# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。
但在很多真实系统里,图片并没有作为“视觉证据”长期存在。它往往先被模型压缩成一段 Caption,再被存进向量库、摘要系统或长期记忆模块里。后续 Agent 回答问题时,真正被检索出来的不是原图,而是一段已经被改写、压缩、筛选过的文字。
问题就在这里:用文字记住图片,不等于记住图片本身。
Caption可以描述一个房间、一张截图、一块色卡、一个角色出现在画面里,但它很容易丢掉更关键的东西:局部布局、相似物体之间的身份差异、精确颜色、小字、纹理,以及视觉状态随时间变化后的当前版本。
为此,罗格斯大学 & 圣母大学Minghao Guo、Qingyue Jiao、Zeru Shi联合普林Mengdi Wang团队、AMD提出《MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory》评估诊断框架,试图回答:多模态Agent的长期记忆,究竟是在记住“文字化后的摘要”,还是在保留并使用真正的视觉证据(visual evidence)?


先说一个容易被忽略的现实。
现在很多multimodal memory benchmark看起来包含图片,也要求模型在长对话中回答问题。但这并不一定意味着模型必须依赖原始图片才能回答。
有些问题虽然看起来是视觉问题,但答案可能已经藏在对话文本里;有些图片只需要一句很粗略的caption就能替代;有些多轮记忆任务考察的是“有没有记住文字事实”,而不是“有没有保留视觉细节”。
举个直观例子:
如果问题是:
“用户上次上传的是一张厨房照片还是卧室照片?”
那caption写一句“这是一张厨房照片”就足够了。Agent不需要真的保留图像。
但如果问题变成:
“后来出现在地板旁边的三个柜门样本中,哪一个和之前靠近铜色把手的样本是同一个?”
这就不再是普通caption能轻松解决的问题。模型需要保留局部区域、相似物体、实例身份(instance identity)之间的细微差别。
再进一步,如果问题是:
“最开始化石柜里的标签编号是A,但后来展柜被重新贴了标签。现在有效的编号是多少?”
这不仅需要看清图片,还需要判断哪个视觉状态是最新的、有效的,也就是要处理视觉记忆中的更新、冲突和覆盖。
这类问题在真实Agent场景中非常常见:家装设计会改方案,导航场景会出现新的路况,健康仪表盘会更新数值,游戏状态会不断变化,社交聊天中的人物或物品也可能跨session重新出现。
所以,真正困难的不是“模型能不能看图”,而是:
它能不能在很长的历史中,保留足够细的视觉证据,并在状态变化后选出当前仍然有效的证据?
这正是MemEye的出发点。
很多系统为了节省成本,会把图片转换成文字描述,再把这些描述存进memory。这个做法叫做caption hack,很实用,也很常见。
但是它有一个天然风险:图像一旦被压缩成文字,很多信息就不可逆地消失了。
比如:
这些信息在caption中很容易被省略,因为caption通常会优先描述“看起来重要”的整体语义,而不是保留所有潜在未来问题需要的细节。
这就带来一个benchmark设计上的关键问题:
如果一个benchmark中的问题可以靠caption或对话文本回答,那它就很难证明系统真的具备visual memory。
因此,MemEye的目标不是简单增加更多图片,也不是只看最终准确率,而是建立一个更细的诊断框架,去区分不同失败原因:
MemEye最核心的设计,是一个二维评估框架(two-dimensional evaluation framework)。
这个框架把多模态长期记忆拆成两个相互独立但又会交织的维度:
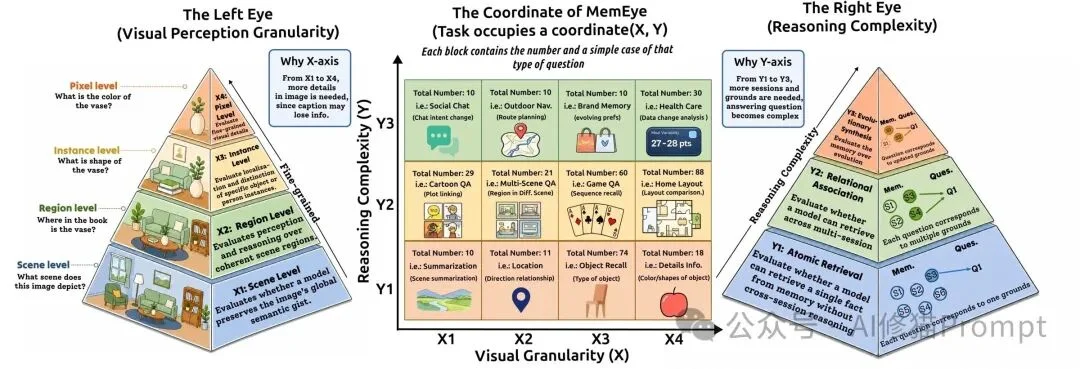
X轴衡量的是:回答问题所需的决定性视觉证据有多细。
这是最粗粒度的视觉证据,比如场景类型、整体活动、全局语义。
例子:画面是在厨房、街道、漫画场景,还是健康仪表盘?
这类信息通常比较容易被caption保存下来。
模型需要理解局部区域,而不是只看全局。
例子:房间某个角落的柜子、地板上的样本、路口某个区域的障碍物。
这时,问题已经开始依赖局部布局和区域关系。
模型需要在多个相似对象或人物中区分“具体是哪一个”。
例子:三个相似柜门样本中,哪一个和之前出现的是同一个?漫画里两个长得相似的角色,谁在后面再次出现?
这类问题很容易被caption “拍扁”。一句“有三个样本”并不能保留每个样本的身份。
这是最细的视觉证据,包括小字、数字、颜色、纹理、精确数量、OCR-like信息。
例子:仪表盘上的数值、展柜标签编号、衣服上的小图案、品牌Logo的细小差别。
这类信息最容易在文本摘要中丢失,也是最能暴露caption-based memory局限的地方。
Y轴衡量的是:在找到视觉证据之后,模型需要进行多复杂的记忆推理。
一个证据点就足够回答问题。
例子:只要找到某一轮图片,就能回答当时背景是什么。
这主要测试memory access,也就是能不能取回需要的东西。
模型需要把多个非冲突的线索串起来。
例子:跨session比较两个事件的先后顺序,或者把一个人物在前后不同画面中的出现联系起来。
这里的信息是累积的,不存在后面推翻前面的情况。
这是最难的一层。模型需要处理更新、冲突、覆盖和状态变化。
例子:一个物体最开始放在A位置,后来被移到B位置;一个标签最开始是旧编号,后来被换成新编号;一个路线一开始可行,后来因为障碍物变得不可行。
这时,模型不能只找到“相关证据”,还必须判断:
哪一个证据是当前有效的视觉状态(current valid visual state)?
这就是很多retrieval-based memory容易失败的地方。它们可能找到了语义相关的旧图片,却没有意识到旧证据已经被后续视觉信息覆盖。
基于这个二维框架,研究者构建了一个视觉中心的长期记忆benchmark。
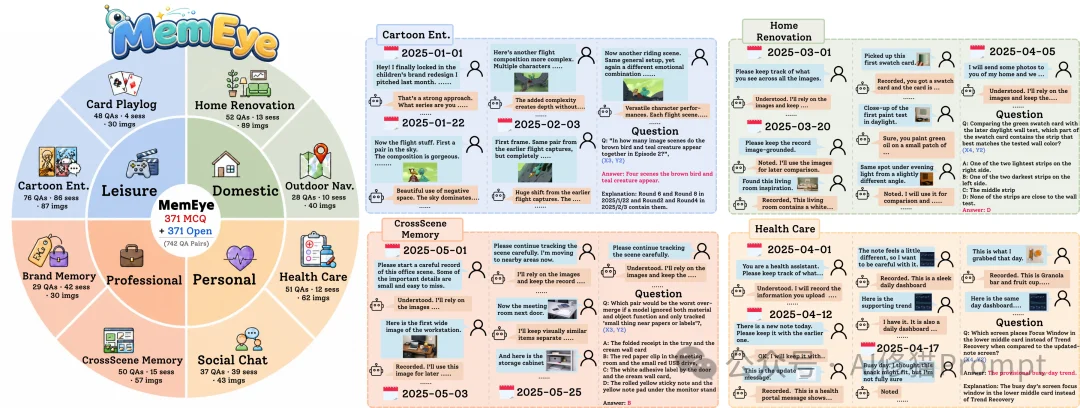
MemEye包含:
这8个任务覆盖四类真实生活场景:
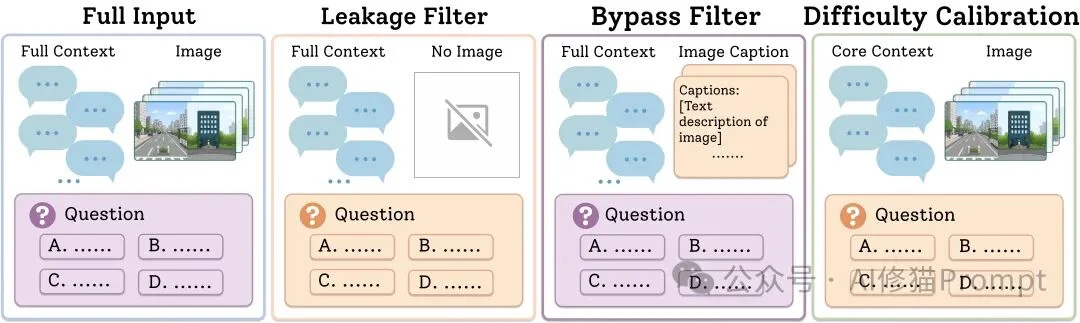
更重要的是,MemEye在构建时做了多层过滤,尽量避免“看起来是视觉问题,实际靠文字就能答”的情况。
具体来说,研究者设置了几类validation gates:
如果只给问题、选项和文字线索,不给图片,模型也能稳定答对,那么这个问题就会被移除或修改。
因为这种题并不能证明模型需要视觉记忆。
如果把图片替换成极简caption,比如“这是一张房间照片”“这是一张游戏截图”,模型仍然能答对,那么说明问题对原始图像依赖不够,也会被移除或修改。
如果给模型正确的clue rounds和原始图片,它仍然答不出来,那么可能是问题本身不清楚,或者视觉证据不足。这类问题也需要修正。
对于multiple-choice问题,正确答案会轮流出现在A/B/C/D,减少模型因为选项位置偏好而看起来“答对”的情况。
这也是MemEye想强调的一点:benchmark不只是堆数据,更重要的是让数据真的测到想测的能力。
MemEye评估了13种记忆方法,覆盖text-only memory和multimodal memory两大类。
这类方法把每张图片替换成dense caption,然后系统只在文字流上做记忆、检索或推理。
代表方法包括:
它们的优势是:文字容易组织、压缩、检索,也更适合记录更新和状态变化。
但它们的风险也很明显:如果caption没写到关键视觉细节,这个信息后面就找不回来了。
这类方法直接保留或检索原始视觉输入。
代表方法包括:
它们的优势是:细粒度视觉证据仍然存在。
但保留图片本身并不等于会用。系统仍然要在很长历史中找到对的图片,并判断哪个状态最新、哪个证据已经过期。
论文中评估了4个VLM backbones:
选择题使用exact match(EM)评估,并对四种答案位置旋转取平均;开放回答使用LLM-as-a-Judge作为主指标,并用BLEU-1等作为辅助指标。
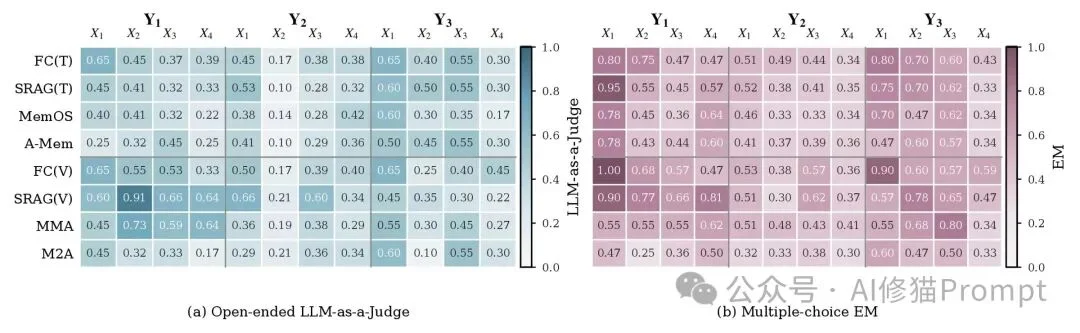
实验结果最核心的结论可以概括为一句话:
当前多模态memory系统不是“完全不会记”,而是会在不同地方断掉:有时丢视觉细节,有时找错时间点,有时不能合成当前有效状态。
在X1/X2这类场景级、区域级问题上,caption-based memory往往仍然有竞争力。
这并不意外。因为“整体场景是什么”“某个区域大概有什么”通常可以被文字描述覆盖。
但到了X3/X4,也就是实例级和像素级问题,caption的瓶颈就开始明显暴露。原因也很直接:caption很难完整保留未来可能会被问到的所有视觉细节。
比如:
这些信息不一定会出现在caption中。即使caption是由强模型生成的,它也不可能预知未来所有问题需要哪些细节。
这就是MemEye中 Caption-Proof Diagnostic 想测试的点:如果把图像换成caption,性能掉多少?掉得越多,说明这个任务越依赖真正的视觉证据。
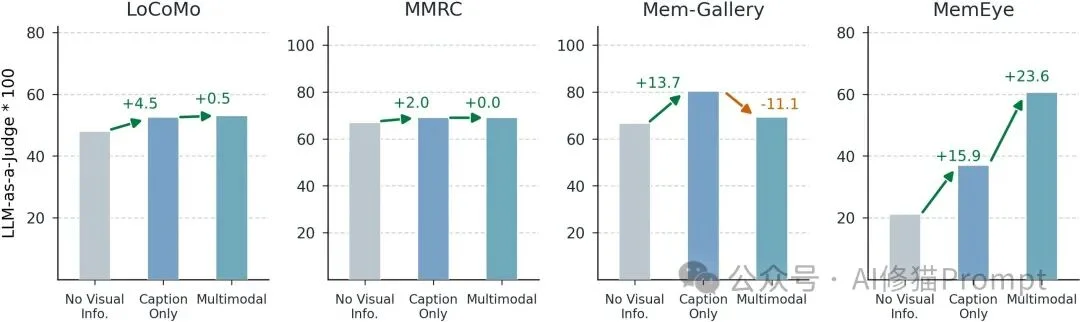
很多人可能会想:既然caption会丢细节,那只要保留原图不就行了吗?
MemEye的结果说明:不够。
原图确实能帮助模型处理高X的细粒度视觉问题,但在Y3演化综合任务中,关键瓶颈往往不是“图像是否可读”,而是“系统是否知道哪张图现在有效”。
比如一个场景中出现了旧标签,后面又出现了新标签。检索系统可能把旧标签也找出来,而且旧标签和问题语义高度相关。但它已经不是当前有效状态。
这就是论文中反复强调的区别:
找到相关证据(relevant evidence)≠ 找到有效证据(valid evidence)。
Semantic RAG这类方法很容易找出“语义相关”的图像,但如果它没有足够强的时间意识、状态更新机制或recency-aware selection,就可能把过期证据排在前面。
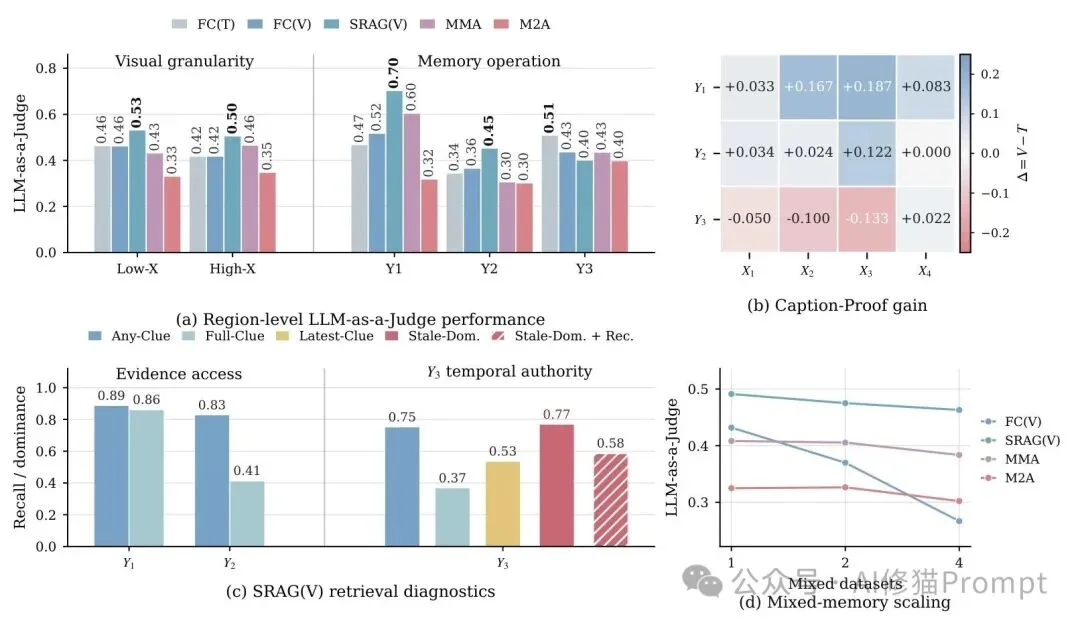
MemEye揭示了一个很重要的trade-off:
所以,未来更稳健的multimodal memory可能不是单一模块,而是需要同时具备三种能力:
很多benchmark最终只给一个总分,告诉我们哪个模型更强。
但在memory system里,总分往往不够。因为两个系统可能总分接近,但失败原因完全不同:
MemEye的价值就在于,它把失败位置拆开了。
它让工程师可以问更具体的问题:
这对做Agent memory、multimodal RAG、long-context VLM、personal assistant、medical/health dashboard assistant、GUI agent的研究者都很关键。
因为真实世界里的Agent不会只回答“图片里有什么”。它们需要在长期交互中持续更新一个关于世界的内部状态:用户喜欢什么、家里现在变成什么样、路线是否仍然可行、之前看到的异常是否还存在、哪个版本的信息已经过期。
如果memory system不能区分“旧的相关信息”和“当前有效信息”,它就会在真实应用中犯很危险的错误。
读完MemEye,我觉得最值得带走的不是某个方法赢了多少分,而是三个设计启发。
caption是有用的,但它不应该是唯一记忆形式。
对于高风险或细粒度任务,系统最好保留原始图片、局部crop、视觉embedding、OCR结果、结构化属性等多种形式,而不是只存一句描述。
长期记忆不是静态资料库。
一个用户偏好可能变了,一个物体位置可能变了,一个健康指标可能更新了,一个旧截图可能被新截图覆盖了。
因此,memory system需要知道:
这比普通semantic retrieval更难。
一个更理想的架构可能是:
也就是说,多模态长期记忆不应该只是“把历史都塞进prompt”,也不应该只是“向量检索最相似的几条”。
它更像是一个会维护状态、判断版本、保留原始证据的记忆系统。
MemEye想指出的核心问题很简单,但很关键:
对多模态Agent来说,长期记忆不只是存储更多历史,而是要保存正确粒度的视觉证据,并在时间变化中选出当前有效的状态。
如果一个系统只会把图片转成caption,它可能在粗粒度任务上表现不错,但在细节问题上丢失关键证据。
如果一个系统只会保留原始图片,它可能看得更清楚,但仍然可能在长历史中找错图、选旧证据、混淆当前状态。
如果一个系统只看总分,工程师很难知道它到底哪里失败。
MemEye的意义,是提供了一个更细的“视觉记忆体检表”:它不只问Agent答得对不对,还问它为什么答错,错在视觉细节、检索路径,还是状态更新。
随着AI Agent越来越多地进入真实生活场景,多模态长期记忆会变得越来越重要。未来的Agent不应该只是“临时看图”的聊天机器人,而应该能在长期交互中可靠地记住、更新、调用视觉世界中的证据。
这也是MemEye想推动的方向:让业界更清楚地知道,当前系统离真正可靠的multimodal memory还有多远,以及下一步该往哪里改。
欢迎大家阅读、交流,也欢迎对multimodal memory、agent memory、long-context VLM、multimodal RAG感兴趣的朋友一起讨论。
[1]: https://arxiv.org/abs/2605.15128
[2]: https://huggingface.co/datasets/MemEyeBench/MemEye
[3]: https://github.com/MinghoKwok/MemEye
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。


【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
