# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

前两天我在做一个产品定价方案,问 Claude Code 有什么思路。
它给了我四个方向。但我看完之后觉得,这不就是我直接问豆包也能得出的答案嘛:
按用量分层(Free、Pro)、按用量计费、Token Plan、免费加广告。
这些回答如同教科书一般正确,但不是我想要的那种「还能这样?然后恍然大悟」的有些心意的答案。
有没有可能让 Claude Code 的输出不这么枯燥?
我做了几次尝试,比如改 Agent 的 md 文件,发现效果一般。
这个问题直到前几天,我突然找到了一个参考答案:
我在 Reddit 上看到一个帖子,标题是「I gave Claude Code ADHD.. and it thinks 2x better now」.
帖子的作者主要是做医疗 AI 安全研究,他通过 Skill 的方法把 ADHD 的思维塞进了 Claude Code,还为这个 Skill 写了篇论文。
前段时间,我同事写过一篇 ADHD 的文章我很喜欢:《ADHD,反而成了 AI 时代的版本答案?! 》
我虽然不是 ADHD,但我立刻想到一点:这个 Skill 能帮我把 Claude Code 变成 ADHD?那可太帅了。
于是我花了两个小时,把论文和代码都看了一遍。
看完之后我觉得,这个 Skill 在一些特定的场景真的很有价值。
先说一个我的判断:现在大模型最大的问题,不是幻觉和回答错误,而是回答得太「正确」了。
这种过于正确的原因是 LLM 的自回归生成机制:
它让每个 token 都是基于前文的条件概率分布采样出来的,虽然有 temperature 等随机性调节,但整体仍然被训练分布强烈约束。
这意味着:大模型写到第三句话的时候,前两句话已经把后面的方向锚定了。
《这就是 ChatGPT》
所以大模型最终输出的,永远是符合训练分布的常规「思考」,而不是真正有价值的「独特」想法(除非你的提示词非常独特,但这不符合大部分的对话方式)。
这在有标准答案的问题上完全没毛病:你问它快排怎么写,它给你写得又快又对。
但大部分问题是开放式的问题,大模型在这里就容易变得「平庸」。
比如当你做架构决策、思考方案这种问题时,这时候标准答案往往就是那个「平庸」的答案。
但真正有价值的方案,往往是「掌握在少数人手里」的「非常规化思考」。
而这,恰恰就是 ADHD 思维的舒适区:
跳过前三个显而易见的答案,在别人停下来的地方继续拐弯,这就是 ADHD 思维最擅长的事。
ADHD 这个 Skill 的核心设计,我把它概括成三点。
第一,五个独立的 Agent。
它不是让一个 AI 想五次,而是开五个完全独立的 LLM 调用,每个调用之间没有任何共享上下文。
Agent A 里的想法,在 Agent B 里根本看不到。上下文直接被物理隔离掉了,所以这就不是靠 Prompt 说「请忽略之前的想法」或者通过上下文的压缩来「减少上下文」,而是根本没有「之前的想法」这个东西存在。
这和 Anthropic 在 Harness 工程里推荐的做法类似:他们认为长任务应该把上下文直接重置,避免上下文压缩影响任务效果。

《harness-design-long-running-apps》
第二,认知框架驱动。
每个 Agent 被分配一个完全不同的「思考角色」。
比如「你是一个监管者,审计这个系统的合规性和失败模式」、「你是一个十岁小孩,从没见过软件,用最天真的方式重新想这个问题」。

论文里有 15 个这样的框架,ADHD 在跑的时候每次会选五个:目的不是让它们各自「正确」,而是让它们各自「不同」。
这样就强制让每个 Agent 只能从一个特定视角出发思考,模拟出 ADHD 式的多线程认知。
第三,生成和批评的流程分离。
这是我觉得最精妙的设计:
- 发散阶段,系统提示明确写着「你是生成器不是批评者,禁止评价、禁止排序、禁止对冲」。
- 收敛阶段,换一个完全不同的 LLM 调用,系统提示变成「你现在是批评者,对抗性阅读,打分,找陷阱」。
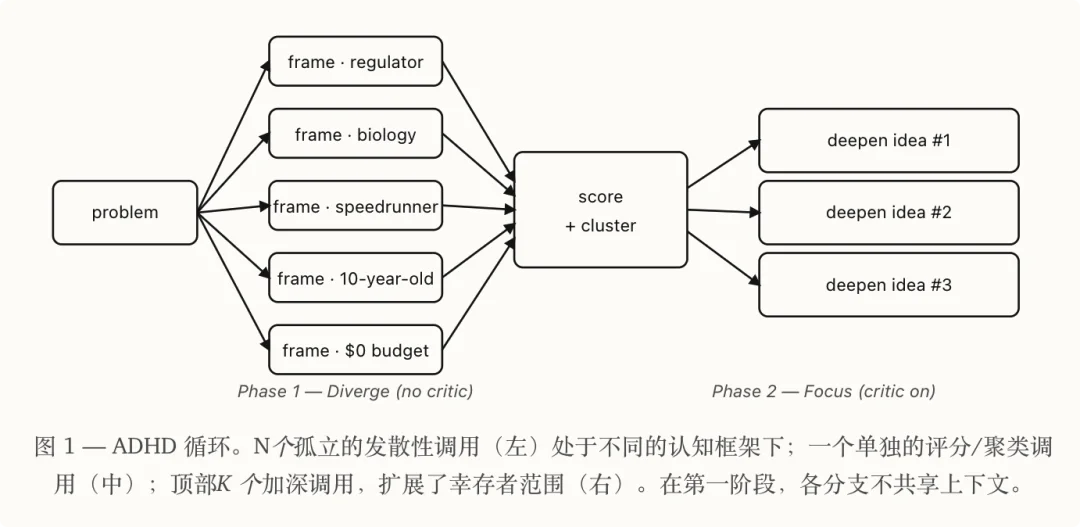
这两个角色,用的是不同的调用、不同的 system prompt、不同的输出格式。
为什么这很重要?因为创造力和判断力同时运作的时候,创造力就发挥不出来能力。
就像一个人在写文章初稿的时候同时在改稿,结果就是什么都写不出来,LLM 也一样。
所以,通过这样的分阶段设计,ADHD Skill 就可以实现:
发散阶段,根据问题从五个独立视角「多线程思考」
收敛阶段,用一个线程负责「整合思考」,最后,给出一个「非常规」的答案。
我用 ADHD 的 Skill 跑了两个真实的问题。
第一个是 SaaS 定价。
这个背景是,我一个朋友做了一个面向中小企业的团队协作工具,大概 5000 用户,需要设计定价模型。
然后他们团队内部讨论了很久,不知道怎么定。
于是,他找我做设计定价方案,我就用了这个 Skill 在 Claude Code 跑了一下:
结果 ADHD 选了五个框架:市场机制、游戏设计师、反向思考、十岁小孩、竞争对手视角。

跑完之后它给出了 30 个想法,聚类成了五个大方向。
让我真正愣了一下的是,它最终提出一个叫「反熵定价」的东西:团队的知识库越完善,月账单越低。
具体来说就是,知识库里的文档覆盖率高了、重复问题减少了,折扣就自动出来。
这个想法好在哪?它把「付费」变成了产品价值的一部分。用户为了省钱会主动完善知识库,而知识库越完善切换成本越高。留存率和产品质量形成正循环。
说实话,我在看到它之前,最多只能想到按照文档 API 付费这一层。
而按他这个方向,千人千面,每个人的付费逻辑不一样,这种定价逻辑,我想到没想过。

第二个问题是给一个 Agent 产品想一个名字。
我最近想给面向一人公司,做个 Agent 工具,但是起名字不知道怎么起。
然后我就用了这个 Skill 跑了一下:
于是五个框架,选了反向思维、市场定位、竞争者视角、天真直觉、生物隐喻。

最终推荐排第一的叫 Quorum:
它把一人公司重新定义成「一组达到协调共识阈值的智能体集合」,还是蛮有叙事张力的。

这个名字从「生物学」框架冒出来的,然后收敛阶段被打了高分。
这种跨框架的碰撞,很难靠单一视角想出来。
当然,这两个案例还不够严谨,ADHD 真的足够有效吗?
作者自己也做了更系统的验证,甚至写了篇论文:《ADHD: Parallel Divergent Ideation for Coding Agents》

论文里用 6 个开放式工程问题做了测评:ADHD 对比同模型的单次回答,5 胜 1 负。
他的测评结果是,ADHD 让整个方案的新颖性提升 5.17,广度提升 4.17。
如果从传统提示词工程的角度,可以这样理解这个思想:
ADHD 改变的是 AI 的思考逻辑,让我们在调用模型时,直接改变模型输出的结构。
你可能会说,CoT(思维链)不是让 AI 想得更深了吗?ToT(思维树)不是让它搜得更广了吗?
没错。
但 CoT 是让一个脑子沿着一条路想得更慢更仔细,它依然是一条线。ToT 是让同一个脑子在分叉点尝试不同的下一步,但分支之间共享上下文,写到第四步的时候前三步的上下文依然在。
所以无论大模型想得再深、搜得再广,都不能解决「角度本身就没换过」这个问题。

理解了这个区别之后,我们可以思考一个更大的问题:
当模型能力和框架趋同之后,下一个差异化的维度是什么?
我认为是推理时工程:在调用模型的那一刻,你怎么组织调用、怎么隔离上下文、怎么分配角色、怎么安排生成和评估的时序。
一个例子就是最近 Claude Code 推出的蜂群模式(Agent Teams):让多个 AI 并行协作成为可能,最多支持 20 个子 Agents 同时跑。
ADHD Skill 也是这个方向的一个具体实现:
它不改模型权重,不做微调,纯粹在推理时用调用编排的方式,改变 Agent 输出的多样性和质量。
如果你想试试,安装只需要一行命令:npm install -g adhd-agent
对于那些每天都在做架构决策、产品定位、技术选型的人来说,这可能是目前性价比最高的「第二大脑扩展」:
让它学会像一个版本最强的 ADHD 一样,用不同的角度深度思考一个问题。
文章来自于"特工宇宙",作者 "特工小花 特工小饼"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
