# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去半年,几乎所有Agent框架都在补长期记忆能力。最常见的做法,是给系统接一个向量数据库,把历史对话、用户偏好、项目经验、工具调用结果、失败案例都存进去。看起来,只要把“记忆”这块补上,Agent就能从一次性对话工具变成长期协作伙伴。
但问题是,长期记忆并不等于“把历史塞进向量库”。
压缩可能丢掉条件,存储可能覆盖共存事实,检索可能找回语义相似但上下文错误的内容。最终表现出来,就是Agent明明有记忆,却依然答错、乱用、误用,甚至越记越混乱。

UC Berkeley最近的一项工作《MemFail: Stress-Testing Failure Modes of LLM Memory Systems》试图把这个问题工程化:把长期记忆系统拆成压缩、存储、检索三个基本操作,再分别测试它们在什么情况下会丢条件、漏事实、错检索,或者把正确记忆用到错误场景里。

研究者首先构建了一个形式化框架。在这个框架中,任何外部记忆系统都可以被拆解为三个标准操作。

基于这种标准化的操作分类,研究者推导出了任何现代记忆系统都可能存在的四类失败模式:

为了精准地触发上述失败模式,MEMFAIL精心构建了包含5个数据集的4项对抗性任务。每一项任务都像一把手术刀,专门切入记忆系统的特定操作环节。





为了能够公允且自动化地对各类底层架构迥异的记忆系统进行打分,研究者设计了一套通用的自动化评估链路。
这套框架只要求待测系统暴露三个基础接口:存储对话、检索记忆、获取所有记忆。整个测试循环划分为三个阶段:

MemFail选取了目前学术界和工业界最先进的四个开源记忆系统架构,它们的内部操作机制截然不同:


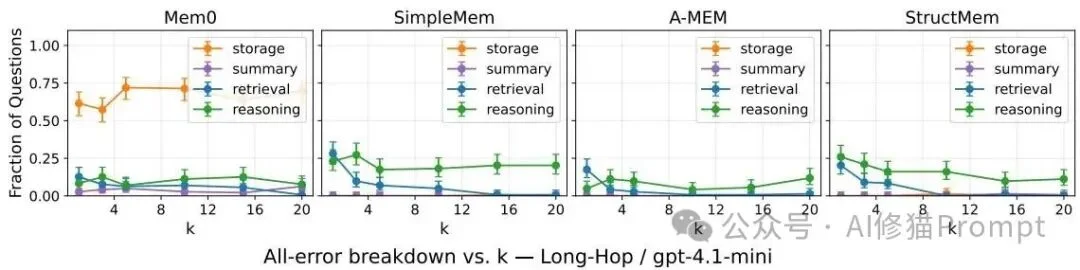
通过对四款前沿系统的大规模摸底,MEMFAIL揭示出了一系列传统聚合评测无法触及的系统级特征。

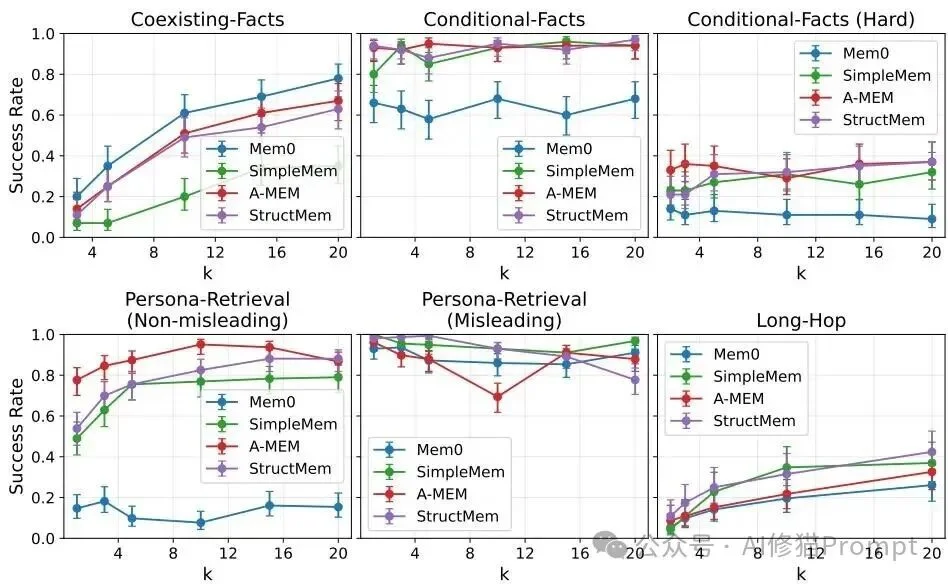
在常规的智能体开发经验中,把底层的推理模型升级为参数量更大、更聪明的模型,往往能立竿见影地提高Benchmark分数。
然而在记忆系统领域,规律失效了。研究者尝试将系统的内部驱动模型进行升级后发现:
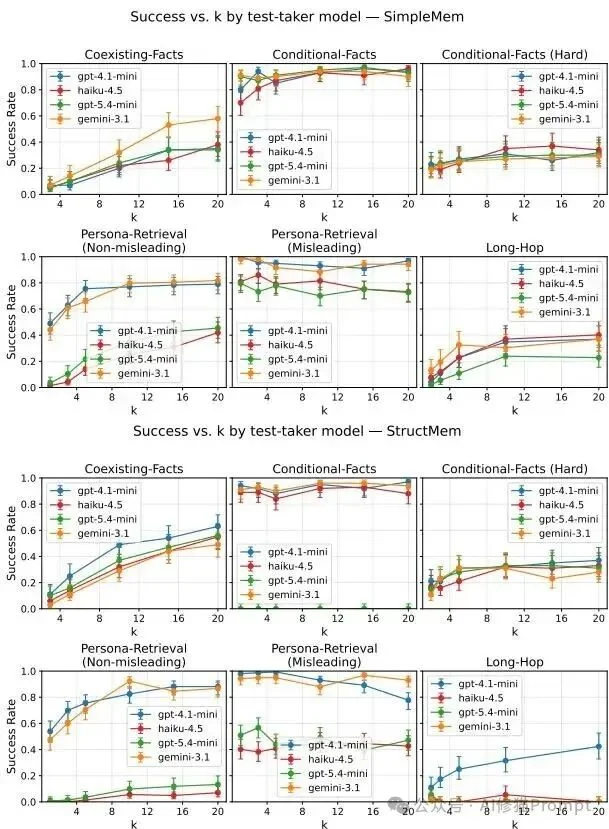
增加Token消耗换取准确度,一直被视为一种稳妥的扩频手段。但MEMFAIL揭示了其在记忆存储上的权衡关系具有高度的“任务特异性”。
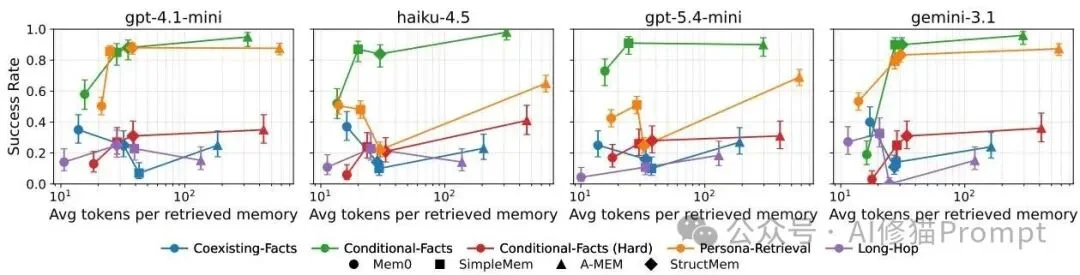
测试结果清晰地表明,没有哪一款单一架构能够在所有任务中取得全面统治。底层的架构选择,从一开始就锁定了该系统易受攻击的失败弱点。
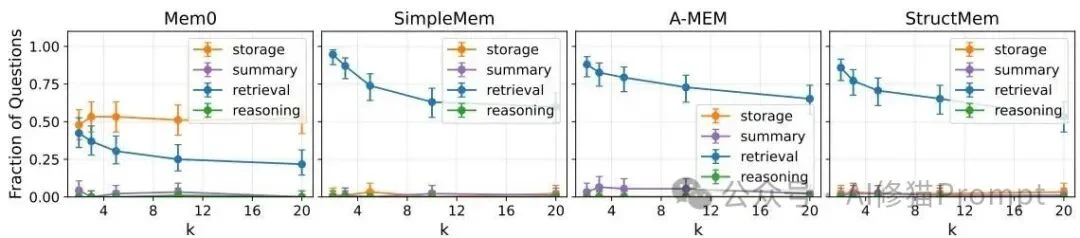
基于从MEMFAIL中淬炼出的海量失败样本,研究者为下一代无死角记忆系统的开发指出了两个极具潜力的研究方向。
当前业界的研发思路大多局限于一种底层存储逻辑死磕到底(要么全用向量,要么全推图数据库,要么全做层级树)。
既然不同的架构在对应的任务上具备绝对优势,未来的记忆体系统完全可以迈向“混合路由”时代。
目前的系统在生成记忆条目时,往往采用固定长度的提示词模板进行无差别输出,这导致了严重的资源错配。
《MemFail》的推出,标志着大模型长效记忆领域的测试方法迎来了从“黑盒评分”到“白盒诊断”的进阶。它以极具针对性的任务设计,无情地扒开了现阶段所谓“智能记忆系统”底层的架构短板。
通过详实的数据证实,单纯依赖大模型智力的提升或无脑放大召回阈值,根本无法修补由系统底层架构引发的深层失败模式。通过全面开源其评估标准与代码套件,MEMFAIL正在为下一阶段构建真正健壮、灵活且无死角的大语言模型长期记忆基础设施,提供最核心的校验准绳。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
