# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

“AI新物种”企业级Token生产平台TokenBox™。
大模型越跑越快,企业本地部署AI的难题也被进一步放大。
一边,DeepSeek V4这类大参数模型已经成为企业关注的焦点,1.6T参数规模对显存、算力和GPU互联提出了更高要求;另一边,DeepSeek、千问Qwen、智谱GLM等开源模型持续迭代,企业刚把上一版模型部署完成,新版本又已经发布。
而本地AI部署,并不是“买台机器、装个模型”这么简单。
模型真正跑起来之后,企业还要面对推理性能优化、GPU利用率提升、运行监控、故障定位和版本更新等一系列问题。
这些看似分散的环节,最终都会落到同一个核心指标上:Token产出效率。
比如,GPU利用率不高,会直接影响单位算力能够生成多少Token;KV Cache优化不到位,会拖慢模型生成速度;并发调度不合理,则可能导致高峰期响应延迟甚至服务卡顿。
模型版本更新慢,还意味着企业即便买了同样的硬件,实际Token生产能力也可能很快落后于行业平均水平。
云端AI服务可以把这些工作藏在后台,但背后的API成本难以承担,数据安全让人担忧;本地部署则意味着企业需要自己负责这些复杂环节。对于缺少AI运维团队的公司来说,算力买回来了,Token能不能稳定、高效地产出,依然是一笔难算的账。
面对这种行业共性难题,本地化部署成为必须,同时市场急需一种全新的解法:它需要像数据中心一样强悍,具备极致的Token产出效率,又无需专业数据中心的投资建设和运维投入成本。
在近日举办的超聚变2026探索者大会算力高峰论坛上,一个被称为“AI新物种”的解法正式亮相——超聚变推出了软硬一体、可扩展、可演进、开箱即用的企业级Token生产平台TokenBox™。

TokenBox™将数据中心级超节点能力、液冷静音、PCIe Fabric Gen6高速互联、Pack模块化扩展,以及数据中心的FusionOne AI软件平台,整合进同一套本地AI方案中。
在企业AI投入持续升高的阶段,TokenBox™试图回答一个问题:企业怎样在办公室里部署一套能跑大模型、能持续升级、还能支撑多人并发使用的本地AI系统。
过去几年,企业采购AI基础设施时,更关注的是GPU型号、FLOPS和显存规模。
但随着AI Coding、数字员工、企业知识库和智能体应用逐渐进入业务流程,企业真正开始消耗的,已经变成源源不断的Token。Token成为新的成本中心,Agent是新的利润中心,只有真正被业务消费的高质量Token,才能转化为实际价值。
而每一次调用、每一次推理、每一次Agent执行,背后都会持续消耗推理资源。
这意味着,企业买GPU只是起点。后续GPU利用率、推理时延、并发调用能力以及长期运维成本,都会直接影响AI投入回报。
超聚变敏锐地捕捉到了这一痛点,并提出:Token Factory是企业AI应用的关键承载平台,是帮助企业把AI从概念验证真正转化为持续生产力的重要基础。每家都应该有自己的Token工厂。
在“FLOPS-TOKENS-AGENT-VALUES”这条全新的价值链中,TokenBox™承担的就是算力向Token高效转化的关键节点。
它不仅仅是一个物理盒子,而是围绕Token产出效率进行了一套系统级重构。
针对推理效率,TokenBox™在CXL,PCIe Fabric等创新硬件加速技术之上,协同自研KV缓存卸载,智能稀疏等推理加速引擎技术,实现针对性软硬协同优化,推理性能相较于普通开源方案有显著提升。
在企业本地部署场景里,这类优化会直接影响Token产出效率。
因为很多企业虽然为100%的GPU算力买单,但实际业务里的Token产出效率可能不足40%。实验室里的模型跑分,与真实业务现场之间,依然存在明显落差。
某种程度上,企业之间未来的AI差距,或许不只是GPU数量的差距,而是谁能更稳定、更高效地把Token转化成真实业务能力。
算力的转化效率解决了,承载算力的物理形态同样需要跃迁。
企业想在本地跑DeepSeek V4这种1.6T规模的大参数模型,过去往往陷入两难:普通的办公工作站算力、显存和互联带宽根本扛不住;而数据中心的AI服务器性能虽强,但对机房、供电、散热和噪音的苛刻要求,让普通企业望而却步。
正是出于这种两难处境,很多企业虽然想做本地AI部署,但真正落地时仍会卡在环境条件与长期运维成本上。
TokenBox™填补的正是办公场景高算力的缺口,为了实现这一目标,TokenBox™在硬件架构上进行了几项关键突破:

1、满血版算力支撑:具备T级显存和10P以上的AI算力,可支撑DeepSeek V4满血版1.6T参数模型的高效运行。
2、图书馆级静音:采用DC级冷热部署设计与先进的液冷整机散热体系,在主流业务负载下噪音可低至35dB(图书馆级别)。

3、Pack模块化架构:由GPack、CPack、MPack、SPack构成可进化的平台架构。TokenBox™从一开始就不是一台边界固定的设备,而是一个可以持续进化的Pack平台。围绕GPU、CPU、内存、存储等核心能力模块,企业可根据业务需求灵活扩展,让AI基础设施从一次性建设走向长期演进,把当前投入沉淀为可持续增长的平台能力。无论是GPU、CPU,还是内存、存储资源,企业都可以像搭积木一样按需灵活扩展。

4、TokenFabric™极限互联:超聚变与博通联合打造了全球首款PCIe Fabric Gen6产品TokenFabric™,支持从4卡到128卡的全互联扩展。GPU之间通过高速互联直接通信,彻底绕开传统CPU中转带来的延迟损耗。

为了更直观地理解其架构,这里附上一图读懂TokenBox™的核心逻辑:


除了算力本身,本地AI部署还有另一个现实问题:模型更新太快。
过去一年里,DeepSeek、千问Qwen等开源模型迭代频率明显提升。很多企业刚把上一版模型部署完成,新版本已经发布。对于本地部署环境来说,更麻烦的是后续的推理服务适配、版本兼容和运维更新。
有技术人员透露,部分模型更新之后,行业里的硬件与推理服务适配周期可能长达数周甚至更久。TokenBox™给出的解法是——ModelEver模型永新能力。它能为TokenBox™用户提供模型永新的贴身保障,能力覆盖模型全周期。
其核心理念是借助高度的工程化和产品化能力、领先的架构、专业的本地服务、强大的平台支撑和大量政企客户和互联网客户项目交付经验,帮助用户降低模型适配与升级成本,缩短上线周期,让企业无需投入大量技术资源,即可轻松实现大模型的持续更新与优化,充分释放AI生产力价值。
具体地讲就是:新模型一经发布,在超聚变AI Lab实验室便会完成模型的预验证、预集成工作,TokenBox™用户可第一时间获取到精选的模型及其配套工具镜像,实现新模型的第一时间获取、可视化部署、可视化评测和平滑升级,让用户第一时间享受新模型带来的生产力提升。
同时,对于已有模型的更新,企业也通过简单的软件界面就能完成升级,让推理服务永远与最新模型版本保持同步。
TokenBox™从硬件架构到软件栈均围绕“Token生产”来设计,主打开箱即用、部署即生产。
它预置模型管理平台和应用市场(FusionXplay),覆盖从模型推荐、获取、部署、升级、全周期管理、优化加速等多个环节。
其将复杂的底层适配、版本管理和运维工作前置封装,为本地AI提供一套可持续演进的“应用商店”,下载即用。
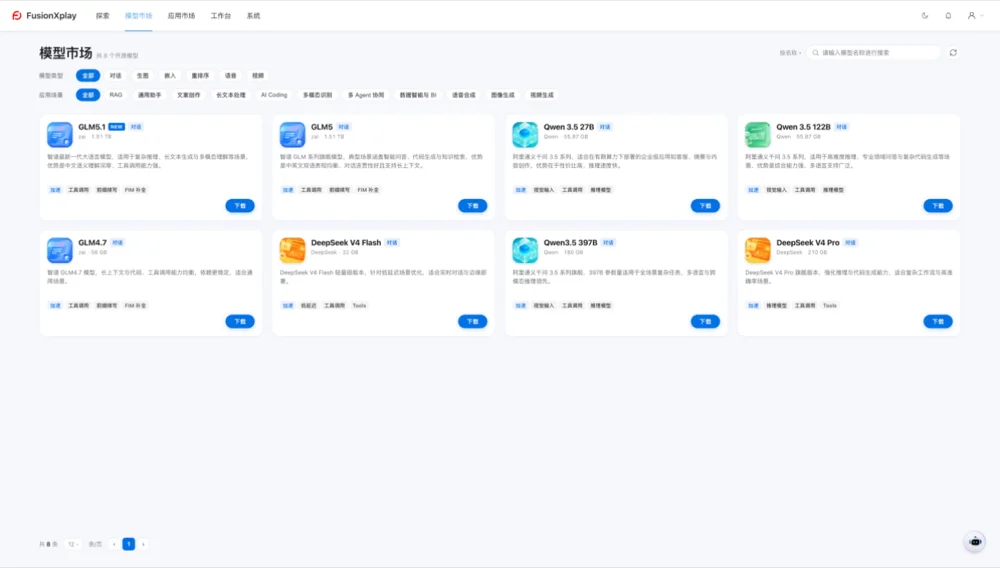
企业可以在本地环境中像下载App一样选择模型、安装应用,龙虾(Openclaw的昵称)、爱马仕(Hermes的昵称)等智能体的选择也能实现随心切换、一键部署。
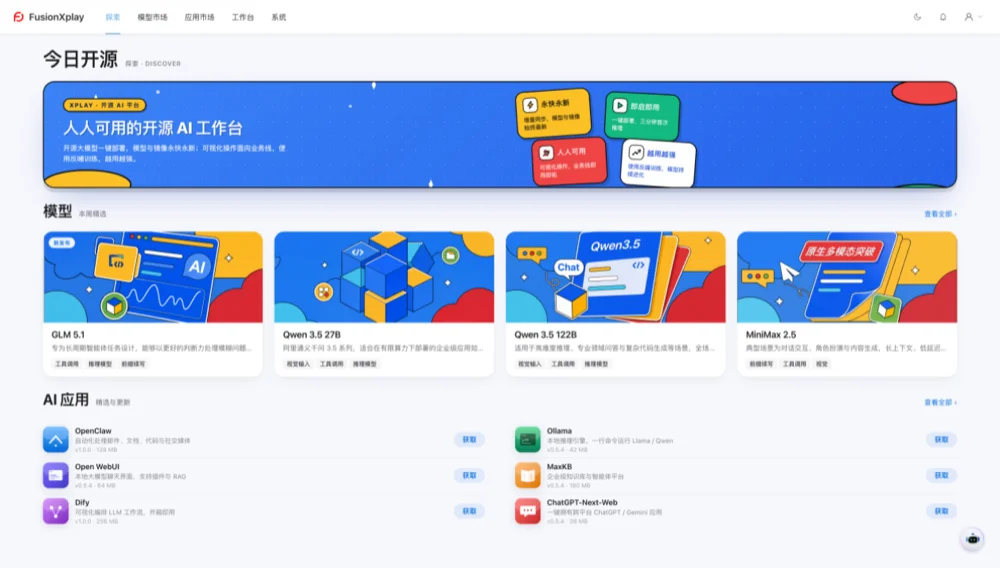
此外,为了进一步降低长期运维成本,TokenBox™还引入了手机端原生AI交互以及从模型到卡全栈资源可视能力,也提供液晶屏、桌面管理端等多入口管理方式,可实时查看Token吞吐、并发任务、GPU利用率和显存占用等运行状态,支持拓扑定位故障根因,其运维体系可将运营成本降低80%显著降低运营成本。
TokenBox™也支持PC端、PAD端和移动端等多端访问。

过去,企业做本地AI部署时,市场里的主流选择并不多:要么是工作站,要么是数据中心服务器。
前者部署方便,但算力、显存和扩展能力有限;后者性能更强,却对机房、供电、散热和长期维护都有更高要求。
随着DeepSeek V4这类大参数模型出现,企业对于本地AI系统的要求也开始变化。很多企业既希望能在办公室环境里直接部署,又希望系统可以持续升级、支持多人并发,并长期稳定运行。
TokenBox™代表的,正是一种新的本地AI基础设施形态。
它尝试把高性能硬件、模型适配、推理加速、应用管理和运维交互,进一步整合进同一套产品里,缩短企业从“买算力”到“真正用上AI”之间的距离。
而随着AI Agent、AI Coding和企业知识库持续增加,企业内部对于推理服务、Token吞吐和长期稳定运行的需求,也会越来越高。
未来企业之间的AI竞争,或许不只是模型能力的竞争,也会变成谁能更稳定、更低成本地生产和调度Token。
文章来自于"智东西",作者 "江宇"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
