理,代码生成与常识问答共36组实验中,Next-ToBE在35组中表现最优。
除此之外,Next-ToBE 在训练开销上也有明显优势,相较于MTP 类方法,显存和训练时间都有明显的降低。作者还验证了 Next-ToBE 在预训练场景下的有效性 — 这说明前瞻能力并非大模型预训练后的偶然产物,而是可以被训练目标主动「塑造」出来的。
Next-ToBE 在更大的尺度上实现了对确定性分配的系统性调节。随着超参λ增大,模型不再把全部注意力压在「下一个 token」上,而是逐渐将一小部分概率质量分配到更远的 token 上。这一变化直接带来的结果是:下一 token 的预测置信度持续下降,如图5(左)所示。
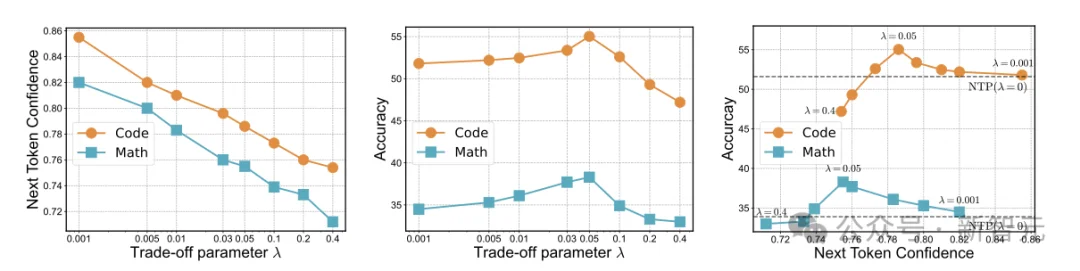
图 5:越大,下一 token 置信度越低(左);但推理准确率随,置信度呈先升后降(中、右)
然而,最有意思的地方在于,随着模型预测下一 token 的置信度下降,推理准确率反而先上升,然后下降,呈现一个漂亮的A形 (图5中、右)。换言之,模型在「适度不确定」的状态下,反而表现出更强的推理。
相比之下,传统 Next Token Prediction(NTP)可视为 的极端情形,即将全部概率质量压缩于当前一步,追求极致的局部确定性。这种「短视的自信」并未带来整体推理最优解,反而限制了对长程依赖与潜在路径的探索能力。
可见,有效的长程推理,往往来自于对确定性的克制。与其追求极致的笃定,不如为未来保留空间。Next-ToBE最聪明的地方恰恰在于用当下一点点不确定性的让渡,来换取更长远的收益。
大模型诞生至今,有一件事很少被质疑或重构:让模型在每一步,都押注于一个确定的答案。我们以为,确定性是智慧的必然。而事实上,模型从来不是只顾当下——即使披着one-hot得枷锁,它的预测里仍然藏着对更远未来的感知。
Next-ToBE只做了一件事:卸下枷锁,让大模型骨子里的前瞻性得以自由生长。
这或许也是给我们自己的启发:真正的智慧,从不是每一步都绝对正确的僵化,而是那份在流动与开放中与不确定性共舞的觉知,带我们抵达更远处的必然。
参考资料:
https://openreview.net/pdf?id=T8IJojfaOh
文章来自于"新智元",作者 "LRST"。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
