# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
训练一个真正会用网页的GUI Agent,最自然的思路通常是:
去真实网站上操作,收集轨迹,再拿来训练。
但有一个卡脖子的问题——真实网站不告诉你答案。
当Agent在真实网页上点击、输入、跳转时,我们往往只能看到页面截图或DOM变化,很难直接知道背后的任务状态到底发生了什么。
举个例子,一个商品是否真的被加入购物车,一封邮件是否真的被发送,一个表单是否真的完成提交,这些都不是截图本身能稳定回答的问题。
结果就是,我们不得不依赖人工标注或LLM judge去判断轨迹是否正确,而这会带来成本高、不稳定、难扩展的问题。
对此,香港科技大学(广州)DIAL Lab和Foundation Agents开源社区联合推出了AutoWebWorld(AWW)——
一个用有限状态机(FSM)驱动的网页环境生成框架,让轨迹验证从“事后猜测”变成“环境自带答案”。
团队的核心想法很简单:
与其在真实网站里猜测Agent做得对不对,不如先构造一批完全知道内部规则的网页环境。
每个环境都由一个有限状态机描述,页面是什么、状态变量有哪些、动作什么时候可执行、执行后状态如何变化、哪些状态代表任务成功,这些都被显式写进transition中。
这样一来,网页不再只是一个黑盒界面,而是一个带有可验证语义的交互世界。
AutoWebWorld总体流程如下图所示:
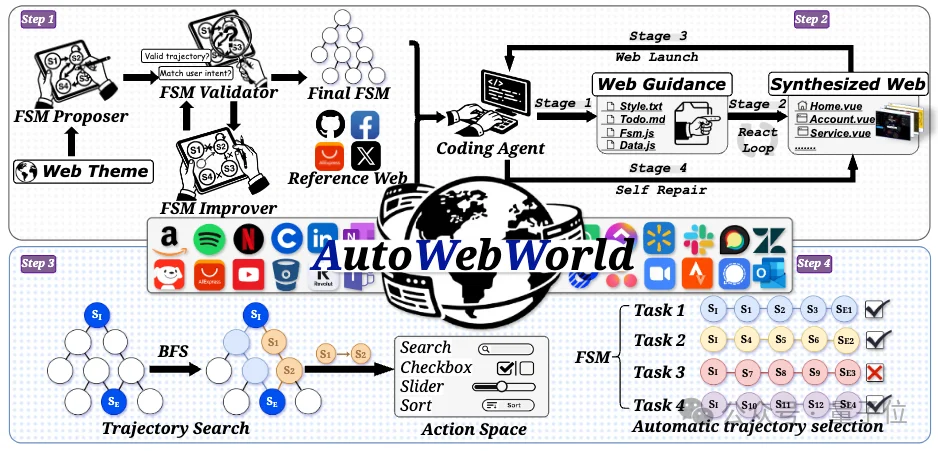
第一步是FSM Generation。
系统从给定的web theme出发,通过FSM Proposer、FSM Validator和FSM Improver形成闭环,逐步生成可接受的 Final FSM。
Proposer负责提出初始交互语义框架,Validator检查其合理性、用户意图一致性和轨迹支撑能力,Improver根据反馈持续修改。
系统还会结合reference web,使最终环境在页面结构、交互形式和视觉风格上更接近真实网页。
第二步是Web Synthesis。
在得到Final FSM后,Coding Agent将其转化为可运行的网站前端。
该过程包括生成Web Guidance,如style.txt、todo.md、fsm.js和data.js,再根据这些材料逐步实现页面文件,并启动synthesized website。
如果构建或运行中出现错误,系统会进入Self Repair,自动修复并重新启动,直到得到可交互的web environment。
第三步是Trajectory Search。
系统基于FSM的transition graph进行BFS,从初始状态搜索到目标状态的候选轨迹。
每一步动作是否可执行由precondition决定,执行后的状态变化由transition rule决定。因此,搜索得到的轨迹具有明确的语义合法性,并通常对应到达目标状态的最短路径。
第四步是Automatic Trajectory Selection。
BFS产生的候选轨迹会被replay到synthesized website中,并由Playwright执行真实GUI操作。
系统会检查元素是否存在、操作是否成功、页面跳转是否符合预期,以及最终是否到达目标状态。只有完整执行成功的轨迹才会被保留,形成最终的verified trajectories。
这套设计带来的核心变化是:轨迹生成和轨迹验证被统一到了环境内部。
传统GUI数据收集通常依赖真实网站、人工标注或LLM judge。
问题在于,真实网站的内部状态不可见,外部evaluator只能根据截图、DOM或操作记录去猜测任务是否完成。
而AWW中的状态、动作和transition都是显式定义的,任务成功可以通过是否到达FSM goal state来判断,动作合法性也可以通过precondition和transition rule来检查。
因此,AWW的验证不是事后补上的外部判断,而是环境本身自带的intrinsic verification。
Query 1(推特):
Update my profile bio to ‘Experienced software engineer specializing in full-stack web development and cloud architecture’ and change my display name to ‘Alex Chen’, then save the changes.
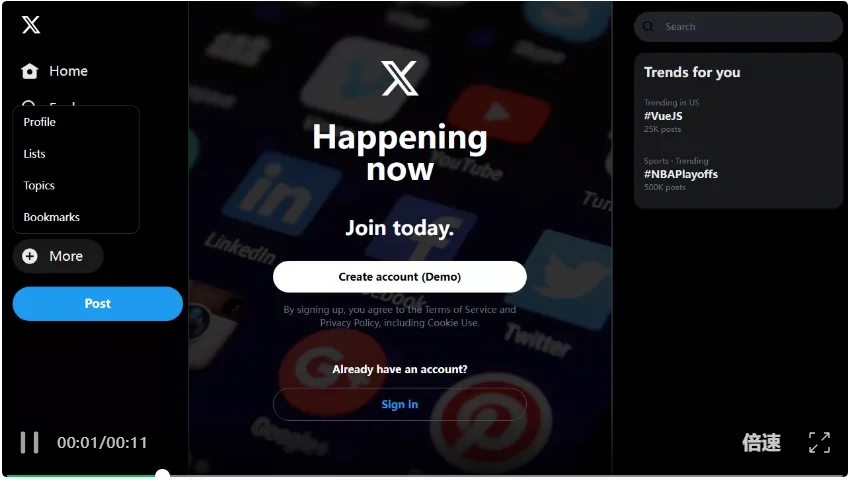
Query 2(skyscanner):
Find American Airlines flights from LHR to JFK, traveling on September 16, 2029 in economy class. Book the American Airlines flight that comes up in the search results, choose standard baggage and standard seat, then complete the booking with first name Alex, last name Johnson, email alex.j@email.com, and card number 4111111111111111. Accept the terms and confirm the booking.
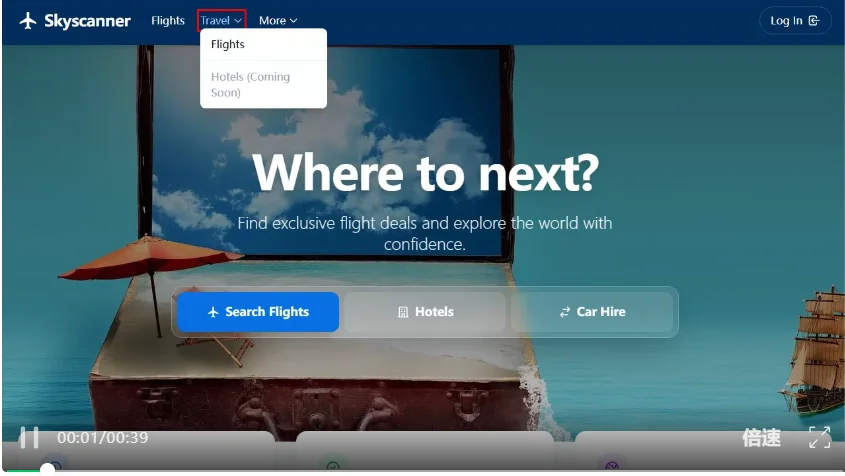
Query 3(Medium):
Start writing a new story, set the title to ‘The Midnight Garden’, write the body content ‘Under the pale moonlight, the old garden whispered secrets only the night could hear. Roses bloomed with silver petals, and the fountain sang a melody of forgotten dreams.’, enable publishing, open publish options, continue to confirmation, schedule it for November 18, 2021 at 9:18 AM, and confirm the schedule.
从数据规模上看,AutoWebWorld合成了29个不同的网页环境,总共覆盖875个页面,并生成了11,663条verified trajectories。
相比一些真实网页数据集,AWW的一个明显特点是轨迹更长,平均轨迹长度达到约21.9步,而Explorer、AgentTrek、Fara、Mind2Web等真实网页数据集的平均步数大多在6.9到12.1之间。
这意味着AWW更强调长程交互、组合式操作和跨页面状态追踪,而不是只覆盖短路径点击任务。
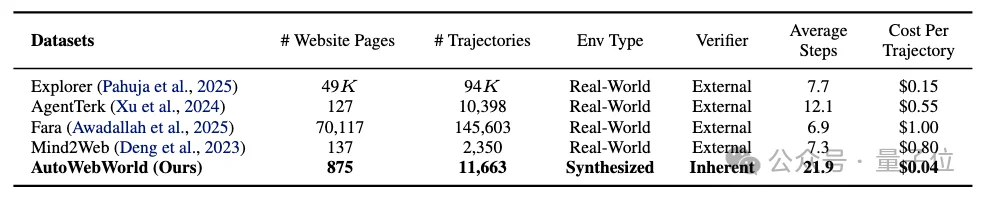 △GUI轨迹数据集对比
△GUI轨迹数据集对比
成本上,AWW的平均生成成本约为每条轨迹0.04美元,而已有真实网页轨迹数据集的成本通常在0.15到1.00美元之间。
整个29个环境的构建总成本约为447.37美元,其中Web Generation成本约为52.26美元,FSM Generation约为57.10美元,Query Generation约为65.84美元,Thinking Generation约为272.17美元。
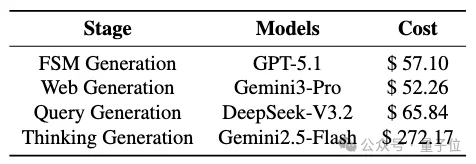
△AWW每阶段成本
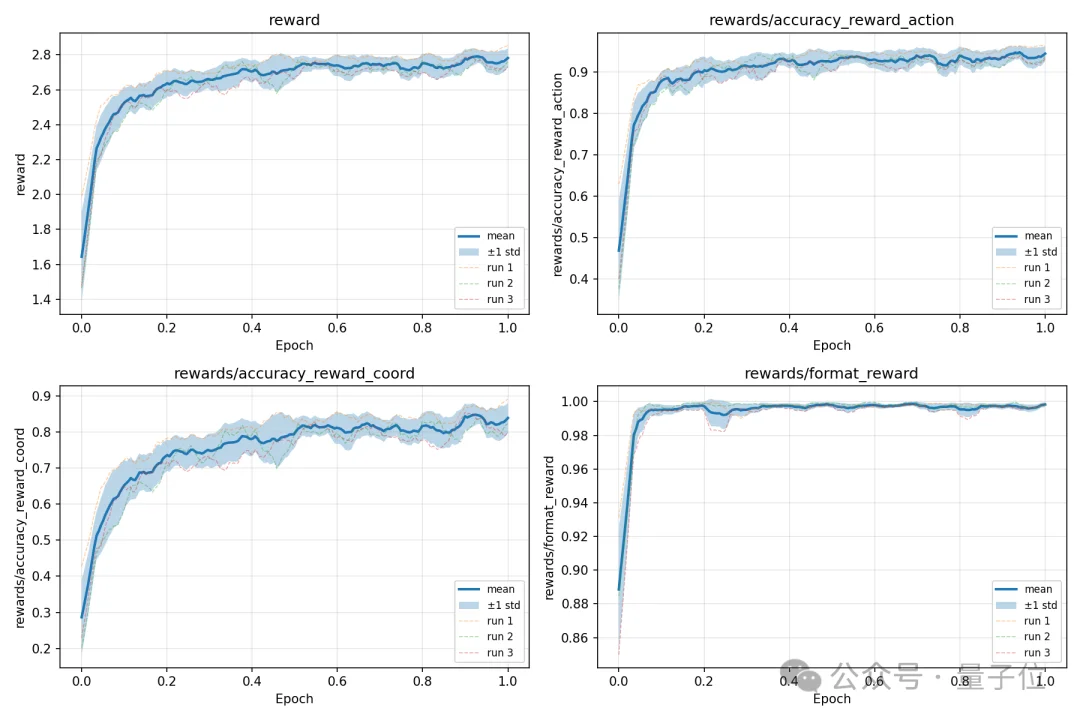
△GRPO训练曲线
在训练时,AWW并不是直接把11,663条轨迹全部无差别塞进模型。
由于同一个任务下可能存在多条相似轨迹,为了减少过拟合到高度同质的transition pattern,实验中会从同一任务的平行轨迹中采样代表性路径,最终得到1215条distinct trajectories,总计12,585个交互步骤。
除此之外,AWW还会从轨迹中抽取单步交互,并把它们改写成grounding supervision,让模型不仅学习“下一步应该做什么”,也学习“应该点击截图中的哪里”。
最终,导航轨迹数据和grounding数据被合并成约16k个GRPO training steps。
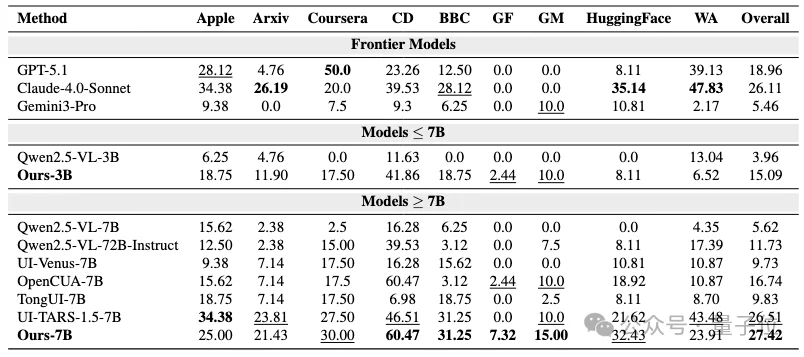 △WebVoyager实验结果
△WebVoyager实验结果
在真实网页导航上,AWW使用WebVoyager作为主要评估对象。
由于真实网站经常出现access denied、登录限制或CAPTCHA,实验中对WebVoyager选择了9个较稳定的网站,并将每个任务限制在最多15步以内,用Gemini-3-Flash作为judge model来判断任务是否成功。
在这个设置下,基于AWW数据训练后的7B Web GUI agent在WebVoyager上取得了27.42%的整体成功率,超过UI-TARS-1.5-7B的26.51%,也显著高于原始Qwen2.5-VL-7B的5.62%。
在部分具体网站上,模型也表现出明显提升,例如CD达到60.47%,Coursera达到30.00%,HuggingFace达到32.43%,并且在一些更难的网站上也获得了非零成功率。
在grounding评估上,AWW使用ScreenSpot-V2和ScreenSpot-Pro来验证模型是否更擅长定位可交互元素。
结果显示,AWW数据对grounding也有稳定收益。
在ScreenSpot-V2上,Qwen2.5-VL-3B的整体分数从61.87提升到65.88,Qwen2.5-VL-7B从84.83提升到86.16。
在更难的ScreenSpot-Pro上,3B模型的平均分从13.3提升到18.0,7B模型从23.2提升到27.5。
这说明AWW轨迹不只是提供高层任务规划信号,也能提供底层视觉grounding信号。
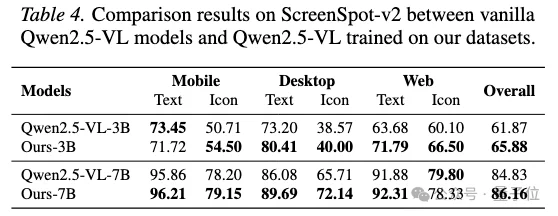
△ScreenSpot-v2结果
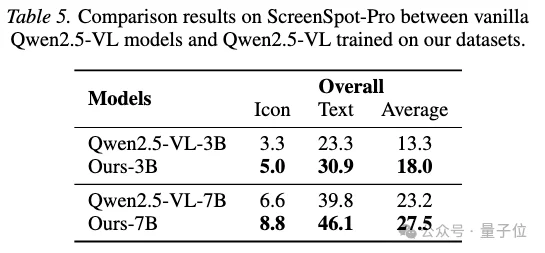
△ScreenSpot-Pro结果
AWW同时还给出了scaling curve。
也就是说,论文并不是只报告“用完整数据训练后效果变好”,而是进一步研究了:
当合成数据规模逐步增加时,真实网页任务上的成功率是否也会稳定提升。
实验中,训练集规模被设置为8、256、1,024和16,253个 samples,并在每个规模下保持相同的数据配比,即grounding data和navigation trajectory data维持2:8的比例,从而尽量排除数据组成变化带来的干扰。
结果显示,随着AWW合成数据规模扩大,WebVoyager上的整体成功率从3.92%逐步提升到17.59%、19.09%,最终达到27.42%;Online-Mind2Web上的成功率也从1.22%提升到7.32%、7.93%,最终达到14.02%。
论文还对这两条曲线进行了简单polynomial fitting,拟合结果与观测点基本一致,并预测在更大数据规模下仍有继续提升的趋势。
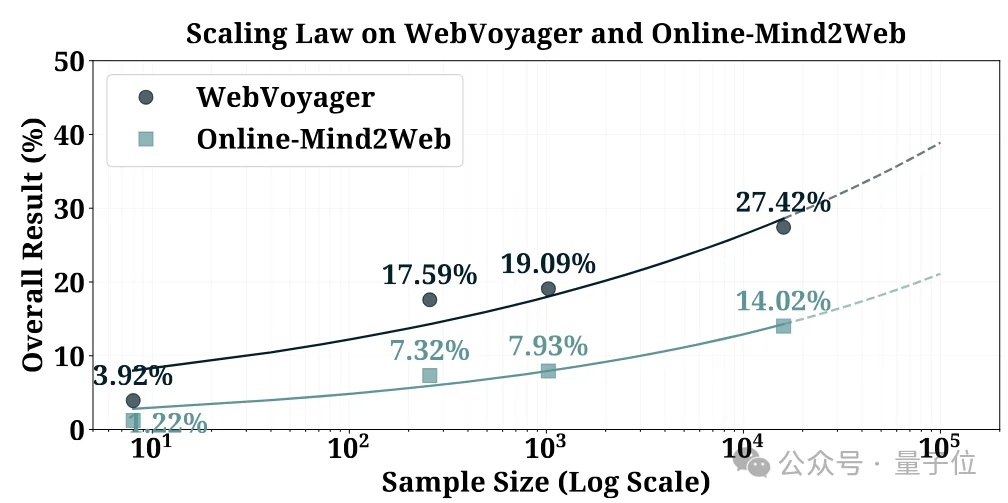 △Scaling曲线
△Scaling曲线
这条scaling curve是AWW实验里非常重要的一点。
它说明AWW的价值不只是“生成了一批有用的数据”,而是提供了一种可以继续扩展的数据生成机制。
换句话说,只要继续扩大verified synthetic trajectories的规模,模型在真实网页benchmark上的表现也有希望继续提升。
这正好回应了GUI agent训练中的核心问题:
我们缺的不是零散的任务样本,而是一个能够稳定生产可验证交互数据、并且具备scaling potential的环境生成 pipeline。
因此,AutoWebWorld不是简单地“生成网页”,也不是简单地“生成任务”。
它真正做的是transition-driven web environment generation:先定义可验证的交互语义,再用coding agent生成遵守这些语义的网页环境,接着通过BFS搜索候选轨迹,最后用真实前端执行来过滤并保留verified trajectories。
这和传统task-driven数据生成方式有本质区别。
传统方式往往是先写任务,比如“买一件红色衬衫”或者“发送一封邮件”,然后让agent在真实或模拟网页中尝试完成,再用外部evaluator判断是否成功。
问题在于,任务本身并不提供完整的状态转移结构,网页背后的真实状态也不可控,所以验证只能依赖外部判断。
AutoWebWorld则把验证逻辑内置到环境本身:只要轨迹满足FSM transition并到达目标状态,我们就可以确定它完成了任务。
最后,AutoWebWorld作者团队来自于香港科技大学(广州)DIAL Lab实验室和Foundation Agents开源社区。
第一作者为香港科技大学(广州) 研究生吴壹凡,该篇工作为其在DeepWisdom实习期间完成。
共同通讯作者为DeepWisdom创始人兼CEO吴承霖,蒙特利尔大学刘邦副教授,以及香港科技大学(广州)骆昱宇助理教授。
文章来自于"量子位",作者 "香港科技大学(广州) 吴壹凡"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
