# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。这意味着,“训练数据如何被选择” 正在从工程细节走向核心算法问题。
作者来自华为 GTS 研发部 AI 数据团队,长期聚焦领域大模型数据、训练与评测方法。面向通信等专业场景,他们关注的不是 “再堆多少数据”,而是一个更实际的问题:当高质量领域数据稀缺且昂贵时,模型每一步究竟应该先学哪些样本?
训练一个领域大模型,有时像准备一场高强度考试:题库很贵,时间有限,但你并不知道下一道题究竟是在查漏补缺,还是在浪费训练预算。
在通信、医疗、法律等垂直领域,高质量数据通常稀缺且昂贵。传统微调要么随机采样,要么在训练前按照长度、困惑度等指标排好一个固定课程。但模型能力会不断变化:昨天不会的题,今天可能已经掌握;看似基础的样本,也可能仍然卡在某个专业知识点上。
于是问题来了:能不能让模型每一步都学当前最该学的数据?
华为 GTS 研发部 AI 数据团队通过长期在领域大模型的训练实践提出 EDCO(Entropy-based Dynamic Curriculum Orchestration),用推理熵动态编排训练课程,让模型持续面对当前最困惑、最有学习价值的样本。该工作已被 ICML 2026 接收。

静态课程学习像一张训练前写好的课表:先学什么、后学什么,一旦确定就不再改变。这在从零学习时很自然,但领域大模型微调不是从小学数学开始,而是在已有通用能力上补专业短板。
尤其在通信这样的专业领域中,“简单” 和 “有用” 并不总是一回事。无线网络优化任务往往不是看一条告警或一个指标就能下结论,而是要把路测轨迹、信令流程、参数配置、话统指标和专家规则放在一起分析:同样是掉线率升高,背后可能是覆盖问题、切换参数不合理、邻区配置缺失,也可能是容量受限或终端行为异常。
数通场景同样如此。真实运维输入通常来自多厂商、多设备、多协议的非结构化日志,文本长、术语密集、格式不统一。模型不仅要读懂日志,还要结合网络拓扑、路由关系和协议机制进行判断、计算与综合分析。这意味着,通信任务中的样本难度并不由文本长度或表面形式决定。“同症不同因”“短问长推理”“长文本找关键异常值” 在这里非常普遍:
按困惑度(PPL)、长度这些预先算好的静态指标甚至在部分场景中不如随机选择,本质因为模型的能力边界一直变化。模型已经把 "该学的" 刷完了,剩下的训练预算都耗在它早就掌握的题上。
EDCO 的核心判断很直接:样本价值不是固定属性,而取决于模型当下是否仍然不确定。推理熵越高,说明模型面对该样本越犹豫,也越可能处在能力边界附近。
从这个角度看,EDCO 实际上把传统 “从易到难” 的课程,改造成一种更适合领域大模型微调的动态反向课程:不是一味先喂简单题,而是在每个训练阶段主动寻找仍能激发探索、避免模型过早自信的样本。
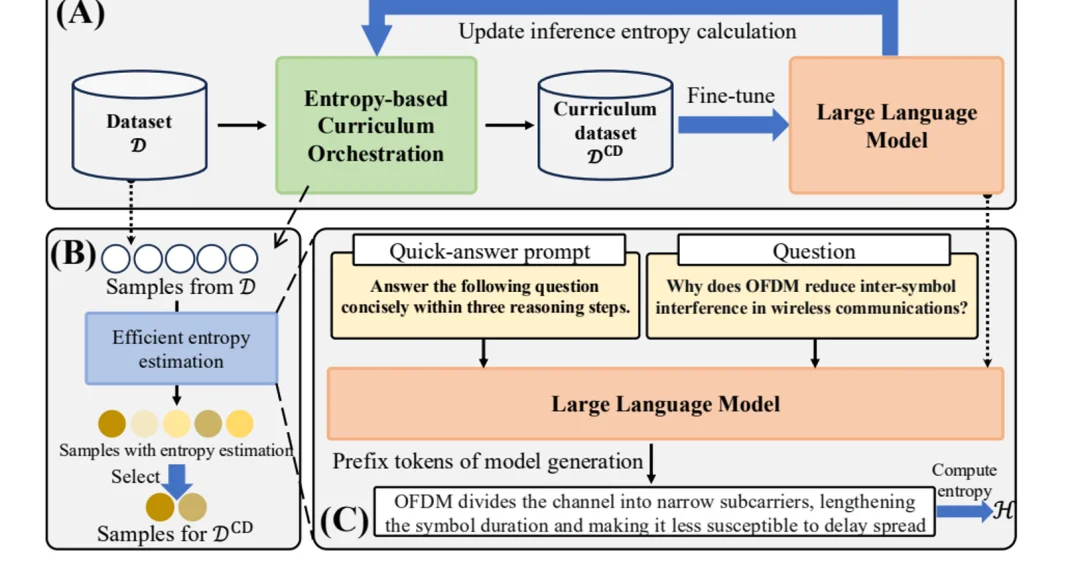
图 1:EDCO 整体框架:推理熵估计、动态课程生成与 LLM 训练闭环。
EDCO 的训练闭环由三部分组成:首先估计训练池中样本对当前模型的推理熵;随后选择推理熵最高的一批样本组成下一阶段课程;最后用该课程继续微调模型,并在下一个间隔重新计算熵值、更新样本集合。
1. 用推理熵衡量样本挑战性
EDCO 对训练池样本估计当前模型的推理熵。高熵样本不是简单意义上的 “难题”,而是当前模型仍然拿不准、可能带来更强学习信号的样本。
这种定义的好处在于,样本是否重要不再由训练前的静态难度决定,而是由模型实时状态决定。模型已经掌握的样本会逐渐退出课程,仍然让模型犹豫的样本则会被保留下来继续训练。
2. 用前缀熵估计把动态课程做轻
完整序列熵估计成本很高。EDCO 通过 quick-answer prompting 让模型尽快进入答案主体,再用前缀 token 条件熵近似完整序列熵。实验中,单样本熵估计时间从 2.24 秒降至 0.37 秒,计算开销减少 83.5%。
3. 每个阶段重新选 top-N 高熵样本
在每个训练间隔,EDCO 基于当前模型重新估计样本熵值,并选择最高熵样本组成下一阶段训练集。样本会随着模型状态动态进出课程,而不是按固定顺序走完一遍。
动态课程听起来很自然,但真正落地时会遇到一个直接问题:如果每次都要让模型对整个数据池生成完整答案,再计算完整序列熵,训练开销会非常高。EDCO 因此设计了两个轻量化策略。
第一,quick-answer prompting 会引导模型尽快进入答案主体,减少长链路推理带来的冗余生成;第二,前缀熵估计只使用输出前若干 token 近似完整序列熵。论文实验显示,前缀估计与完整序列估计具有较强相关性,能够保留样本排序所需的主要不确定性信号。
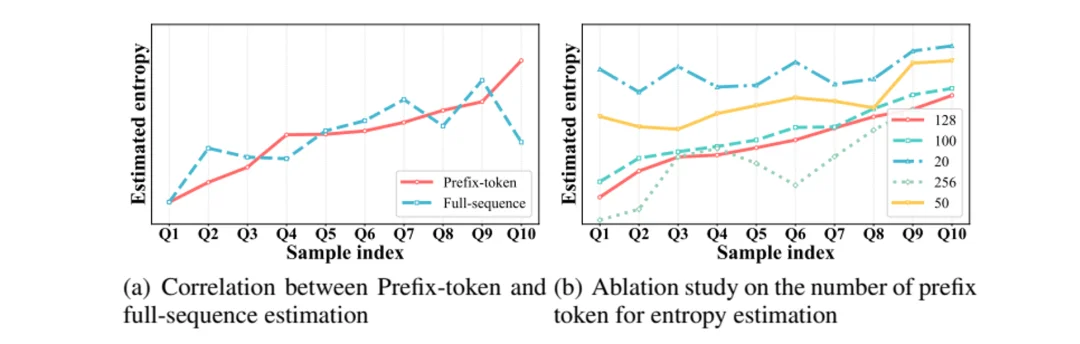
图 2:前缀熵估计与完整序列熵估计趋势一致,并可通过 prefix 长度控制稳定性与效率。
进一步看效率,完整序列估计单样本耗时 2.24 秒,前缀估计仅需 0.37 秒;在 8 卡并行时,耗时可降至 0.04 秒。对于需要周期性扫描训练池的动态课程方法来说,这一步让 EDCO 从 “思路可行” 变成了 “训练中可用”。
研究团队在通信、医疗、法律三个领域验证了 EDCO,模型覆盖 Qwen3-4B 与 Llama3.2-3B,训练范式覆盖 SFT 与 RLFT。其中,通信领域设置了 Datacom 与 Wireless 两类任务,分别对应数通运维分析与无线网络优化两种典型高复杂度场景。
Wireless 任务关注无线网络问题诊断与优化建议生成,样本涉及路测、信令、配置、话统等多类专业输入,要求模型从长文本和结构化指标中识别关键异常,结合规则与经验推理根因。Datacom 任务则面向数通网络运维,覆盖多厂商、多设备、多协议日志输入,要求模型理解领域术语、判断路由与协议状态,并完成计算和综合分析。
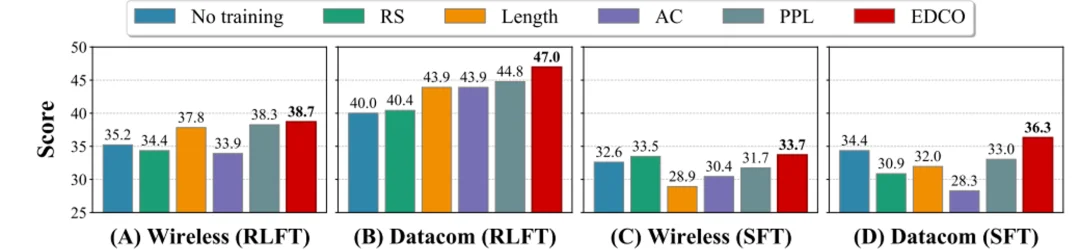
图 3:EDCO 在通信领域 RLFT 与 SFT 设置下的主结果。
在通信领域 RLFT 中,EDCO 在 Datacom 上达到 46.96%,高于随机采样的 40.43% 和 PPL 课程的 44.78%;在 Wireless 上达到 38.70%,同样优于其他基线。
值得注意的是,在 Wireless 场景中,一些静态策略甚至会让性能低于未训练模型。这说明在专业任务中,课程策略并不是 “有就比没有好”:如果排序信号不适配模型当前能力,反而可能把训练推向低效甚至错误的方向。
在 SFT 中,EDCO 也取得最高准确率:Wireless 为 33.7%,Datacom 为 36.3%。在 MedQA 上达到 36.7%,JEC-QA 上达到 17.4%,跨领域优势依然保持。
更强的动态基线对比同样说明问题:在 Datacom 上,EDCO 达到 47.0%,明显高于 Dynamic-PPL 的 41.3% 和 SEC 的 34.78%。动态更新本身还不够,关键是选择什么信号。
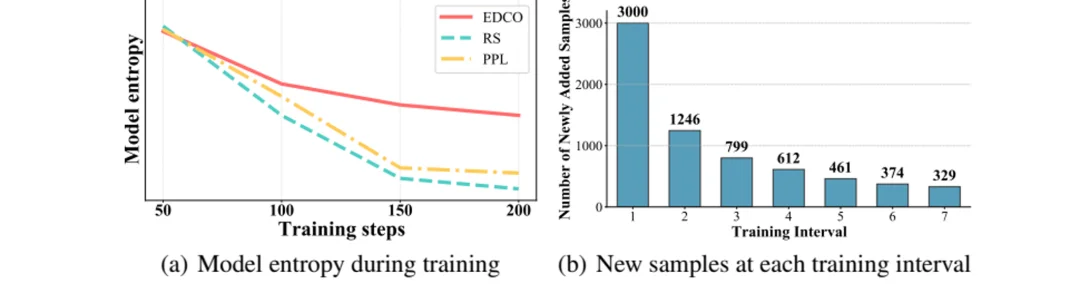
图 4:EDCO 在训练过程中维持更高推理熵,并持续更新课程样本组成。
EDCO 不只是挑更难的样本。训练过程分析显示,随机采样与 PPL 课程下模型推理熵下降更快,而 EDCO 能在训练过程中持续维持更高熵值,让模型不断接触仍具挑战性的样本。
课程组成也在不断变化:第一次训练间隔中有 3000 个新样本进入课程,之后每个间隔仍会持续加入此前未被选中过的高熵样本,同时保留部分仍未被模型掌握的旧样本。这意味着 EDCO 并不是简单 “一轮刷题”,而是在 “复习难点” 和 “引入新挑战” 之间动态平衡。
论文还在 MedQA 上固定 Qwen3-1.7B 参数,对比 EDCO 与随机采样诱发的梯度信号。结果显示,EDCO 所选样本的批次内梯度方向一致性达到 0.92,高于随机采样的 0.82;平均推理熵为 1.51,高于随机采样的 1.23;RL 梯度范数为 3.77,高于随机采样的 2.62。
这说明 EDCO 选出的样本既能提供更强学习信号,又能减少梯度冲突。与其让模型在所有样本上平均用力,不如让它把有限训练预算花在真正能推动参数更新的地方。
EDCO 给领域大模型微调提供了一个很有数据中心 AI 味道的启示:数据的价值不只取决于数据本身,还取决于模型当前处在什么状态。
通过推理熵驱动的动态课程编排,EDCO 让模型在训练过程中持续面对当前最有信息增益的样本;通过 quick-answer prompting 与前缀熵估计,它又把动态课程的额外成本控制在可接受范围内。
该方法不改变模型结构,也不绑定单一训练目标,可同时接入 SFT 与 RLFT,对通信、医疗、法律等专业任务都展现出稳定收益。
在高质量领域数据越来越昂贵的今天,如何安排数据进入训练,可能会和如何构造数据本身一样重要。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
