# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
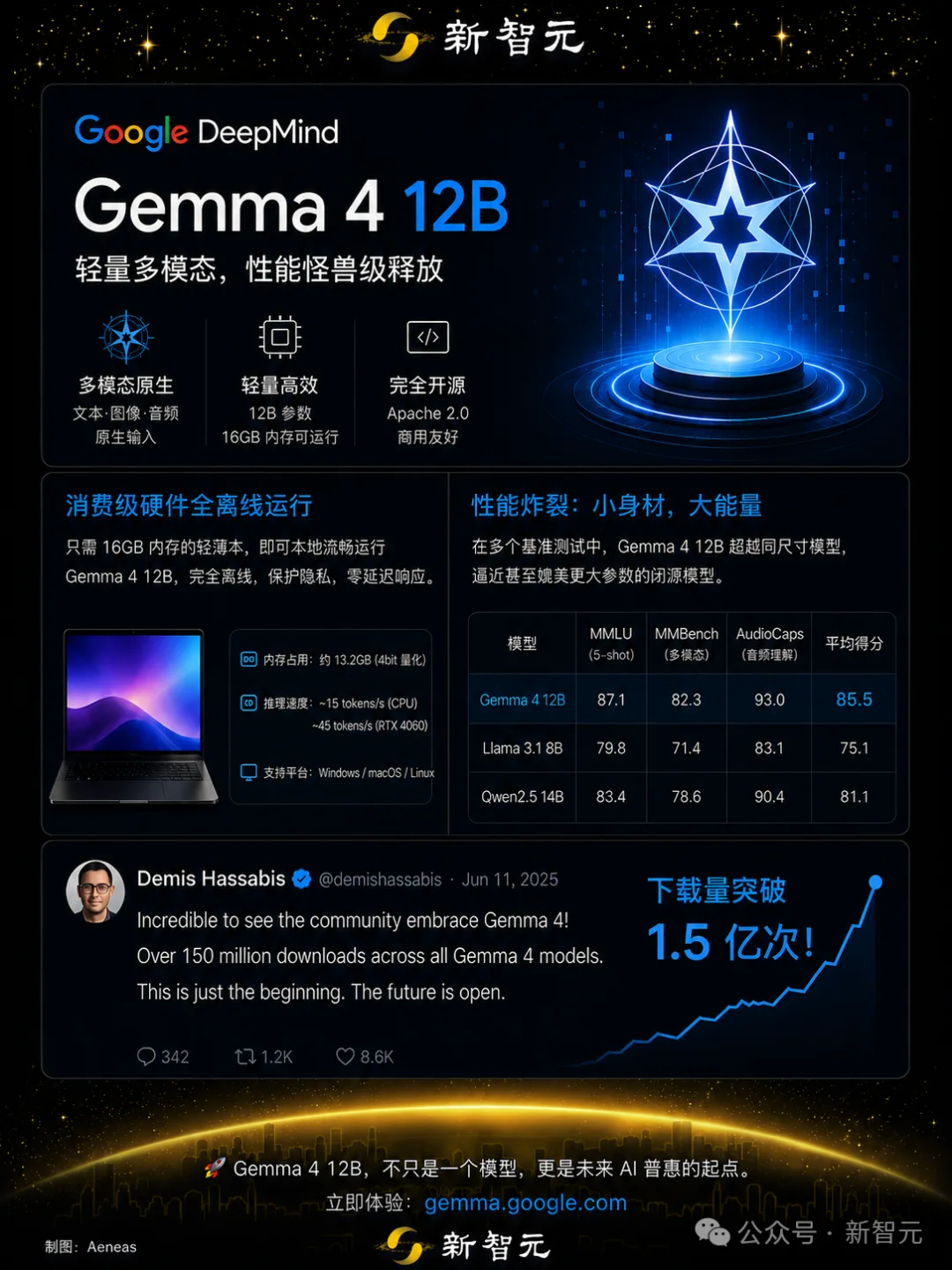
刚刚,谷歌扔出Gemma 4 12B大杀器!16G轻薄本就能全离线流畅跑通,性能直逼26B巨兽,全体开发者惊呼太震撼了,平民级本地AI封神之作降临。硬核实测速来看!
就在今天,全球AI开发者的朋友圈和X被同一个名字刷屏了——Google DeepMind Gemma 4 12B。
所有人还在为千亿模型烧掉上千万美元算力时,谷歌突然转头,向消费级硬件市场投下一枚神器!
这个模型,完全抛弃了传统编码器、原生支持文本、图像和音频直接输入,能在16GB轻薄本上全离线运行,堪称「多模态六边形战士」。
DeepMind CEO Demis Hassabis 亲自下场发文庆功:Gemma 4全系列的下载量已经正式突破 1.5亿次!

这标志着,开源轻量级AI模型已获得全球开发者社区的巨大认可。
这个让边缘AI狂飙、把显卡逼到极限的 Gemma 4 12B,到底有多恐怖?
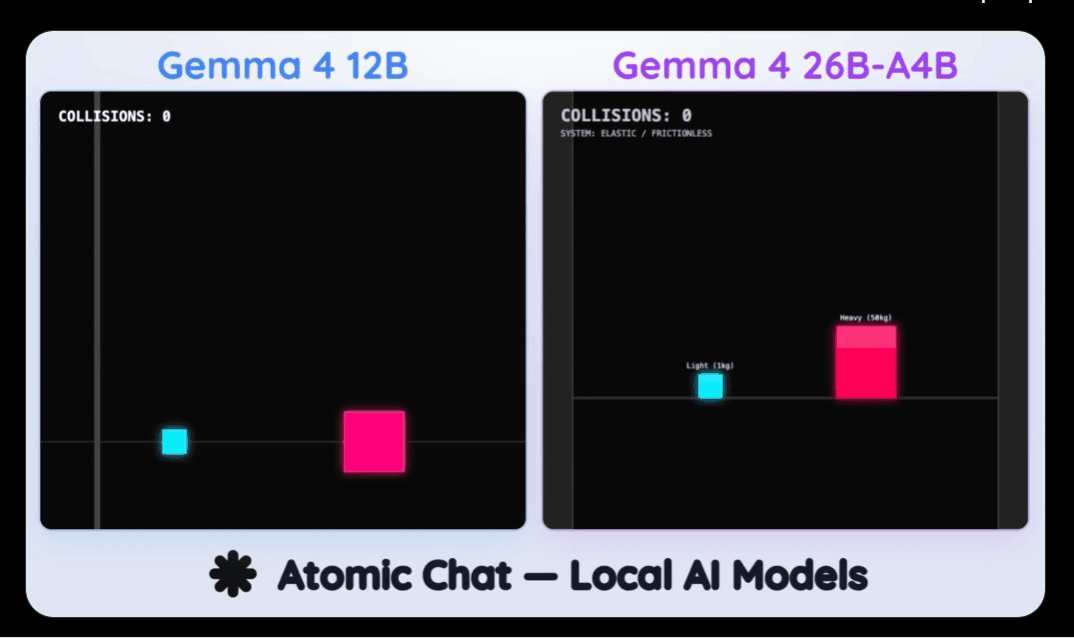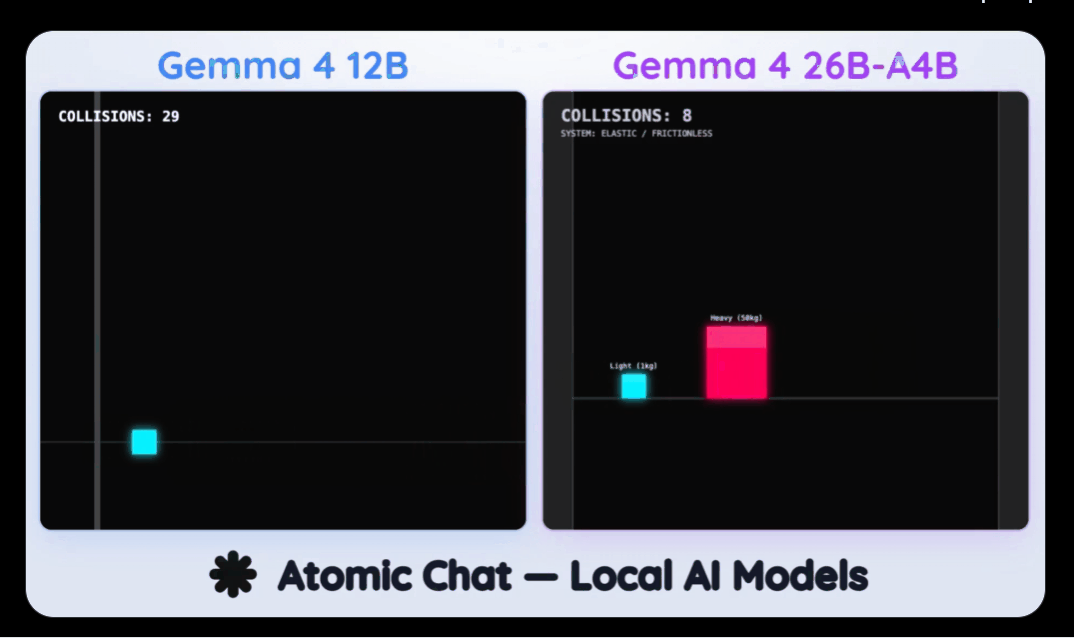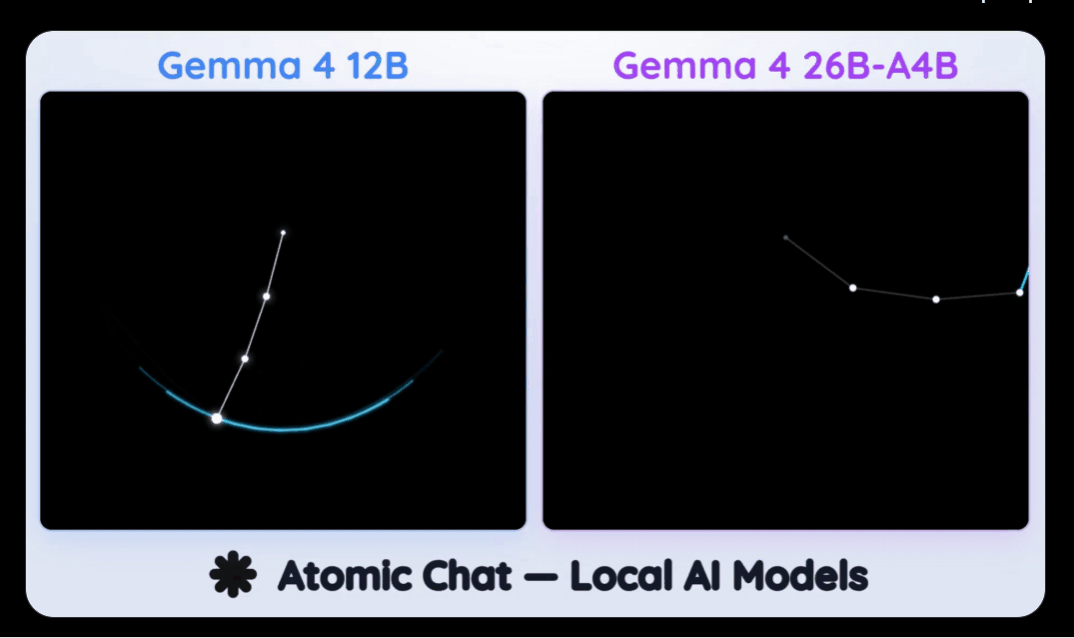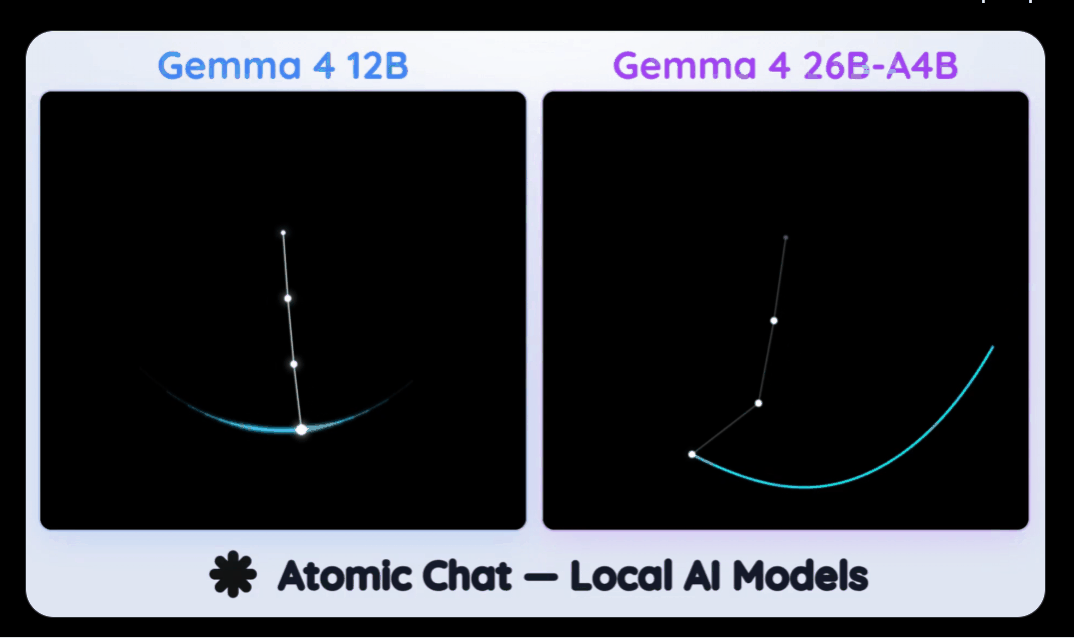
Gemma 4 12B刚发布,著名评测机构 atomic.chat 就它拉到单张 RTX 4090 显卡上,与Gemma 4 26B-A4B进行pk。

这场测试,是极度变态的「纯手写单文件 HTML5 Canvas 复杂物理动效」。
要求极其苛刻:不依赖任何第三方库,完全靠AI的物理直觉和代码能力,凭空手搓出包含「高尔顿钉板」、「方块碰撞」以及混沌学经典的「三摆系统」。
这个过程,两个模型没有任何参考,就得推理出物理引擎的底层代码。
测试结果,让人惊掉下巴。
前代模型Gemma 4 26B-A4B毫无悬念地展现了碾压级的统治力。
它在所有场景中完胜,速度狂飙到惊人的 138 tok/s,生成了6.9k token的代码。但代价是,它吃掉了 15GB 的显存。
这次的新模型Gemma 4 12B,虽然在这场终极极客对决中以 80 token/s 的速度(生成8.9k token)惜败于老大哥,但它直接全线通关了所有物理测试场景。
最可怕的数据在于:Gemma 4 12B 完成这一切,仅仅只占用了 9GB 的显存!

要知道,二者整整差了140亿的参数。
Gemma 4 12B 用不到前代模型一半的体量,几乎打出了同等质量的战绩。
atomic.chat这样评价:「同样的Gemma 4家族,26B跑得快赢了所有场景,但12B紧追其后。在只需要9GB显存的情况下,12B绝对是16GB内存笔记本用户的本地部署完美神机!」
以前,如果要跑这种级别的多模态物理代码推理,要么忍受云端API的延迟和计费,要么得买昂贵的双路工作站。
现在,你只需要一台普通的MacBook或者搭载消费级显卡的游戏本,就可以让AI离线为你写出一个物理引擎!
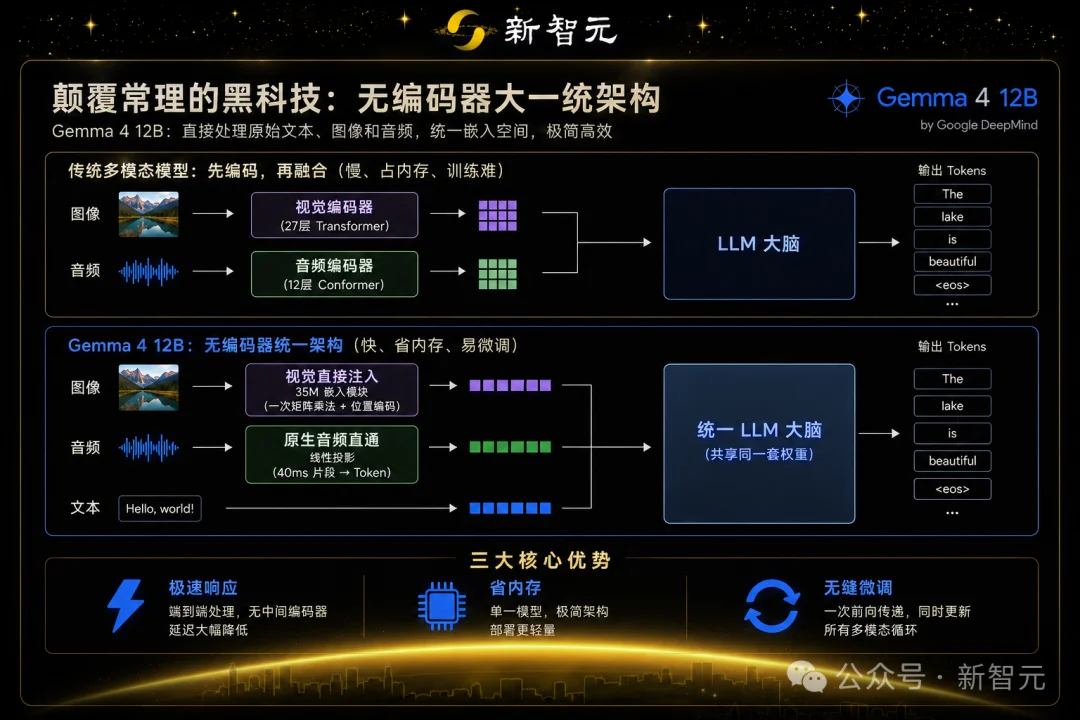
颠覆常理的黑科技——「无编码器」大一统架构
为什么一个 12B的中量级模型,能爆发出如此惊人的多模态理解力?
核心秘密在于谷歌DeepMind这次引入的颠覆性设计:无编码器统一架构。

在过去,所有的多模态大模型,本质上是一个「缝合怪」。看图或者听声音时,必须请两个「翻译官」。
首先,视觉编码器把图片像素翻译成向量。然后是音频编码器,把声音波形翻译成向量,然后再喂给LLM的大脑。
这种「先编码,再融合」的传统范式有三个致命缺点:慢(延迟高)、占内存、训练难。
而 Gemma 4 12B 告诉你:「我全都要,而且我直接吃原数据!」
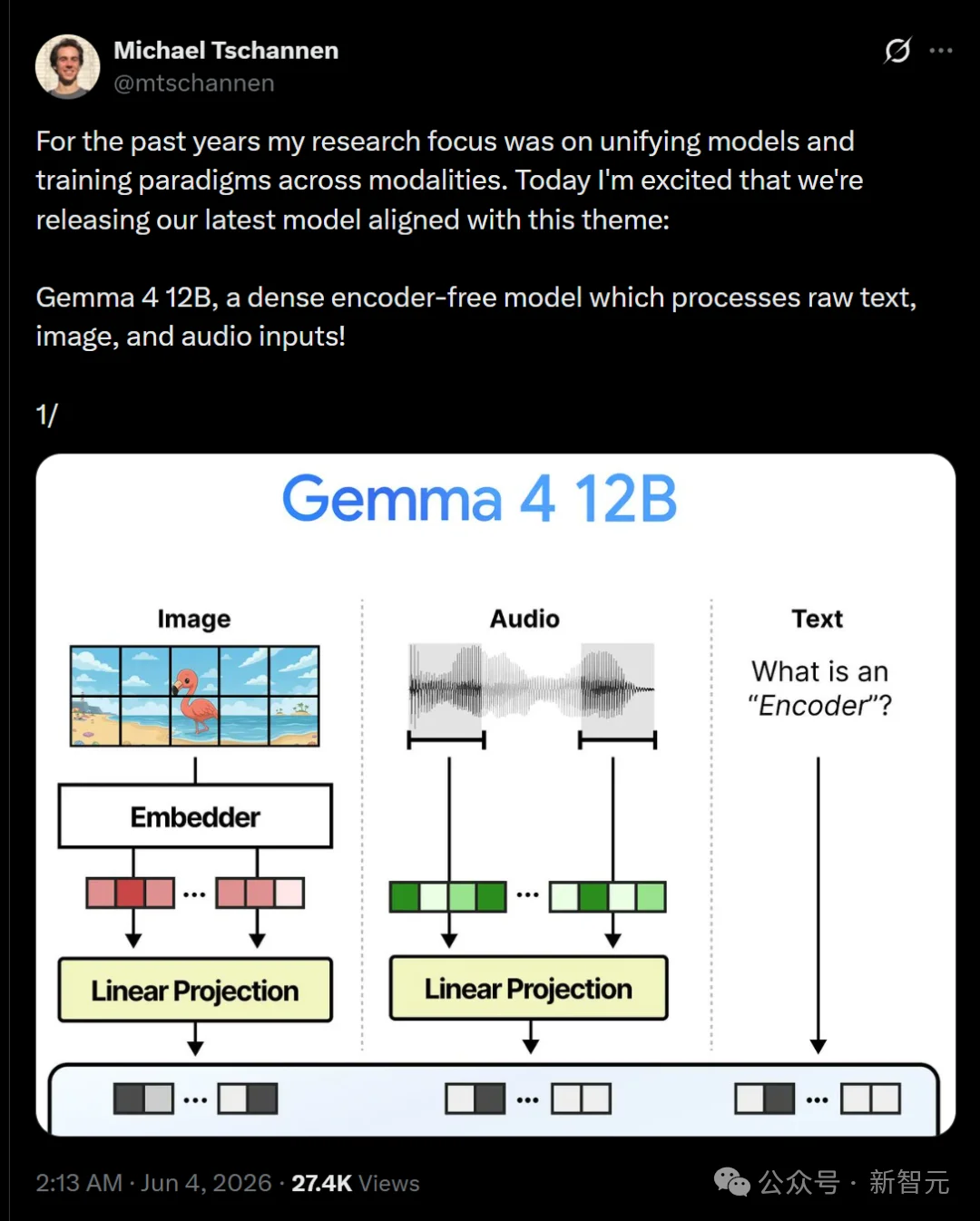
主导这项研究的DeepMind科学家 Michael Tschannen 在X上激动分享:「过去几年我的研究重点就是统一跨模态的模型和训练范式。今天我们发布了Gemma 4 12B,一个高密度的无编码器模型,它直接处理原始文本、图像和音频输入!」
谷歌是如何做到如此极简的?
首先,是视觉直接注入(Vision Embedding)。
谷歌残忍地「砍掉」了原本包含27层的视觉Transformer。取而代之的,是一个仅仅35M的超轻量级嵌入模块。
原始的48x48像素块进来,只需经过一次简单的矩阵乘法,加上分解坐标查找(把X和Y的数学空间位置直接绑定),视觉信息就像文本Token一样,直接流进了LLM的骨干网络中。
就这样,AI的「大脑」直接接管了视觉处理!
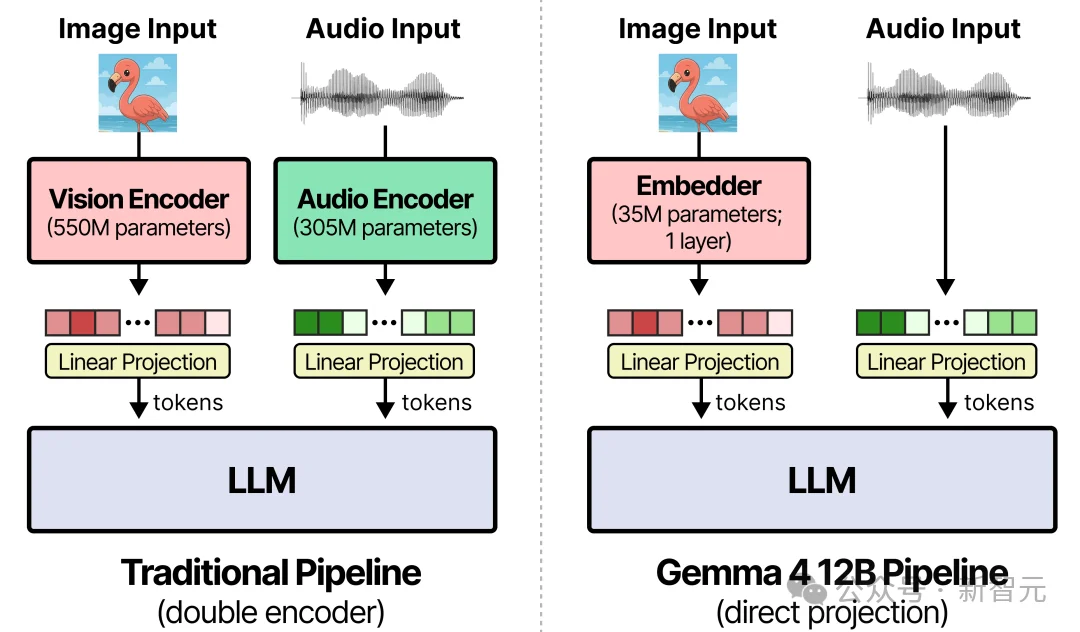
第二,是原生音频直通(Audio Wave Projection)。
这样,音频处理更是被简化到了令人发指的程度。原先在 Gemma 4 E2B里用到的12层Conformer音频编码器被彻底拔掉。
原始的 16kHz 语音信号进来,被切成 40毫秒的片段(每个片段640个浮点数),然后通过线性投影,直接塞进和文本Token完全相同的维度空间里。
这种「大一统」,首先就实现了极速响应。没有了中间商赚差价,端到端的延迟大幅降低。
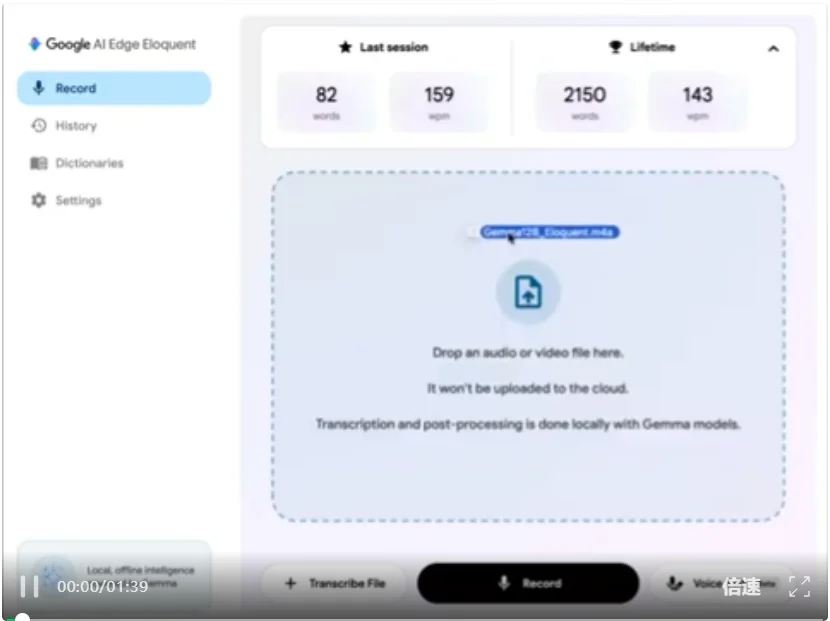
Gemma 4 12B 使用 Google AI Edge Eloquent 应用完全离线转录、格式化和翻译语音输入
其次,还实现了无缝微调。
因为视觉、音频和文本共享同一套权重,开发者在使用 Hugging Face 或 Unsloth 进行 LoRA 微调时,只需要一次前向传递,就能同时更新所有的多模态循环。
这简直是本地开发者梦寐以求的特性!
Michael Tschannen 骄傲地表示:「尽管抛弃了编码器,12B 依然稳稳地坐在了 Gemma 4 家族的帕累托前沿上。它不仅能看能听,在纯文本和Agent任务上的表现,更是远超那些只专注视觉-语言的开源模型。」
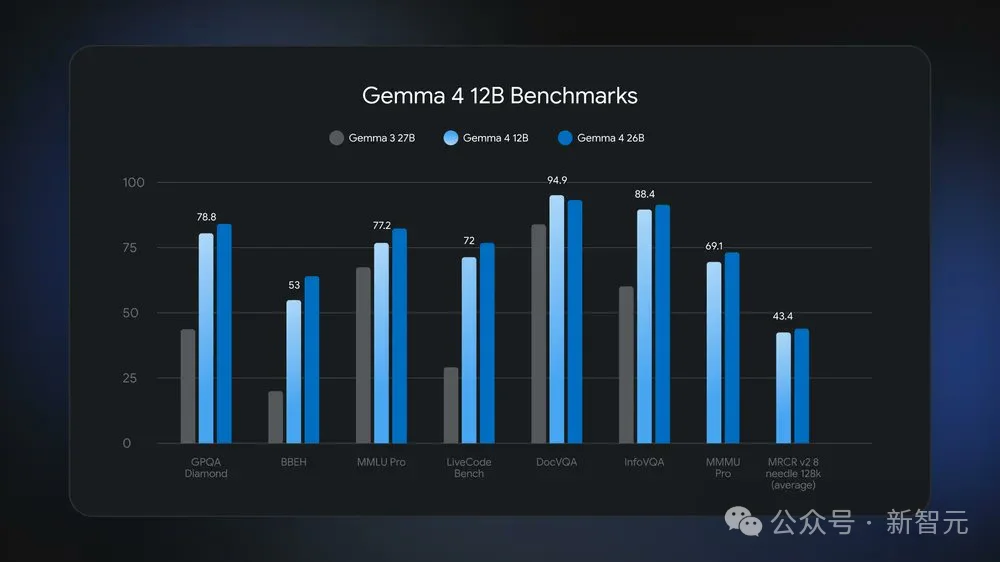
真正属于普通人的 AI 时代——16GB显存的狂欢
「Apache 2.0 协议 + 能在16GB显卡上运行,这才是真正的亮点!」 知名AI安全与量化博主 Oussema 一针见血地指出。
长期以来,AI 圈存在一种「算力焦虑」。
大厂动辄发布千亿参数模型,对于普通开发者和中小企业来说,只能通过 API 调用,数据出海面临隐私风险,长期调用的 token 成本更是让人肉疼。
Gemma 4 12B 的出现,就是为了打破这种垄断!
官方的博客写道:「Gemma 4 12B 的设计初衷,就是将高性能的多模态智能直接带到你的笔记本电脑上。」
16GB VRAM(显存)或统一内存意味着什么?
意味着目前市面上主流的 MacBook Pro(M1/M2/M3 Pro 16GB及以上版本),以及搭载了 RTX 4060 Ti / 4070 / 4080 的 Windows 游戏本和开发机,统统可以毫无压力地将其纳入麾下!
开发者 Mustafa Ergisi 非常震撼:「上周我在我的 M2 芯片 Mac 上测试 Gemma 4 12B 时,真切地感受到了这种冲击。」
为了让本地部署爽到极致,谷歌这次连「周边配套」都做到了令人发指的完善:
1.自带「草稿箱」加速: 模型内置了多Token预测机制,能极大地降低本地生成的延迟。
2.全面适配桌面端: 谷歌不仅开源了模型,还把原本属于移动端的 Google AI Edge Gallery 官方移植到了桌面 macOS 平台!它利用苹果的 Apple Silicon GPU 进行了底层优化。
3.甚至带沙盒环境: 在 Mac 本地应用中,你甚至可以直接在聊天气泡里执行 Python 代码并绘制科学图表,完全在一个安全的沙盒环境中进行,全程断网,无惧隐私泄露!
正如网友 Blissy 激动地留言:「终于有一个我不需要卖肾就能跑得起的模型了!在笔记本上跑原生多模态,这才是真正的炫技。」
千万别以为缩小了体积,Gemma 4 12B 就不行了。
在谷歌官方提供的《开发者指南》中,12B 展现出了惊人的 Agentic能力。
它不仅能回答你的问题,还能自己规划步骤、使用工具、写代码并执行任务。
下面,就是两个官方演示中惊艳全球的真实案例。
案例一:AI 的「俄罗斯套娃」——自己写代码调用自己
在测试中,开发者想要一个能处理图像的本地桌面应用。
于是,他们启动了本地的 Gemma 4 12B(通过 llama.cpp 结合官方的 gemma-skills 库),并对它说:「给我写一个能处理图像的 Gradio App。」
奇迹发生了——
Gemma 4 12B 直接手敲出了完整的 Python 和 Gradio 代码,构建出了一个带有图形界面的图像处理工具。
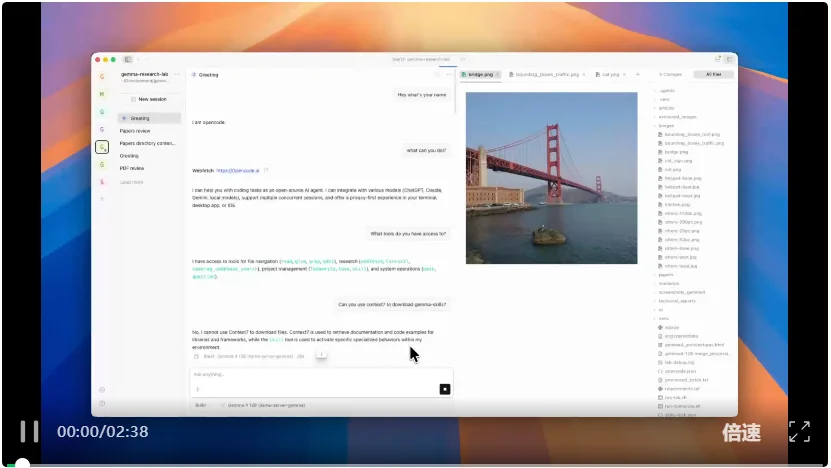
而更绝的是,这个工具背后的图像分析核心引擎,依然是调用本地的 Gemma 4 12B 自己!
用 Gemma 写一个套壳应用来运行 Gemma,这就是未来的开发常态。
案例二:一帧一帧啃视频——精准识别「隐喻」
团队将一段长达 5 分钟的 Google I/O 大会演讲视频(1313帧画面,每秒1帧,加上现场的原始音频)喂给了 Gemma 4 12B。

提示词是「当这个男人拿手机自拍时,视频里发生了什么?」
面对这长达 5 分钟的海量多模态数据,12B 模型不仅完美消化了 256K 的上下文,更给出了堪称「人类专家级」的洞察:
在这个演示视频中,当男人拿起智能手机放在脸前自拍时,这其实是一个巧妙的视觉隐喻。他并不是真的在自拍,而是在演示人工智能如何将一个单一的输入(自拍),作为生成一整个新世界(比如太空站、森林场景)的基础。这是 Gemini Omni 模型展示复杂多模态推理和创造力的一部分……
令人惊奇的是,它get到了人类演讲中的视觉隐喻!
这种深度的视频理解能力,过去只有顶级闭源模型上才具备。
1.5亿次下载背后的开源信仰与生态狂欢
「庆祝 Gemma 4 全系列下载量突破 1.5 亿次的巨大里程碑!伴随新发布的 12B 模型,它体积如此之小,却异常强大。Apache 2.0 许可——祝大家构建愉快!」
当 DeepMind 掌门人 Demis Hassabis这样说的时候,整个开源社区的狂欢被推向了高潮。
1.5 亿次下载是什么概念?
正如有人所质疑的:世界上根本没有 1.5 亿个开发者啊?
事实是,这 1.5 亿次包含了自动化构建、全球服务器的部署、以及超 7 万个衍生微调版本的诞生。
这证明了,Gemma 4 已经成为了像 Linux 操作系统一样的新基建!

而 Apache 2.0 开源协议的加持,更是为商业化落地彻底扫清了障碍。你可以随意修改、微调、甚至把它打包进你的商业软件里去卖钱,不需要向谷歌交一分钱版权费。
在这个生态中,无数人的命运正在被改变。
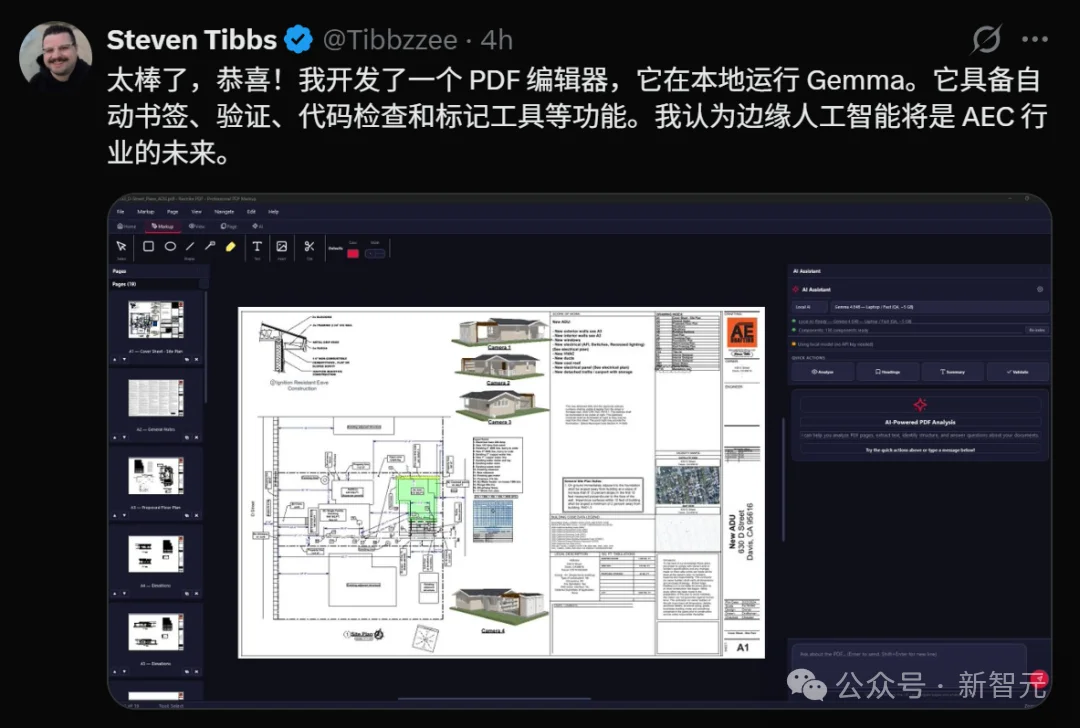
建筑行业的开发者 Steven Tibbs 构建了一个 PDF 编辑器,称赞说边缘AI就是我们这个行业的未来。
独立开发者 Balu0X 感慨:「Gemma让人印象最深的,是它真的太容易运行、微调和发布了,完全不需要昂贵的硬件。」
科技评论员Tech News更是直言:「Apache 2.0 协议的本地推理,才是真正诞生商业应用的地方。」

而且,谷歌已经为你铺平了所有的路。
今天,你只需要点开 LM Studio、Ollama,或者使用 llama.cpp、MLX、vLLM,就能用几条命令行,在自己的电脑上使用Gemma 4 12B了。
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
# Start the OpenAI-compatible server
litert-lm serve
在过去两年的大模型混战中,所有的巨头都在卷参数、卷云端算力。
然而,闭源实验室运送的是纯粹的智力;而开源权重,运送的是杠杆。一个能塞进你笔记本里的前沿级模型,才是真正的科技普惠。
Gemma 4 12B 的发布,就像是普罗米修斯将火种带到了人间。
它不再是被锁在云端机房里、按次计费的奢侈品;它是你笔记本里那个永远不会断网、永远保护你隐私、永远不知疲倦的数字搭档。
当AI从云端降落到每个人的书桌上,一场属于超级个体和Agent开发的超级大爆炸,才刚刚开始。
参考资料:
https://x.com/atomic_chat_hq/status/2062294835411718465
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12B/?utm_source=tw&utm_medium=social&utm_campaign=og&utm_content=&utm_term=
https://x.com/demishassabis/status/2062241713398149524https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
文章来自于"新智元",作者 "Aeneas David"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
