# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。
这条路线很自然,也很成功。无论是超分辨率、去雨、去雾、低光增强,还是风格转换,扩散模型都凭借更强的生成质量和多样性,逐渐成为 I2I 任务里的重要范式。
但最近一篇来自香港大学、中国科学院沈阳自动化研究所、UC Santa Cruz 等团队的工作,提出了一个非常有意思的问题:
我们是不是一直忽视了 “噪声” 的作用?
更准确地说,扩散模型里的高斯噪声,可能不只是一个等待被移除的扰动,也不只是把数据从低维流形中抬升的工具。它还可能扮演一个此前被忽略的角色:域协调器(Domain Harmonizer)。论文提出的 DRDD,全称为 Decoupled Residual Denoising Diffusion Models,正是围绕这个发现,重新设计了统一且数据高效的 I2I 翻译框架。

过去的 I2I 扩散方法,大体可以分成两类。
早期方法,比如 SR3、WeatherDiff,通常从纯高斯噪声开始反向生成,把输入图像当作条件信号。后来的方法,比如 RDDM、IR-SDE,则意识到直接从纯噪声出发不够稳定,于是改成从 “带噪输入图像” 开始反向采样,以更好保留输入结构、减少推理不确定性。
但这些方法背后有一个共同点:
它们都把图像翻译过程压进了一个单一、耦合的反向扩散过程里。
也就是说,在每一步采样中,模型一边去噪,一边去残差,一边完成源域到目标域的转换。这样的转换看起来很自然,但问题也出在这里。
对于单一任务,这样做可能还算有效;但一旦进入统一 I2I 场景,也就是一个模型要同时处理低光增强、去雨、去雾、去模糊、去噪等多个任务,问题就会变得棘手:不同任务、不同退化类型、不同图像域之间存在明显 domain gap。模型需要在多个差异很大的分布之间找到统一映射。
这正是 DRDD 的切入点:
既然加噪能让不同域的特征分布靠得更近,为什么要在核心翻译还没完成之前,就急着把噪声去掉?
DRDD 重新解释了高斯噪声在 I2I 翻译里的作用。
传统观点里,噪声主要有两个功能:一是把数据从低维流形中移出,二是为 score estimation 提供更丰富的训练信号。但论文进一步从理论和实验上证明:注入一定水平的高斯噪声,可以降低不同域特征分布之间的差距。
简单说,原本低光、去雨、去雾这些任务,在特征空间里可能分得很开;但当它们都被注入适当噪声之后,分布会变得更接近。论文在 Figure 1 中用 t-SNE 可视化展示了这一点:源域之间 gap 明显,而加入噪声后的 Source+Noise domain 中,不同任务的特征明显靠近。
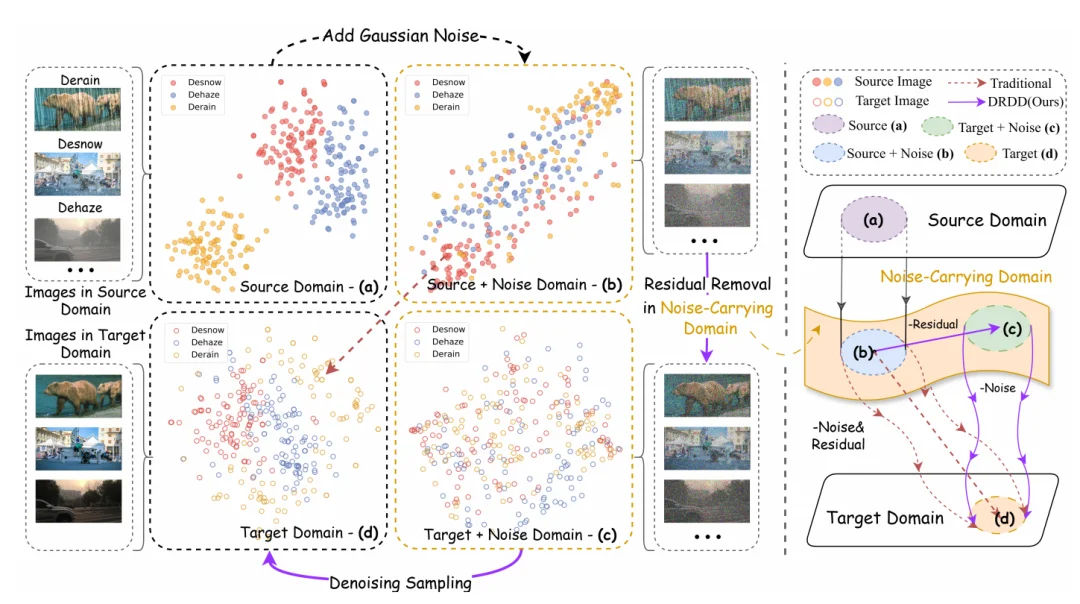
图 1:DRDD 的流程拆解,不同特征的 t-SNE 可视化
这件事对统一的 I2I 很关键。
因为统一模型最怕的不是某一个任务难,而是不同任务之间互相 “打架”。如果噪声可以先把不同域拉到一个更协调的空间里,那么模型学习统一映射的难度就会下降。
问题是,现有耦合扩散模型虽然也加噪,但它们在反向过程中会一边做源到目标的转换,一边把噪声去掉。结果就是:
噪声刚刚带来的域协调效果,还没来得及真正服务于核心图像翻译,就被模型提前擦掉了。
这就像刚为来自不同领域的图像搭建起一座 “中间桥梁”,翻译过程还没真正通过这座桥完成迁移,桥本身却先被拆掉了。
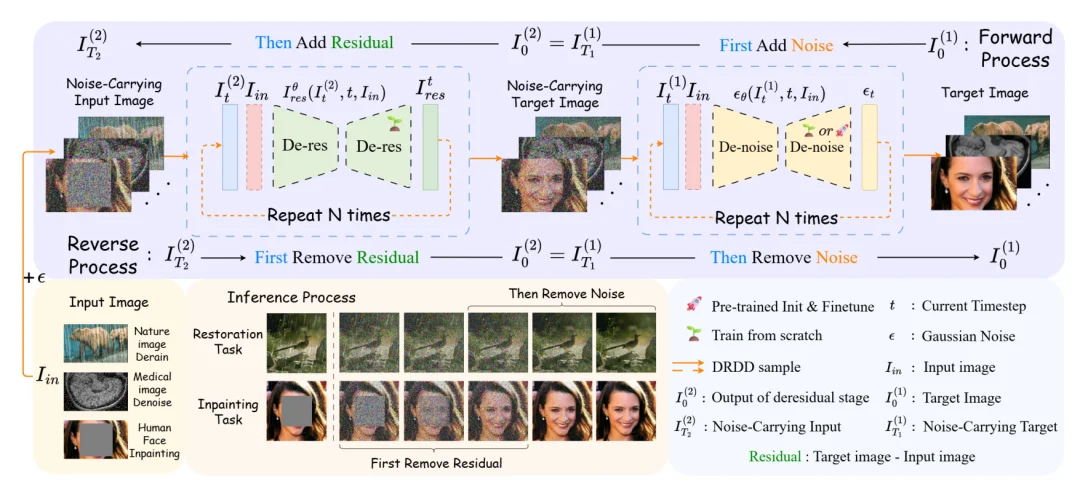
图 2:DRDD 的正向扩散和反向生成
DRDD 的做法是这样的:不要再把残差去除和噪声去除塞进同一个过程,而是把它们拆成两个阶段。
具体来说,DRDD 将传统单一扩散过程解耦为两个顺序执行、彼此独立的扩散阶段:
反向过程也对应拆成两步:
先在带噪域里做残差去除,完成核心的源域到目标域转换;再做去噪,把已经完成语义转换的带噪目标图像变成干净目标图像。
这和传统耦合扩散最大的区别在于:
传统方法是一边换域,一边去噪;
DRDD 是先在噪声还在的时候完成换域,再最后去噪。
这个设计看似只是顺序变了,但本质上改变了扩散模型做 I2I 翻译的几何路径。它让噪声的域协调效果完整保留到核心映射阶段,而不是在中途被提前消耗掉。论文 Figure 2 也清晰展示了这个流程:前向过程先加噪、再加残差;反向过程先去残差、再去噪。

图 3:DRDD 的公式
DRDD 的优势可以概括成两件事。
第一,它让统一映射更容易学。
在统一 I2I 任务里,不同退化类型和不同图像域之间的 gap 会让模型很难用一个共享参数空间同时覆盖所有任务。DRDD 通过固定噪声域完成残差去除,相当于先把不同任务拉到一个更协调的中间空间,再学习源到目标的核心变换。
这不是简单地 “多加点噪声”,而是把噪声变成了有辅助作用的中间域。
第二,它显著提高了数据效率。
DRDD 的去噪阶段只需要目标域干净图像训练,不需要成对的源域 - 目标域样本。换句话说,只要有大量 unpaired target-domain images,就可以训练或增强去噪模块,从而提升最终图像保真度。论文也指出,DRDD 的 denoising network 可以只在干净图像上训练,并且能够使用大规模自然图像预训练权重初始化。
I2I 任务最贵的往往不是图像本身,而是成对数据。比如真实低光图和正常曝光图、真实模糊图和清晰图,都不容易大规模收集。DRDD 把 “必须依赖配对数据” 的部分缩小到残差映射阶段,而把去噪质量提升交给更容易获得的非配对目标域图像。
DRDD 的实验设计覆盖了多个层面:多任务统一图像修复、多域单任务 I2I、单域单任务 I2I、少量配对数据、跨扩散范式兼容性,以及噪声强度分析。整体来看,它不是只在一个 benchmark 上刷分,而是在多个维度验证 “解耦” 这件事确实有效。
1)All-in-One-5:统一图像修复平均表现领先
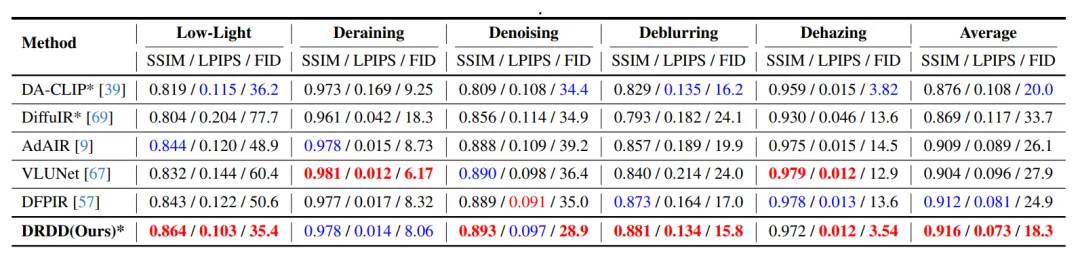
在 All-in-One-5 统一图像修复 benchmark 上,DRDD 同时处理低光增强、去雨、去噪、去模糊、去雾五类任务。
结果显示,DRDD 在平均指标上取得 0.916 SSIM / 0.073 LPIPS / 18.3 FID,整体优于 DA-CLIP、DiffuIR、AdAIR、VLUNet、DFPIR 等方法。尤其在感知质量指标上,DRDD 的优势更加明显。
这组结果说明,DRDD 并不是为了某一个单独任务定制,而是真的具备 all-in-one restoration 的统一建模能力。
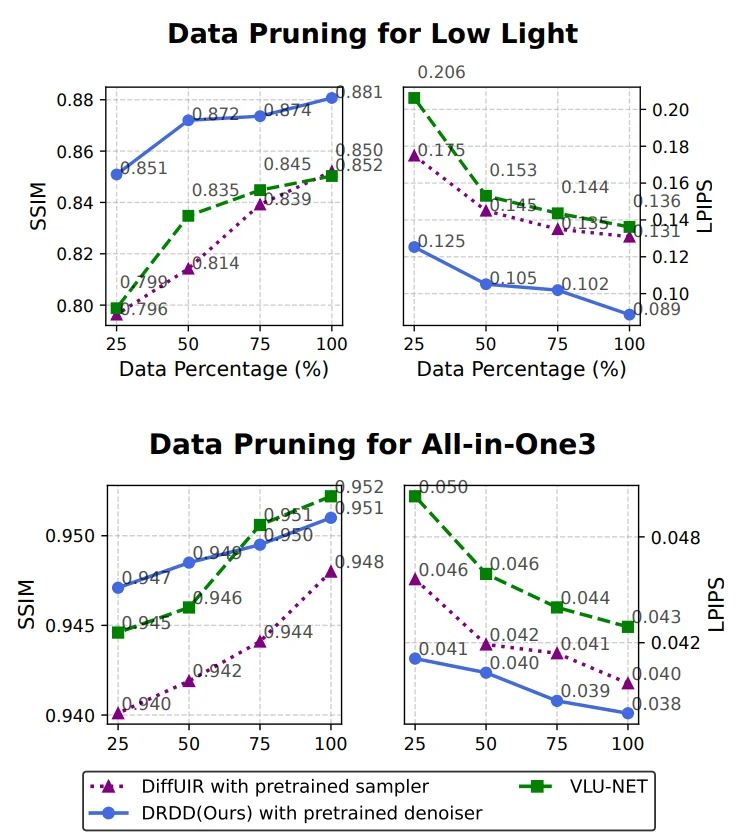
2)少量配对数据:数据越少,优势越明显
DRDD 另一个重点是 data-efficient I2I。
论文在 Low-Light 和 All-in-One-3 上做了数据裁剪实验,将训练集随机下采样到 75%、50%、25%,验证少量配对数据下的表现。结果显示,随着训练数据减少,DRDD 的性能下降明显小于 DiffUIR 和 VLUNet 等基线。Figure 5 中也可以看到,在低光增强和 All-in-One-3 上,DRDD 在 SSIM 和 LPIPS 上都保持了更稳定的曲线。
这传递了一个很明确的信号:
DRDD 的提升不是靠 “吃更多配对数据” 堆出来的,而是靠把配对映射和目标域去噪拆开,让每类数据承担更合适的角色。

3)噪声不是越大越好:DRDD 也给出了 “加多少” 的答案
当然,如果说噪声能协调域分布,一个自然问题是:
那是不是噪声越大越好?
答案是否定的。
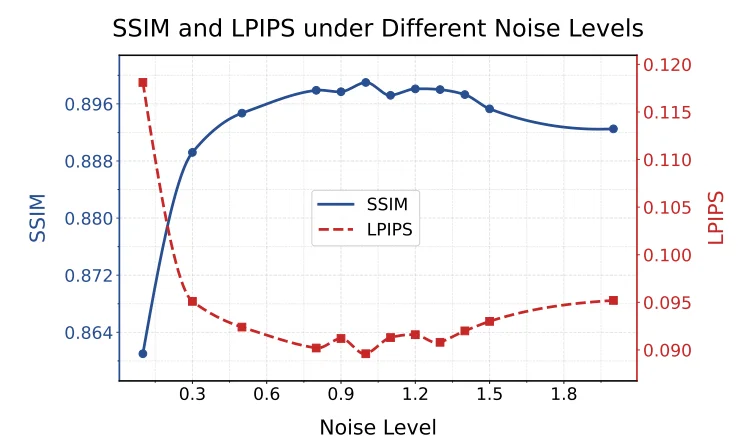
噪声太小,域协调效果不够;噪声太大,又会过度破坏输入结构,让翻译任务变得更难。DRDD 因此从理论和实验两侧分析了噪声强度。
论文定义了两个距离:一个衡量带噪源域和带噪目标域之间的距离,另一个衡量带噪源域和原始源域之间的距离。前者希望小,因为域 gap 小更好翻译;后者也不能太大,否则输入被破坏太多。最终,DRDD 通过一个 trade-off objective 来寻找合适噪声水平。
在 All-in-One-5 上,理论分析得到的最优噪声强度大约在 1.1 到 1.2;实际实验中,模型在噪声强度为 1.0 时达到最优,并且在 0.8 到 1.3 范围内表现稳定。
这也让 DRDD 的 “用噪声” 不是玄学,而是有理论约束、有实验验证的可控设计。
很多扩散模型工作都在追求更好的网络、更快的采样、更强的条件控制。但 DRDD 的有趣之处在于,它没有把重点放在 “怎么更快去噪” 上,而是反过来问:
为什么一定要这么早去噪?
在传统耦合扩散框架里,噪声和残差被绑定在一起移除;而 DRDD 把它们拆开,让噪声先完成域协调,让残差去除在这个协调后的空间里发生,最后再做保真度恢复。
这就把 I2I 扩散模型里的噪声,从一个 “必须尽快清理掉的扰动”,变成了一个 “帮助不同域对齐的工作空间”。
DRDD 给出的路线非常清晰:
这套顺序让扩散模型不再只是 “加噪 — 去噪” 的生成机器,而更像是一个分阶段的视觉翻译系统:噪声负责协调,残差负责转换,去噪负责精修。
当统一 I2I 逐渐从单任务 benchmark 走向真实复杂场景,模型面对的将不再是单一、干净、边界明确的退化类型,而是多任务、多域、多退化、多数据约束同时存在的现实世界。DRDD 的意义就在于,它为这种场景提供了一个更自然的框架:
不要把所有困难都塞进一个耦合反向过程里,而是让每个阶段分别做自己最擅长的事。
从这个角度看,DRDD 不只是一个新的 I2I 方法,更像是对扩散模型内部机制的一次重新拆解。
噪声不是敌人。
用得好,它可能正是统一图像翻译所缺的那座桥。
本文作者包括 Ziyue Lin、Jiahe Hou、Hongyu Xia、Xinrui Xie、Feifei Wang、Yuyin Zhou、Wei Wang、Jiawei Liu 和 Liangqiong Qu。作者团队来自香港大学、中国科学院沈阳自动化研究所、香港中文大学和 UC Santa Cruz。其中 Ziyue Lin、Jiahe Hou、Hongyu Xia 为共同一作,Jiawei Liu 和 Liangqiong Qu 为通讯作者。
文章来自于"机器之心",作者 "Ziyue Lin、Jiahe Hou、Hongyu Xia、Xinrui Xie、Feifei Wang、Yuyin Zhou、Wei Wang、Jiawei Liu 和 Liangqiong Qu"。


