# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。
开源塑造了无数产品的形态,也成为我们这一代人缔造互联网高光时刻的见证。
于我个人而言,过去十多年,在大数据时代,一边上班,一边下班抽空参与Cassandra、HBase 这类系分布式 NoSQL 数据库的设计实现,讨论region 怎么切,replica 怎么放,compaction 什么时候跑……几乎构成了那时初入职场阶段日常生活的全部。职业刚起步阶段,就有幸运维过全球最大的 HBase 集群之一,到现在还是老友见面时候,值得吹上一段的历史。
再到后来的AI时代,我又深度参与了Milvus 2.0 的新一轮存算分离架构的设计和代码实现。
当时,1.0阶段的Milvus 已经在单机上做到了有口皆碑,2.0重构系统,有技术挑战,也要去面对非常多来自内部和外部的不理解。半夜在邮件列表里和素未谋面的人为一个 compaction 策略争论好几天,类似的事情几乎每天都在发生,但这种在信仰笼罩下的碰撞与思考,让人目眩神迷。
但产品越做越深,知道我们的人越来越多之后,经常会有一个与过去理想背道而驰的想法冒出来:
AI Agent时代的新负载,正在挑战传统开源数据库的地位。
或者,更准确来说,"传统的开源数据库内核足以解决一切问题"这个假设,其实早就不存在了。
不是因为开源代码不够好,恰恰相反,开源在普世方面,做的太成功了,普世就意味着它必须忽略很多底层差异:资源的异构、用户行为的差别、数据结构的分布、资源的差距,默认所有人都拿着一组给定资源,在相同的资源环境下寻找可以落地的公约数。
这在过去是合理的。但到了 AI Agent 时代,给定资源下求解,或许要成为过去式了。
过去二十年,数据库容量规划大体围绕两种负载形状展开。
一种是 OLTP。请求持续、小而密,核心问题是峰值来了能不能扛住。我们看历史 QPS,看业务高峰,看 SLA,然后按峰值留出余量就能搞定。
另一种是 OLAP。请求主要是批量大查询,可以排队,可以降级,可以跑在一个按吞吐量 sizing 的资源池里。它不一定要求每一次查询都立刻返回,更多时候追求的是整体吞吐和单位成本。
这两类负载差异很大,但共享一个隐含前提:资源池先定好,剩下的问题只是怎么把请求摊进去。
AI Agent 的负载不属于这两类。
一次用户交互,可能会在几秒到几分钟内扇出成多次向量检索、memory 读写、metadata filter、工具调用、上下文拼接和结果回写。随后一切归零——下一次可能在十秒后,也可能在三个月后。
我把它叫做episodic workload。这和我们常说的"突发"不是一回事:突发流量通常发生在一个持续在线的系统上,底下始终有稳定的访问基线,只是某一刻冲高了。Episodic workload 的麻烦在于,两次 episode 之间系统可能完全空闲,历史 QPS 对预测下一次访问几乎没有帮助,但背后的数据又必须长期保留,不能因为三个月没人查就丢掉。
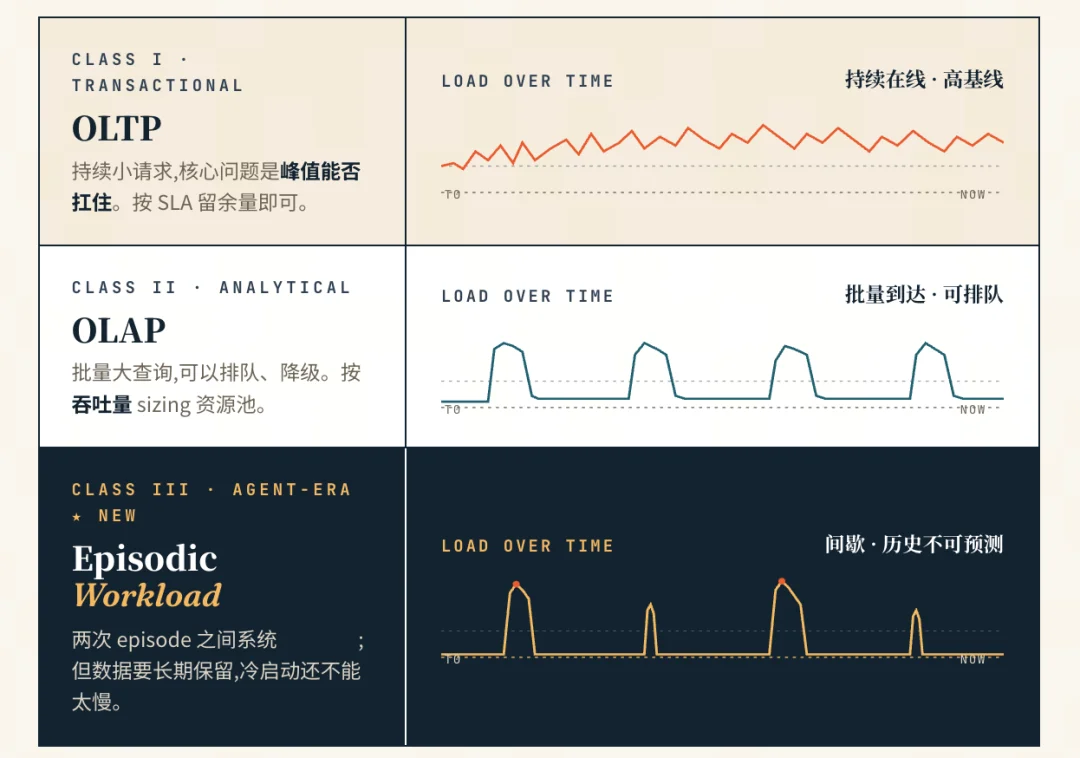
它有几个特征,与传统数据库资源规划几乎是相悖的。
第一,它是交互式的。请求方会在线等待,这种情况下,让用户做分钟级等待完全不可接受。
第二,它与历史弱相关。传统容量规划喜欢看历史曲线,但一个用户的 memory 三个月没被访问,不代表下一秒不会被唤醒。历史低频并不能被简单翻译成未来不需要资源。
第三,它天然多租户、访问局部、冷热极端分明。云上的 agent memory 平台往往承载成千上万个用户或项目,任一时刻都只有极少数数据是热的,而绝大多数数据处在沉睡状态。这种倾斜分布给了我们一个机会:只为热的部分付算力。但它也让传统固定资源池分配模式显得非常浪费,因为你在为大量冷数据常驻算力。
第四,长期分布未知。同一套系统里可能同时存在两种 agent:一种 7×24 高频调用,另一种一年只触发几次。系统在 provision 的时候无从预判谁会变热,谁会一直冷下去。
结果就是,固定容量规划会在这种负载下失效:按峰值留会导致为闲置付费,按均值留会让 episode 超时,按历史预测则是在拟合噪音。
总而言之,问题可以压缩成一句话:数据长期存在,资源需求间歇出现,访问模式不可预测,但冷启动还不能太慢。
以我们一个多租户 agent memory 用户为例:他们成千上万个用户的记忆库挂在同一套系统上,访问分布极度倾斜。90% 的数据一个月都没有被碰过,99% 的数据每天访问不到一次。
采用传统做法为了让任意一个用户随时能查,把全部数据常驻在本地磁盘里,再配足够的算力待命。就会导致一个月成本高达7K 美元,而绝大部分付给了那些几乎从不被访问的冷数据。
在性能、产品能力全都做到极致后,围绕AI数据,后面所有的设计,都需要围绕这张账单展开。
分布式数据库的调度逻辑,从 HBase、MongoDB 到 Milvus,本质上都很相似:把数据切成分片,再由调度器决定哪个分片落在哪台机器上。当负载不均时,再把分片迁到更空的机器。
区别不过是HBase 按 key range 切 region,MongoDB 按 shard key 切 chunk、靠 balancer 在 shard 之间搬,Milvus 会把数据切成大小受控的 segment,每块单独建索引,在任一时刻只在一台 QueryNode 上 serving。
这些系统的负载均衡目标都一样:把这些分片摊到合适的节点上,让每台机器承担的算力、内存和存储尽量均匀。
这套思想非常成功。过去二十年的分布式数据库工程,很大一部分都建立在它之上。
但它也共享一个很少被明说的前提:资源池大小是外部输入,不是调度器的决策变量。
这里说的是数据库内核自身的调度逻辑,不是云托管产品在外面套的一层 autoscaling。
HMaster 不会自己去申请一台机器,balancer 也不会因为某个 chunk 变冷就把一台机器还给数据中心。它们的优化目标始终是"在给定的机器里把分片摆得更均匀";。
机器从哪来、有多少、何时增减,是运维的事,是云控制面的事,不是传统数据库内核的事。
Milvus 在这套范式里走得相当靠前——QueryNode 是无状态的,sealed 数据全部落在对象存储,节点不持有不可丢失的状态,加机器、迁 segment 理论上很快。
但即便如此,它依然假设机器由外部管理,而不是由 coordinator 自己决定该不该存在。
这背后是一个开源数据库的设计边界问题:一个要"到处都能跑"的开源数据库,不可能假设底层一定有弹性实例,不可能知道用户是否愿意为 standby 节点付费,也不可能把某个云厂商的配额、计费、实例生命周期、region 可用性写进内核。
因为开源必须足够通用。通用,就意味着它不能把资源管理当成内核的第一等公民。
但 episodic workload 把这个假设逼到了墙角。固定池里的负载均衡做得再好,也改变不了节点大部分时间空转的事实。突发请求到来时,在池子里搬 segment 做重平衡,也永远追不上直接拉一个新节点,把请求导过去。
问题不再是"已有资源怎么摊得更均匀",而是"资源此刻该不该存在"。
这句话听起来简单,但它的答案根本不在传统数据库内核里。它只能被设计在云控制面里,与我们的配额、计费模型、region 可用资源息息相关。
开源数据库在数据和任务两个维度上调度得很好,但天生缺少资源这第三个维度。
因此,我们基于Milvus推出了更商业版的Zilliz Cloud ,又将Zilliz Cloud 进化为了如今的vector Lakebase形态,它能够集数据管理、任务调度以及资源分配于一体。
对内,我们给如今进化为Vector Lakebase形态的Zilliz Cloud 取了工程代号叫Kite ,Milvus 在生物学里是鸢属猛禽的拉丁学名,Kite 正是它的英文俗名。同一种鸟,两个名字。能力上,他们使用的是同一份 SDK,同样的 collection、index、search 语义。但Kite 为云重写了资源模型,所以它像 Milvus,但不是 Milvus。
顺带一提,Kite 在英文里也是风筝,能够在需要时放出去,不需要时收回来。就像我们在云上的资源弹性利用一样。
前面说清楚了 episodic workload 的本质,以及开源数据库在资源管理这个维度上的缺失。
遵循这些约束,我们在设计Vector Lakebase时,确定了四个关键决策:
一、存算分离,接受冷启动。
冷数据需要把存储成本要足够低,就必须选择对象存储。因为对象存储最大特点是无查询则无算力开销。
另外,考虑到在早期检索类数据架构中,查询节点与数据通常是强绑定的部署模式。每个节点不仅承担查询计算工作,还会本地存储分片数据。当业务流量波动、需要通过增减查询节点来调整集群算力时,运维侧必须同步完成大量数据的拷贝、迁移与重新分片工作,导致集群扩容缩容的效率被数据体量制约。
为此 ,Vector Lakebase 把固化分片统一持久化至对象存储,查询节点只做无状态计算。依托这套架构,节点可以轻松实现高频扩缩容。
当然,这样做的代价也是冷启动不可避免,总有冷数据被第一次唤醒。这个几秒的代价在很多传统数据库场景里不可接受,但在 AI workload 下反而有空间。RAG 查询、agent memory 检索、上下文召回的 P99 延迟预算通常在几百毫秒到几秒之间,而不是亚毫秒级。这个窗口让"数据在 S3,查询时按需拉起"的模型有了成立的可能。
关于如何设计冷启动,以及控制它的成本,我们在后续章节展开。
二、云核一体,控制面全局池化。
资源伸缩看起来像是管控面的事,但管控面看到的通常是滞后的指标。
一个 load collection 操作可能在几秒内需要大量内存。如果等外部系统检测到内存压力,再触发扩容,load 可能已经因为 OOM 失败了。
Vector Lakebase 的做法是让 coordinator 同时承担数据面路由和资源调度。
在路由一次查询的同一个调用栈上,coordinator 发现目标 Resource Group 是冷的,就可以当场触发拉起,而不是把信号传给另一个系统,再等它慢慢反应。
这需要数据库内核在做路由决策时,能同时看见资源状态,并把要不要分配资源变成同一个系统里的决策。
控制面(coordinator 与 Catalog)本身也必须全局池化,而不是 per-tenant 独占。
如果每个租户都有一套独立控制面,控制面开销会随租户数线性增长,每套又都得常驻,最后把 scale-to-zero 省下来的钱重新吃掉。
池化之后,控制面成本就会和租户数量解耦。更重要的是,系统拿到了全局视野后:哪台物理机有余量,备用池里还有多少可用 pod,哪个 Resource Group 可以共享,信息全都一目了然,调度决策可以在毫秒级完成。
三、多租户算力隔离,三层缓存分级。
多租户隔离不能一刀切。
大量低频 agent workload 并不值得为每个租户常驻一整组独立资源。小租户或流量较低的 collection,可以多个共享同一个 Resource Group。控制面开销低,冷启动快,资源利用率也更高。
但对于流量高、SLA 明确、业务关键的租户,就需要独立 Resource Group。这样一个租户的突发,不会抢占另一个租户的资源。
在每个计算边界内部,数据再按访问热度维护在 COLD、WARM、HOT 三个状态里。
这两层叠加后,系统可以用较低成本同时服务数千个低频 agent 和若干高频核心业务。让不同租户、不同数据,各处其位,各付各的成本。
四、按功能切分计算资源,各自独立伸缩。
写入、索引构建、在线查询,看起来都属于数据库计算,但它们需要的资源完全不同。
写入是 IO 密集,索引构建是 CPU 密集且突发,在线查询是内存密集且延迟敏感。
如果三类任务混在同一批节点上,规格只能迁就最贵的那一种。扩容时也会互相抢资源:写入高峰拖慢查询,索引构建挤占内存,查询压力反过来影响 ingestion。
Vector Lakebase 在设计上,把写入节点、查询节点、索引构建节点分开,各用合适的规格、按各自的访问模式独立伸缩,日志和 Catalog 存储也从计算层剥离成独立组件——每一类资源都跑在合适的位置上。
四个决策加在一起,就是 Vector Lakebase 的基本设计原则:控制面池化、计算面按需、数据状态外部化、资源按 workload 匹配。但是在接口层,Vector Lakebase 依然保持了和开源 Milvus 完全一致的 SDK、collection、index、search 语义,只有资源模型在内部分叉。
把上面四个决策拼起来, Vector Lakebase的架构就是下面这张图:池化的控制面(coordinator + Catalog)在上,三类计算服务在中,对象存储在下。
查询服务内部按租户拆成多个 Resource Group,每个 RG 的 replicas 在 0 到 N 之间按需变化。
PyMilvus / CLI ──→ Gateway ──→ kite-coordinator · Catalog Svc
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌───────────┐ ┌────────────────────┐ ┌───────────┐
│ 写入服务 │ │ 查询服务 │ │ 索引服务 │
│ StreamNode│ │ RG A RG B … │ │ IndexNode │
└───────────┘ │┌────────┐ ┌───────┐ │ └───────────┘
││ Memory │ │Memory │ │
││ SSD │ │ SSD │ │
││ 0..N │ │ 0..N │ │
│└────────┘ └───────┘ │
└────────────────────┘
│ │ │
└───────────────────┴───────────────────┘
│
▼
┌────────────────────────┐
│ Object Storage │
│ vectors·indexes·manifest│
└────────────────────────┘
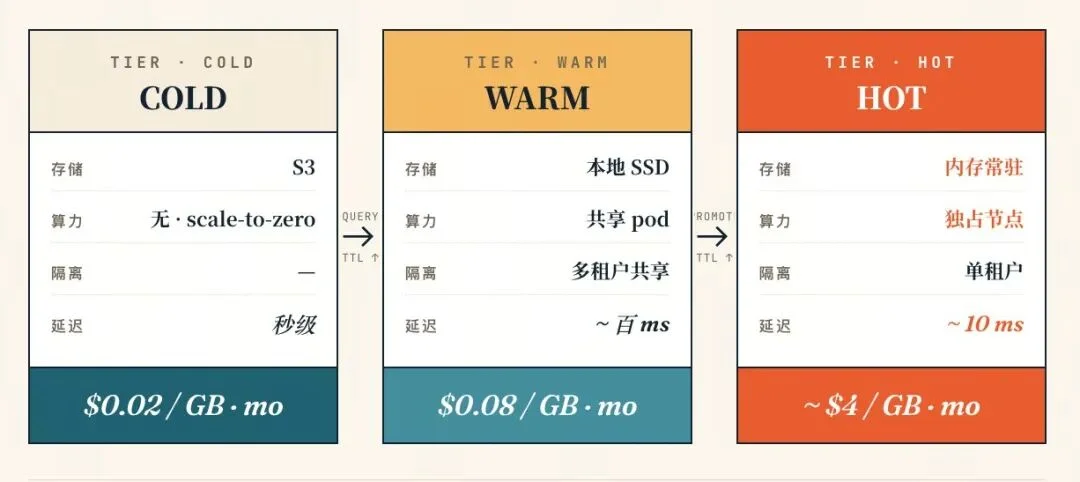
数据的三种状态
每个租户处于COLD、WARM、HOT三种状态之一,状态会决定数据缓存在哪一层、是否有算力、延迟预期是多少。
┌──────────┐ 查询到来 ┌──────────┐ 持续查询 ┌──────────┐
│ COLD │ 认领备用 pod │ WARM │ SSD→内存 │ HOT │
│ │─────────────→│ │ 拉独立节点 →│ │
│ 存储: S3 │ │ 存储: SSD │ │ 存储: 内存 │
│ 算力: 无 │ │ 共享节点 │ │ 独占节点 │
│ 延迟: 秒级│ │ 延迟:~百ms│ │ 延迟:~10ms│
│ $0.02/GB │ │ $0.08/GB │ │ QPS: 100+│
└──────────┘ └──────────┘ │ ~$4/GB │
▲ │ └──────────┘
├───────── TTL 到期 ──────┘ │
└──────────────── TTL 到期(直接)────────────────────┘
三层的单位存储成本差着两个数量级:对象存储约 $0.02/GB·月,本地 SSD 约$0.08/GB·月,而内存(按内存优化实例摊算)约 $3~5/GB·月。
可以发现,把 1GB 冷数据压在内存里,比放在 S3 上贵近两百倍,而这也是大部分企业选择冷热分层的全部理由:99% 几乎不被访问的数据,必须待在最便宜的一层。
WARM 和 HOT 的核心区别是两个维度:存储介质(SSD vs 内存)和隔离方式(多租户共享 vs 独立节点)。WARM 是轻量的缓存形态,多个低频租户共用一组节点,SSD 上有数据,查询到来时 mmap 进内存即可服务。HOT 则是重量级 provisioned 形态,租户独占算力,index 常驻内存,可以支撑持续高 QPS。
不过,WARM 和 HOT 数据的 TTL 到期后,又都直接回到 COLD,不经过中间状态。
写入路径
写入走的是一条标准的 WAL-first 路径:
Client ──→ kite-coordinator ──→ StreamNode (写入服务, IO-bound)
│
┌──────────────────────┴──────────────────────┐
▼ ▼
WAL append ──→ ObjectStorage 异步触发 IndexNode (索引服务, CPU-bound)
(落地即返回, p50 ~200ms) IndexBuild ──→ SealedSegment ──→ ObjectStorage
请求经 kite-coordinator 到写入服务,也就是 StreamNode。
数据先写入 WAL,落到对象存储后即可返回,p50 约 200ms。
索引构建交给独立的 IndexNode 异步完成。构建完成后的 sealed segment 同样落到对象存储。
拆开之后,写入和索引可以各自独立伸缩,也不会互相抢资源。写入延迟也只取决于 WAL 落盘,不受索引任务波动影响。而还没来得及建索引的 WAL 数据则在查询时走暴力扫描,对刚写入的少量数据,这点成本可以接受。
读取路径
查询请求进入 kite-coordinator 后,会根据目标数据的当前状态走不同路径。
Client Query ──→ kite-coordinator
│
┌──────────────────┼───────────────────────────────┐
▼ ▼ ▼
HOT WARM COLD
路由到已有 路由到已有 pod 小租户: 现有机器组直接选一台
query pod 从本地磁盘读 meta+索引 大租户: 从备用池认领 pod
内存命中 mmap 加载 从 S3 加载数据
│ │ │
<10ms ~百ms 秒级(首次)
这三条路径的差别,本质上就是数据离内存有多远。
HOT:目标已有常驻 pod,index 在内存,直接路由过去,毫秒级返回。WARM:目标 pod 还在,数据在本地磁盘,读 meta 和索引、mmap 进内存即可服务,百毫秒级。COLD:没有现成算力,需要先拿到一台机器——小租户共享一组现有机器,coordinator 直接从里面选一台挂上去,省掉拉机器的开销;大租户要独立隔离,从备用池认领一台预热好的 pod,再从 S3 按 layout 加载真正需要的那部分数据。
这套路由之外,后台有一个 balancer 持续维护全局水位:它盯着每台节点的负载,在整体偏紧时让 Node Manager 加机器、整体偏空时回收资源,并在节点之间迁移 WARM 数据,避免热点集中在少数机器上、也避免某些机器空占着缓存。
前台的查询路由决定"这一次去哪取数据",后台的 balancer 决定"整个集群该有多少机器、WARM 数据怎么摆"——一个管单次延迟,一个管全局成本。
冷启动慢,通常慢在两件相互独立的事情上:
一个是机器从无到有(拉一台新节点、装好、加入集群),一个是数据从S3到内存(把 segment 和 index 加载进来)。
传统 Dedicated 模式的冷启动之所以可能超过 10 分钟,是因为它把这两件事都做到了最重:临时申请节点,同时全量预加载数据。
要把它的冷启动压到秒级,就需要从机器拉起和数据拉起两手抓起。
先看怎么把"机器从无到有"压到秒级。
标准的 Kubernetes 自动扩容(Cluster Autoscaler)在自动扩容上很吃力:它基于预定义的 node group 扩容,一轮只能扩一个 group;新节点起来后还要拉镜像——Milvus 镜像 1~2GB,就需要30~60 秒。我们实测过,从 pod 创建到容器启动经常超过 2 分钟。
Vector Lakebase 绕开这条慢路径,做了三件优化。
优化一,一个借鉴 Karpenter 思路的 Node Manager:直接对接云厂商的实例 API,用 list-watch 在 2~3 秒内对未调度的 pod 做出反应,按 pod 的真实资源请求挑最划算的机型,省掉 node group 的排队。
优化二,维护一批standby节点——这些实例预先启动、初始化好、把镜像缓存到磁盘之后再停机。需要唤醒时直接 resume,跳过冷启动里最慢的那段,也就是拉 1 到 2GB 镜像的 30 到 60 秒。这样可以把起一台机器从约 90 秒压到约 20 秒。而停机实例只付磁盘费,不付算力费,成本大约只有运行实例的 3%,所以备用池可以准备得比较充足。
优化三是一小批 active 节点。这些节点始终在线,进程预热好。查询打过来时不用 resume,秒级就能接管。合起来是一条从快到省的回退链:先用 active 秒级响应、扛住日常的瞬时拉起;不够了唤醒 standby(约 20 秒、近乎零成本);再不够,才现拉一台全新机器(约 90 秒)。前面读取路径里 COLD 被唤醒时"认领一台预热好的 pod",认领的就是这个备用池。
接下来看,怎么把"数据从S3到内存"压到最小。
这一层不是 Vector Lakebase 自己做的,而是来自它底下的索引和存储引擎。传统模式假设数据必须全量加载才能查,加载量往往是一次冷查询真正需要的几十上百倍;而 Vector Lakebase 用的索引和存储反过来——一次查询只搬它真正需要的那一小块。
一次冷查询,只读真正需要的部分
标量过滤 向量搜索
┌──────────────┐ ┌──────────────┐
│ 倒排索引 │ │ IVF 聚类 │
│ block 为单位 │ │ 数据切成 bucket│
│ minmax 剪枝 │ │ 只取最近的几个 │
└──────┬───────┘ └──────┬───────┘
└───────────────┬────────────────┘
▼
拉取数据量 < 全量的 1%~2%
│
┌────────────────┼────────────────┐
▼ ▼ ▼
S3 ←——按需流转——→ 本地磁盘 ←——→ 内存
(全量) (warm cache) (hot cache)
└──── 可缓存 · 可驱逐 · IO 全异步流水线化 ────┘
标量侧用谓词下推,倒排链按 block 为单位加载、配 minmax 统计提前剪枝;向量侧用 IVF 家族索引,把数据聚类成多个 bucket,搜索时只拉距离最近的几个。两者叠加,一次冷查询需要拉取的数据量通常能压到全量的 1%~2% 以下。
这些小粒度的数据块会在 S3、本地磁盘、内存三层之间按需流转,可缓存、可驱逐,整条 IO 链路全异步、计算和 IO 流水线化,不让 CPU 和网络互相空等。(索引与存储的详细设计见刘力的索引文档。)
回到开头那个 agent memory 平台。90% 的冷数据不再常驻内存,它们落回对象存储,只有真正被访问的那一小部分占用算力和本地缓存。
同样的查询体验,能让你的账单不再跟数据总量走,而是跟真实访问走,资源真正成为了可以被调度的变量。
先说清楚:这套架构不是万能的。
它是为稀疏访问、分析型、episodic workload 准备的,不是为传统 OLTP 准备的。
对那些 7×24 高频、延迟极度敏感、容不下任何冷查抖动的在线业务,固定算力的 Dedicated 仍然是更对的选择。因为冷启动被降低了,但没有被消灭,COLD 的首次查询依然是秒级、不是毫秒级。
所以坦白讲,这套东西还很早期,调度策略、缓存换入换出的时机、TTL 的自适应都还粗糙,在持续打磨。
我把它写出来,不是因为它已经完美,而是因为它指向的方向让我越来越确信,这条路必须有人走。具体演进方向上,所有的产品发展会沿着三条线重写。
第一是 headless。系统要向上暴露更多信息,让调度有据可依。冷热、访问频率、索引状态、数据布局、资源需求,都不应该被藏在黑盒里。
第二是 serverless。资源要跟着业务走,而不是业务迁就预留好的资源。真正的弹性不是扩几个副本,而是资源可以出现,也可以消失。
第三是 copyless。减少数据重力,不要让搬数据成为业务的枷锁。
这三条分别落在信息、算力、数据三个维度,但它们指向的其实是同一种能力:流动性。
这也恰恰是今天很多主流形态缺失的东西。On-prem 的算力是恒定的。SaaS 弹性的代价是把计算资源整个塞进黑盒,用户仍需为资源付费。
就连云厂商也只有半只脚迈进了弹性与流动性的大门,因为真正做到资源流动的,往往是 S3、DynamoDB、EKS 这些底层能力,基于它们之上的很多托管产品,骨子里仍然是集群模式加一套负载均衡,弹不动也缩不掉。
所以,不是简单的产品上云,就等于弹性了。弹性需要产品整体为流动性重新设计。
过去,我们都为这种"资源给定"的虚假弹性付出了太多的资源成本,当然,也很多人看到了这个问题,但也有意无意的忽略了。
但现在这个节点,重新来看这个问题,天时地利人和正当时:业务模式在从交易走到 AI agent。查询pattern 在从 TP/AP 走到 episodic。硬件基础也从本地磁盘走到对象存储和按秒计费的弹性算力。
所有的推倒重来,让我常想起电气刚取代蒸汽的那几十年。
最早的工厂只是把中央那台蒸汽机换成一台大电机,厂房布局原封不动,产能几乎没涨。电真正的红利,要等到工厂围绕"每台机器一个小马达"重新设计、长出流水线之后,才释放出来。
数据库今天也站在类似的路口。
所以回到一开始的思考,开源还有价值吗?还要继续吗?答案是毋庸置疑的。开源仍是我的信仰,也是我们团队会一直坚持做下去的事情。。
如果没有开源,就不会有今天云上的这套系统。Vector Lakebase 并不是站在 Milvus 的对面,它就长在 Milvus 这棵树上。
但一棵树要继续长大,就不能只守着最早的那一圈。新的 workload 会长出新的结构。新的资源模型会长出新的内核。新的商业模式也会倒逼系统重新理解成本、延迟和隔离。
开源依然重要,但它会活在更深的地方。它不一定永远以一个完整商业产品的形态存在,但它会以接口、语义、内核能力、工程共识和开发者信任的方式,成为下一代系统最里面的那圈年轮。
而在这个成长过程中,被淘汰的,是抱着集群时代不放的落后设计,是资源恒定的 on-prem,是传统 SaaS 人为制造的数据 lock-in,以及 license 兜底、而非按需付费的商业模式。更是抱着旧设计、旧部署、旧商业模式不肯放手的惯性。
现在,这棵树,该长出下一圈了,它的名字,叫Zilliz vector lakebase。

栾小凡
Zilliz CTO
LF Al & Data 基金会技术咨询委员会成员
文章来自于"Zilliz",作者 "栾小凡"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
