# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。自动化所、上交、UCSD 和合工大联合团队最新综述《Context Compression for LLM Agents》系统梳理了 Agent 上下文压缩的方法、失败模式与评估体系,指出 Agent 的核心瓶颈正在从“模型能不能想”转向“上下文能不能被可靠管理”。
最近做 LLM Agent 的人,大概都有一种共同的焦虑:模型明明前面几步都对,后面却开始忘事、丢约束、反复横跳,最后把一个本来能做完的长任务,活生生跑成了事故现场。
很多人第一反应是,模型还是不够强。但由自动化所、上交、UCSD和合工大联合团队发表的这篇题为《Context Compression for LLM Agents: A Survey of Methods, Failure Modes, and Evaluation》的综述,真正把问题掰开后会发现,Agent 的麻烦常常不在“会不会想”,而在“上下文能不能被可靠地管理”。
论文预印本:
https://www.preprints.org/manuscript/202605.2065
GitHub 仓库:
https://github.com/YerbaPage/Awesome-Context-Compression
换句话说,Agent 真正的瓶颈,很多时候不是推理,而是上下文。
它讨论的对象,不是普通静态长文档,而是 LLM Agent 在执行长周期任务时不断累积出的 unbounded agentic trajectory。这个轨迹里混着 Actions、Thoughts 和 Observations,也就是大家熟悉的 A-T-O 序列。
这种上下文最麻烦的地方在于,它不是“字太多”,而是“状态太多”。每做一步,环境就变一次;每记录一次,依赖关系就重排一次;每重试一次,后续策略就可能被改写一次。于是上下文窗口越来越紧,关键信息越来越容易被挤掉。
所以,这篇综述一开始就把问题定得很明确:上下文管理不是可有可无的优化,而是 Agent 能不能持续跑下去的基础设施。
普通长文档压缩,更多是在处理一段静态材料;Agent 的上下文压缩,面对的是一个持续变化的执行过程。这里的每个 token 都不只是文本,它还承载着时序、状态、约束和动作后果。
这也是为什么作者强调,Agent context compression 不能只追求“压短”,还必须保住 temporal dependencies、actionable states 和 structural fidelity。压短了但不能继续执行,那就不是压缩成功,而是把系统弄瘦了、也弄残了。
作者把整个上下文管理过程整理成一条完整管线:先 Select,决定哪些内容值得处理;再 Compress,把它变成更紧凑的表示;然后 Store,把关键状态保留下来;最后在需要时 Recover,重新把它们取回来。
这个框架的价值,不只是把概念讲清楚,更重要的是它把研究对象从“一个压缩算法”升级成了“一个可执行系统”。真正该比较的,不只是压缩率,还包括保存了什么、丢了什么、以后还能不能找回来。
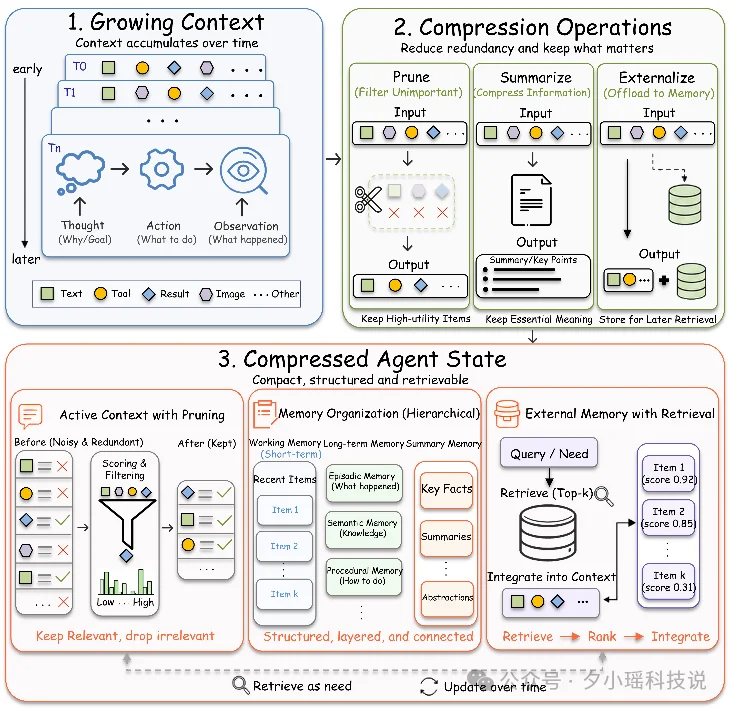
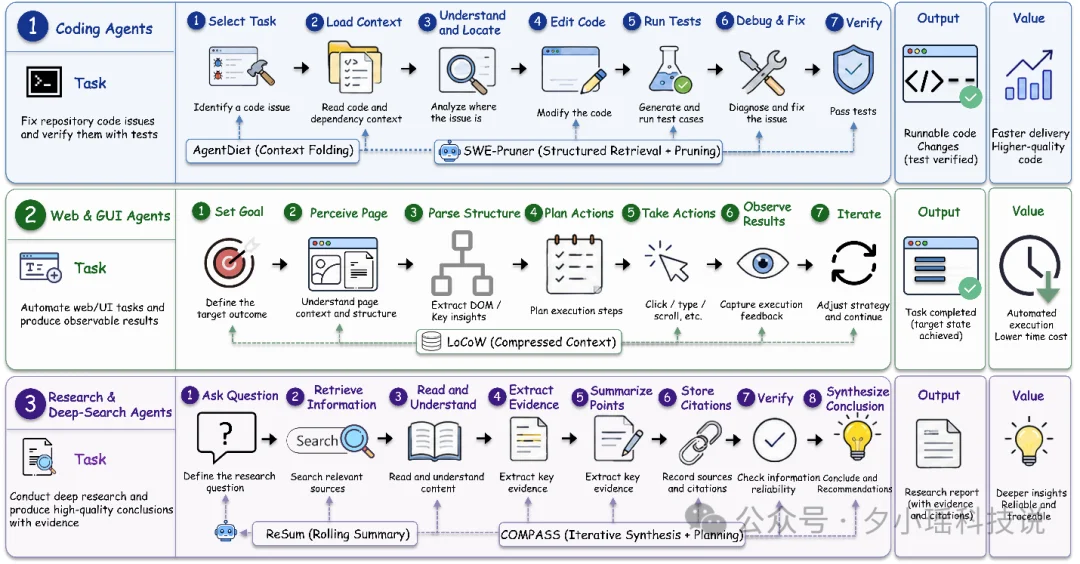
第一条是 compression target,也就是压什么。作者把现有方法分成几类:有的压 observation,有的压 trajectory,有的压 plan 和 reasoning,有的压 memory state,还有的直接压 representation。
第二条是 compression mechanism,也就是怎么压。这里包括 masking/truncation、summarization/abstraction、pruning/reduction、externalization/retrieval,以及更底层的 representation compression。
第三条是 control policy,也就是谁来决定什么时候压。可以是系统固定规则,也可以是外部控制器,也可以是 Agent 自己决定,甚至可以通过学习策略来优化。
这三条线其实分别对应了工程里最容易出问题的三个层面:压错对象、压坏内容、压错时机。只要其中一条链路不稳,Agent 就很容易从“看起来很聪明”变成“看起来很忙”。
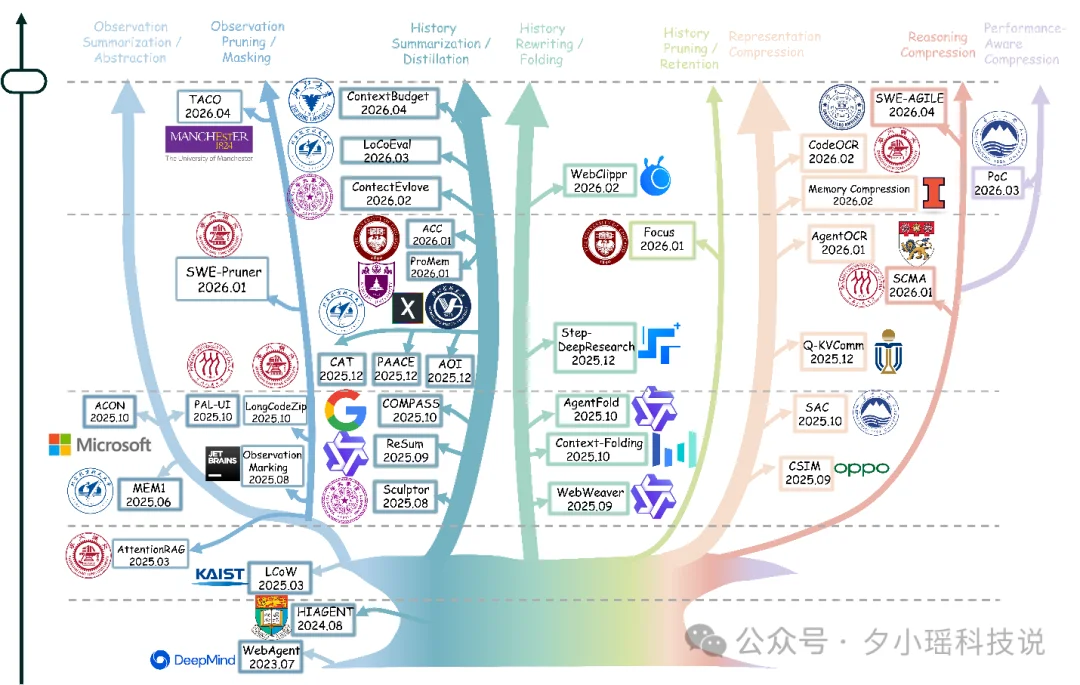

作者对不同机制的态度也很鲜明。截断和遮盖最便宜,但一旦删掉就很难恢复;总结压缩能保留语义,但容易引入遗漏和过度概括;剪枝可以保留结构,却不一定压得足够狠;外部化和检索最像真正的可恢复系统,但代价是把问题从“压缩”转成“能不能找回”。
这段看下来会发现,一个很现实的结论是:很多系统表面上做了压缩,其实只是把上下文问题从当前轮次推迟到了下一轮次。token 省了,风险没少,只是换了一个地方爆。
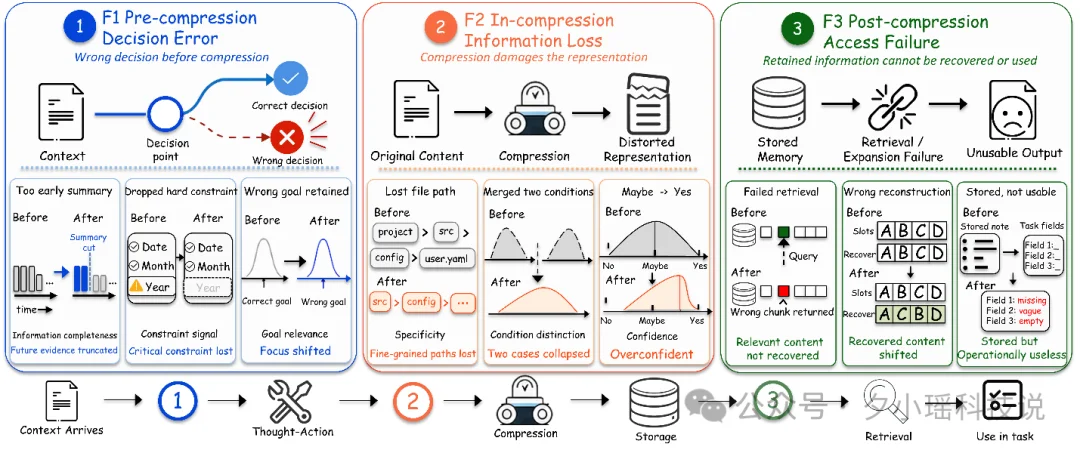
论文把 failure modes 整理成三层。第一层是 F1:压缩前就选错了对象、时机或者粒度,本来不该压的被提前压了。第二层是 F2:压缩过程中把关键语义、结构关系或约束条件损坏了。第三层是 F3:信息其实还在,但后面找不回来、恢复不准、或者无法正确使用。
这三种失败非常像真实工程里的事故链:先是判断错,再是处理坏,最后是恢复失败。看起来是一个问题,实际上是三次失误一路叠加。
尤其是 F3,最容易被忽视。因为它最像“信息还在”,但对 Agent 来说,信息只要不能在该用的时候准确拿出来,就等于不存在。
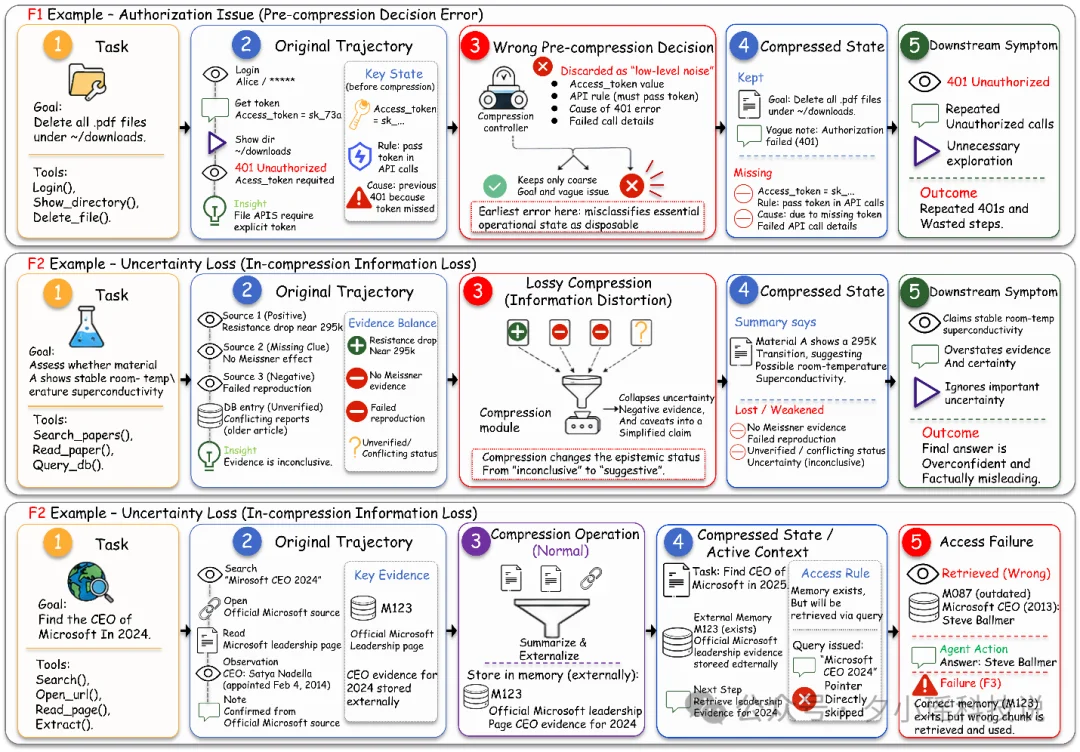
论文还专门做了 domain-specific analysis,讨论软件工程、Web 导航和 deep research 这三类场景。它们对上下文的要求根本不是一套标准。
在软件工程里,最重要的是代码依赖、错误链和状态约束;在 Web/GUI 导航里,关键的是页面结构、可点击对象和交互反馈;在深度研究里,关键的是证据链、来源和推理路径。
也就是说,Agent context compression 根本不存在一个“万能模板”。同样的压缩策略,在不同任务里可能一个救命、一个翻车。

综述对评估部分的批评很直接:只看 end-task success 不够。因为有些方法表面上把任务做完了,但中间状态已经坏掉了,后续的可恢复性也没了。
作者更希望看到的,是一套更接近系统真实运行方式的指标体系,比如信息密度、时间一致性、错误传播,以及压缩后状态还能不能稳定支撑后续决策。对于 Agent 来说,过程可靠性本身就是性能的一部分。
它不是在说“上下文越短越好”,而是在说:Agent 的上下文应该被当作一种可管理、可恢复、可控制的执行资产。谁能把 Select、Compress、Store、Recover 这条链路做稳,谁就更有机会把长任务真正跑完。
这也是这篇综述最值得被记住的地方。LLM Agent 的上限,越来越像上下文管理能力的上限。不是单纯看模型有多大,而是看它能不能把长期轨迹压得住、存得住、取得回。
如果说长上下文模型解决的是“能装多少”,那 agent context compression 解决的就是“装进去以后还能不能持续用好”。它面对的不是一次输入,而是长程执行;不是静态文本,而是动态轨迹;不是简单截断,而是可恢复的结构化状态。
当任务越来越长、工具越来越多、状态越来越复杂时,真正决定系统上限的,往往不是再多给一点上下文,而是把上下文压缩成一套真正可靠的执行机制。
文章来自于"夕小瑶科技说",作者 "夕小瑶科技说"。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
