# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

紧跟DeepSeek价格战,小米掏出技术底牌!
智东西6月1日报道,5月30日,小米首次公开MiMo-V2.5系列API永久降价99%的技术秘籍,其博客提到,这也是业内首篇全面覆盖Hybrid SWA+MoE+多模态组合架构的大规模工程落地方案。
其降价的核心技术基础是,小米MiMo大模型团队围绕Hybrid SWA+MoE+多模态的复合架构,系统性重构从KV Cache管理、分级缓存、前缀缓存到调度策略与Prefill/Decode链路的完整推理栈,KV Cache存储压缩至同级方案的约1/7,在长序列场景下推理成本大幅下降。

5月30日,小米MiMo大模型负责人罗福莉在X发帖介绍了这篇技术论文,她提到,经实际生产流量验证,这些优化措施使有效KV Cache容量提升了近5倍,主流测试框架下的服务器端缓存命中率平均达到93%~95%,结合MoE配置调优和多模态推理优化,这些措施能够实现更高效的长上下文推理,也是近期小米MiMo API降价的部分原因。
小米发布题为《MiMo-V2.5系列推理全链路优化:将Hybrid SWA效率推向极致》的技术博客是对其上周MiMo-V2.5系列API永久降价、TokenPlan计费体系优化等一系列举措的最新回应。
5月27日,小米官宣MiMo-V2.5系列API永久降价,TokenPlan计费体系优化后其用量提升至原来的5~8倍。小米MiMo几乎直接对标DeepSeek API价格。更新价格后,MiMo-V2.5输入缓存命中价格降至0.02元/百万tokens,未命中输入为1元/百万tokens,输出价格为2元/百万tokens;MiMo-V2.5-Pro则分别为0.025元、3元和6元。
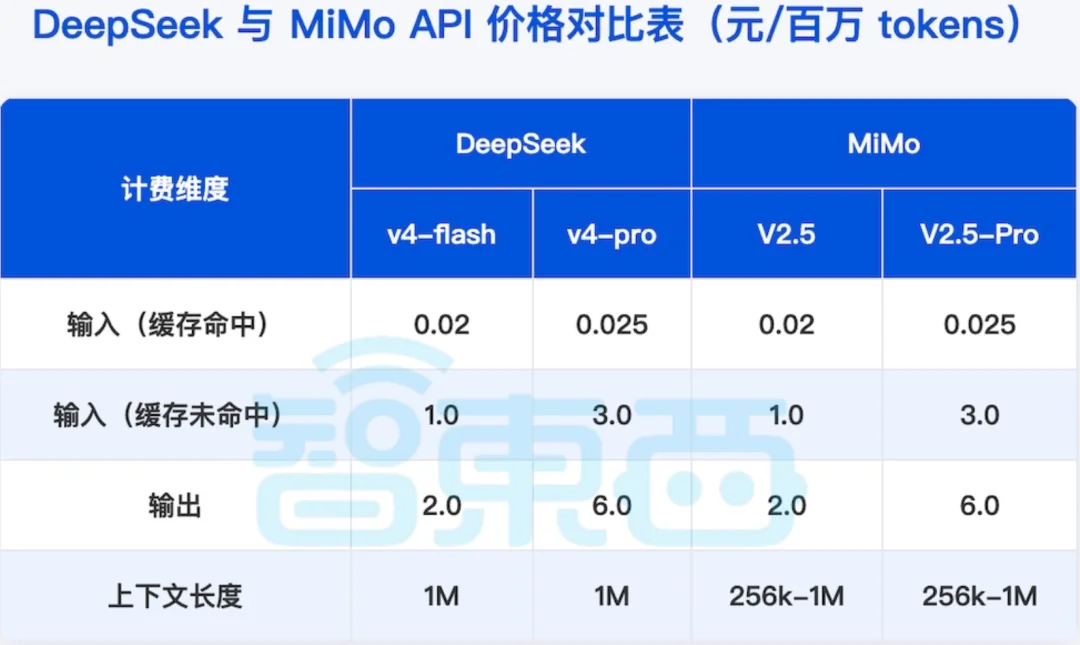
▲DeepSeek与小米MiMo API价格对比表(智东西制表)
5与27日,罗福莉在社交平台X上就预告了技术报告即将发布,并提前划了重点,她提到输入(缓存命中)部分降幅高达99%,根本原因是其推理框架现在支持SWA的KVCache优化;输入(缓存未命中)和输出价格降低60%-80%是因为Hybrid SWA架构中SWA层占比为6/7,其计算量约为Full Attention的1/7。此外,在API大幅降价的同时,小米仍能基本实现收支平衡。
技术博客:
https://mimo.xiaomi.com/zh/blog/mimo-v2-5-inference
小米在技术博客中提到,MiMo-V2.5系列模型的推理效率是多维度协同优化的结果。
其核心架构是Hybrid SWA+MoE+多模态架构,并系统性重构了KV Cache管理、分级缓存、前缀缓存树,优化调度策略及Prefill/Decode链路,最终将其理论效率优势真正兑现到生产环境。
小米研究人员选择Hybrid SWA+MoE+多模态架构的原因是,MiMo-V2.5设计之初的目标就是,训练出一个在长文推理场景下既足够强、又足够高效的模型。
传统全局注意力(Full Attention)架构无法兼顾,Hybrid SWA的核心思想是在局部窗口注意力(SWA)与全局注意力之间进行分层混合:绝大多数层仅计算局部窗口内的注意力,只有少量关键层保留全局视野。理论上,这种结构能够将Attention的计算复杂度压低到接近线性,同时依然维持对长程依赖关系的建模能力。
但想要充分发挥Hybrid SWA架构的推理效率优势还需要调度策略、Prefill/Decode执行链路、多模态、MoE架构的全链路优化。
先以MiMo-V2.5-Pro为例,具体看下Hybrid SWA架构的推理效率优势。
MiMo-V2.5-Pro模型共70层,其中10层为Full Attention、60层为SWA,SWA的滑动窗口大小是128。
与Full Attention相比,Hybrid SWA架构中SWA层占比为6/7,因此其计算量约为Full Attention的1/7。
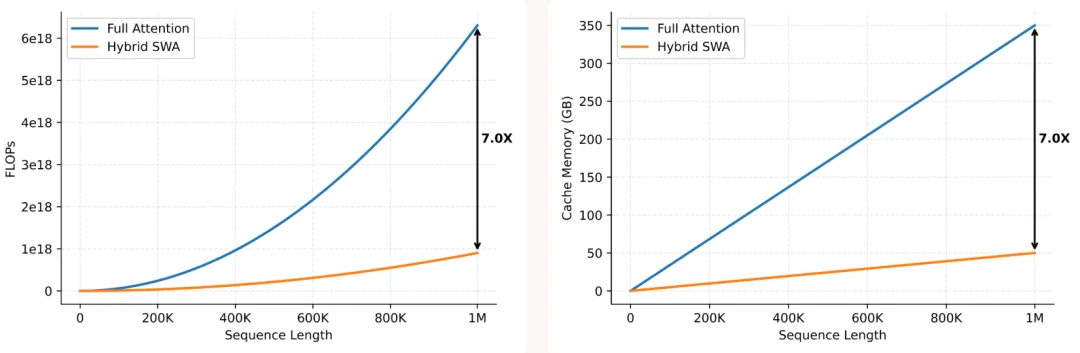
此外,由于SWA层仅需保留滑动窗口内KV,无需存储全序列,因此KVCache占用同样下降至接近1/7。在长序列下,KV Cache的体积可能远超模型参数,因此KV Cache存储的减少几乎直接等价于长序列场景下decode成本的降低。
其技术博客提到,不同模型架构KV Cache存储、访存模式都存在差异,其故估算了多个国产模型的KV Cache大小,MiMo-V2.5-Pro和MiMo-V2.5在KV Cache上位列国产模型第二,仅次于DeepSeek-V4-Pro和Flash。
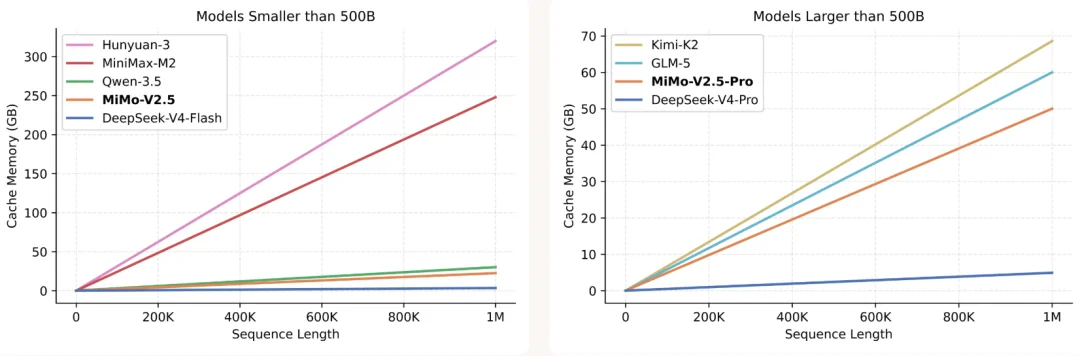
因为存在与序列长度无关的固定计算与访存开销,所以实际成本差异并不严格等价于KV Cache规模比例。但在长上下文场景下,整体趋势一致:短文性价比接近,序列越长推理成本优势越大。
5月27日,小米官宣降价时,罗福莉就在社交平台X上发帖,为MiMo API的降价原因划了重点。
MiMo-V2.5降价幅度最大的是输入(缓存命中)部分,降幅高达99%,根本原因是其推理框架现在支持SWA的分层键值缓存优化。生产环境推理引擎测试表明,此优化可将缓存token容量提升5倍,相当于缓存成本降低80%。结合混合模型中多个全注意力模块之间的缓存读取重叠,实际成本进一步降低。
输入(缓存未命中)和输出价格降低60%-80%是因为SWA稀疏度比,70层MiMo-V2.5-Pro的预填充计算量大致相当于10层GQA模型。这使其最初的推理成本远低于行业平均水平,带来2~3倍定价利润。
她还提到,在API价格大幅下调的情况下,小米的生产推理引擎几乎满负荷运转,基本能够实现收支平衡。他们之前曾建议大模型公司不要“盲目降价”,因为极少有模型架构和推理优化方案能够保证API成本不亏损。如果未来出现更多能够节省计算资源和KV Cache的架构,以及能够进一步降低API成本的更完善推理基础设施,这将在行业内形成一个良性循环。
此外,经济实惠且高性能的模型API将推动真正、持续且大规模的推理需求。这种上游需求将带动整个AI基础设施链发展。

为了让SWA更加可用,研究人员围绕KV Cache进行了系统性重构,此前其选择的临时方案都无法让推理系统真正“理解”Hybrid SWA的存储特性。
Hybrid SWA带来的核心存储矛盾是,Full Attention层需要保留全序列KV(O(N)),而SWA层仅需维护滑动窗口内KV(O(W))。在传统单一KV pool设计下,系统必须按O(N)为所有层统一分配显存,使SWA的窗口稀疏性无法被利用,实际存储效率退化为Full KV Cache的近似实现。
在此基础上,其采用了双池分治、前缀缓存树重构、GCache三级缓存综合优化。
分池优化是将KV Cache拆分为Full Attention与SWA两个独立池,并在系统层进行统一抽象,这使得SWA KV Cache在系统层面实现严格O(W)存储约束,使整体KV Cache容量效率提升约7倍,主流推理框架也都采用了类似的实现方案。
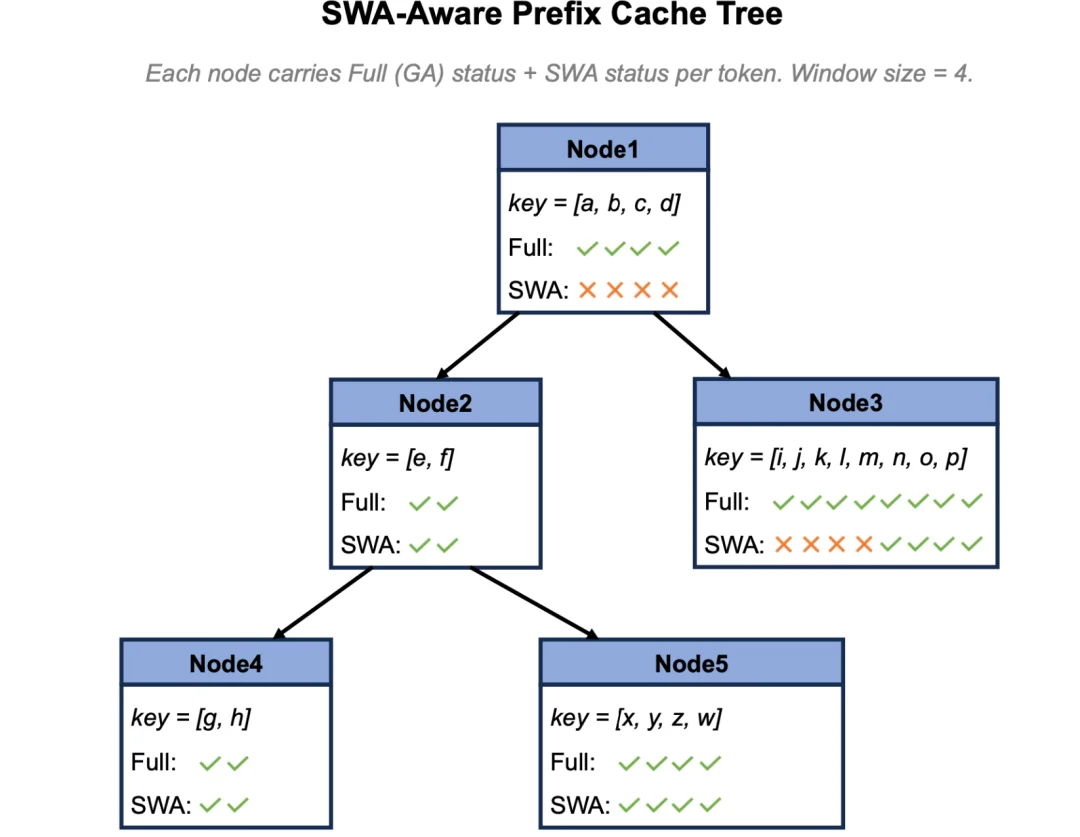
SWA-aware前缀缓存树优化包括匹配规则升级为“窗口安全长度”、淘汰路径与请求生命周期绑定、节点同时承载两套索引。
SWA把KV体积压到1/7是容量层面的收益,命中率是复用层面的收益,两者乘起来是prefill阶段实际计算成本的曲线。引入“窗口安全长度”匹配规则后,同样token容量的KV Cache命中率理论上是小幅度下降的,但同样存储容量下的token数量达到数倍,实际命中率大幅度提升。
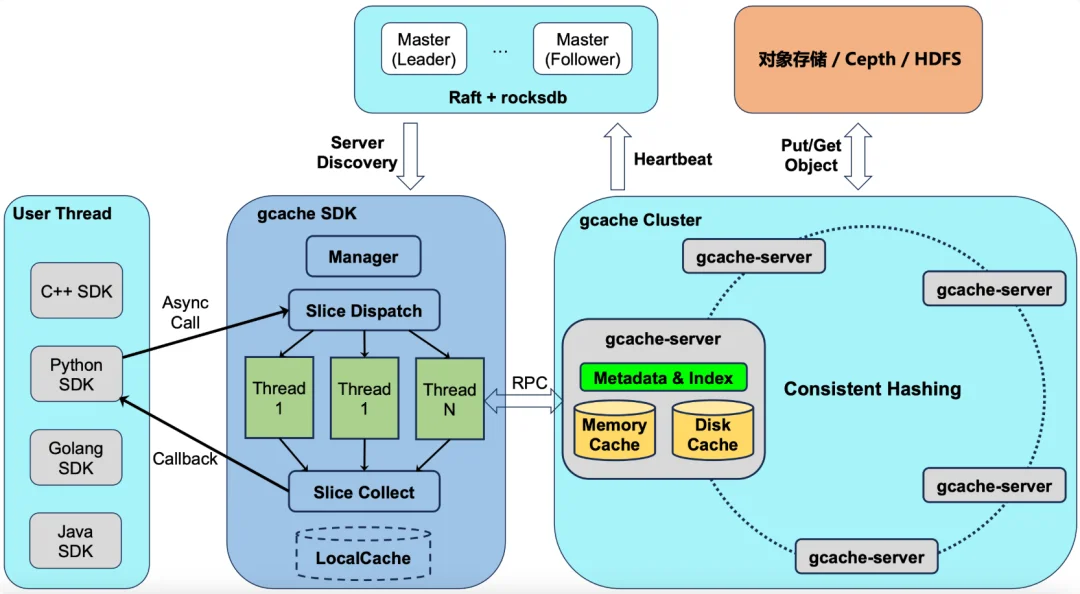
GCache是小米存储团队开发的高性能通用缓存,它是构建存储“训推一体”体系重要的一环,同时支持GPU显存、CPU内存和NVMe SSD的高性能分布式缓存系统。存储成本方面,GCache优先采用在GPU机器上混布的方式,接管了Prefill和Decode节点的部分内存,和机器自带的数块NVMe SSD,额外的存储成本为0。
得益于这些优化,小米研究人员观测到,在优质harness框架下,服务端KV Cache命中率平均可达93%;对于高强度、长周期使用的个人用户,该指标可达95%乃至更高。
在调度优化方面,小米希望通过匹配调度和计算链路,让省出来的显存空间和算力余量真正发挥作用。
在此基础上,小米开发了可动态扩展的无状态调度器LLM-Router,通过使用Redis作为中心化存储,避免单服务故障后的KV Cache调度回退现象,稳定保证缓存命中率。
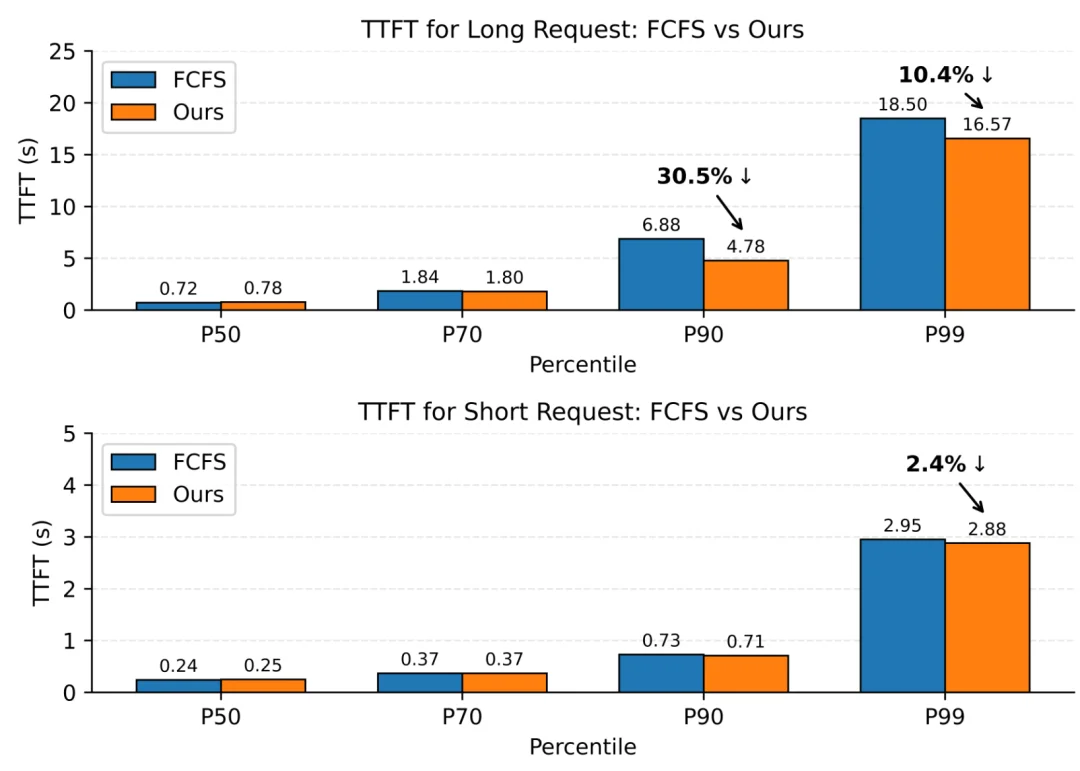
首先是KV Cache与负载亲和调度,由于HiCache对于L2的命中率非常敏感,如果L2没有命中,就需要去L3查找并拉取KV Cache,等待拉取结束后才能对该请求进行推理。Router中通过将分发过的请求维护在Radix前缀树中,实现了KV Cache亲和调度。在多个Prefill实例间优先选择已经缓存当前请求前缀的节点,并同时兼顾负载均衡来避免热点倾斜。
该策略上线后,将L2的缓存命中率提升了约25%,单机输入吞吐提升了约30%。同时其引入计算量感知优先调度,优先处理真实计算token数更少的请求,辅以等待时间惩罚机制避免饥饿,TTFT P90降低30%。
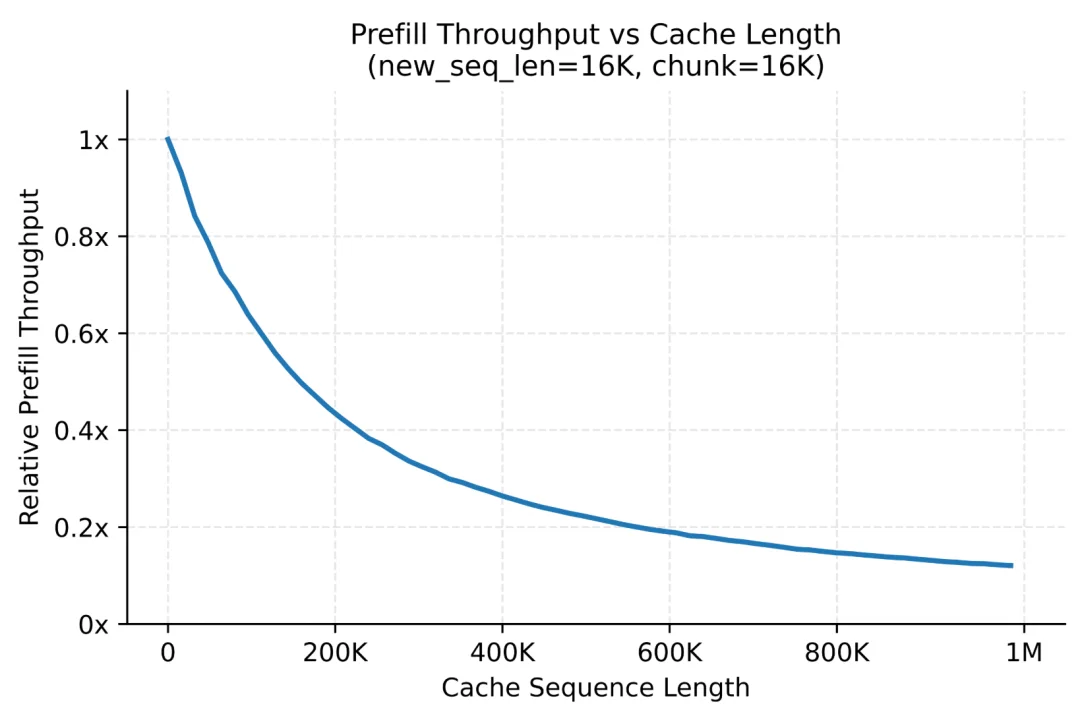
其次是关于Prefill链路本身的计算效率,早期SWA KV Cache需保存所有token的KV Cache,导致EP被迫偏大;优化后仅需保存SWA部分token,研究人员将EP缩减至原先的1/2,端到端性能提升约40%。
为缓解负载不均衡问题,研究人员还采用三级长度分桶策略(0–64K/64K–256K/256K–1M),将负载特征相近的请求聚合至同一桶内做计算,提升了线上prefill的平均吞吐。
MiMo-V2.5系列模型均采用MoE架构,还需要考虑prefill阶段的专家负载均衡问题。由于该模型在预训练阶段引入了负载均衡的训练目标、且训练较为稳定,模型在训练时已学习到较为均匀的专家分配策略。
推理阶段,在未启用任何专家负载均衡策略的条件下,各层平均专家负载度(一层中所有rank的平均token数与该层rank最大token数之比)约为0.85,处于较优分布水平。
Decode阶段的核心瓶颈是显存被KV Cache占满导致batch size无法扩展,GPU算力打不满。因此其进行了显存优化和MTP优化。
显存优化包括Decode KV Cache完整支持SWA,使得KV Cache有效容量提升近5倍;PD分离中KV Cache预分配优化,将尚未启动的请求的prealloc过程从GPU显存迁移至CPU内存,decode实际启动时才搬入显存,消除资源预占造成的浪费;CUDA Graph显存调优,能优化CUDA Graph参数减少空间浪费,使可用显存提升。
MiMo-V2.5系列模型原生支持3层MTP加速decode输出,其还在prefill阶段引入MTP支持并对HiCache L2/L3进行专项适配和优化,这使得decode前期MTP加速效果提升:第0–128 token加速比达2.3倍,第128–256 token加速比达1.5倍,降低了智能体场景下的真实decode成本。
最后是多模态推理优化。MiMo-V2.5系列支持视觉、音频、视频跨模态理解。
基于SGLang社区v0.5.7 EPD方案,小米研究人员围绕MiMo-V2.5做了大量EPD分离方面的工程优化与稳定性修复,在延时保持不变的情况下,将Encoder吞吐提升至2倍。

具体的优化包括Encoder支持跨请求组Batch,多个请求的image/audio融合为一次Forward再按请求切分返回;图片预处理迁移至GPU消除大图场景下CPU瓶颈;视频解码切分为多chunk多线程并行处理,1小时视频端到端延时从156秒降至23秒;通过一致性哈希和机内共享内存实现Embedding缓存共享,整体Encoder吞吐提升至2倍。
小米MiMo-V2.5系列API最高降幅99%,核心依托Hybrid SWA+MoE复合架构与全链路推理栈优化,实现了系统性的推理链路优化。此次,DeepSeek先将V4-Pro永久降价75%,小米五天后跟进MiMo-V2.5最高降99%,直接全面对齐。
这一轮价格战或加速业界大模型企业重新审视API定价体系,加速API服务转向普惠算力基础设施,为AI大规模产业化扫清成本障碍。
文章来自于"智东西",作者 "程茜"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
