# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在前面几篇文章中,聊了下我们为什么要构建 Vector Lakebase:背后的行业变化、现有 AI 数据架构的局限,以及向量数据库在Vector Lakebase承担新的角色。
这篇文章想回答几个大家更关心的基础问题:Vector Lakebase 能解决你的什么问题,什么场景下用它最合适,如何用好Vector Lakebase 。
最近在我们推出了vector lakebase之后,有很多朋友关心它到底是什么?与向量数据库的关系是什么?以及我们还做不做向量数据库了?
首先,我们还依然在重点投入向量数据库。Milvus 和 Zilliz Cloud,也始终是在线场景下生产级向量搜索的最优解,是RAG、AI agent 、电商推荐 等场景中的核心infra设施。
但我们同时也发现,高效的在线语义检索,不再是AI时代数据处理的唯一诉求。
我们还需要围绕同一份数据做训练集去重和聚类、异常与漂移检测、模型变化后的重新 embedding、治理和 lineage,以及来自生产行为的反馈分析。
大多数技术栈会把这些流程拆成不同系统:数据湖存原始文件,向量数据库做在线检索,批处理 pipeline 做预处理,embedding 和索引由单独任务构建。结果是数据被反复复制,索引被重复构建,在线服务和离线发现逐渐不再同步。
这给现有架构带来了几个问题:
所以我们推出了Vector Lakebase ,它是一种面向 AI 数据的统一湖原生架构。它结合了向量数据库级别的在线服务能力,以及开放湖存储、可复用的湖级索引,以及共享语义层。
而Vector Lakebase 的目标,就是把以上提到的断裂的系统重新连接起来。它保留向量数据库擅长的低延迟检索能力,同时把这条在线路径连接到一个湖原生的数据基础上。在这个基础上,数据、向量、索引、元数据和语义上下文都可以被存储、治理、版本化、复用,并随着时间持续改进。最终让同一份非结构化数据可以同时支撑在线 AI 应用、交互式数据发现和离线分析的问题。
Vector Lakebase 适合那些在大规模非结构化和多模态数据上构建 AI 应用或 AI 数据工作流的组织。常见使用场景包括 RAG、AI memory、agentic search、多模态语义检索、特征工程、context engineering、训练数据探索,以及非结构化数据预处理。
有大量长尾数据的检索增强生成(RAG)将文档、知识库、网页、代码、工单和日志转化为可检索上下文,并根据访问频率、时效性和成本要求进行冷热分层。热数据用于低延迟召回,冷数据保留在湖中用于长期知识沉淀和批量重建。
Feature Engineering 与 Context Engineering从非结构化数据中抽取语义特征、实体关系、标签、摘要和上下文片段,为模型训练、检索排序、RAG 编排和智能体决策提供高质量输入。
训练数据探查在大规模样本和多模态数据中发现主题分布、覆盖缺口、重复样本、异常样本和潜在偏差,为训练集构建、数据筛选和模型评测提供依据。
非结构化数据预处理使用语义表示识别重复、近似重复、主题簇和离群样本,帮助企业清理大规模文档、图片、日志、对话和多媒体数据。
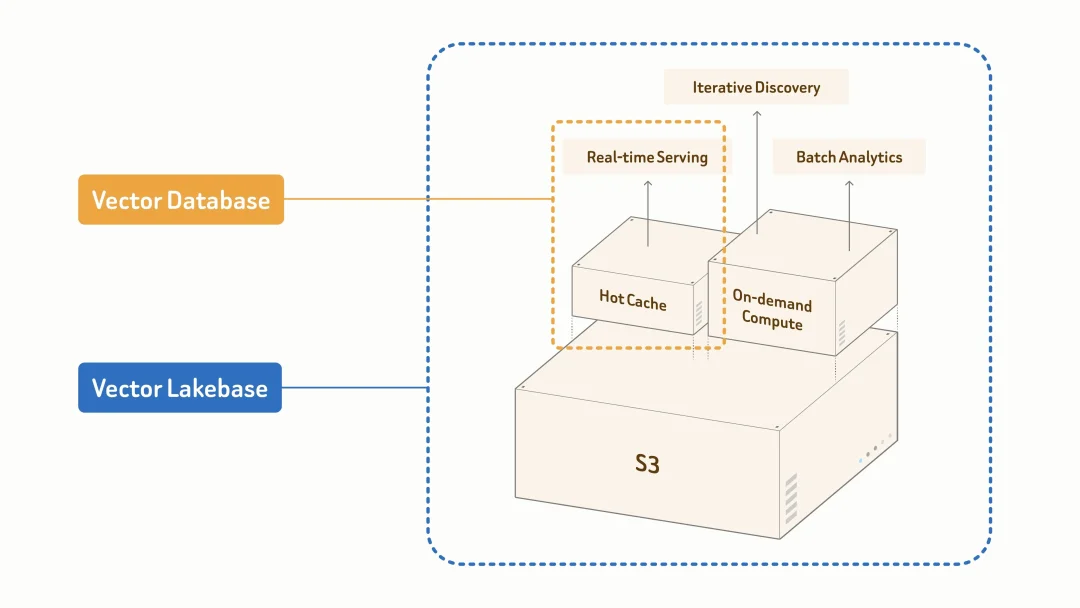
Vector Lakebase 的设计可以概括为三个原则:One Data、One Index、One Semantic Layer。

One Data 指的是以开放湖存储作为数据的唯一事实来源。原始数据、清洗后的数据、向量、标量字段、元信息、索引产物、语义标签和数据血缘都沉淀在同一数据底座中。
在这个架构中,向量数据库不是新的数据孤岛,而是低延迟服务路径的一部分。原数据仍保留在湖上,在线系统可以按需缓存热点数据和索引。这样可以减少重复存储、重复治理和跨系统迁移,让同一份数据同时服务在线应用、离线处理、模型训练和数据治理。
One Index 指的是索引不再只属于某个在线引擎,而是成为可以在湖上构建、版本化、复用和分层服务的数据资产。
同一个索引可以根据访问模式和成本要求映射为不同服务形态:热数据使用高效索引用于毫秒级在线检索,温数据通过磁盘缓存或分层存储服务访问,冷数据保留在湖中用于探索、治理和离线分析。
One Semantic Layer 指的是在数据和索引之上构建统一的语义层。它管理的不只是 embedding,还包括实体、标签、摘要、主题、上下文片段、数据来源、模型版本、权限和反馈信号。
这一层让企业可以按语义组织非结构化数据。RAG 可以从语义层获取可信上下文;agent 可以理解历史任务和工具调用结果;训练数据流程可以发现样本覆盖、偏差和异常;治理系统可以追踪某个答案、特征或样本来自哪些源数据。
语义层也是数据飞轮的核心。在线应用产生的查询、点击、引用和反馈会反哺语义层;离线处理产出的聚类、标签、特征和索引版本又会提升在线服务效果。
Vector Lakebase可以 在 serving 和 discovery 之间形成一个持续循环。我们将其称为 CS/CD,也就是 Continuous Serving 和 Continuous Discovery。
Serving 会产生反馈和新数据;discovery 会把这些反馈信号转化为更干净的数据和更好的索引;这些改进再回到 serving 中。
从操作流程看,这个循环包含四个阶段:数据导入、向量化与增强、查询服务,以及离线处理。
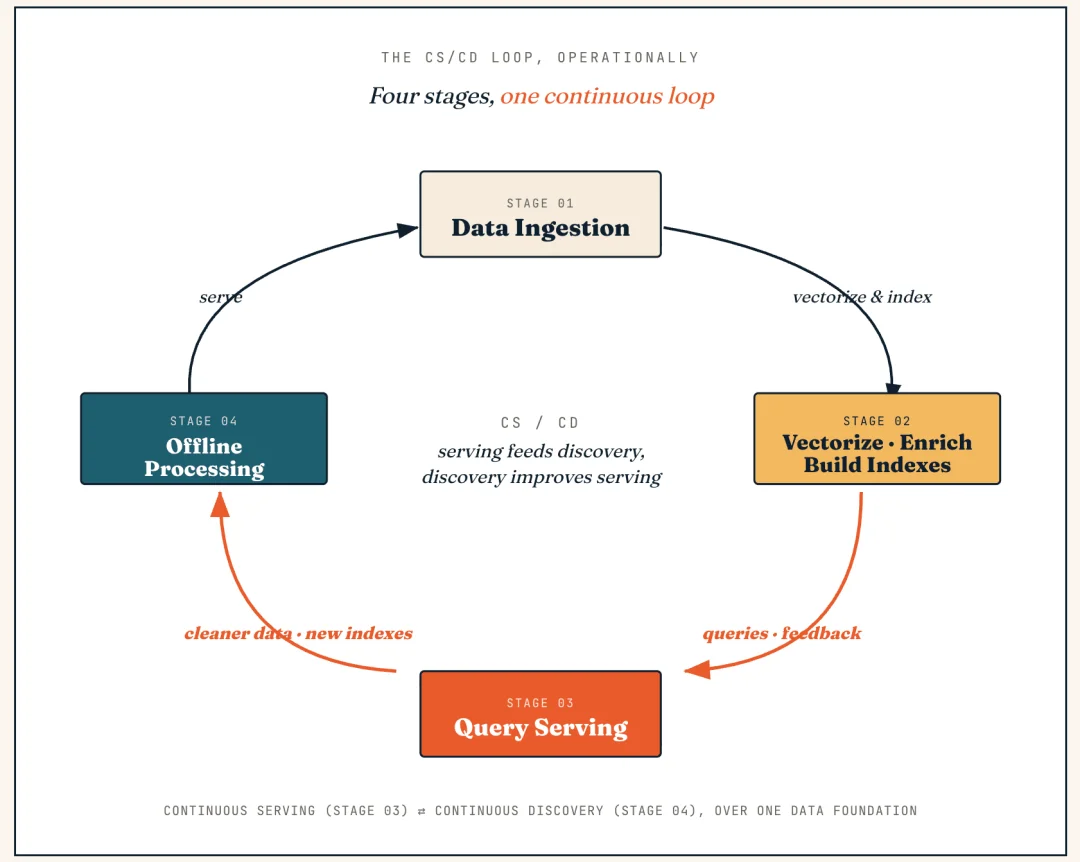
企业可以通过向量数据库写入或导入文档、向量、标量字段和业务元信息,也可以通过开放湖格式接入湖上已有数据。随着非结构化数据规模增长,数据也可以从对象存储源头进入清洗、治理和向量化流程。
系统使用模型和数据处理任务生成向量表示,并补充实体、标签、摘要、主题、来源、权限等元信息。随后,Vector Lakebase 在湖上构建和管理向量索引、关键词索引、全文索引和其他查询结构,使索引可以独立于在线服务引擎进行版本化和发布。
Vector Lakebase 面向 RAG、Agentic Search、Semantic Search 和多模态检索提供统一接口。查询路径可以直接访问湖上数据和索引,也可以通过向量数据库或缓存层服务热点数据。查询能力包括向量检索、关键词检索、过滤、全文搜索和混合排序。
离线处理包括聚类、去重、异常识别、数据质量分析、训练数据探查和 Schema Evolution。处理结果会重新写回湖存储、索引体系和语义层,持续提升在线服务和离线数据生产质量。
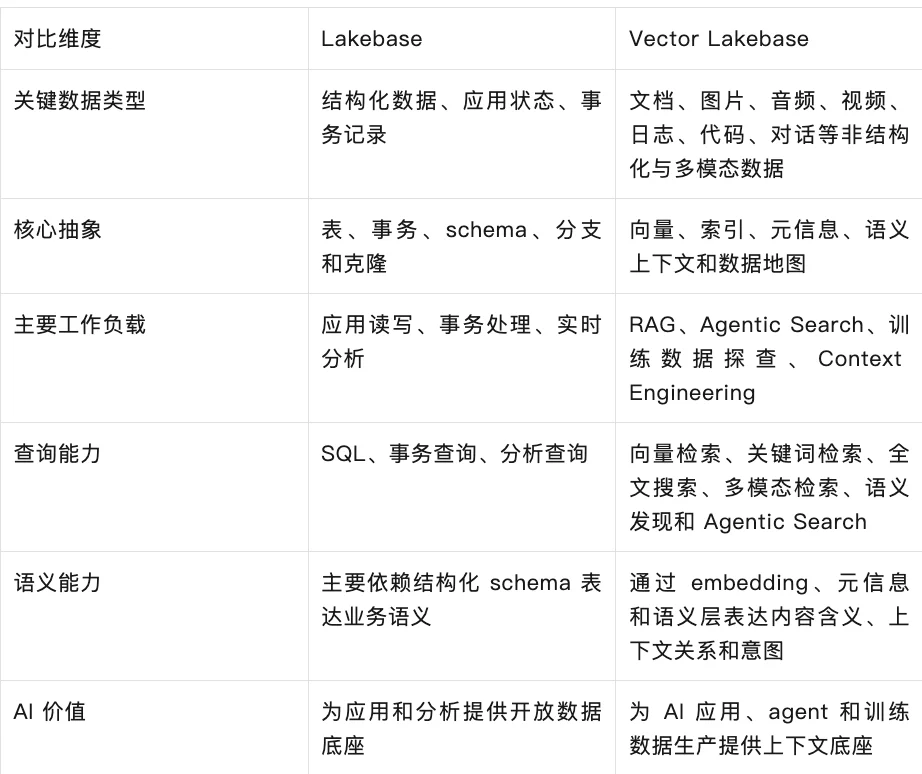
Vector Lakebase 可以看作 Lakebase 架构在非结构化数据、向量索引和 AI 语义上下文场景中的扩展。它也可以看作向量数据库能力向湖上数据底座演进后的结果。
Lakebase 把应用数据库能力带到湖上,重点是结构化应用数据、事务处理、弹性计算和开放存储。Vector Lakebase 则把这些思想扩展到非结构化数据和 AI 上下文,重点是语义层、多模态数据、Agentic Search,以及 Serving + Discovery 的统一。
Vector Lakebase 并不是简单替代向量数据库。向量数据库仍然是低延迟在线检索的重要组件,但在 Vector Lakebase 中,它更像 serving cache 或查询引擎,而不是数据和索引的唯一归宿。
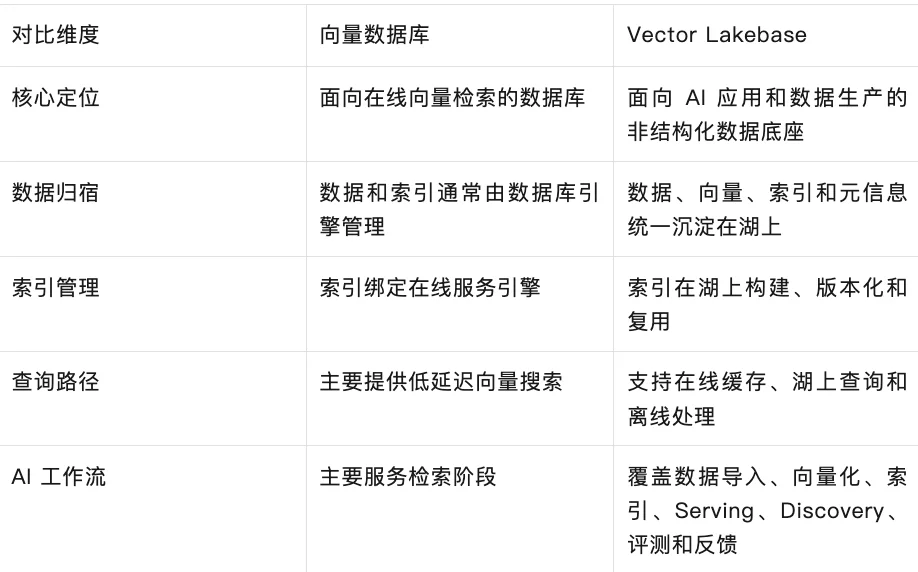
如果企业只需要为单一应用提供低延迟向量搜索,向量数据库已经足够。如果企业需要在海量非结构化数据、多团队、多模型和多应用之间复用数据、索引和语义上下文,并且需要治理、成本优化和开放架构,那么 Vector Lakebase 更适合作为长期数据底座。
所有现代企业都会逐步转向 AI 原生数据架构。Vector Lakebase的可以以开放湖存储作为数据底座,以湖上索引统一检索资产,以 AI 原生语义层组织上下文,并通过弹性计算同时服务在线应用和离线数据生产。
它不会取代数据湖,而是会扩展数据湖的能力,使其支持语义发现、上下文关联和智能自动化。
一句话概括:Vector Lakebase 是面向 AI 原生应用的 Lakebase,它让企业不仅能保存非结构化数据,还能理解数据、发现上下文,并持续把上下文服务给应用、智能体和模型训练流程。
文章来自于"Zilliz",作者 "Zilliz"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
