# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
胸片AI进入了一个新阶段:不再只给诊断,开始给推理。
过去的医学影像AI更像“分类器”,擅长回答有没有病、像不像某种病。
但真实临床需要的是一条能被医生复核的推理路径。
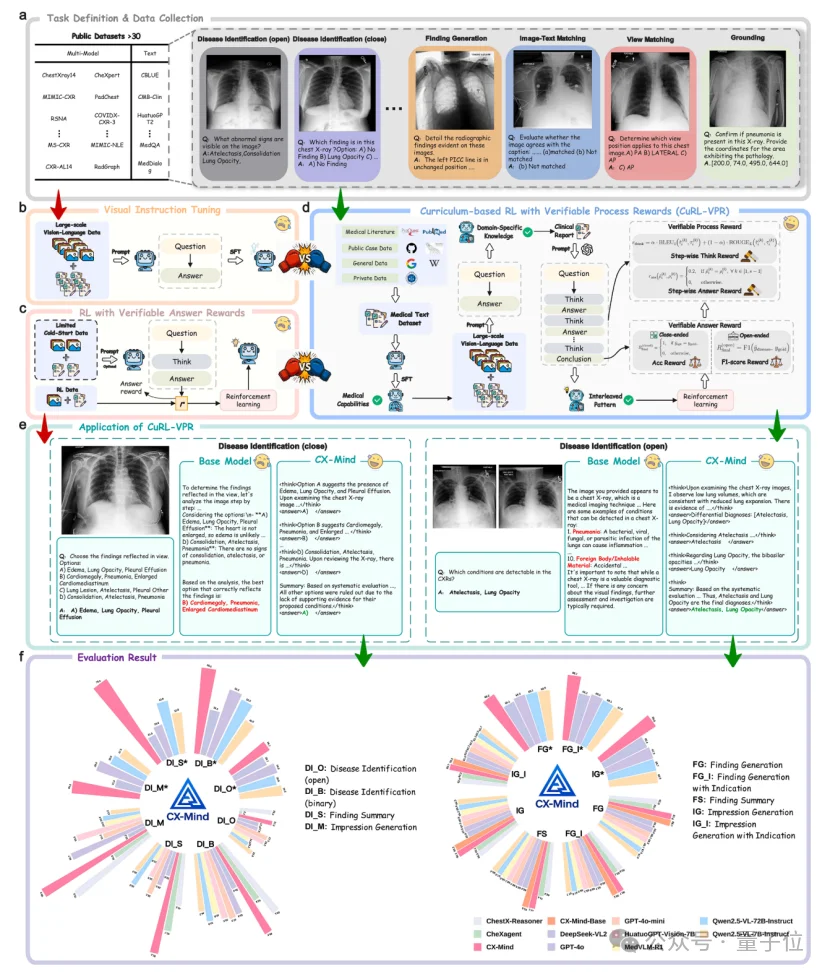
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——
从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。

在横跨23个数据集、708,473张影像的评测中,它在视觉理解、报告生成和时空对齐三大能力域平均提升25.1%。
而在真实世界测试集Rui-CXR上,多中心医生主观评估五项维度全部排名第一。
胸部X光是临床最常用的影像检查之一,也是医学多模态大模型最重要的真实场景。
它的难点并不止于识别某个病灶,而在于把影像观察、病灶定位、共病判断、报告生成、历史比较和临床语义整合到同一个诊断链条中。
这也是过去很多胸片AI难以真正进入临床核心工作流的原因。
模型可以给出一个看似准确的标签,但医生仍然会追问:
依据是什么?排除了哪些可能?结论是否与报告 findings 一致?如果模型错了,错误发生在观察、鉴别还是总结阶段?
CX-Mind试图解决的,正是这个更深层的问题。
它不是把思维链写得更长,也不是让模型生成一段听起来合理的解释,而是把医学推理拆成可解析的think-answer交错单元:
每一步先围绕影像证据进行观察和推断,再输出阶段性答案,随后继续完成鉴别、定位、报告生成或病程判断。
换句话说,CX-Mind把医学影像大模型的目标从“给出答案”推进为“给出可审查的答案形成过程”。
这使模型不再只是一个黑箱阅片工具,而更接近医生可以协作、追问和复核的临床推理伙伴。
传统医学视觉模型大多遵循one-shot judgment路线:输入影像,输出标签、选项或报告。
即便引入CoT,也常常变成一整段难以验证的长文本。
这样的解释看似完整,却很难判断哪些中间步骤真正来自影像,哪些只是语言模型生成的“医学叙事”。
CX-Mind的关键设计是interleaved reasoning。
在封闭式问题中,它逐项评估候选答案,给出保留或排除的证据;在开放式问题中,它先提出可能疾病,再围绕每一种疾病进行证据核验,最后形成诊断结论。
这种输出方式更接近真实阅片:先观察征象,再形成假设,再进行鉴别,最后写出结论。
这项工作的突破性不在于“让模型解释自己”,而在于让解释成为训练和奖励的一部分。
可解释性不再是事后附加的说明,而是模型学习诊断能力时必须满足的结构约束。
要训练一个真正面向胸片诊断的大模型,仅靠疾病标签远远不够。
CX-Mind团队构建了大规模胸片指令数据集CX-Set——
整合23个胸片相关公开数据集,形成708,473张影像与2,619,148条指令样本,并进一步构建42,828条由真实放射学报告监督的高质量交错式推理样本。
CX-Set的设计遵循一个清晰问题:一个胸片专家到底需要哪些能力?
论文将其拆解为三大能力域:
Visual Understanding用于疾病识别、单病判断和多病共存诊断;
Text Generation用于findings、impression和summary;
Spatiotemporal Alignment用于影像-文本匹配、体位识别、疾病进展判断和病灶定位。
因此,CX-Mind学到的不只是“某个标签是否存在”,而是一套完整的胸片诊断工作流:看图、定位、比较、鉴别、总结、生成报告。
这也是它相较于单点分类模型更具基础模型价值的原因。
医学诊断任务的强化学习难度远高于一般选择题。
开放式答案空间复杂,疾病可能共存,医学表达存在多种等价写法;更重要的是,最终答案正确并不代表中间推理可靠。
只奖励final answer,容易造成奖励稀疏、credit assignment困难和医学幻觉。
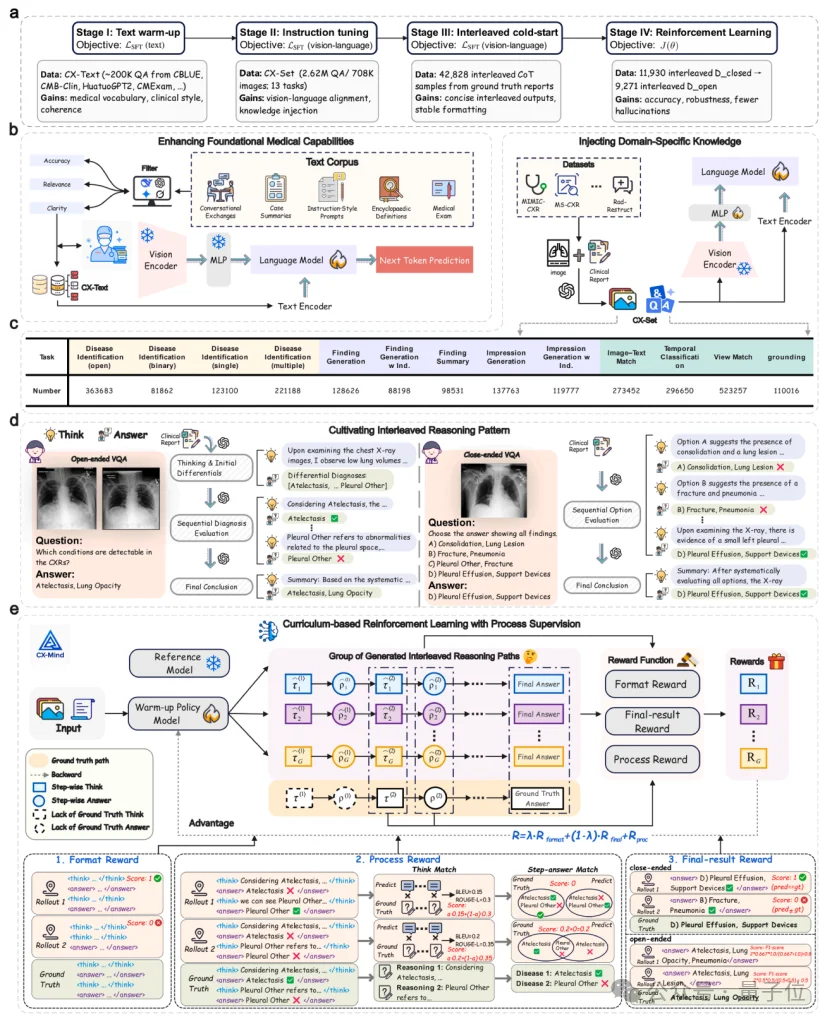
CX-Mind提出CuRL-VPR,即curriculum-based reinforcement learning with verifiable process rewards。
它的意思是,先从简单题练起,逐步加难;训练时不只看最终答案对不对,还用真实放射科报告来核查每一步推理是否有影像证据支撑。
整个训练流程包括医学文本warm-up、大规模胸片指令微调、交错式推理cold-start,以及基于GRPO的课程强化学习。
在奖励机制上,CX-Mind同时使用format reward(格式奖励)、final-result reward(最终结果奖励)和process reward(过程奖励)。
模型不仅需要输出格式正确、最终答案正确,还需要让中间think-answer步骤与真实放射学报告中的证据保持一致。
这意味着强化学习不再只盯着终点,而是开始关注路径质量。
对于医学场景而言,这一点极其关键:一个来自错误证据的正确结论仍然不可接受,一段没有报告证据支撑的解释仍然可能是幻觉。
同时,CX-Mind采用closed-to-open课程学习策略:先在二分类和选择题等封闭式任务上建立稳定可验证奖励,再迁移到开放式诊断任务。
这种训练节奏更符合临床任务难度梯度,也让开放式医学推理的RL过程更稳定。
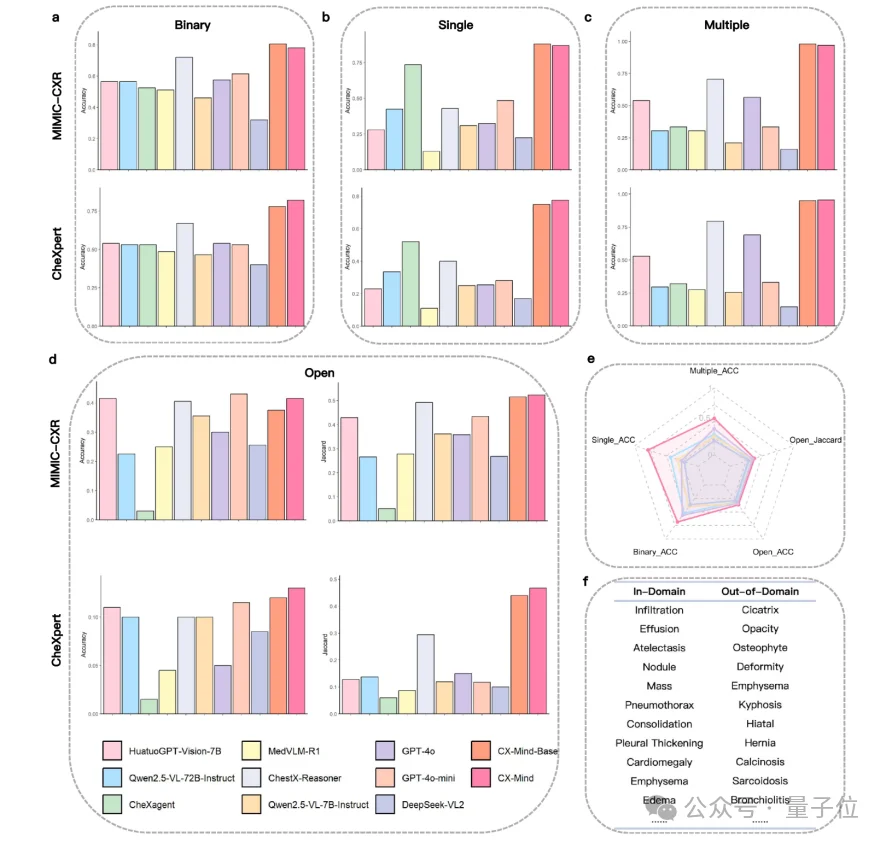
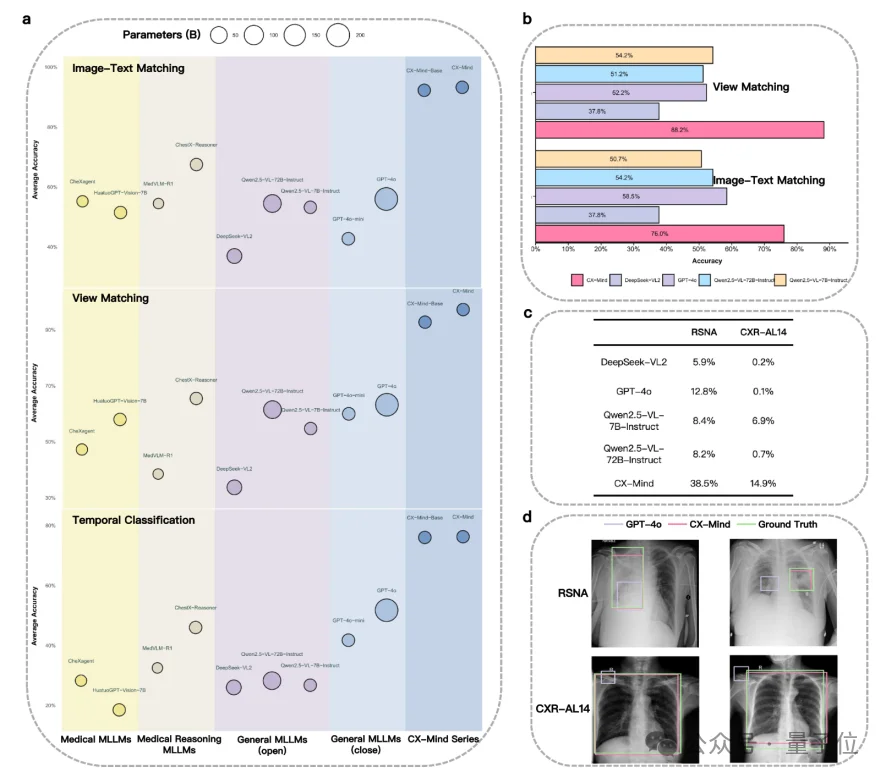
CX-Mind在二分类、单疾病识别、多疾病共存识别和开放式疾病识别中整体领先。
论文显示,相比胸片专用模型,CX-Mind在三大能力域上取得25.1%平均性能提升。
在更接近真实临床的复杂任务中,这一优势更加明显。
单疾病识别任务中,CX-Mind相比CheXagent和ChestX-Reasoner平均提升19.5%和21.0%;在多病共存诊断中,相应提升达到63.5%和21.2%。
这说明interleaved reasoning的价值不只是改善简单分类,而是在多异常、多证据、多候选诊断同时存在时,帮助模型更稳定地完成临床鉴别。
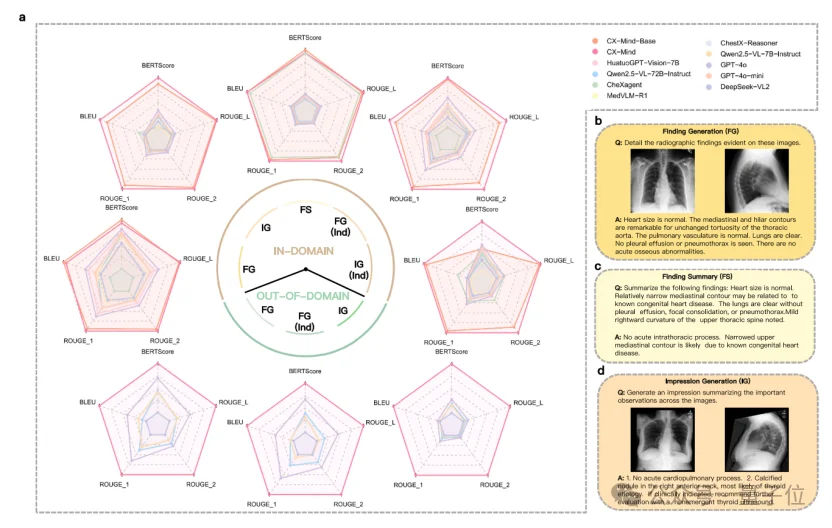
临床可用的胸片AI不能只给标签,还需要把影像发现转化为规范、清晰、可修改的医学语言。
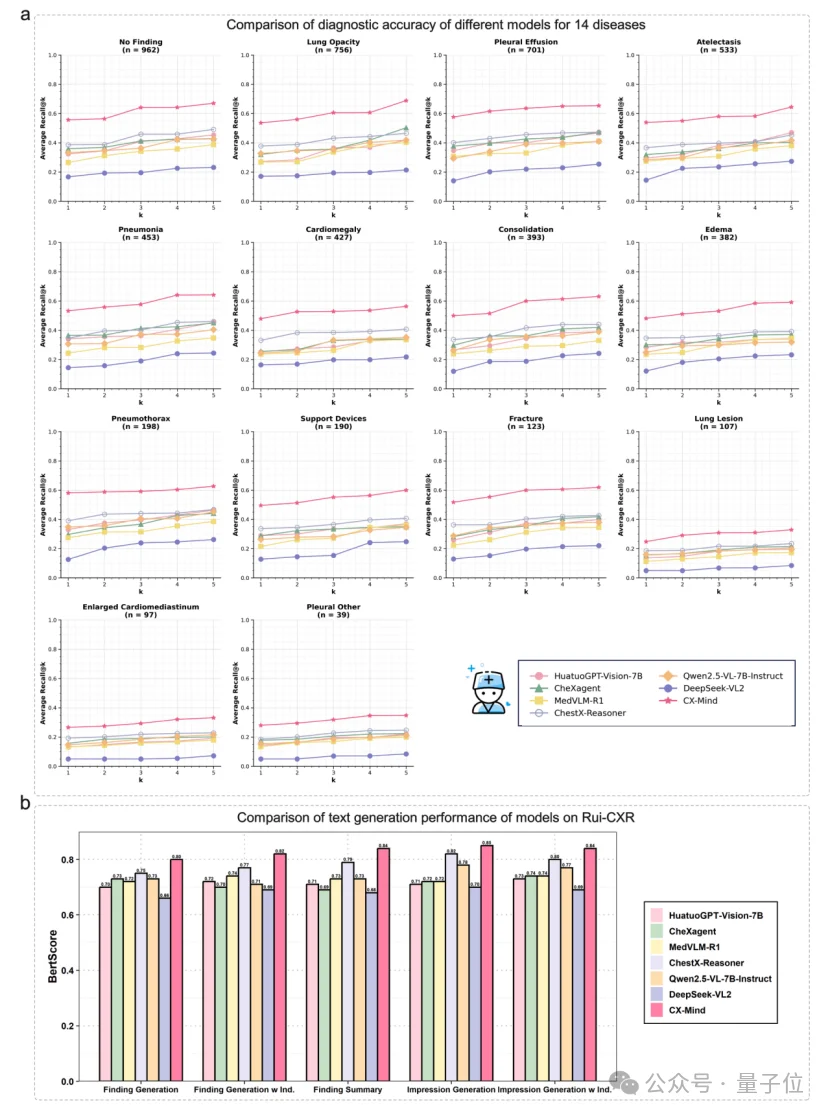
CX-Mind在findings generation、impression generation和findings summarization等任务中取得SOTA表现。
与GPT-4o相比,CX-Mind在Finding Generation任务中BERTScore高1.6%、BLEU高7.6%、ROUGE平均高11.1%。
在带indication的Finding Generation中,BERTScore、BLEU 和 ROUGE 平均分别高出3.6%、21.7%和22%。
在Impression Generation与Impression Generation with Indication中,CX-Mind分别达到90.3%和80.7%的BERTScore。
这意味着CX-Mind不只是“看图更准”,还能够把影像证据转写为与金标准报告语义一致的专业表达,为报告草拟、质控、教学和交互式问答提供基础能力。
真实胸片诊断往往涉及纵向比较和跨模态对齐。
医生需要判断同一患者不同时间点的病变进展,也需要确认报告描述、拍摄体位和病灶位置是否一致。
CX-Mind因此把Spatiotemporal Alignment作为核心能力之一。
在image-text matching和disease progression任务中,CX-Mind分别比最佳基线平均提升25.8%和30.2%。
在 OpenI外部测试集上,影像-文本匹配和体位识别分别达到76%和88.3%。
在 RSNA与CXR-AL14外部定位数据集上,CX-Mind的mean IoU分别达到38.5%和14.9%。
这部分能力指向更大的临床空间:随访比较、病程追踪、多模态病历整合,以及未来影像Agent对患者纵向状态的理解。
医学 AI 的影响力最终必须通过真实世界检验。
论文进一步构建Rui-CXR真实世界测试集,原始数据来自上海交通大学医学院附属瑞金医院骨科2018-2023年采集的80,648名患者标准PA位胸片及报告。
经过脱敏、筛选和一致性验证后,形成4,031张高质量胸片测试集,覆盖14种常见胸部疾病。
在Rui-CXR上,CX-Mind在 14 种疾病诊断中保持领先,mean recall@1明显超过第二名模型。
在真实世界报告生成中,标准Finding Generation的BERTScore达到0.80,带indication的版本达到0.82,较第二名模型平均提升约5%。
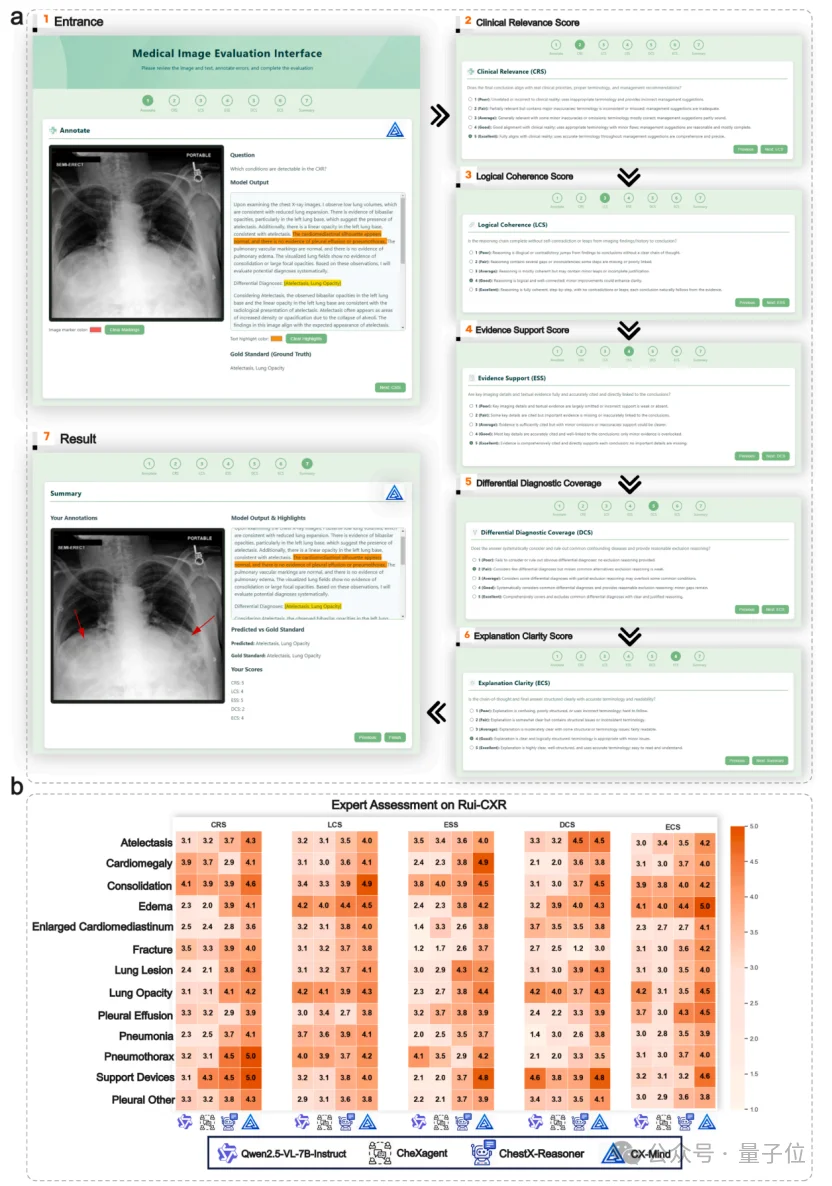
更关键的是,团队还邀请多中心、不同资历层级的临床医生进行主观评估,评价维度包括Clinical Relevance、Logical Coherence、Evidence Support、Differential Diagnostic Coverage、Explanation Clarity。
CX-Mind在五个维度上均获得最高平均分。
这说明CX-Mind的优势不只是自动化指标,而是医生能否读懂、信任和复核模型输出。
对于医疗场景而言,可审查性本身就是临床价值的一部分。
如果把CX-Mind放在医学AI的更大图景中,它的意义在于推动了一个关键转向:
从“医学视觉模型”走向“医学推理模型”,再走向“可被医生协作审查的医学智能体”。
这一思路有望迁移到更多医学场景。
例如,胸部CT多癌种筛查需要模型在3D影像中分层定位病灶、结合报告和病史进行鉴别;MRI需要跨序列整合;
病理需要高分辨率区域级证据;
全流程临床Agent更需要在入院评估、检查解释、治疗建议和随访管理之间保持连续推理。
当然,临床部署仍需要前瞻性研究、跨医院泛化验证、医生工作流集成、错误边界评估和监管审查。
但从研究范式看,CX-Mind已经给出了一个清晰信号:
下一代医学AI的核心竞争力,不仅是“看得准”,而是“推理得清楚、证据可复核、过程可协作”。
论文共同第一作者为李文杰、张钰杰、孙浩然。
李文杰为上海创智学院、上海交通大学、上海交通大学医学院附属瑞金医院联合培养在读博士生,主要研究方向为Visual Reasoning、Multimodal Large Language Models与 Medical AI Agents。
张钰杰为上海创智学院、复旦大学联合培养博士生,主要研究方向为Vision-Language Model Reasoning、Reinforcement Learning与Large Language Models。
孙浩然为复旦大学直博二年级博士生,主要研究方向为Medical Multimodal Large Models, Self-Evolving Memory, AI4Science Experimental Automation。
论文DOI:https://doi.org/10.1016/j.inffus.2025.104027
GitHub(团队更新版):https://github.com/SII-WenjieLisjtu/CX-Mind
HuggingFace:https://huggingface.co/SII-JasperLi77/CX-Mind
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
