# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
但在实际训练中,这两种信号却难以有效融合,现有工作大多仅停留在 “把两个loss混在一起” 的层面。

为应对这一挑战,研究团队提出了DYPO(Dynamic Policy Optimization)动态策略优化方法。
核心思考在于:既然 SFT 和 RL 的学习信号统计性质天然不同,统一优化要如何做,才能既保留监督学习的稳定性,又不牺牲强化学习的探索能力?
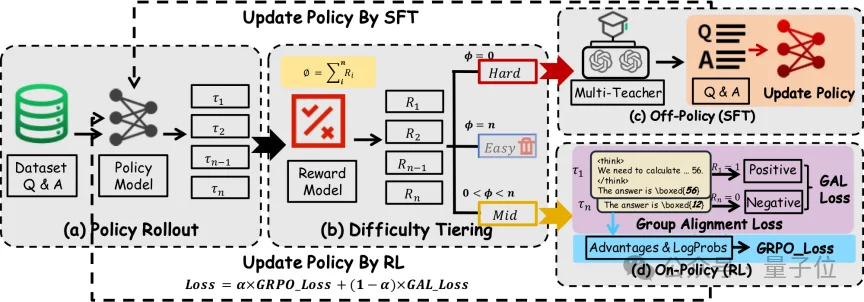
△ 图1:DYPO的整体框架
如图1,模型会先根据一组rollout的结果判断样本所处的学习阶段,再决定它应该走监督路径、强化学习路径,还是暂时跳过。
如果把大模型后训练比作“教学生做题”,SFT 和 RL 的特性差异便一目了然。
SFT更像老师直接讲标准答案。它的优点是学得快、过程稳、收敛也更容易控制,但问题在于,学生很容易学成“会按套路做题”,一旦题目稍微变形,就可能缺乏泛化能力。
RL更像让学生自己反复尝试,再根据得分不断修正策略。它的优点是更有探索性,更可能逼着模型从“记住解法”走向“学会推理”,但缺点同样明显:训练过程中波动更大,奖励一旦稀疏,模型就很容易学偏,甚至不稳定。
从理论层面看,这背后对应着典型的偏差—方差矛盾:
问题也正出在这里。很多统一训练方法虽然同时用了SFT和RL,但默认所有样本都值得用同一种方式去处理。
但实际情况中,不同样本的学习信号存在显著差异:有些问题模型已经会了,多次rollout都能答对,这类样本继续训练,收益往往很有限;有些问题模型当前完全不会,多次rollout全部失败,这时直接做RL通常也拿不到什么有效奖励;
真正最值得优化的,反而是那些“已经会一点,但还不稳定”的样本。它们既说明模型已经摸到了门槛,又保留了区分正确轨迹和错误轨迹的空间。
因此,这项工作想解决的,并不是“要不要把SFT和RL放在一起”,而是更进一步:不同学习阶段的样本,到底应该怎样被优化,才能在稳定和探索之间找到更合理的平衡。
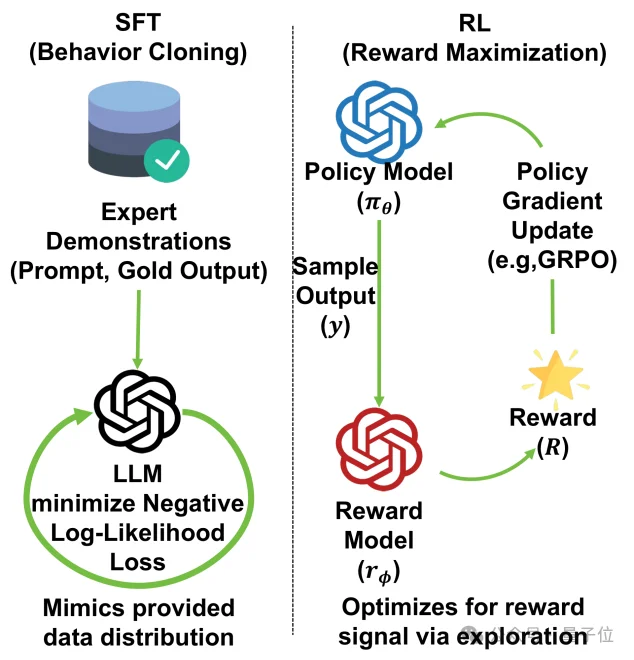
△ 图2:SFT与RL的偏差—方差矛盾
SFT更稳,但偏差更大;RL偏差更低,但训练波动明显更强。
基于上述思考,本文提出了Dynamic Policy Optimization(DYPO)。它的核心思想并不是再堆一个更复杂的训练流程,而是先根据rollout结果判断样本所处的学习阶段,再去匹配最合适的优化路径。
具体而言,DYPO 会让当前策略为每个问题生成一组rollout,然后根据这些rollout的成败情况,把样本划分成三类:
GAL的核心思路是利用同一组rollout中的成败轨迹差异,显式将模型拉向正确轨迹、推离错误轨迹。这让RL更新不再仅依赖高噪声奖励信号,而是额外获得了一层更稳定的相对对齐约束。
换句话说,GAL的作用并不是简单“再加一个loss”,而是在RL更新过程中充当一个动态的方差抑制项。
如果从理论上总结DYPO的设计逻辑,它其实是在分别处理SFT和RL的两个核心缺陷:
由此可见,DYPO并不是简单把SFT和RL拼起来,而是在结构上把“高偏差监督”和“高方差强化学习”分别放到最适合的样本上处理。也正因为如此,它更像是一种重新组织后训练过程的方式,而不仅仅是一个新的训练技巧。
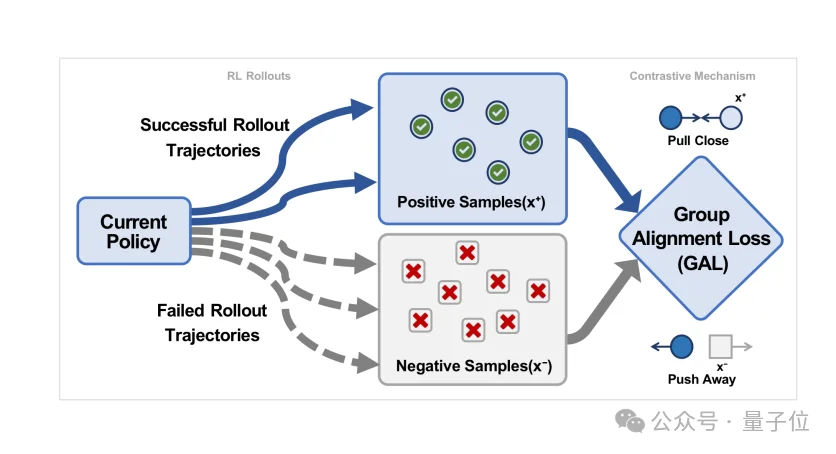
△ 图3:GAL的直观机制
如图3,它利用同一组rollout中已经出现的正负样本,把模型往正确轨迹方向拉近,同时把错误轨迹往外推开。
研究团队在数学和逻辑推理场景开展实验,基础模型包括Qwen2.5-Math-7B和Qwen3-4B-Base,评测任务覆盖AIME 2024/2025、AMC、MATH-500、Minerva,以及更偏分布外泛化的ARC-c和GPQA-Diamond。
对这类工作来说,分数当然重要,但如果只看最终结果,很容易把DYPO理解成“又一个做得更高的训练技巧”。真正值得看的,其实是它到底赢在什么地方。
在Qwen2.5-Math-7B上,和传统SFT→RL顺序pipeline相比,DYPO:
这一提升并非依赖单一任务冲高,而是整体表现更稳定。尤其是在GPQA-Diamond这种更看重迁移推理能力的任务上,DYPO取得了表中最好的结果,这说明它学到的并不只是更贴近训练分布的模板。
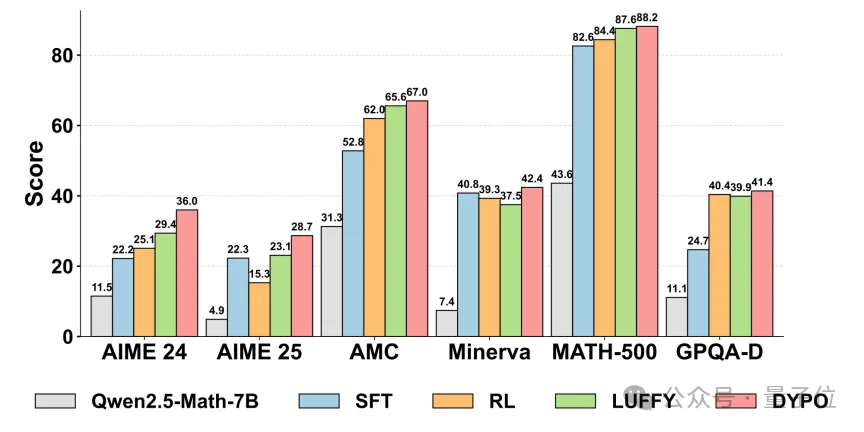
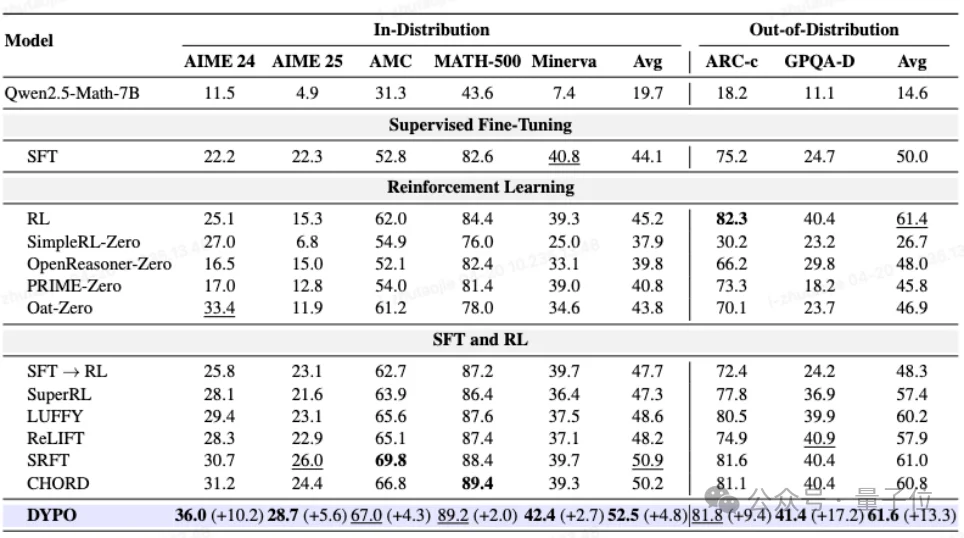
△ 图4:Qwen2.5-Math-7B上的整体结果对比
如图显示,DYPO在复杂推理和分布外任务上都表现出较强的综合优势。
在Qwen3-4B-Base上,类似的趋势依然存在。DYPO:
这说明它的收益并不只依赖某一个特定backbone,而更像来自这套动态分流机制本身。
此外,消融实验进一步验证了方法有效性。
很多时候,一个方法看起来更强,未必是因为方法本身,也可能只是teacher更强、数据更好。
但在这项工作里,即便把第二个teacher换成比原教师deepseek-R1更弱的Qwen3-8B模型,DYPO依然能把AIME 25从22.0提升到27.8,把GPQA-Diamond从30.8提升到39.4。
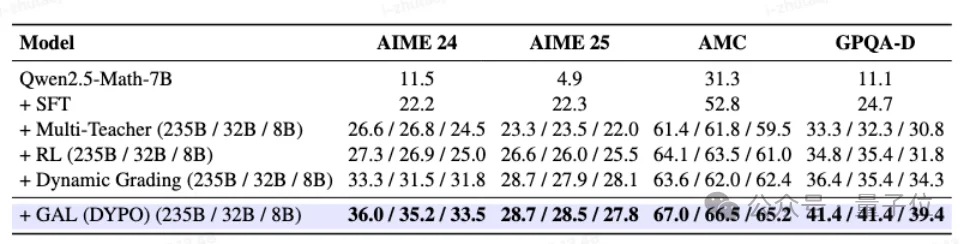
这意味着它的提升并不只是来自“多喂了一些更强teacher的数据”,而是后面这套动态路由与低方差优化本身确实发挥了作用。
除了最终结果,研究还验证了 DYPO 的训练稳定性。
作者分析了训练过程中离线数据占比、reward和策略熵的变化。
一个很有意思的现象是,DYPO并不是一上来就把模型推向更强的探索,而是随着能力提升,逐步降低对监督信号的依赖,让训练自然从“更靠teacher扶着走”过渡到“更依赖策略自己探索”。
这个过程有点像一种自适应课程学习:先把基础稳住,再把探索空间慢慢放出来。
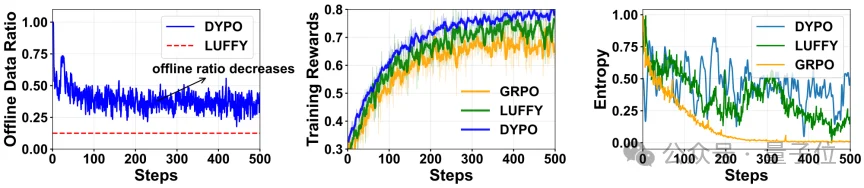
如图,随着训练推进,DYPO会逐步减少对离线监督的依赖,同时保持相对健康的策略多样性。
再看梯度范数。
标准GRPO的梯度曲线会有比较明显的剧烈震荡,而DYPO的曲线要平滑得多。这种差异看起来像是训练细节,但背后对应的其实是一个很实际的问题:如果梯度一直在大幅摆动,训练就更容易发散,也更难把学习率和优化策略设得积极。
DYPO在这里表现出的稳定性,正好说明它对RL那部分高方差更新做了有效约束。
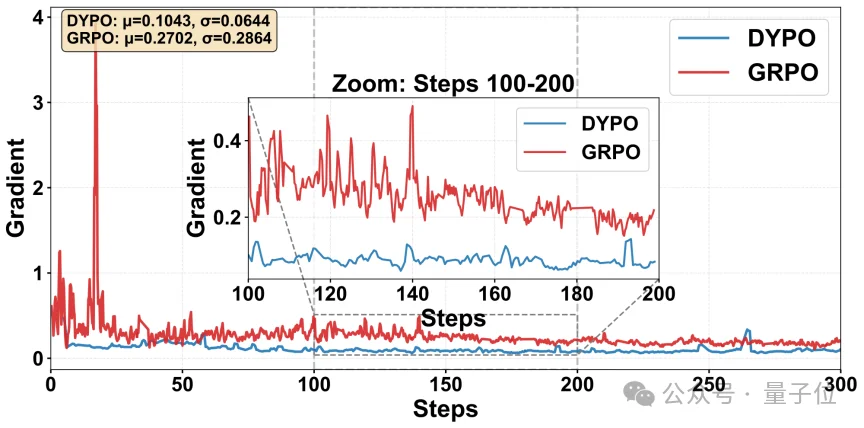
△ 图6:梯度范数对比
如图6, 和标准GRPO相比,DYPO的更新轨迹更平滑,也更容易保持可控。
DYPO不是在证明SFT和RL可以一起用,而是在回答它们到底应该怎样一起用。它提供的,是一种更像“训练组织方式”的思路。
过往研究已意识到,单纯依赖监督或者单纯依赖强化学习,都不足以把大模型推理能力往前再推一大步。但核心难点并非设计目标函数,而是不同阶段、不同样本暴露出来的学习信号本身就不一样。
DYPO的核心贡献,是将优化逻辑前移:先判断样本学习阶段,再匹配优化路径。这样一来,SFT负责把模型扶稳,RL负责让模型继续往外探索,而非无差别地混合两种信号。
当然,这项工作也有其实验边界。
目前主要验证的是数学与逻辑推理场景,对开放式对话、创作类任务是否同样有效,还需要进一步观察;同时,为了稳定估计样本难度,训练时每个prompt需要生成8条rollout,这也意味着额外算力开销。
对于大模型推理能力增强来说,这也许不是终点,但DYPO无疑提供了一个值得持续推进的新方向。
Arxiv Link: https://arxiv.org/pdf/2604.08926
Github Link: https://github.com/Tocci-Zhu/DYPO
文章来自于"量子位",作者 "清华大学深圳国际研究生院&中兴通讯&重庆邮电大学"。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
