# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
随着大语言模型(LLM)在代码生成领域不断突破,AI 正在从“代码补全工具”逐步迈向真正的“自动化软件工程师”。然而,一个核心问题始终没有被真正解决:
AI 能否像人类开发者一样,从零开始独立构建完整的软件仓库(Repository)?
近日,北京大学与百度联合提出了全新的代码生成基准——RepoZero,首次为“从零生成完整代码仓库”提供了可验证、可扩展、自动化的评测框架,为 AI 软件工程研究打开了新的方向。
主页:
https://repozero.osslab-pku.org/
代码:
https://github.com/JesseZZZZZ/RepoZero
论文:
https://arxiv.org/abs/2605.07122
过去的大多数代码评测任务,例如 HumanEval、SWE-bench 等,主要关注:
而真实的软件开发远不止如此。
一个完整的软件仓库往往涉及:

RepoZero 关注的正是这一更具挑战性的目标:
让 AI 在没有现成代码的情况下,仅依据 API 描述,重新实现整个代码仓库。
这意味着,AI 不再只是“补代码”,而是真正参与“软件构建”。
RepoZero 的核心创新,在于提出了“仓库复现(Repository Reproduction)”任务。
系统会提供:
随后,AI 需要:
与传统依赖人工评分或 LLM 打分不同,RepoZero 使用真实执行结果进行严格验证:
只有生成仓库的输出与原始仓库完全一致,才算成功。
这一机制显著提升了评测的客观性与可信度。
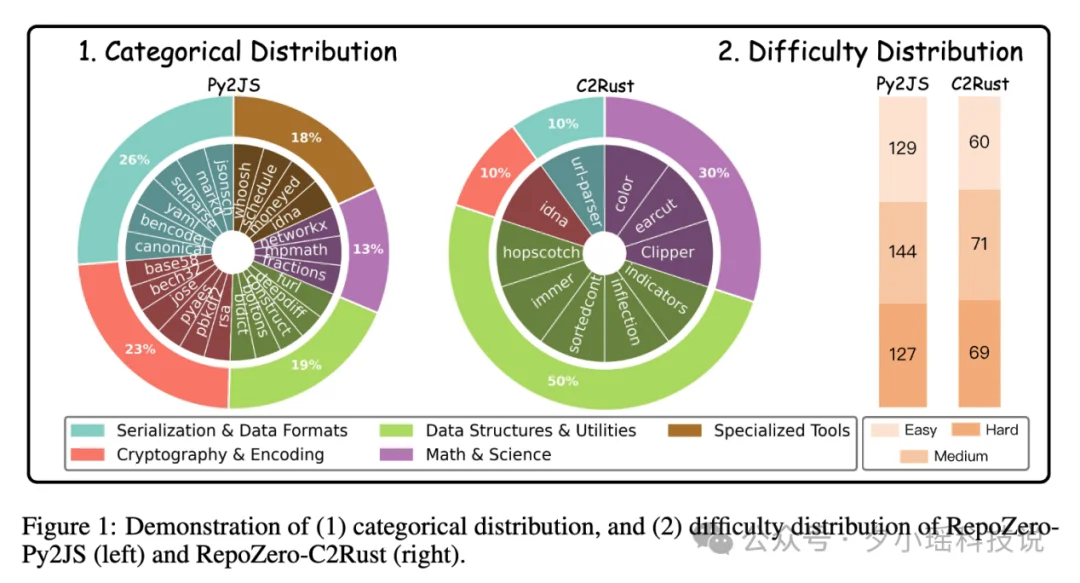
为了避免模型直接记忆 GitHub 代码,RepoZero 引入了极具挑战性的“跨语言生成”机制。
目前包含两个核心任务:
将 Python 仓库重新实现为 JavaScript
将 C/C++ 仓库重新实现为 Rust
同时,系统严格禁止:
这意味着模型必须真正理解算法与系统逻辑,而不是简单“复制粘贴”。
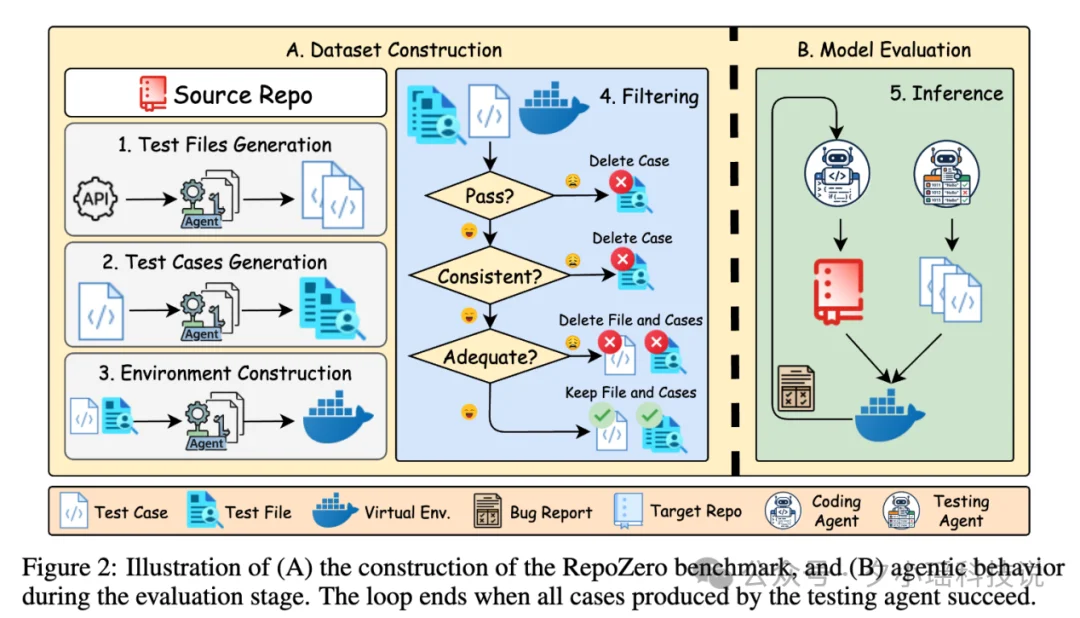
除了基准本身,论文还提出了一套重要框架:Agentic Code-Test Evolution(ACE)
ACE 的核心思想是:
AI 不仅写代码,还要自己生成测试、运行测试、分析错误、并持续修复。
整个流程形成: “代码生成 → 自动测试 → 错误反馈 → 代码修复” 的闭环。
实验表明:
这也意味着:
这也意味着:未来真正强大的 AI 程序员,不只是“会写代码”,而是“会调试、会验证、会自我修正”。
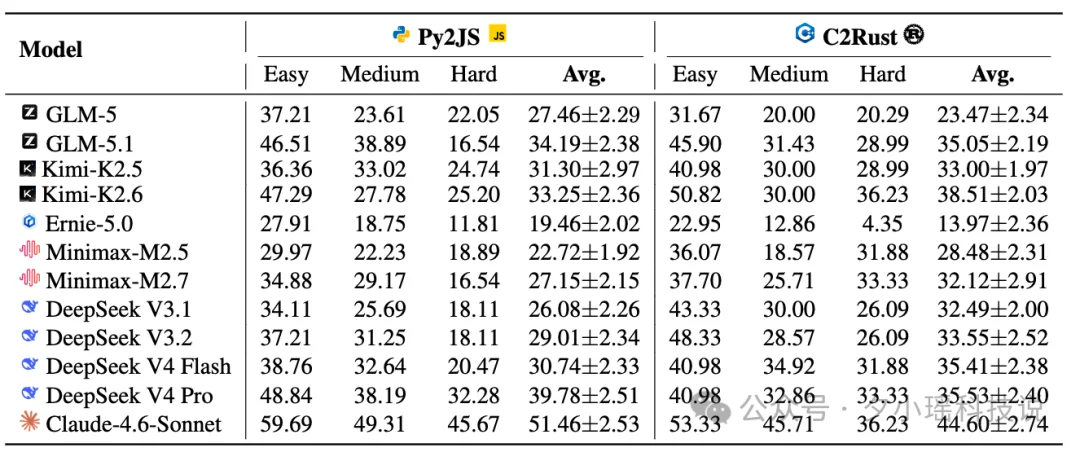
RepoZero 的实验结果也揭示了一个重要现实:
即便是当前最先进的大模型与 Agent 框架,在完整仓库生成任务上的成功率仍然有限。
在最困难任务中:
主要失败原因包括:
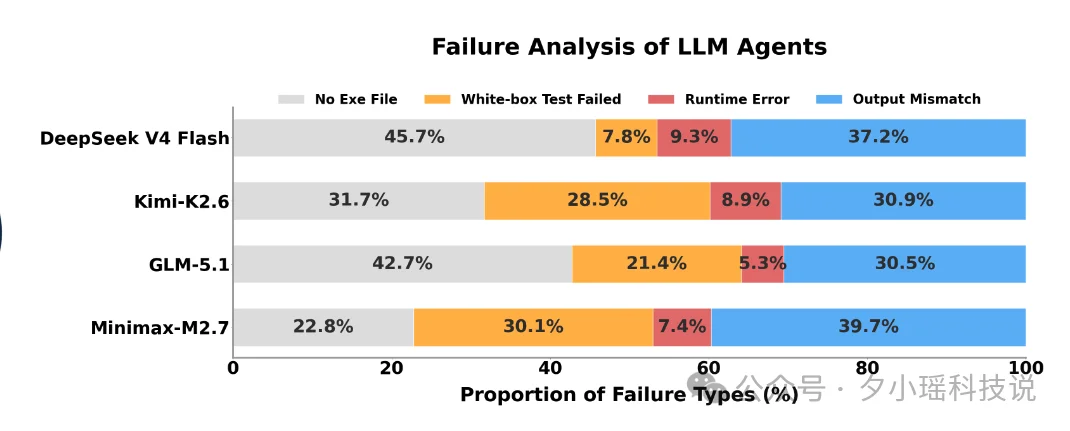
这表明:“真正的软件工程智能”仍然是 AI 领域尚未攻克的重要难题。
RepoZero 的意义不仅在于一个新 benchmark,更在于它重新定义了:“AI 软件工程能力”该如何评估。
它同时具备:
等关键特性。
论文作者认为,未来 AI 编程研究的重要方向包括:
RepoZero 为这些研究提供了统一而可靠的实验平台。
从代码补全,到自动修 Bug,再到从零构建完整软件仓库,AI 正在快速逼近真正的软件工程能力。
而 RepoZero 的提出,意味着:
AI Coding 正正式进入“Repository-Level Generation”时代。
未来,能够“自主开发完整软件系统”的 AI Agent,也许将不再只是科幻设想。
文章来自于"夕小瑶科技说",作者 "北京大学、百度"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
