# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?
作为提升 LLM 性能的主流核心范式,持续扩充训练数据量的传统做法正面临严峻挑战(如图 1 所示)。研究表明,目前互联网上可获取的高质量数据年增长率不足 10 %,难以满足 LLM 训练数据大规模增加的需求。同时,该范式引导的 LLM 训练动辄需要数千万 GPU 小时的算力开销, 产生了巨额资源消耗与碳排放,让堆数据策略难以为继。
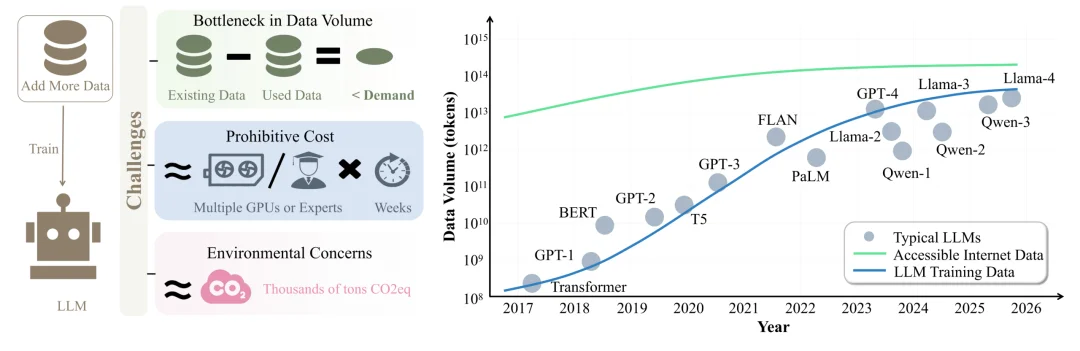
图 1:左:大模型数据扩展面临的三大挑战。右:互联网可用数据量与 LLM 训练数据量的增长趋势对比。
因而,如何在有限的数据规模下获取更多的训练收益,已经成为 LLM 训练的关键问题!
目前,研究者在该领域已展开了大量的探索,例如 s1、Less-Is-More Reasoning (LIMO) Hypothesis 和 Rho-1,但该领域仍缺乏统一的研究视角和系统的工作梳理,导致研究目标界定模糊,研究方法呈现零散化、碎片化的格局,尚未形成完备、统一的理论与方法体系。
在这一背景下,来自上海交通大学与上海人工智能实验室的研究团队发布了该领域的首篇系统性综述。该综述首次提出了 “数据价值密度”(Data Value Density,DVD)这一核心概念并给出数学定义。基于该定义,该综述建立了系统的分类框架,梳理了该领域的现有工作,为学术界和工业界绘制了一份详尽的指南。

本篇 Survey 从底层逻辑出发,首次提出了 “数据价值密度”(Data Value Density,DVD)这一核心概念,并给出了严谨的数学定义:
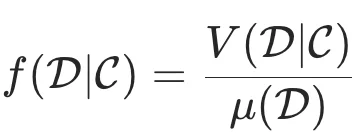
其中,D 表示 LLM 训练所使用的数据集,C 表示评估数据价值所必须的上下文信息,例如当前 LLM 能力分布、目标任务特征等。
V (D∣C) 衡量数据集 D 在训练上下文 C 下对模型性能提升的总贡献价值,而 μ(D) 衡量数据集 D 的规模。该领域研究的目标,就是构建一个新数据集,使其价值密度大于原数据集(Δf>0)。
基于这一核心概念,作者系统性地梳理了现有文献,作出了四大核心贡献:
基于 DVD 的数学定义中分子 V (D∣C) 与分母 μ(D) 的动态变化关系,作者将数据价值密度增强领域划分为五大类别(如图 2 所示):
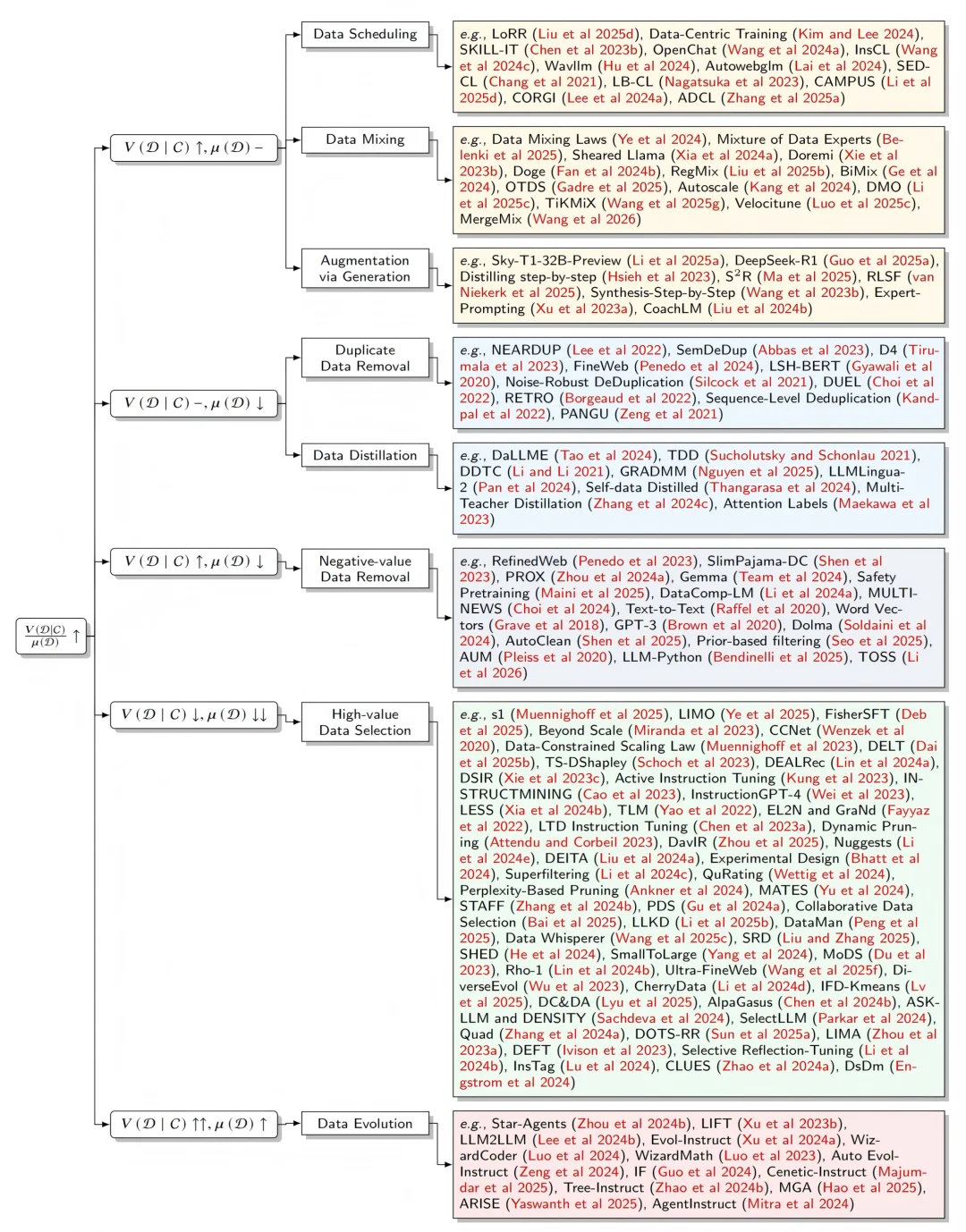
图 2:DVD 增强方法分类框架
为了更好地理解各类 DVD 增强策略,作者用一张清晰的示意图进行形象化的展示,示意了不同类型的 DVD 增强策略实施前后数据集内部发生的变化(如图 3 所示)。
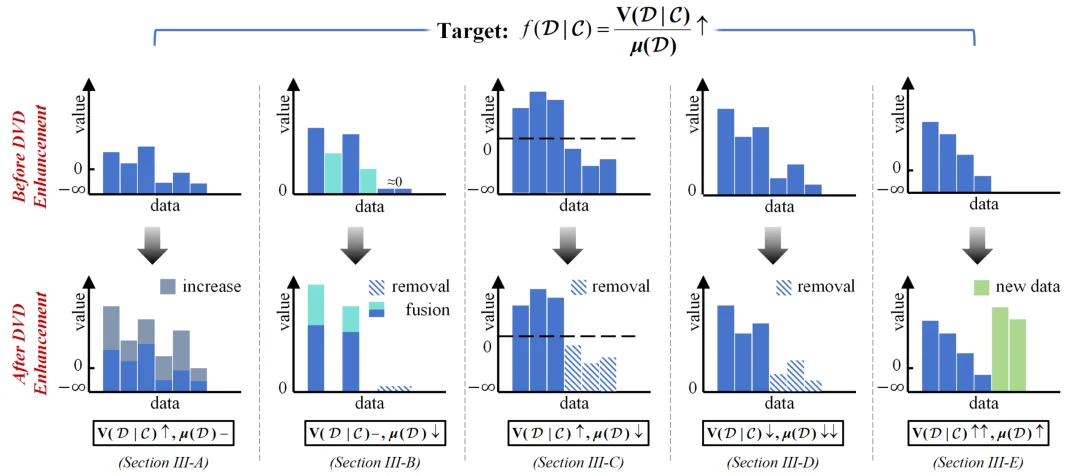
图 3:五类 DVD 增强策略的实现原理
除去方法论相关介绍,本篇 Survey 同时整理了 DVD 增强研究中高频使用的数据集,并根据任务特性将其分为三大板块(如表 1 所示):
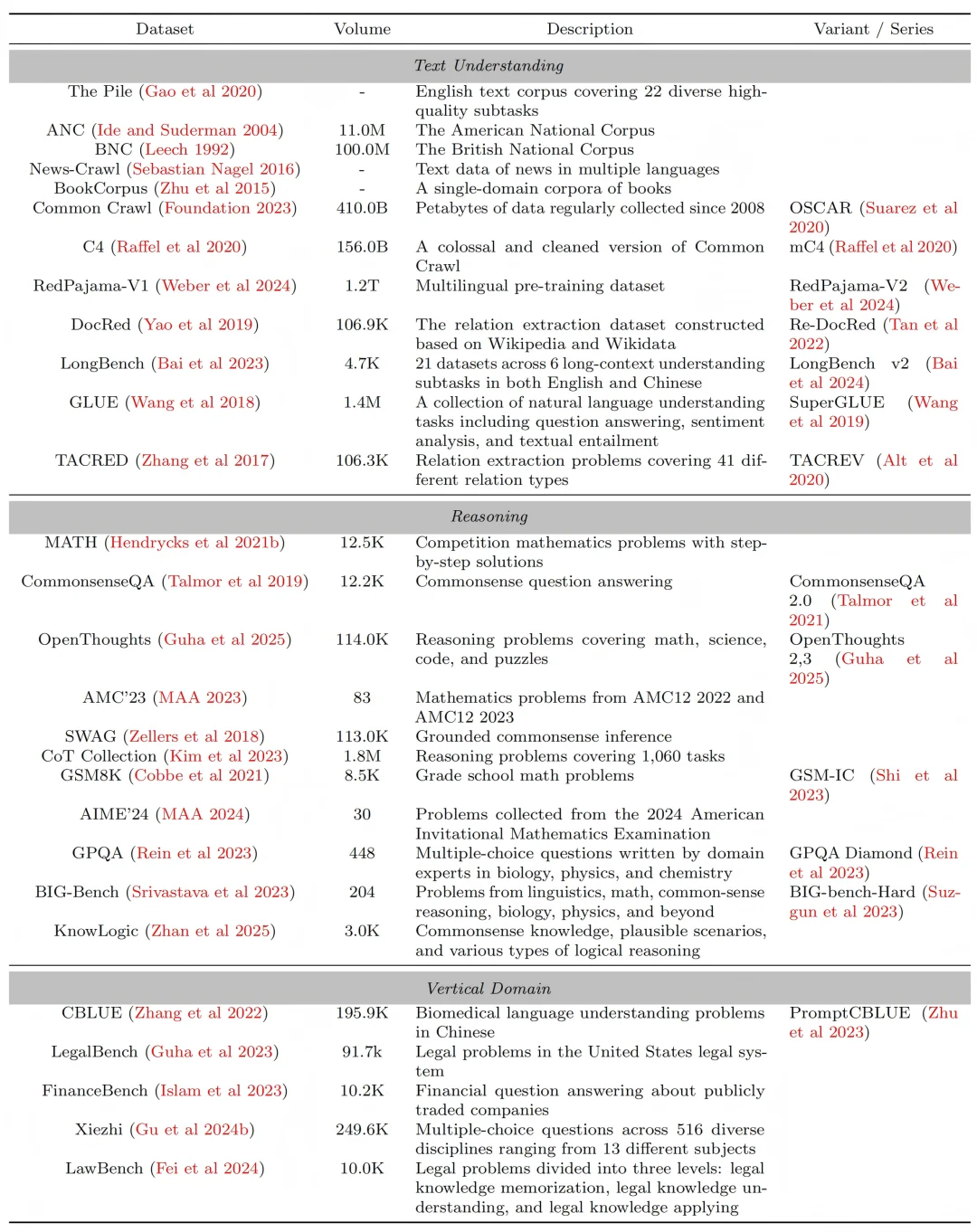
表 1:DVD 增强领域的主流数据集
同时,文章还将 DVD 增强与当前火热的上下文学习(In-Context Learning)、能力密度(Capacity Density)、样本效率(Sample Efficiency)和主动学习(Active Learning)进行了深度对比,打通了不同研究范式之间的底层逻辑。
尽管 DVD 增强技术已经取得了一定的成果,本文指出了 DVD 增强当前面临的四大挑战(如图 4 所示):
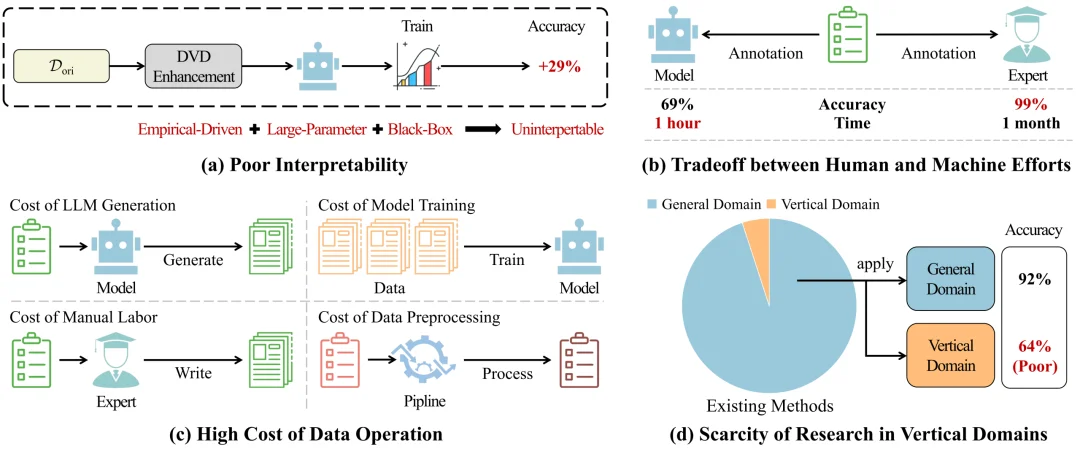
图 4:DVD 增强面临的四大挑战
本篇 Survey 从首创的 DVD 视角出发,系统地梳理了大模型训练数据价值密度增强领域的完整路线图。这一领域的研究有助于解决当下 LLM 训练数据枯竭与算力开销大等问题。
期待这篇 Survey 能为社区提供一份实用的参考指南,帮助研究者快速把握数据价值密度增强的底层逻辑,推动大模型训练模式从粗放式数据消耗向精准化知识萃取的根本性跨越。
文章来自于"机器之心",作者 "孙亦刘、陆彦超与曹家熙"。



