# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

当前的视觉语言 AI 模型(Vision Language Models, VLMs)通过统一的模型架构能够灵活处理各类不同的视觉任务。然而,尽管在语义理解、视觉问答、图像指令等任务上表现优异,它们在三维视觉方面仍然表现不佳。相比之下,专家视觉模型(expert vision models)在绝对深度估计(metric depth estimation)等三维理解任务上,凭借专门设计的网络结构、损失函数及数据增强,已经达到了超越人类的精度。
这就带来了一个核心问题:「视觉语言模型是否在三维视觉学习方面无法替代专家模型?」VLM³ 首次证明了该问题的答案是否定的!
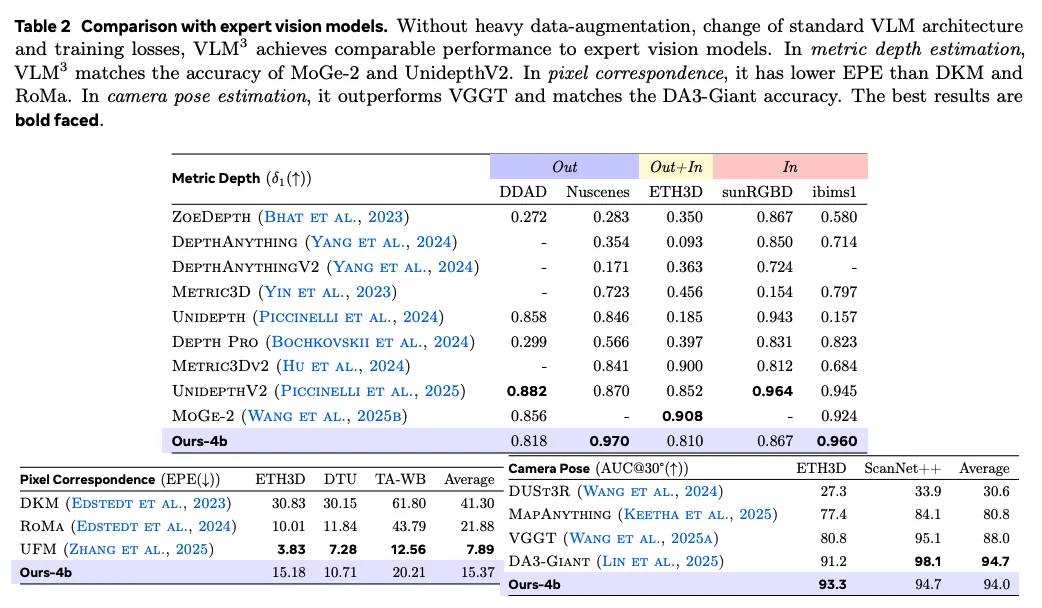
VLM³ 通过极简的设计,在极为多样的三维视觉任务中媲美或超越专家视觉模型,并大幅超越最先进的视觉语言模型:1)在单目深度估计上 match UnidepthV2 及 MoGe2;2)在目标级三维理解任务上超越 SpatialRGPT;3)在像素匹配任务上超越 DKM 和 RoMa;4)在相机姿态估计上 match DA3,超越 VGGT。

在此之前,即便是最先进的 VLM 在标准的三维视觉任务中均远远落后于专家视觉模型。
VLM³ 通过详尽的实验发现,标准的 VLM 仅需要 1)相机焦距归一化;2)像素空间归一化,就能够以令人惊叹的简洁方式有效学会各类三维视觉模型,在 1)单目深度估计中 match UniDepthV2 及 MoGe2;2)在目标级别三维理解超越 SpatialRGPT;3)在像素匹配任务上超越 DKM 和 RoMa;4)在相机姿态估计上 match DA3 并超越 VGGT。
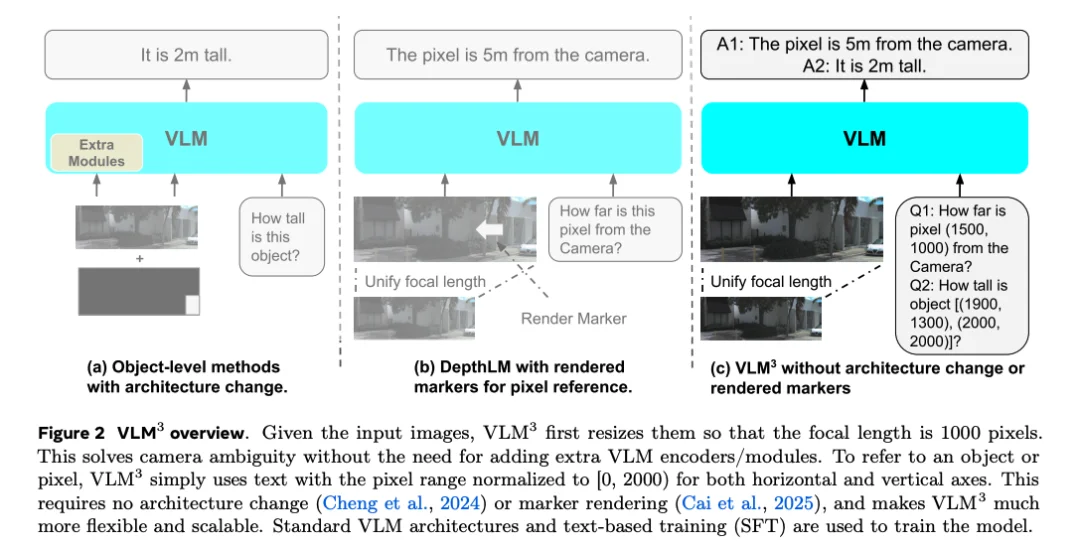
和之前的三维视觉 VLM 不同,VLM³ 既不需要改变 VLM 的架构,也不需要在图片上渲染 marker。相比于专家视觉模型需要大量的架构、损失函数及数据增强方面的复杂设计,VLM³ 仅需要标准的 VLM 架构(如 Qwen3-vl-4B)和训练(基于文字的 SFT)就能够在极为多样的三维任务上达到 SOTA。
这种简洁的训练推翻了之前三维视觉的学习范式,并揭示了三维视觉的 Bitter Lesson:我们其实完全不需要针对特定三维视觉任务人为设计复杂的架构、损失函数及数据增强。通过简单的视觉语言建模 + scale 数据就能够达到同样的效果,并且于其他非三维视觉任务在统一的语言模型训练框架下完全兼容。这使得三维视觉不再需要与视觉语言模型的大规模预训练分离,同时我们能够使用同样的方式来实现三维视觉的 scaling law。
同时 VLM³ 的成功也意味着三维视觉的学习远比我们想象中的要容易:除开不需要特殊架构、损失函数等,我们甚至可以不依赖回归(regression)来学会 fine-grained 3D understanding,这在之前的工作中是难以想象的,因为在连续的输出空间进行回归是绝大多数三维视觉模型的核心设计。
在四大三维视觉任务上性能显著优于最先进的 VLM
在单目深度估计上将 DepthLM 的准确率从 84 提升至 90,并且训练及推理更加简单高效,无需渲染 marker。
在目标级别三维理解上用同样的训练数据超越 SpatialRGPT,并且无需额外的 encoder,模型参数少一半(4B vs 8B)。
在多视角几何任务上如像素匹配及相机姿态估计上远超 Qwen3-vl-32B。
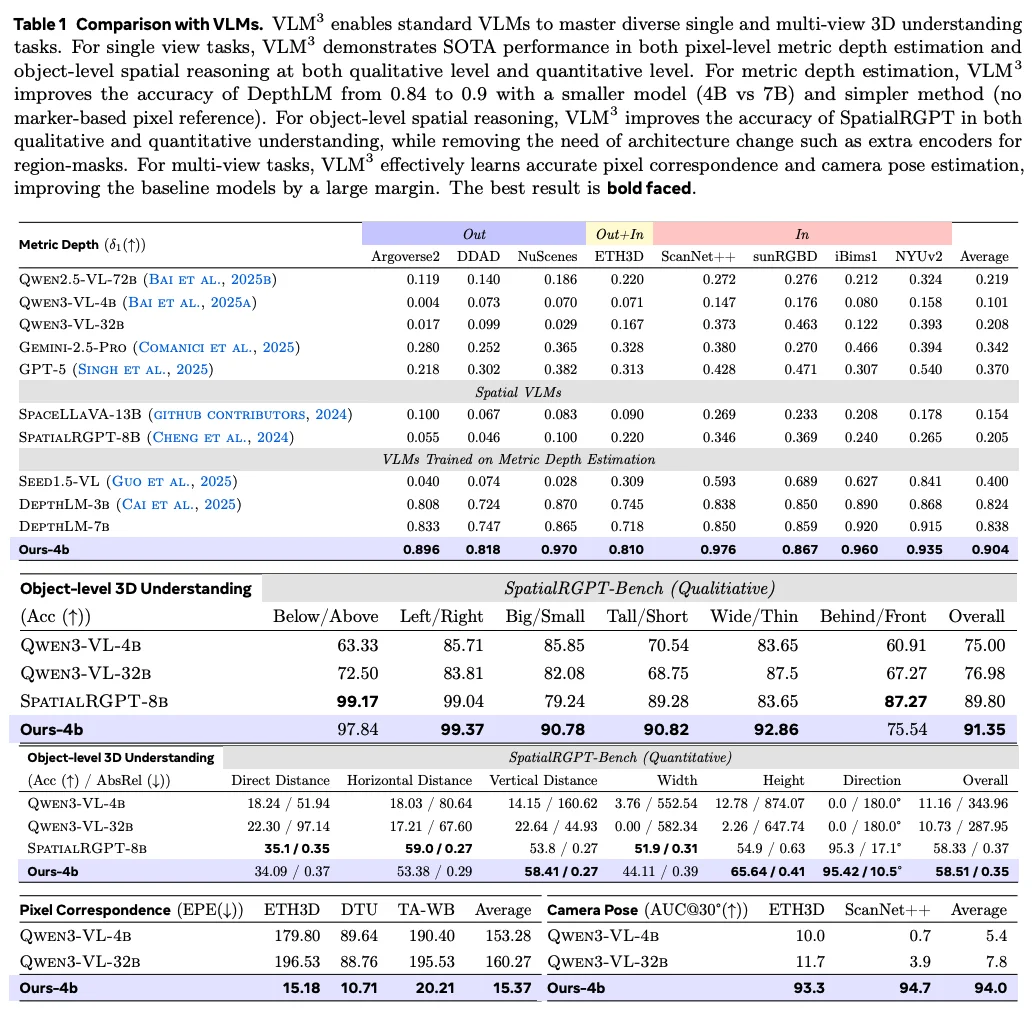
同时在与先进的专家视觉模型(如 MoGe2、DA3、RoMa 等)的对比中,VLM³ 也毫不逊色,并且完全不需要复杂的架构、损失函数及数据增强。

VLM³ 重新定义了三维视觉的最佳学习范式:最简单的 generalist 架构如 VLM 及 scaling 就是最通用的三维视觉范式!过去三维视觉领域普遍采用的人为的 task-specific 的设计并非必须。
这将极大程度地简化三维基础模型的构建。通过将三维视觉任务融入视觉语言模型的预训练,我们也能有效地兼容三维视觉与其它视觉任务,并将 VLM 的优势,及灵活性与泛化性从语义及二维视觉任务有效拓展至三维视觉,极大程度提升模型的能力上限。
VLM³ 的出现,首次打通了视觉语言模型与三维视觉之间的壁垒,使得统一的架构就能够简洁地学会各类视觉任务,并达到专家模型的性能。这既是科研层面的里程碑,也为未来在实际系统中统一多模态推理能力提供了可能。我们期待 VLM³ 后续在机器人、自动驾驶、增强现实等场景中的落地应用。
文章来自于"机器之心",作者 "蔡志鹏"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
