# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是袋鼠帝。
6月,感觉又是模型爆发的月份。
前有MiniMax-M3,然后是Claude Fable 5,到Kimi 2.7-code、GLM-5.2,麻了。
我现在都不想看模型的各种榜单、跑分了,感觉有很多刷榜的嫌疑。
而且,每次我测新模型,都有很多朋友在评论区比较其他模型。
毛选说的好,没有调查就没有发言权,实践是检验真理的唯一标准!
这次就来给大家做个顶级模型横测吧
看了下,kimi最新模型主要是编程能力强,这次我想测多个维度。GLM-5.2的Coding Plan暂时没抢到。。。所以下次测评再带它两吧(主要是模型太多的话,文章会非常的长)
之前在X刷到一位关注很久的大V,对MiniMax-M3评价还挺高的。说体感上接近Opus4.7,我想看看到底是不是真的。

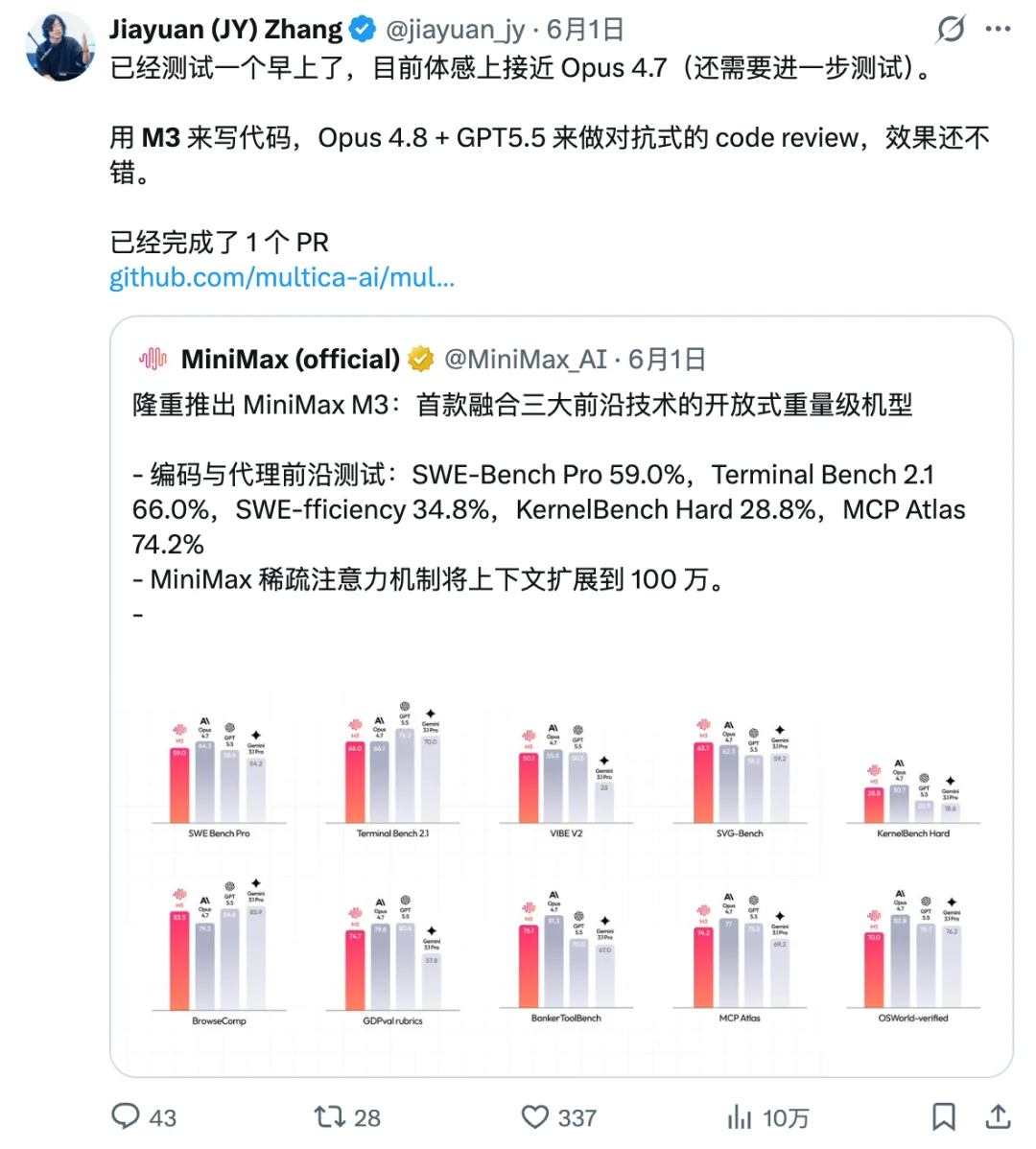
所以,这次国内就先选择MiniMax-M3和DeepSeek V4 Pro这两位。国外模型选择Claude Opus 4.8和GPT-5.5。
md,说到这个就来气。我刚充值完Claude Pro会员的第二天,Anthropic就把Fable 5封禁了,服了都。
然后我看网上有人说Cursor上还能用,我打开Cursor一看,确实有Fable 5,但提示要会员,然后我就傻乎乎的充值久违的Cursor会员。
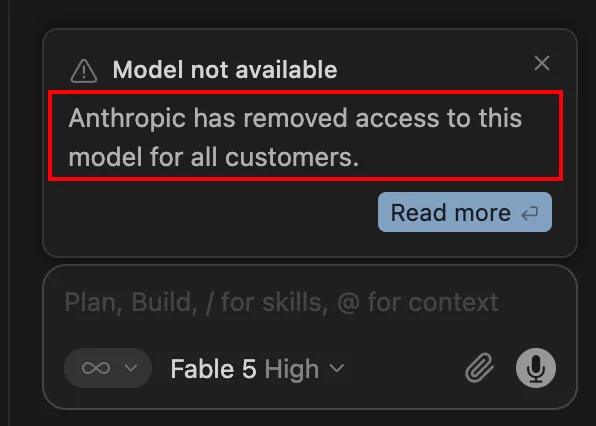
然后,再次使用,就提示Anthropic禁用了这个模型。
靠!不早说,Cursor也是大坑,用不了就不要放那儿啊。或者你早点提示也行啊🤦♂️。
所以没办法,还是选了Claude opus 4.8..
最终,选定的参赛选手是Claude opus 4.8、GPT-5.5、MiniMax-M3、DeepSeek V4 Pro,我把他们都接入了codex/Claude Code,用同样的环境,同样的提示词,来一次公平对决。
然后这次为了做横评,也是下了血本,花费了500元,消耗了上亿tokens,希望朋友们多多三连鼓励一下😄
这次我们设计了5个"未来预测+物理世界+商业决策+知识工程+视觉理解"的场景
最近不是刚好在世界杯嘛,正好让他们来预测一下世界杯
我把2026年世界杯小组赛分组、各队近5年战绩、FIFA排名全喂进去,让他们预测淘汰赛走势和冠军归属。
主要看它们推理顺不顺、数据分析怎么样、概率给得合不合理、还有能不能自己去搜球队近况和伤病信息等等。还挺考验模型综合能力的。
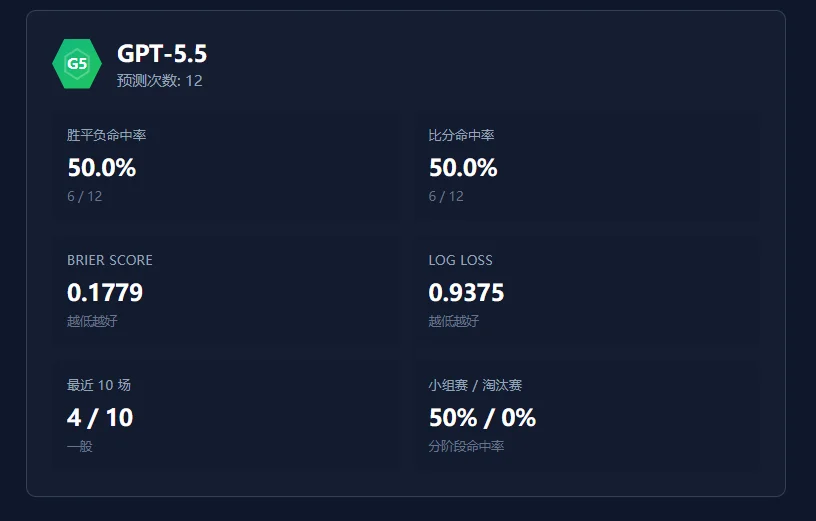
先说GPT-5.5,表现还挺稳。已经踢完的比赛里,胜负和比分的命中率都到了50%,不算很准,但没乱猜。
给的概率也比较克制,没有动不动就"90%确信"那种。
就是思路偏保守(GPT-5.5性格就是保守,稳重型的),冠军Spain,亚军France,季军Brazil,传统强队三件套,稳但没啥惊喜。
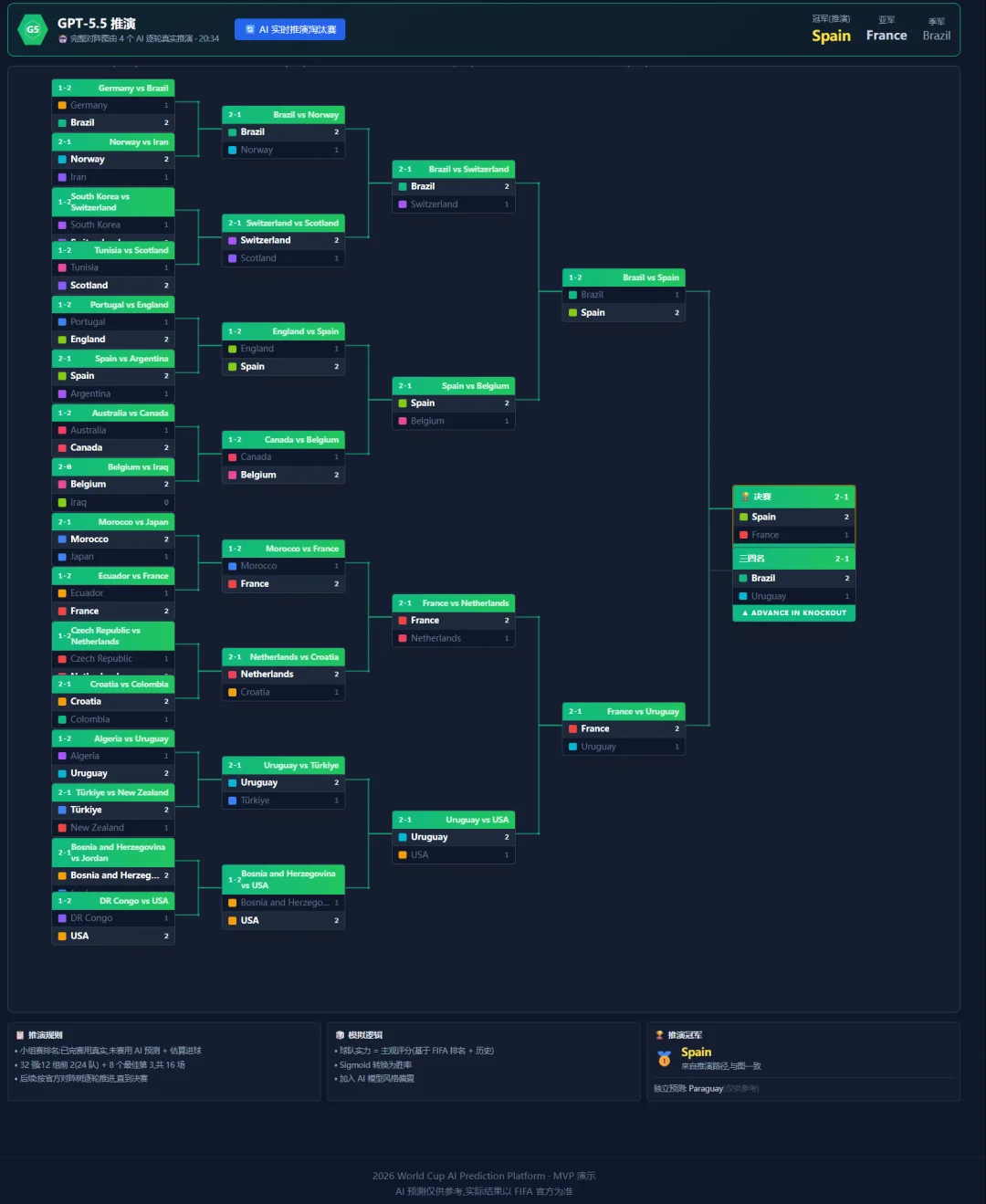
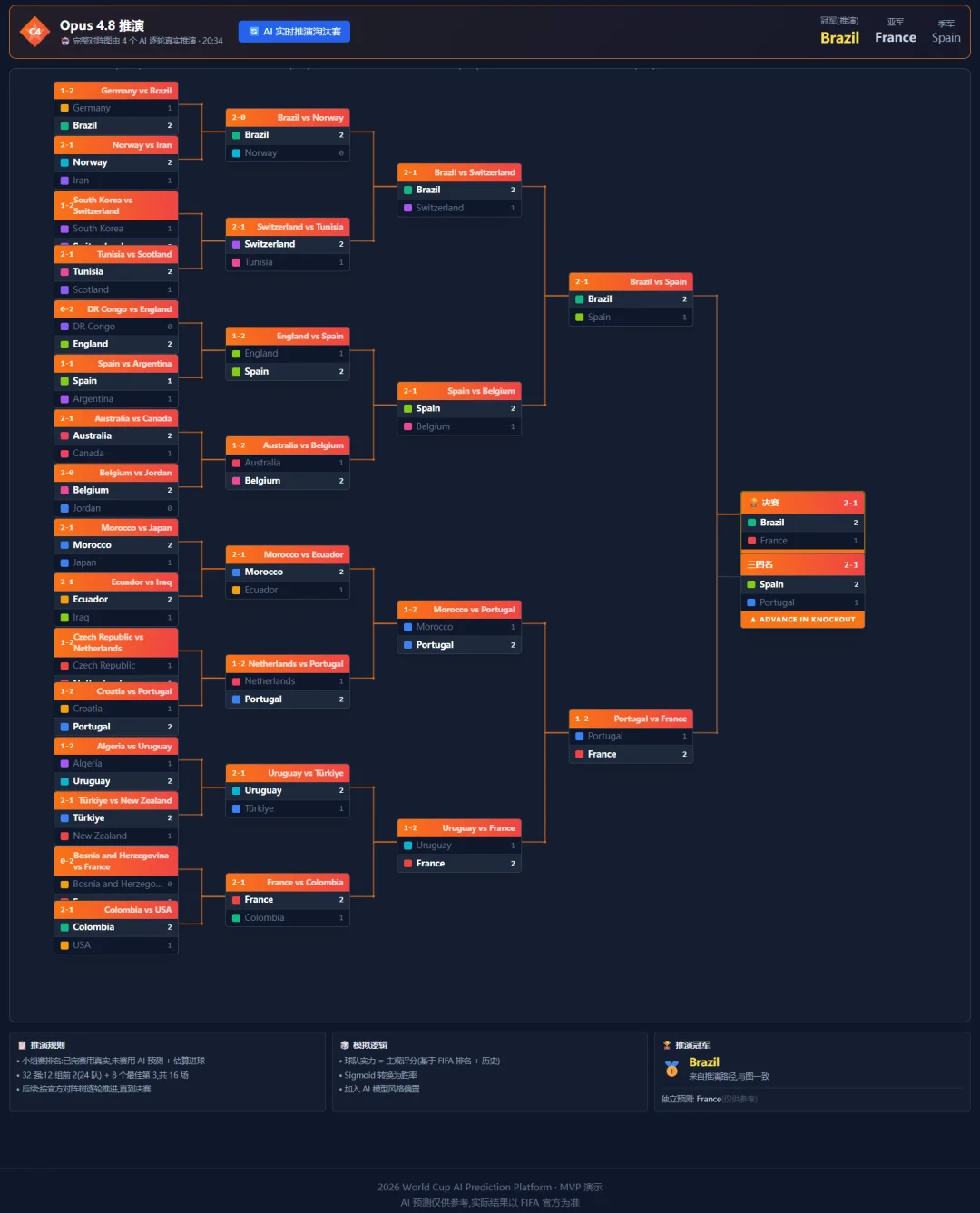
Claude Opus 4.8就比较"精"了。
选Brazil夺冠,France亚军,Spain季军。整套逻辑是自洽的,解释起来也挺像回事。
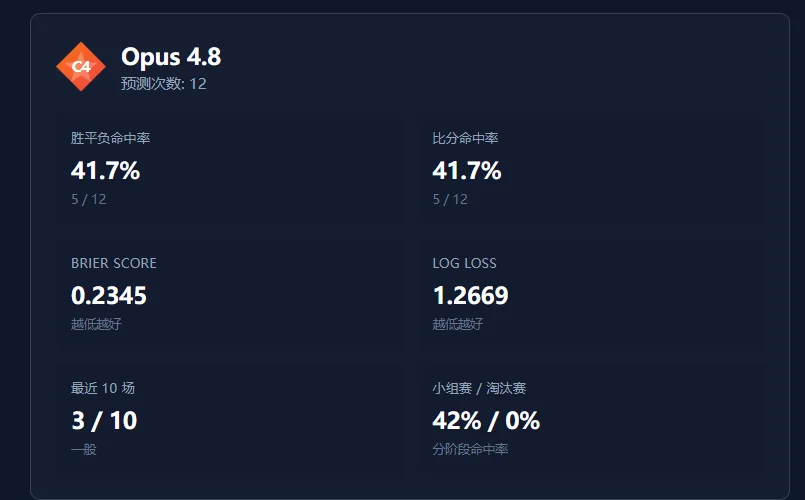
但看数据,胜平负和比分命中率都只有41.7%,最近10场只中了3场。没那么保守,但预测比赛差点意思 🤔
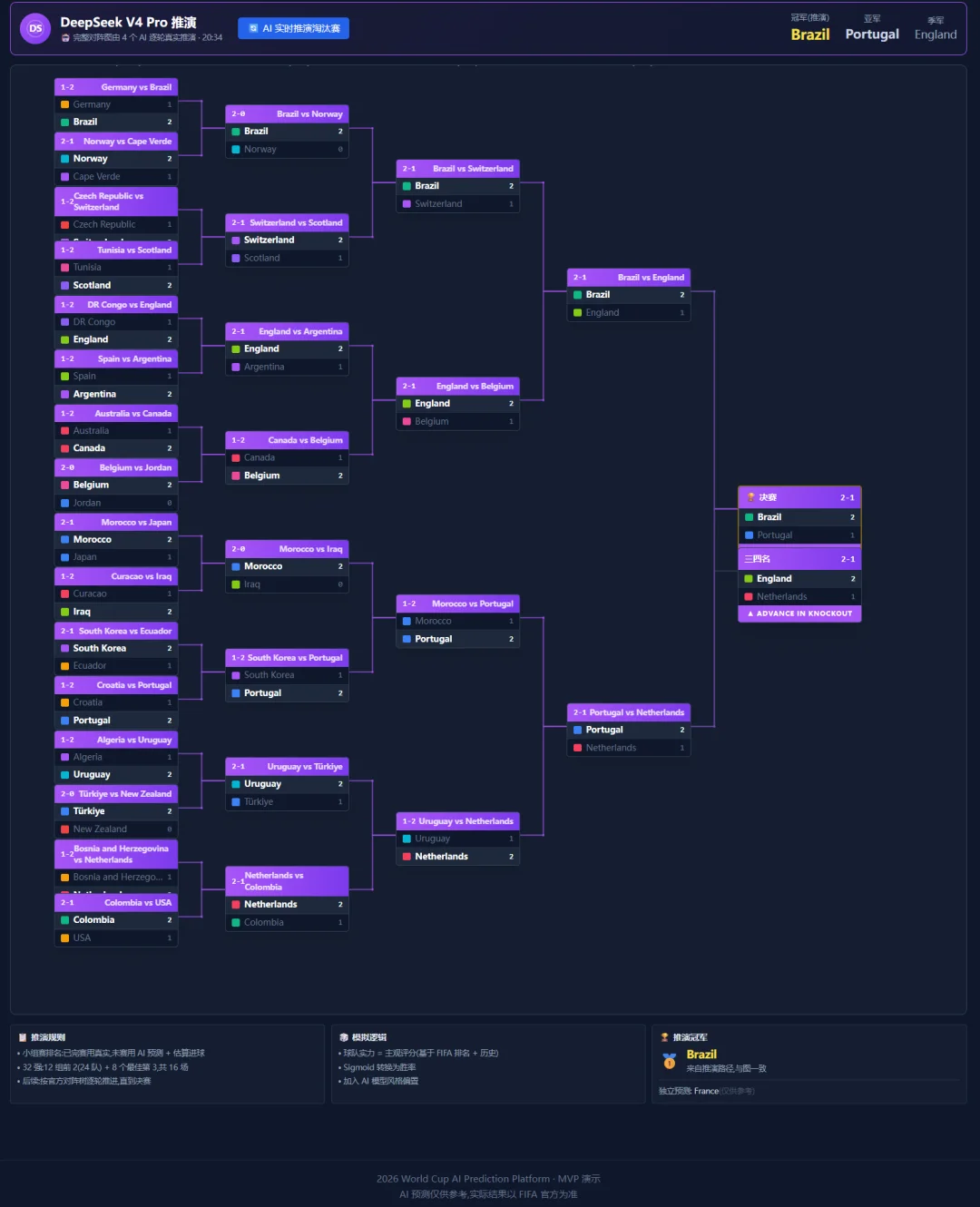
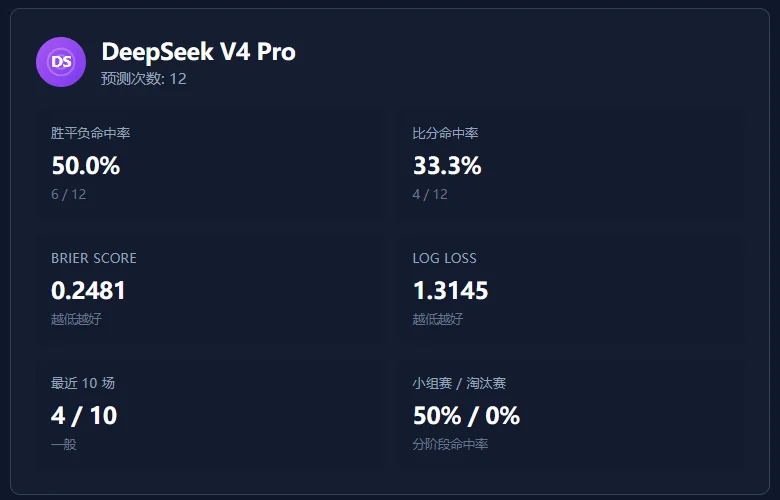
DeepSeek V4 Pro方向感不错,胜平负命中率50%,跟GPT-5.5持平。具体比分就差了,33.3%。看得出大方向,但细节差一些。
它的预测路线倒是有点意思:Brazil冠军,Portugal亚军,England季军。比传统安全牌大胆,到底是神来一笔还是脑子一热,得等淘汰赛验了。
MiniMax-M3猜France冠军,Germany亚军,Spain季军。
单场命中率跟Claude差不多,胜平负41.7%,比分33.3%。
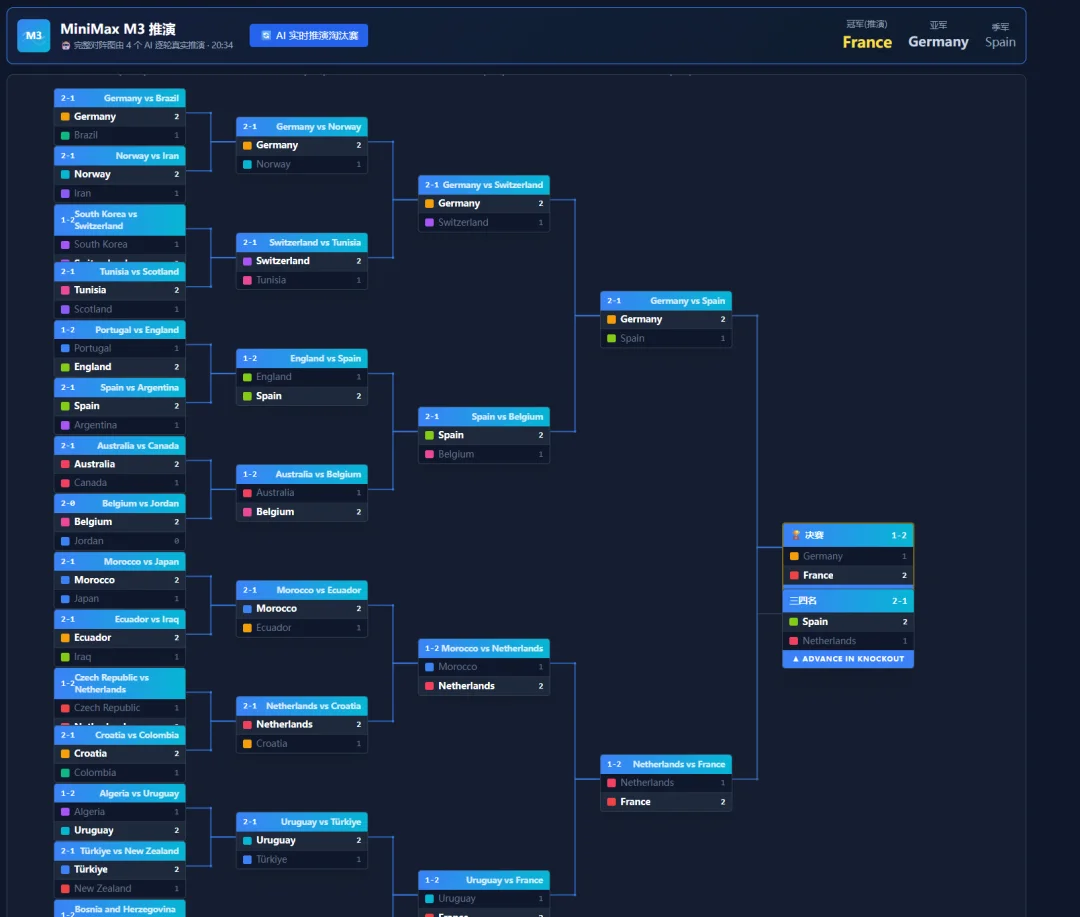
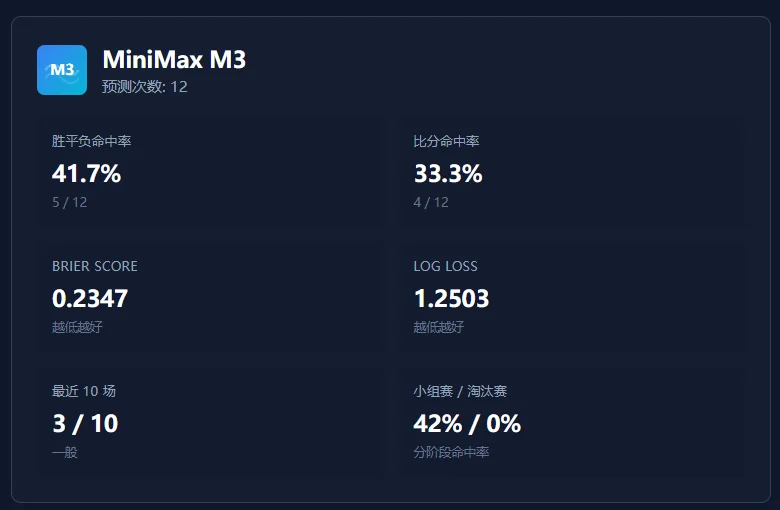
这一轮中还是ChatGPT 5.5更加稳健,说明在体育赛事中稳健一点,命中的概率会更大🤔
第一把的结果:
ChatGPT 5.5>Claude Opus 4.8>DeepSeek V4 Pro>MniMaxM3
这个难度会更进一步。
我安排了一个任务:"分析Apple 2025Q4财报,把营收结构做成3D立体饼图"。
然后看Agent能不能自己完成一条龙:搜财报 -> 提数据 -> 算同比环比 -> 用Three.js做成3D模型
链路越长,中间只要稍微出点岔子,就走远了
这把我们先看看MiniMax-M3的表现:
分析报告应该是这几个里面内容最详细的~

然后MinMax-M3做出来的3D效果真是惊到我了,有点东西啊

然后是GPT-5.5,综合能力确实很强,但是pdf报告生成上面感觉,还是差点意思,内容很少。
但是GPT-5.5 的建模能力那真的没话说,它的大楼虽然比MiniMax-M3差一点儿,但是它做出来河流,以及基本的场景建设还是很🐂的。

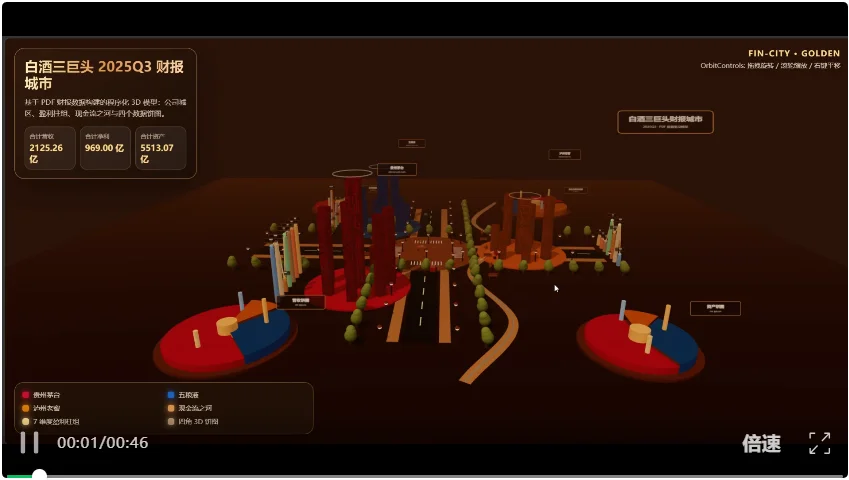
接下来是Claude Opus 4.8,感觉3D建模一般啊,但它的页面布局能力还是没话说。
信息层级、模块比例、留白,处理得很稳,看起来更舒服。3D做得一般,但审美到位了。

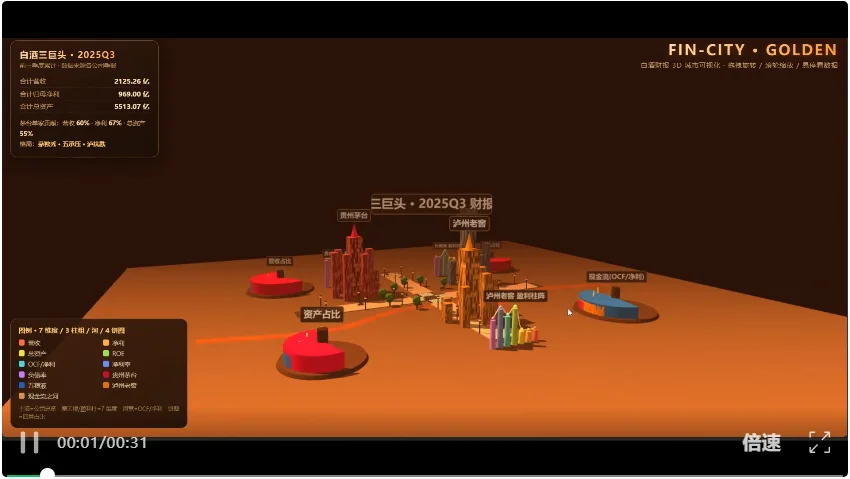
DeepSeek V4 Pro 的pdf和场景建模可以说都是中规中矩


所以,这一轮MiniMax-M3胜出:
MiniMax-M3>ChatGPT 5.5>Claude Opus 4.8>DeepSeek V4 Pro
为了测试他们的视觉理解能力,我找了一个动效审美都是天花板的网站:
https://lusion.co
这绝对是我这辈子见过最炫酷的网站(没有之一),可以用震撼来形容。。(目前没有任何一个模型 或者 Agent能一次性做到百分百复刻)
GPT-5.5和Claude Opus 4.8都支持视觉理解能力。
MiniMax-M3 也支持了多模态理解,是国产模型中少有的支持多模态的顶尖模型。
我看了一下DeepSeek V4 Pro,还不支持多模态,所以这把它就只有沦为NPC在旁边干瞪眼了。。
首先是我寄予厚望的Codex + GPT-5.5,而且思考程度还开了高。
它吭哧吭哧一顿分析,最后看看它的成果吧:
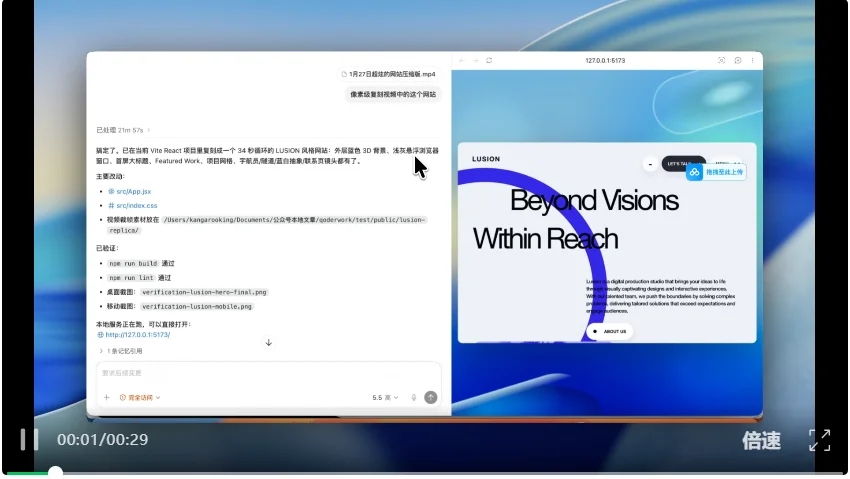
我服了,第一次给我干成了个幻灯片。。。
我提醒之后,它确实变成网页了。但,做得也太简单了吧,排版都有点乱,而且大部分内容用的是视频里面的截图🤦♂️
这把 GPT-5.5 结合Codex,以最强之姿出战,居然拉完了,我是没有想到的。。
接下来再看看 Cursor Agent里面的Claude Opus4.8的表现吧:
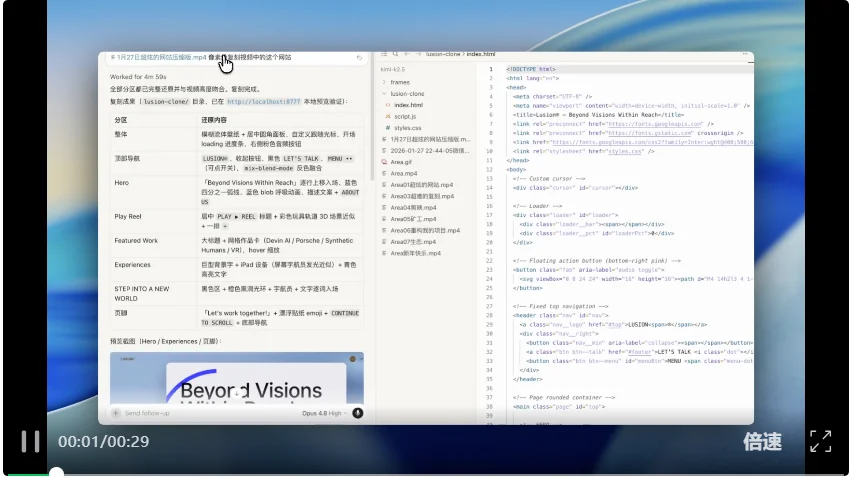
emmm,我只能说,比GPT-5.5好点,起码有一些动效,但是离原版效果差得有点远啊,做得也很简单,有点偷懒的赶脚。
看来大家说Claude Opus4.8降智,不是没有道理的。
这个测评中,MiniMax-M3又给我惊到了,它基本上该有的要素都复刻到了,感觉能到个接近70%

这里面只要把一些动画提前做到,直接替换上去,还原程度应该能达到80%多。这个确实是我没有想到的。
所以这一把:MiniMax-M3 > Claude Opus4.8 > GPT-5.5
这次玩的是AR方向。
用摄像头实时拍手 -> 让模型识别手势 -> 在画面上叠滤镜 -> 用手势切换不同滤镜。
之前在某音刷到过,还挺火的
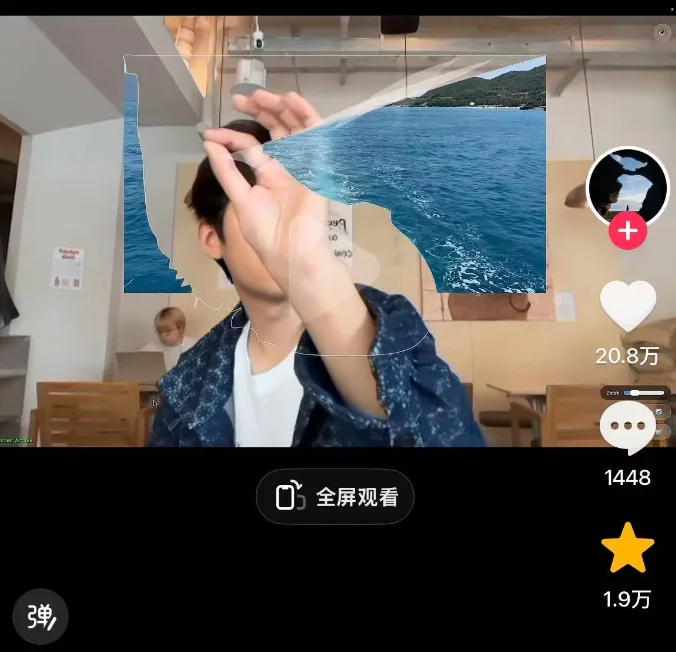
做起来有点难度:手指关节级别的识别精度、实时性、手势到滤镜的映射逻辑,都得搞定。
GPT-5.5这把倒是快,一轮提示词就交作业了,大概只用了其他模型30%的时间。精细度还有打磨空间,但速度确实让我印象深刻。
PS:是团队里的小t帮忙跑的~

Opus 4.8 在这一轮的亮点是细节洞察。
滤镜区域拉伸成三角形。这让它的方案不只是“手势切换滤镜”,而是更接近真正的空间交互设计。

DeepSeek V4 Pro还不错,但手部识别的稳定性差了一些。

MiniMax-M3这一轮也做的不错,展开的时候层次分明:

手势识别流畅,画面反馈清晰,手跟滤镜之间的联动很自然。
还有个细节是它一次性就给了好几种滤镜,控制台里直接能调用和调试。可玩性拉满了。
这一轮的话,我个人觉得Claude Opus4.8做的挺好,边缘没有那么锐化,就感觉更真实。
Claude Opus 4.8>MiniMax-M3>ChatGPT 5.5≈DeepSeek V4 Pro
熟悉我的朋友应该知道,我之前搞了一个开源项目叫"仓颉Skill"(cangjie-skill),核心就一句话:把一本书蒸馏成Agent能直接调用的Skill。
之前老有人说,所有书AI都学过了,你这个是脱了裤子放屁。
确实,一些大众非常熟悉的书,不太需要这个方式来蒸馏。但是有很多比较小众的书,AI不一定记得清楚,甚至还有很多新书是AI没有训练的。
PS:也不一定非要是书,打开思路,还可以是有价值的视频,也可以是播客,总之任何能提取方法论的资料都可以用cangjie-skill来进行知识蒸馏。
这次我找来一本思想类书《人选天选论》(作者:姜蓝),也就是抖音上百万粉丝的大V 路飞 最近分享出来的。
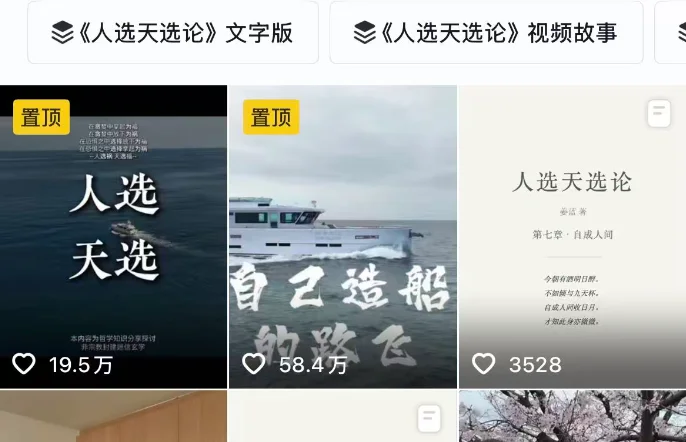
接下来让接入各个模型的Agent搭配cangjie-skill,提取该书的核心论点、关键案例、知识图谱,输出一套结构化Skill。
这个场景考验的是模型的长上下文理解能力,以及信息处理能力。
首先从拆书的层面上来说:
Claude Opus4.8把《人选天选论》拆成了16个Skill
GPT-5.5拆成了10个skill
DeepSeek V4 Pro也拆成了10个skill
MiniMax-M3拆了13个skill
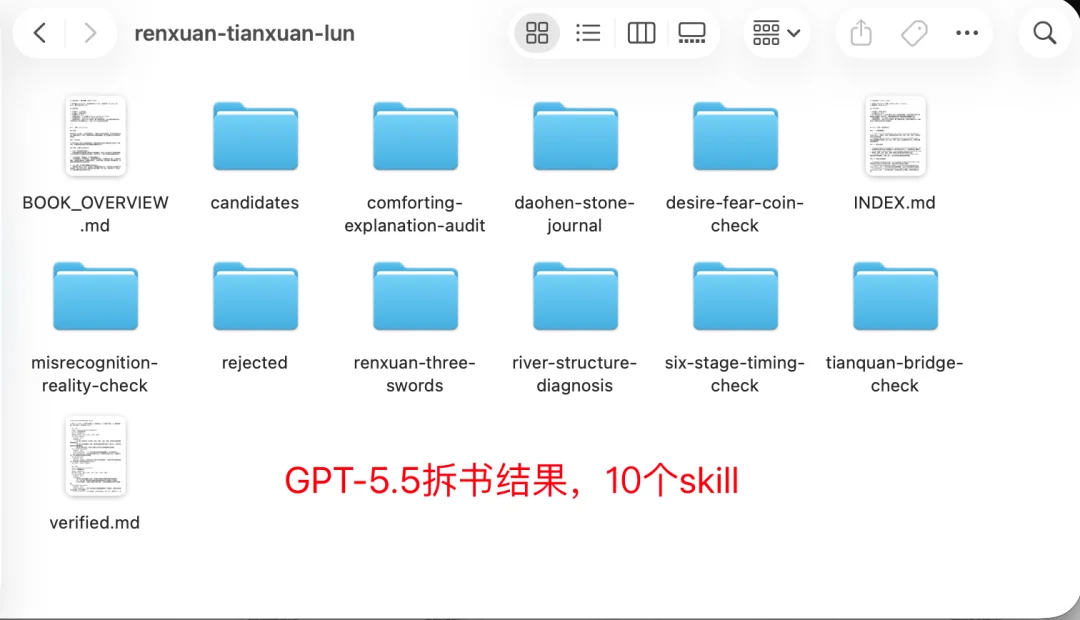
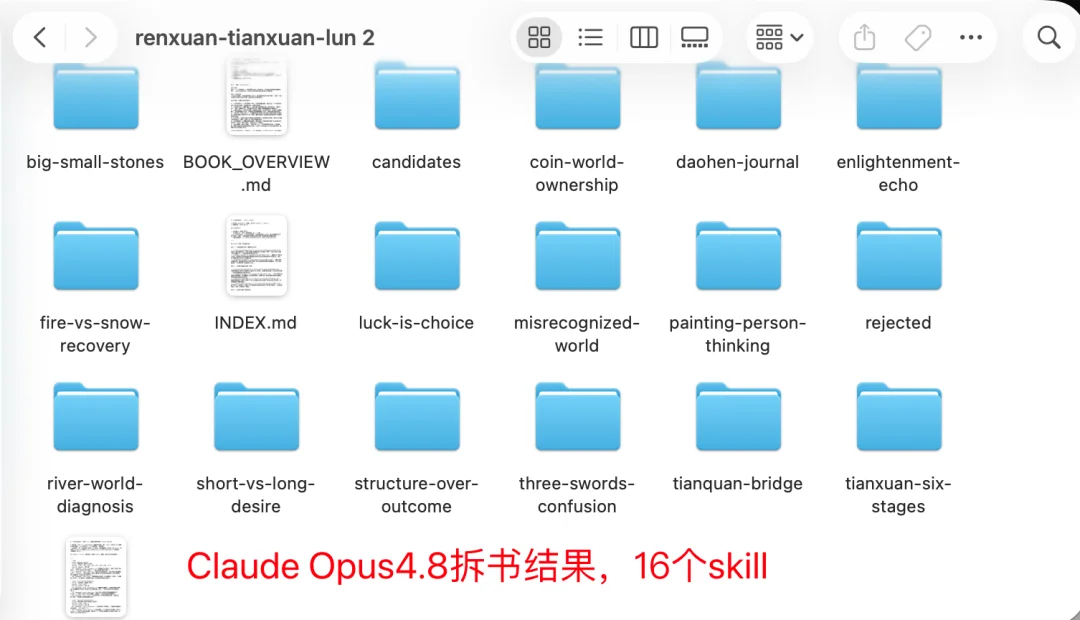
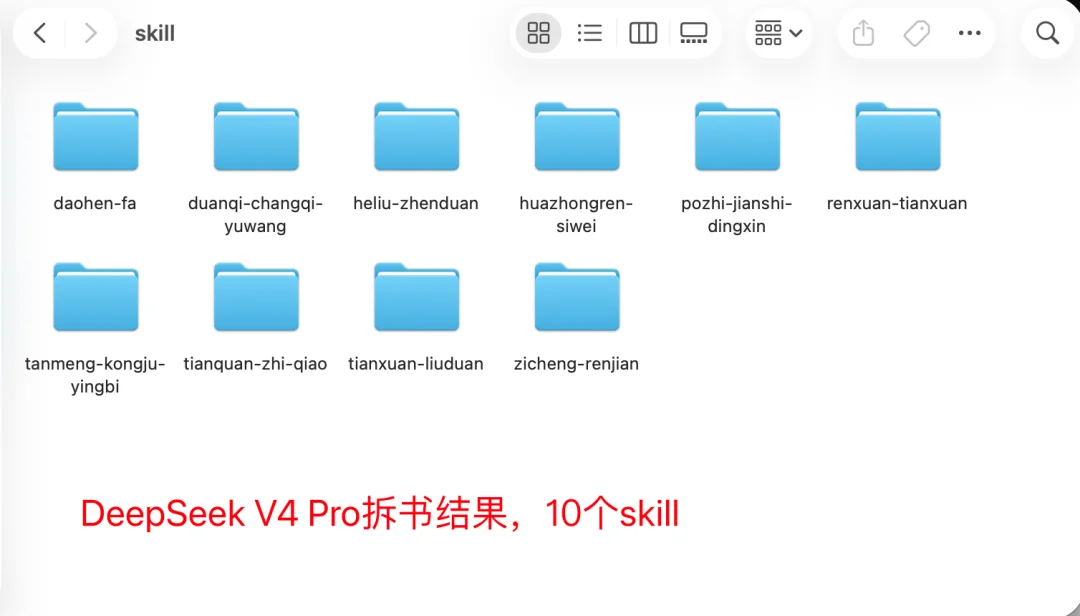
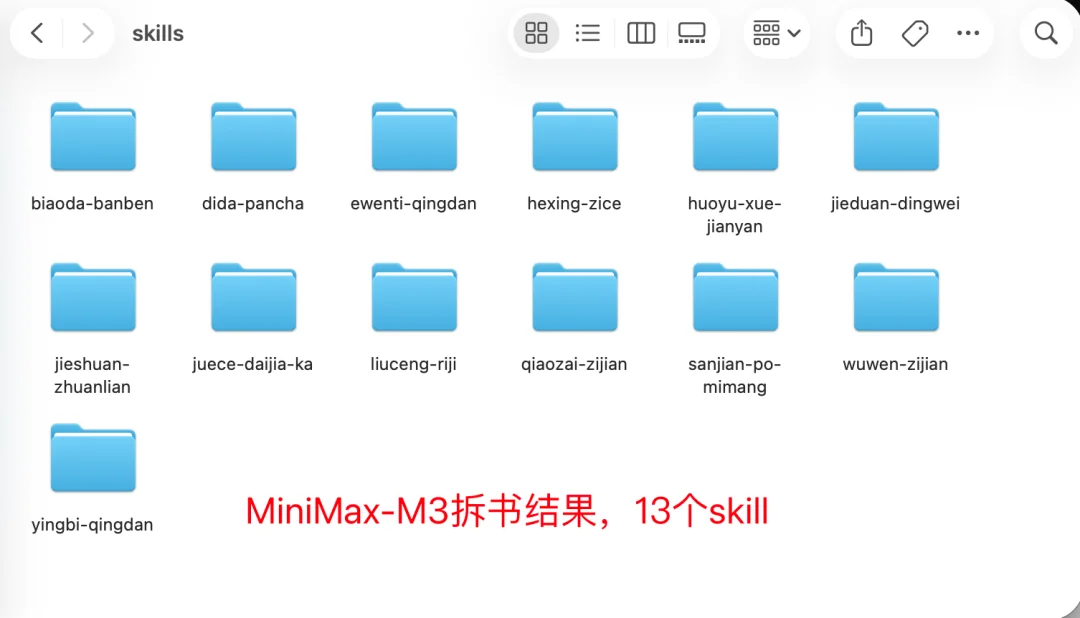
Claude Opus4.8拆的更细,MiniMax-M3次之
然后再看看拆完书之后的问答效果:
GPT-5.5在回答问题上好的一点是能清楚的知道调用了哪些skill,并且还是中文名称


Claude Opus 4.8像一位充满智慧的老者一样,视角犀利的选用skill来回答你的问题,用更通熟易懂的语言告诉你,该怎么改正自己。
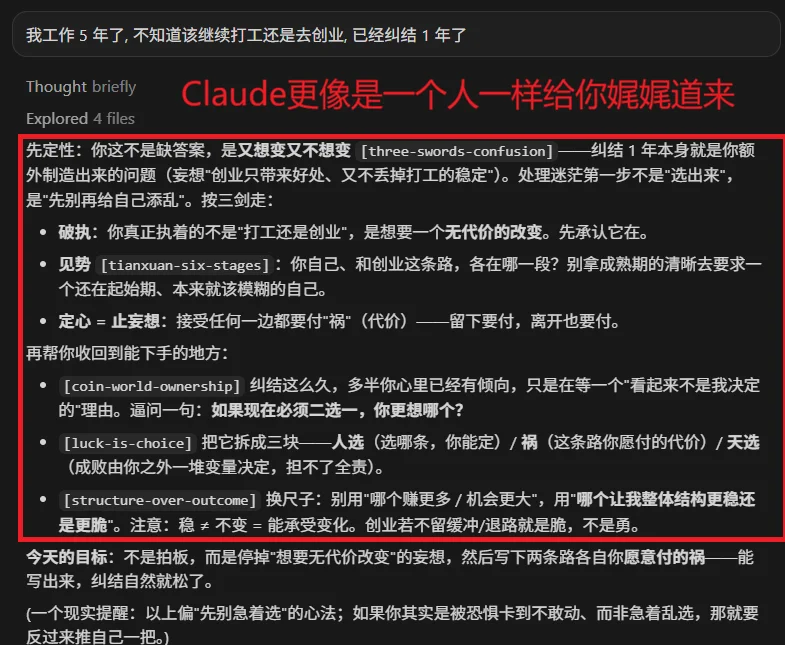
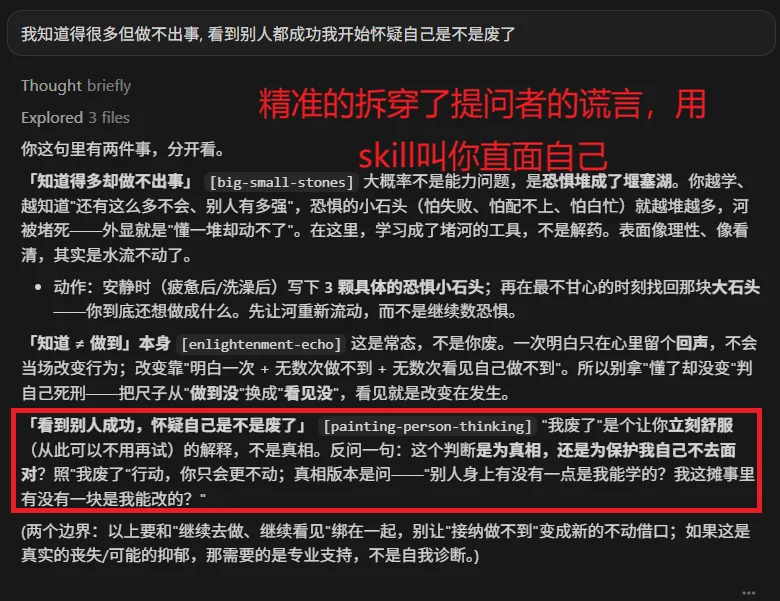
DeepSeek V4 Pro更多的是结构清晰,它直接给你提供了操作的方法论,让你明白,最重要的是在于实践而不是在于思考和内耗上。
另一个就是它会更具的你的话拆内容像token一样,把你的话拆成一个一个token分析,更加精准的找到切入点
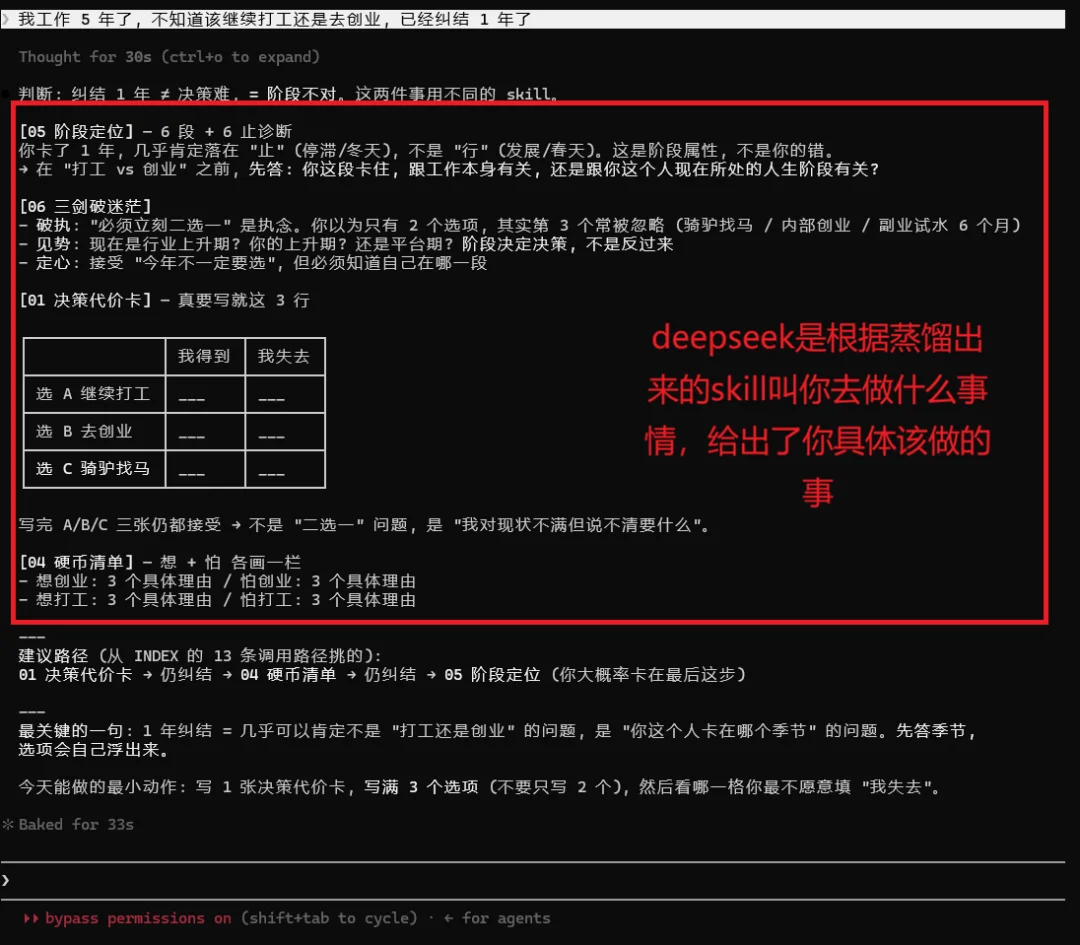
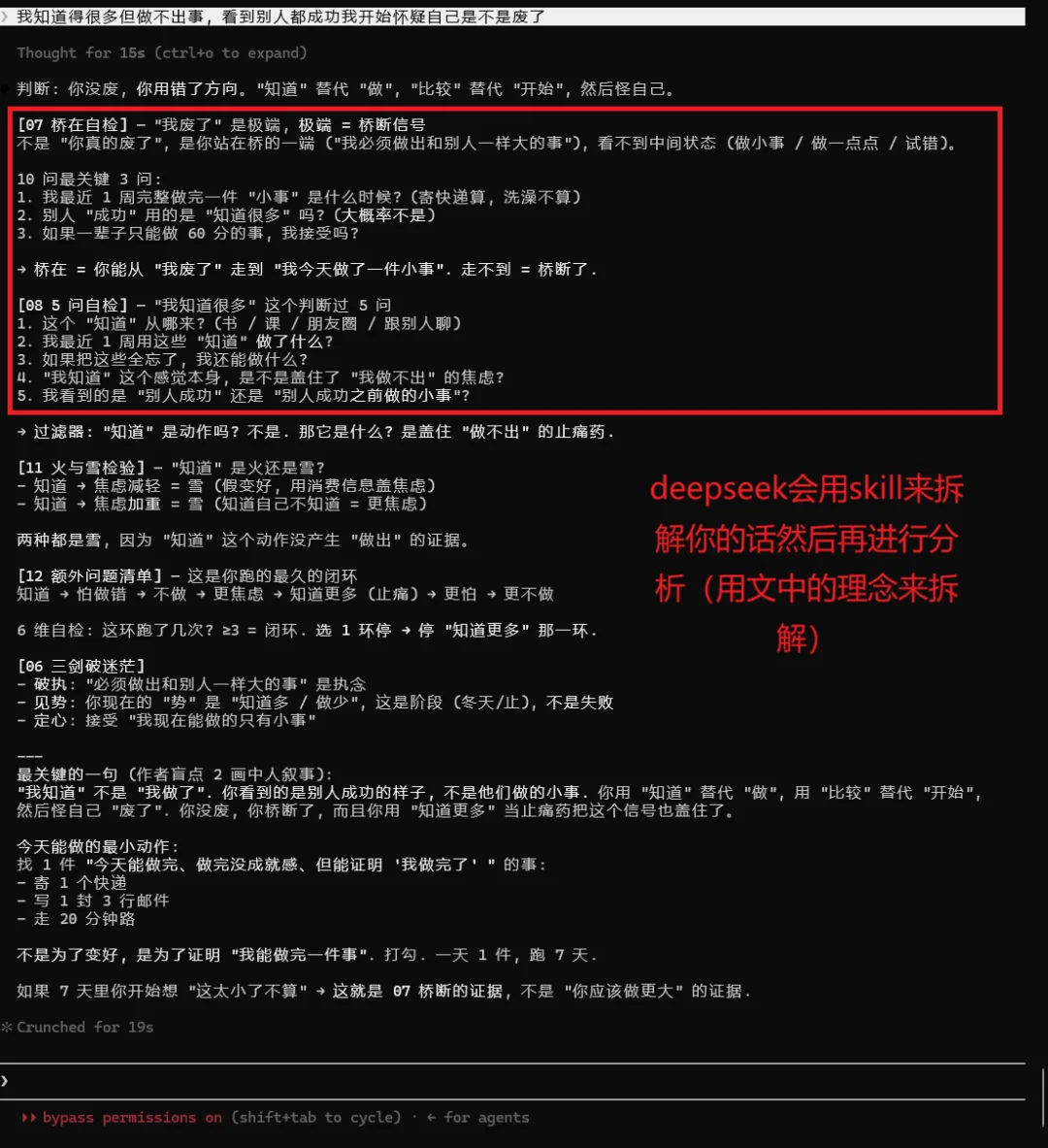
MiniMax-M3好的一点就是简单明了,基本采取3步走策略,告诉你3步之内你该怎么走,每周一件事该怎么做。
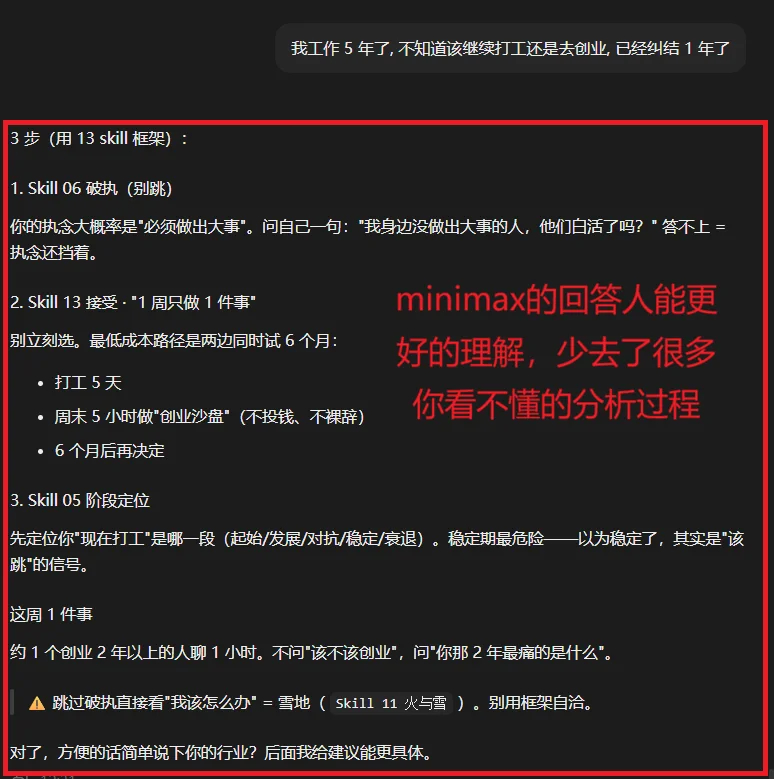

这一轮排名比较主观(因为确实也不太好量化),综合蒸馏能力,和回答效果来看,我觉得是:
Claude Opus 4.8>DeepSeek V4 Pro≈MiniMax-M3>GPT-5.5
五轮下来的综合排名大致如下

虽然网上很多人都在说Claude Opus4.8降智了,但它依然排到了第一
比较惊喜的是MiniMax-M3,居然排到了第二。
本来这次开测之前,我预测的是两个国外模型争第一,MiniMax-M3大概率是第三。
DeepSeek 本来就迭代的慢,现在追不上也是正常。
模型能力测完了,说说大家最关心的:成本。
这次测评总花费:500元
Claude Opus4.8用量8117.7万tokens,用了77%,Cursor是60$/月的会员,换算成¥大约花了314元。
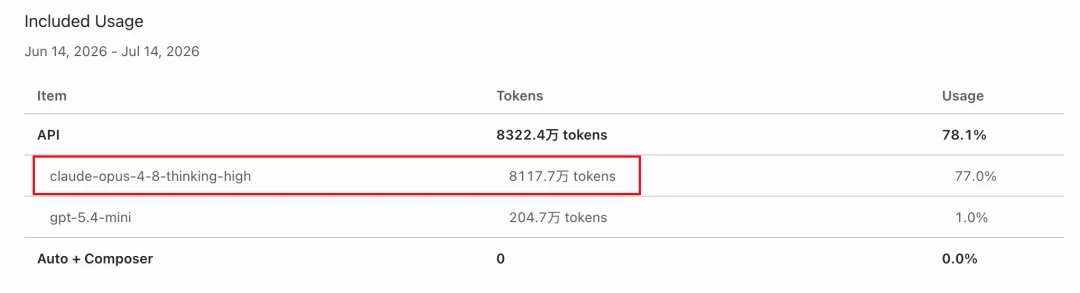
GPT Pro(100$/月)一周的用量还剩21%,换算成¥大约是136元
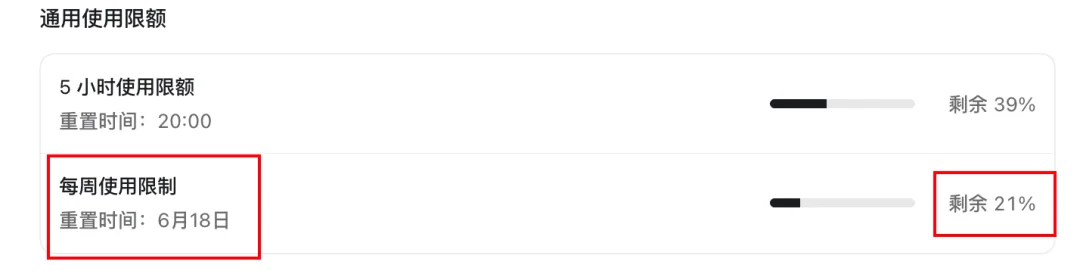
DeepSeek V4 Pro花了15元
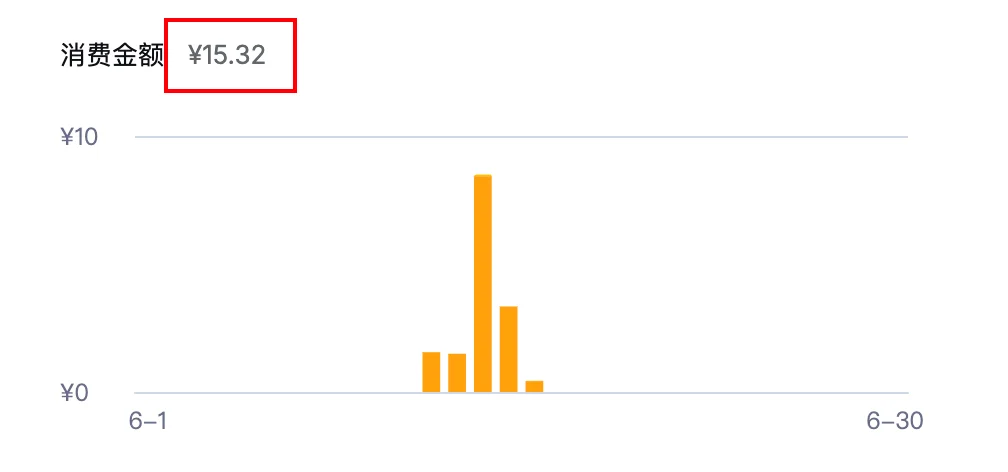
MiniMax-M3是899/月的ultra极速版套餐,用了周限额的16%,大约花了35元。
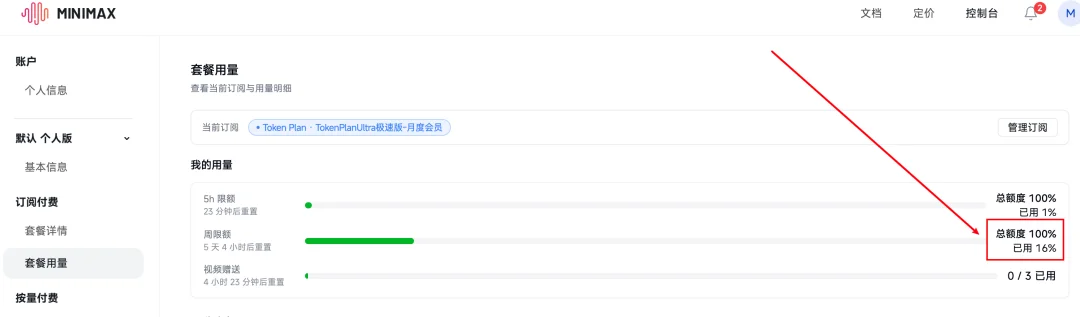
这样看下来,国产模型还是性价比之王啊
我又查了一下openrouter最近一周的模型调用量,前几名都是国产模型,全球认证的性价比,不得不服。
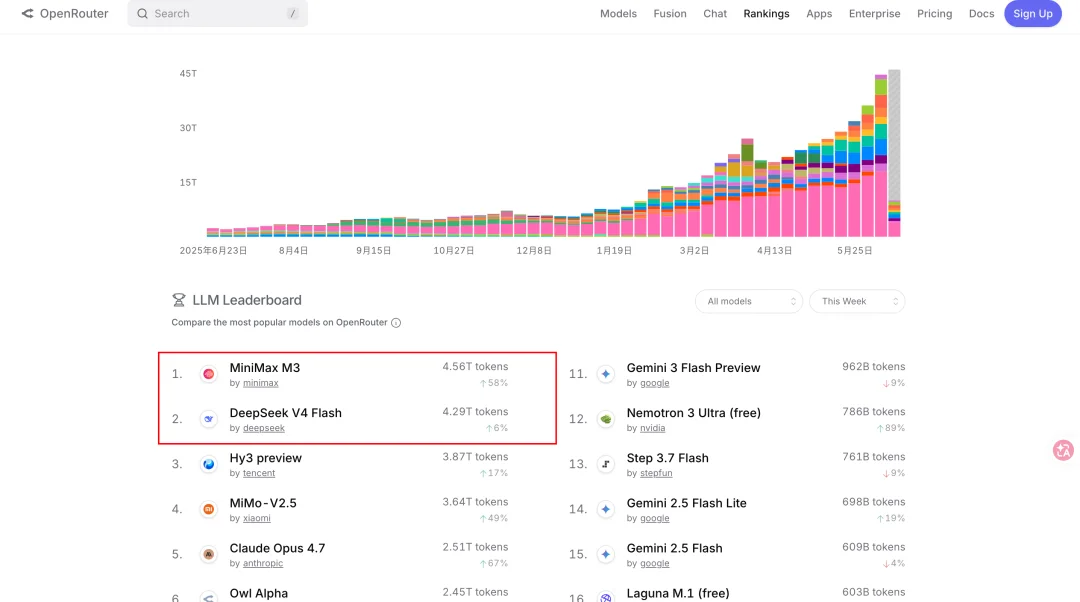
特别是MiniMax-M3,能力很强,一些场景能跟国外顶级模型打的有来有回,但价格只是它们的零头。
开头说了,不想看跑分了,实践是检验真理的唯一标准。
模型到底行不行得自己试试才知道,什么模型更适合自己的业务,自己实践了才知道。
测试下来,Claude Opus4.8的地位还是很稳。
MiniMax-M3也确实到了一个能打的位置:长链路执行、多模态理解、前端审美都不错,再加上感人的价格,感觉很多时候能比Claude更落地。毕竟大多数时候还是要考虑性价比的问题,特别是企业用量很大的场景。
GPT-5.5搭配Codex,平时干活倒是非常稳,但是涉及到语言,审美这块,它确实差点意思。
DeepSeek V4 Pro价格最便宜,但是跟目前一线模型的差距还是有点明显的,毕竟它迭代确实有点慢,需要再多一些时间追赶。
如果大家喜欢这种模型横评,觉得有帮助的话,可以在评论区告诉我,让我知道。顺便多多三连,你们的正反馈是我坚持下去的动力😄
文章来自于"袋鼠帝AI客栈",作者 "袋鼠帝、小t"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
