# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
端午安康
如何让各种 Coding Agent 更好的干活?
在常规的对话外,Claude Code(也可以是 Codex)其实还提供了一些别样的控制(或者说:上下文注入)方法,比如:CLAUDE.md、Rules、Skills、Subagents、Hooks、Output Styles、以及 System Prompt Append
接下来,我会具体聊聊这些奇奇怪怪的东西,用最不绕弯子、最把你稳稳接住🫴的方法,尝试讲清楚这些玩意儿都是个啥,让你最听人话👂的知道:
→ 这些方法各自适合放什么样的指令
→ 为什么在 CLAUDE.md 里写「永远不要做 X」不靠谱
→ Skills 和 Subagents 到底怎么玩
→ Hooks 是怎么做到确定性执行的
→ Dynamic Workflows 怎么让 Claude 自己写编排脚本
此外,最近 Claude 最近还多了一个叫 Dynamic Workflows 的能力,可以让 Claude 自己写编排脚本、协调多个 agent 并行干活,这里也会尝试讲清楚
本文中的图片和部分描述来自 Claude Code 官方文档,有兴趣的话也可以查看原始文档:
Steering Claude Code https://claude.com/blog/steering-claude-code-skills-hooks-rules-subagents-and-more
首先,我们必须要理解大模型的工作原理,简单来说就是【塞进去足够的上文】,模型就能够【给出足够好的结果】:我在央媒的分享:上下文即一切
AI 的能力、问题和用法,本质都由上下文决定。用户发一条请求,AI 把请求和它能拿到的所有材料拼在一起,组成一段完整的上下文,再往下生成结果...循环往复
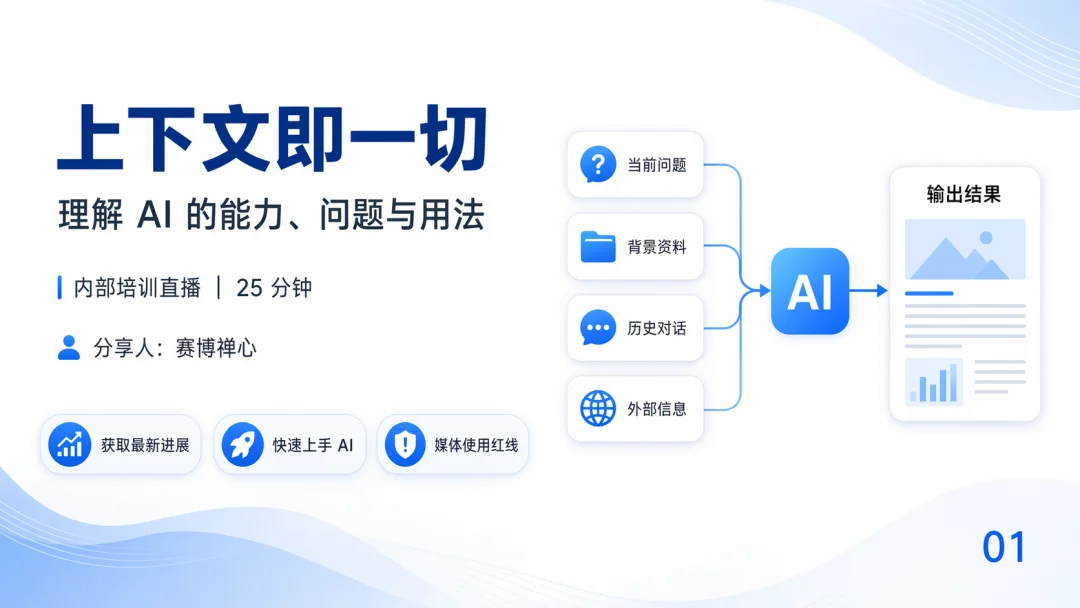
而 Agent,则是在你给到初始的目标、背景信息、限定条件等等之后,它去自己构建上下文
划重点:Agent 和 ChatBot 的区别在一件事上【谁来构建上下文】
ChatBot 靠人喂,你给它什么材料它就用什么材料
Agent 会自己搜网页、读文档、调工具,把有用的内容写进上下文,发现不够还会自动回头继续找
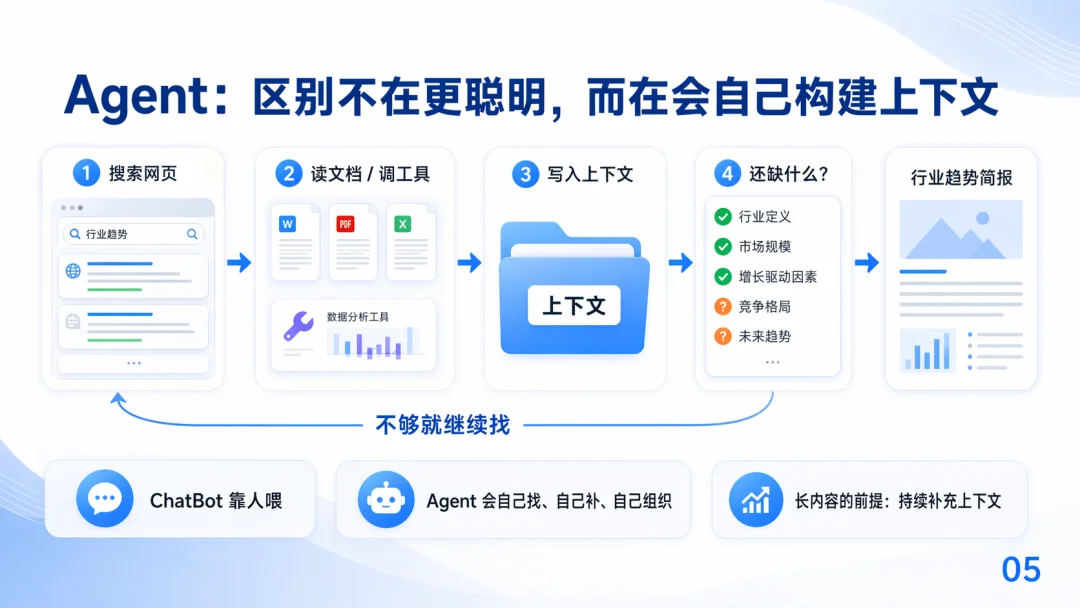
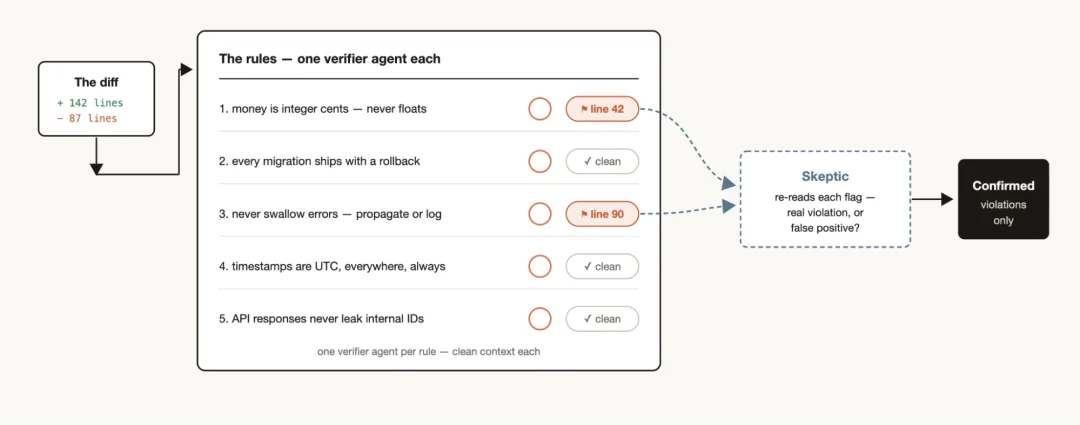
对于 Agent 来说,它只能看到自己上下文内的内容;那么通过一些工程手段,去限定 Agent 在哪些步骤下,能看到哪些东西,就变得尤为重要,于是我们就有了如 claude.md、skill 等上下文注入方法
这里我做了一个表,方便大家更好的进行比较不同的上下文注入方法
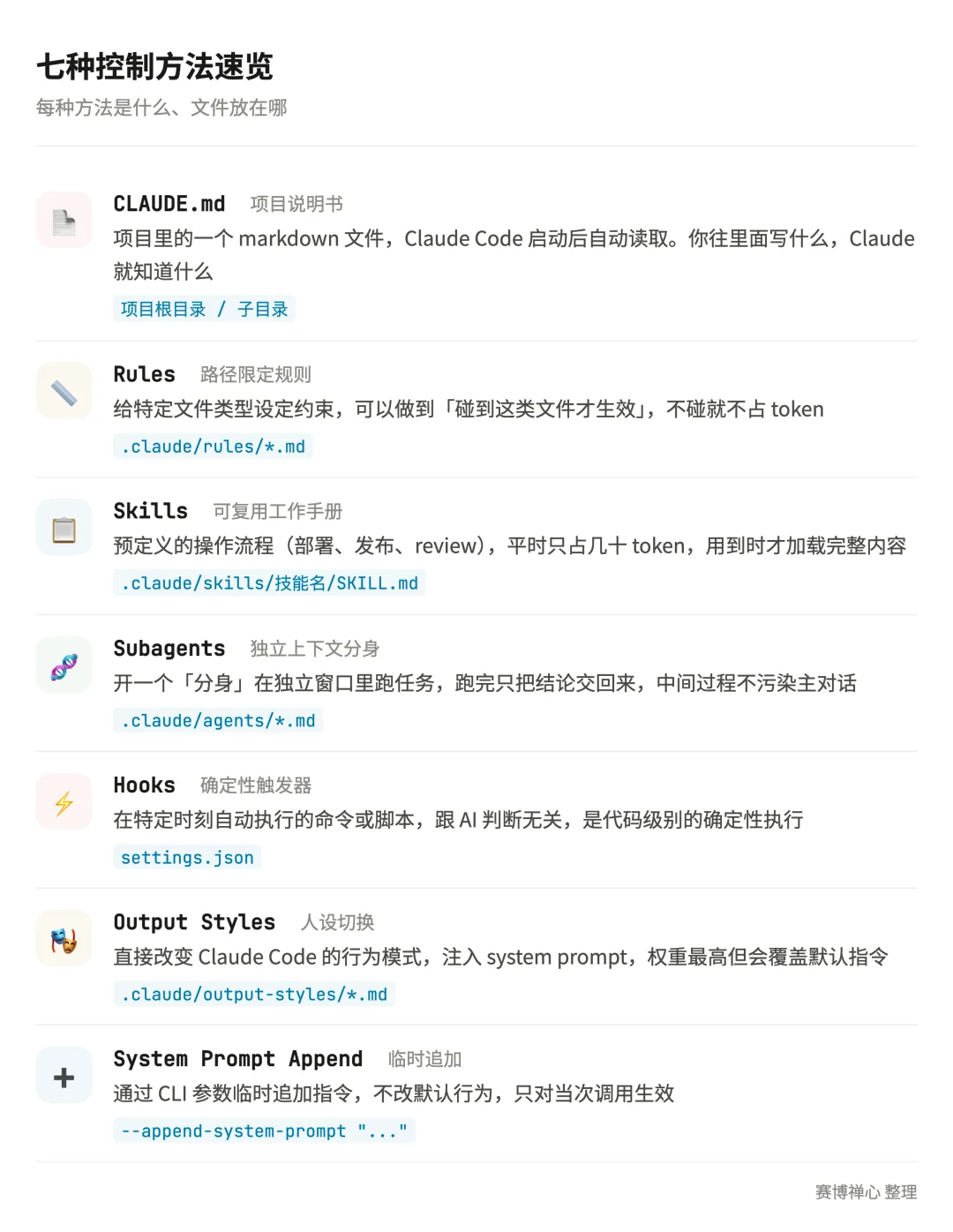
如果追一下这几个东西的设计方法的话,会发现更多有趣的点:
CLAUDE.md 是唯一一个「全程加载、全程占 token」的方法。你写的每一行,不管这次任务用不用得上,都在消耗上下文窗口
Skills 的设计很聪明:只有名字和描述在启动时加载,完整内容等到被调用时才进上下文。用完之后如果上下文满了,最旧的 skill 会被踢掉
Subagents 也是一种上下文注入,它是另起一个对话,在自己独立的上下文窗口里跑,跑完只把最终结果返回给主会话,所以从主会话角度来看,的上下文成本是零
Hooks 完全绕过了上下文窗口。它是代码,由 harness 在外部执行
下面,我们来具体的讲解每一种上下文注入
算是项目的「说明书」,Claude Code 启动时自动读入
【全程都把你稳稳接住】
这东西非常类似于 ChatGPT 里面的 Instruction/自定义指令,或者 API Call 里的 System Prompt,在项目启动时就会读取
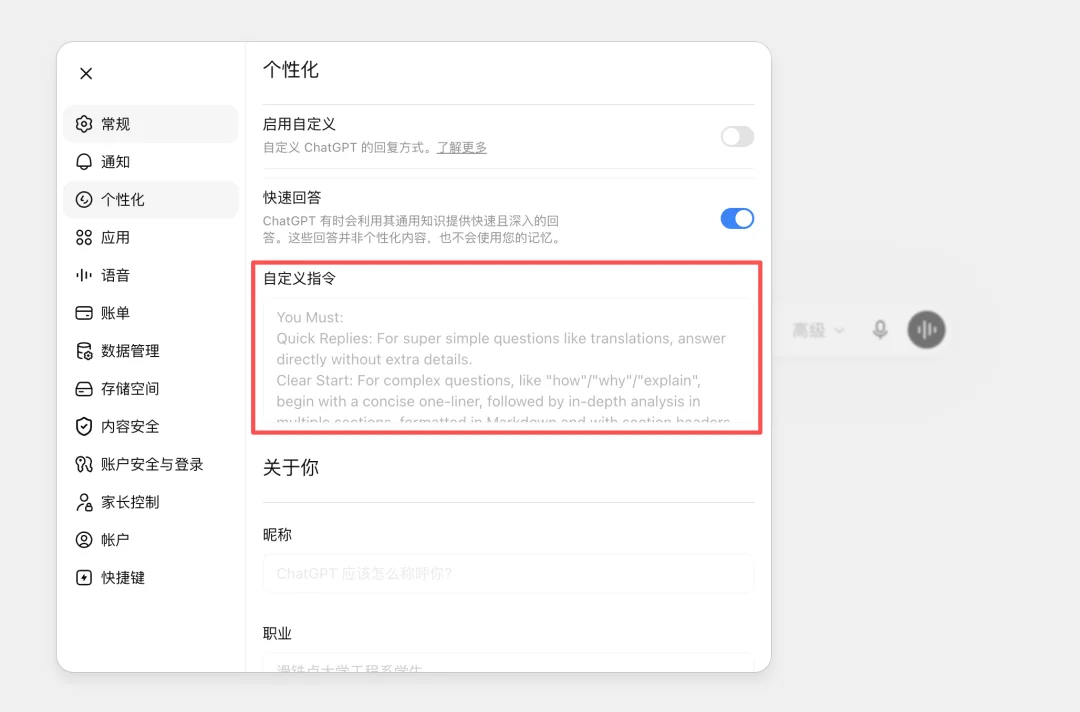
在 Claude 里,这个叫做 CLAUDE.md
在 Codex 里,这个叫 agents.md
这些个文件时放在根目录里的,Claude Code 启动后就会自动读取,你可以在里面去约定一些里面写上构建命令、目录结构、编码规范、团队约定什么的
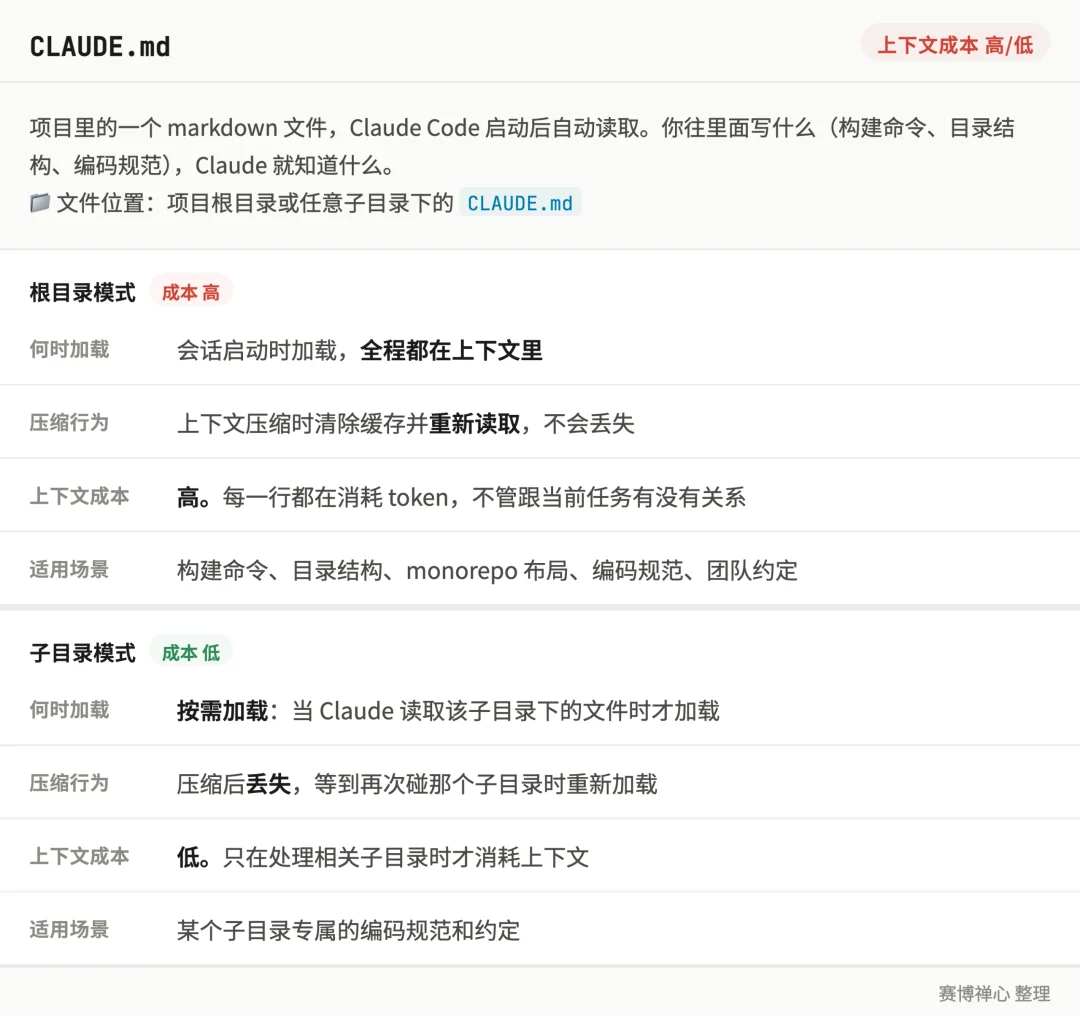
然后这里得说一下,CLAUDE.md 分两种加载模式:
始终加载根目录的 CLAUDE.md,加上你本地个人偏好的 CLAUDE.md。启动即加载,压缩后重新读取,全程都在
按需加载子目录下的 CLAUDE.md(比如 app/api/CLAUDE.md),只在 Claude 读取该目录下的文件时才加载。压缩后丢失,等到再次碰那个目录才重新加载
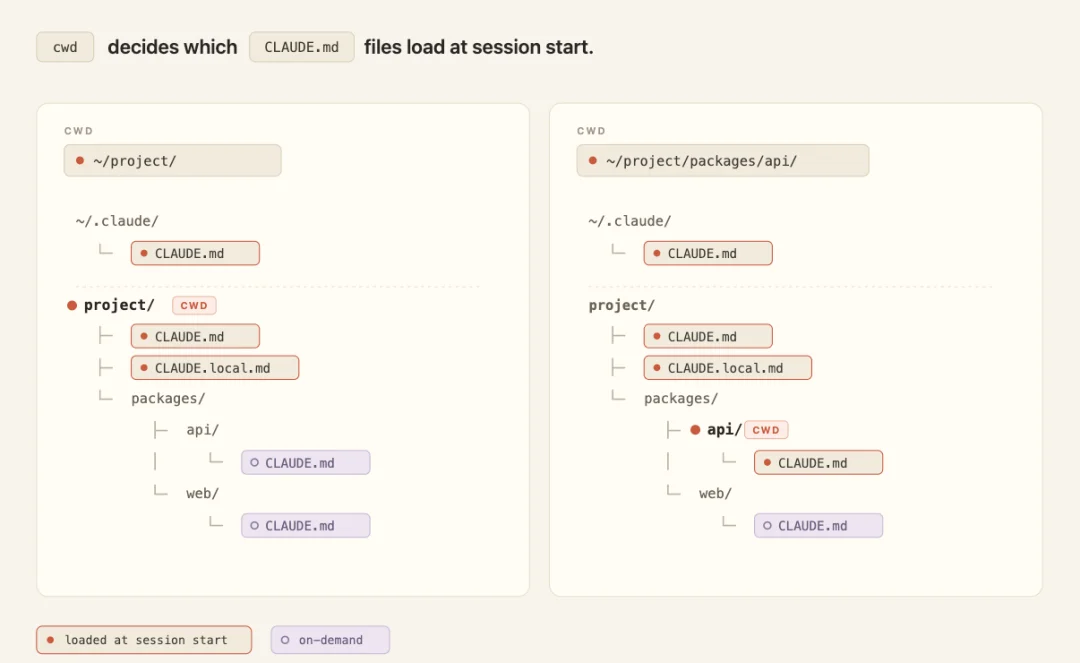
子目录 CLAUDE.md 只在 Claude 碰到那个目录时才加载
对此,官方建议给每个团队的目录放自己的 CLAUDE.md,开发者用 claudeMdExcludes 配置跳过不相关团队的文件,团队之间不互相占用上下文
也如同会不断膨胀的 instruction 一样,CLAUDE.md 也可能会像所有没有 owner 的配置文件一样不断膨胀...毕竟人总喜欢不断的积累规则、加规则,然后这个 CLAUDE.md 也会不断膨胀,让指令遵循率也下降
CLAUDE.md 的正确用法
告诉 Claude 项目长什么样、构建命令是什么。流程和约束放到 Rules、Skills 这些按需加载的机制里
对于组织级别的安全策略和合规要求,可以通过 MDM 或配置管理工具统一部署一份集中管理的 CLAUDE.md 到开发者机器上,这份文件不能被个人配置排除
这给特定文件或目录设定的约束,可以做到「碰到这类文件才生效」

Rules 是 .claude/rules/ 目录下的 markdown 文件。你可以把它理解成更精细的 CLAUDE.md:CLAUDE.md 是全局生效的,Rules 可以只在碰到特定路径的文件时才加载
不加路径限定的 Rule 跟写在 CLAUDE.md 里没区别:启动即加载,全程占 token。加了路径限定就不一样了
--- paths: - "src/api/**" - "**/*.handler.ts" --- 所有 API handler 必须用 Zod 做输入校验
只有当 Claude 读取 src/api/ 下的文件时,这条 Rule 才会加载。做文档的时候,这条规则压根不在上下文里,不浪费 token
至于什么时候该用 Rule?
当一条约束是跨目录的(比如所有 migration 文件只能追加、所有测试文件必须用某个 mock 库),但又不需要全局生效时,path-scoped rule 就是最好的选择
这个算是大家最熟悉的「技能包」了,只在被调用时才加载完整内容,平时只占几十个 token

Skills 的位置在 .claude/skills/ 目录下,每个 skill 是一个文件夹,里面有一个 SKILL.md 定义名字、描述和完整指令
然后,这里我必须要说一点,也是常见的误区:
Skill 不是提示词 ,也通常不作为数据源,通常不会有「小红书搜索 Skill」的
Skill 的本质,是把一堆文件,按约定的结构打包成 .zip,然后把后缀改成了 .skll,所以当你调用别人的 Skill 时,本质是把别人打包文件夹喂给大模型:如果文件夹里有提示词,当然可以把 Skill 当提示词用,但绝对不能说 Skill 是提示词
说回来,当 Agent 启动的时候,并非加载 Skill 的全部内容,而只是加载其名字和描述(几十个 token 的事),完整内容等到 skill 被调用时才进上下文
Skill 调用方式有两种:人工斜杠命令(比如 /code-review)或者 Claude 自动匹配任务

Skills 通过 system prompt 触发,用到才进上下文
Skill 跟 CLAUDE.md 的核心区别是「流程 vs 事实」。CLAUDE.md 放的是 Claude 需要随时知道的事实(构建命令、目录结构)。Skill 放的是需要按步骤执行的流程(部署清单、发布流程、review checklist)。流程不需要全程占 token,用到的时候加载就行
当对话内容过长,对话内容被压缩时,不同的内容会被以不同的方式压缩:
Anthropic 有一份完整的 skill 构建指南:查看指南 https://claude.com/blog/complete-guide-to-building-skills-for-claude
这个也相对容易理解,就是让 Agent 多开几个窗口干活,在独立的上下文窗口里跑任务,跑完只把结论交回来

Subagents 是 .claude/agents/ 目录下的 markdown 文件,用 YAML frontmatter 定义名字、描述、模型选择和可用工具。你可以把它理解成一个专门处理某类任务的独立助手
跟 Skills 的关键区别在于隔离性。Skill 在主线程里执行,你能看到每一步的中间过程。Subagent 在自己独立的上下文窗口里跑,主会话看不到它的中间过程
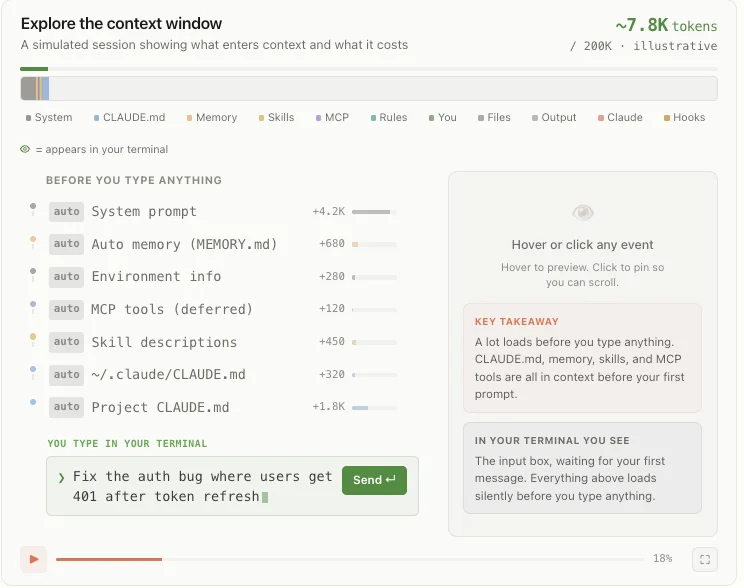
Claude Code 的上下文窗口结构,Subagent 有自己独立的窗口
一个 subagent 做了 50 轮搜索、读了 200 个文件,主会话的上下文窗口里只多了一段摘要,这也是为什么要用它:SubAgent 做脏活累活,不污染主会话,并且能加快效率
在实际使用中,有三个典型场景可以去尝试:深度搜索(大量中间结果不需要保留)、日志分析(翻几百行 log 找问题)、依赖审计(逐个检查库版本)
Subagent 这东西时真的很好用,跑测试什么的非常省心。这几天我正在弄 AGI Bar 的 Drinking Plan,然后做了个小程序,完全是 SubAgent 集群在弄,这里我放个图大家感受下(其实中间我中断了次,实际上已经跑了 40+ 个小时了)
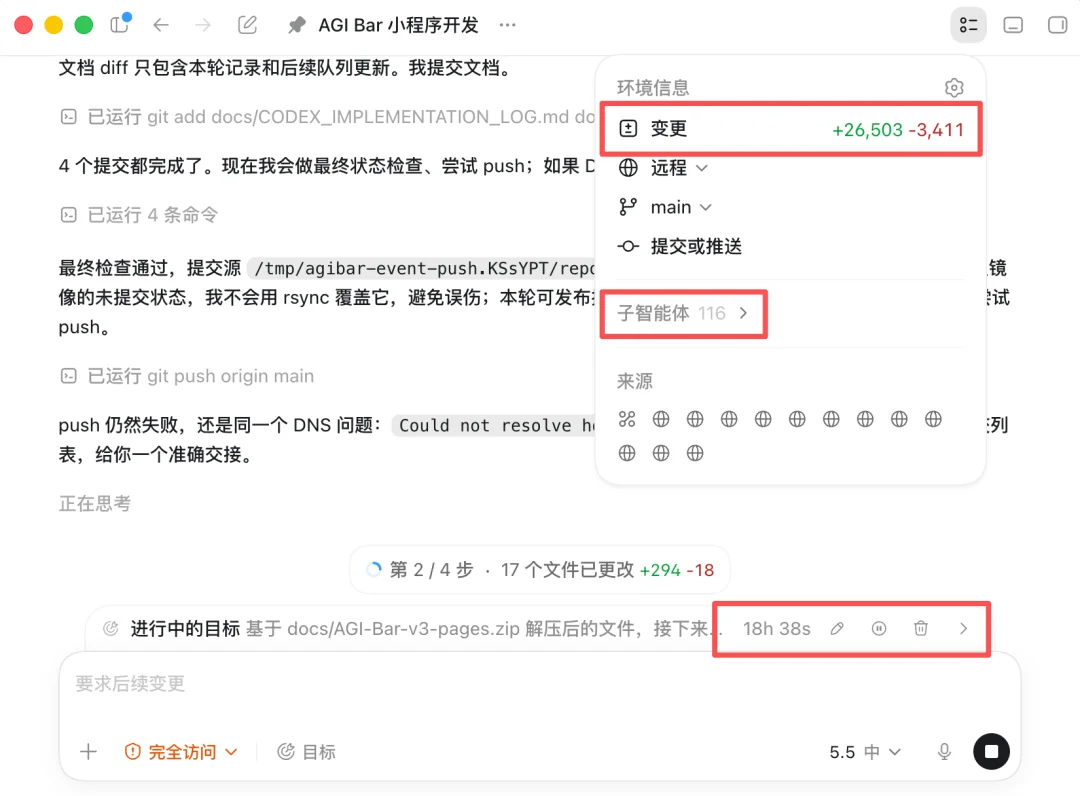
然后,Subagent 可以嵌套,最深五层,后面讲 Dynamic Workflows 的时候会看到,这个嵌套能力是大规模编排的基础
怎么选?
需要看到每一步的中间结果吗?需要就用 Skill
不需要,让它自己跑完给你一个结论,用 Subagent
这东西的本质,是触发脚本:当遇到特定的问题,就自动执行,跟模型的判断力无关

Hooks 是 Claude Code 里最不像 AI 的机制。你在 settings.json 里注册一个 hook,指定「当某个事件发生时,执行这条命令」。IFTTT 知道吧?就是那种: if this, then do that
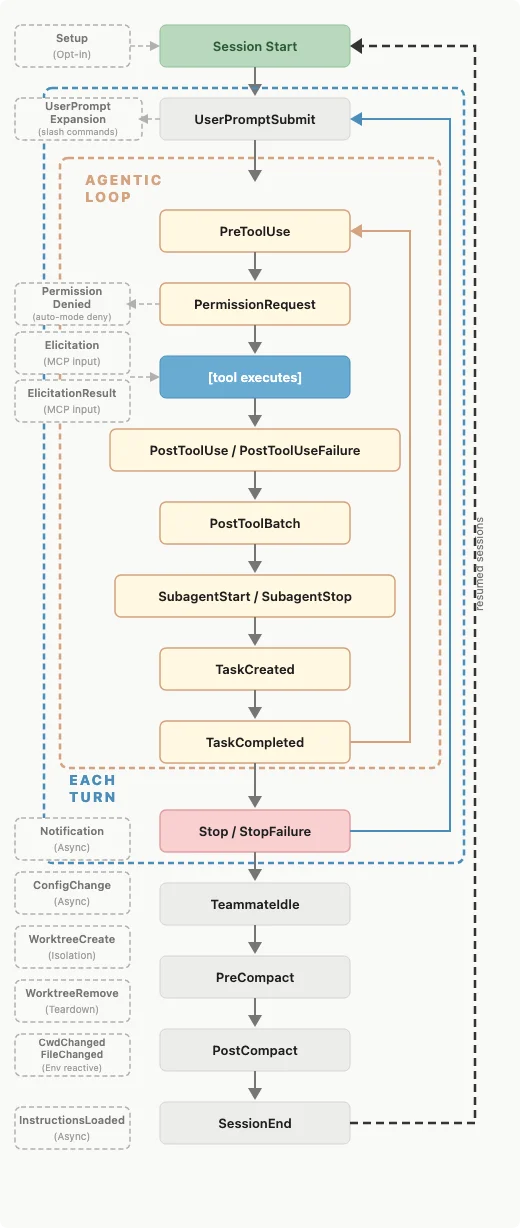
八种 hook 事件覆盖从启动到完成的全流程
可以先看一下上面这张图,有八种 Hook 事件:
PreToolUse工具执行前触发。拦截危险命令、验证文件路径、自动批准安全操作。exit code 2 直接阻止执行
PostToolUse工具执行后触发。写文件后自动跑 Prettier,改代码后自动跑 linter
PermissionRequest权限对话框弹出前触发。npm test 跑了第一百遍还在问你要不要允许?自动批准
SessionStart会话启动时触发。自动注入 git status、TODO 列表
PreCompact上下文压缩前触发。把完整对话备份到文件,防止重要决策丢失
Stop回复完成时触发。检查任务是否做完、测试是否通过。返回 "continue": true 让 Claude 继续干
SubagentStop跟 Stop 一样,但针对 subagent
UserPromptSubmit提交 prompt 时触发。自动追加当前 sprint 信息
而 Hook 动作本身有五种类型:command(执行命令)、HTTP(调接口)、mcp_tool(调 MCP 工具)、prompt(让模型判断)、agent(启动 agent 判断)。前三种完全确定性执行,后两种用模型的判断力
如果某件事绝对不能发生,用 hook 或 permission 做硬护栏
比如,之前我在弄「龙虾大逃杀」的时候,不是被踢了么...艹...龙虾大逃杀:存活下来的,拿 Mac mini|群里有只会踢人的龙虾
当时我是图个懒省事儿,直接写在系统提示词里面的,除此之外没加任何防护,但江湖险恶、人心难测...屮屮屮屮屮....被踢了之后痛定思痛,才上了 permission 硬护栏,活动才能顺利进行
对了,忘了说了,当时比赛最终赢家是【四毛】,我加了一个月好友才加上
然后那段时间 Mac Mini 无现货(这可恶的龙虾潮),订等了好久才到
之后还会有类似的活动,欢迎大家来参加:中奖概率倍儿高,奖品也嘛倍好~
话说回来,做安全防护的时候,任何的提示词防护都是不靠谱的,都很有可能在长会话、压力大、或被 prompt injection 干扰时失效。而 PreToolUse hook 拦截就是确定性的,作为大守密者,永远帮你把握住「永远不要执行 rm -rf」这样的信息
更多 hook 配置细节:查看指南 https://claude.com/blog/how-to-configure-hooks
你可以通过这个,修改 Claude Code 的「人设」为猫娘,注入到 system prompt 里,权重最高但影响面也最大
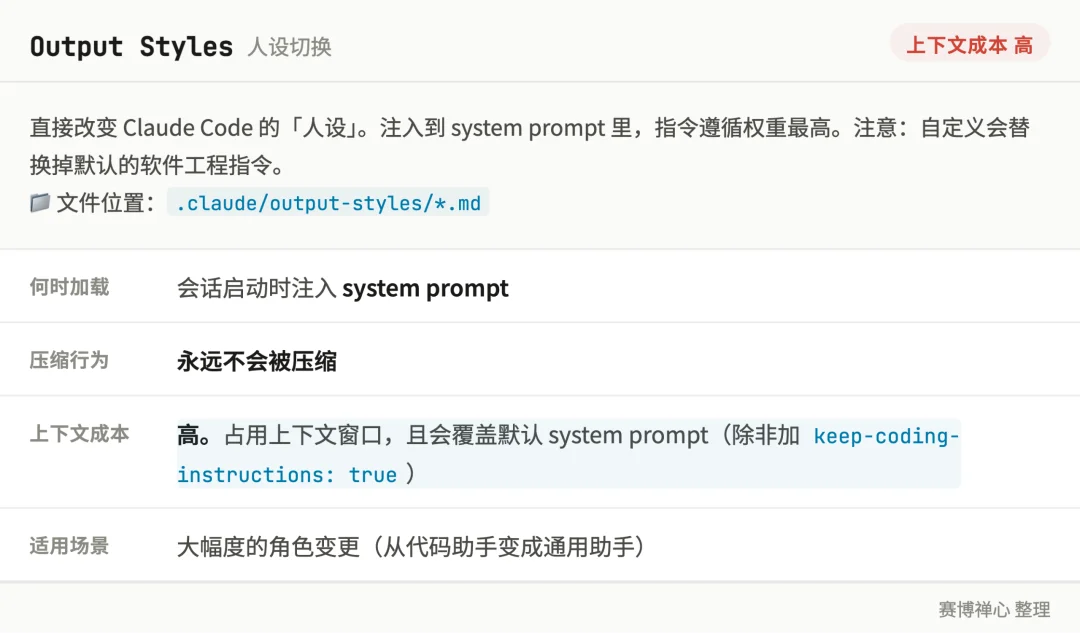
Output Styles 这个东西的位置,在 .claude/output-styles/ 下面,能够注入到 system prompt 里、永远不会被压缩,且指令遵循权重最高
但在另外的一方面,你得知道:自定义 output style 会替换掉默认的 system prompt
这里说一下 system prompt,这是 Claude 里的内置基础提示词,包含了很多定义,比如:怎么限定改动范围、安全问题怎么处理、改完代码先跑测试
除非你在 frontmatter 里加 keep-coding-instructions: true
对此如果你想进一步研究的话,可以先看一下三个内置的 style:Proactive(自主决策多)、Explanatory(教学模式)、Learning(协作编码)
一句话解释:通过 CLI 参数临时往 system prompt 后面追加内容,不修改默认指令,只对当次调用生效

如果觉得 Output Styles 改动太大,append-system-prompt 是一个更甜品的选择。它只往默认 system prompt 后面追加一段内容,不替换任何东西。Claude Code 原本的软件工程指令全部保留
在 CLI 里,你可以这么输入:
claude --append-system-prompt "所有回复使用中文,代码注释也用中文"
这条指令只对当次调用生效,不写文件,不跨 session。适合加编码规范、输出格式、语气偏好这类轻量指令
压缩行为跟 Output Styles 一样:永远不会被压缩
但要注意一个递减效应:追加的指令越多,Claude 对每条指令的遵循率越低。特别是指令之间有冲突的时候,遵循率下降得更快
对于这些注入方法,其实也有些常见的配置误区的,这些来自官方,我给翻译&补充了下:
错误:「每次 X,必须做 Y」写在 CLAUDE.md 里
比如你希望每次编辑文件后自动跑 formatter。这类行为应该用 PostToolUse hook。模型选择做一件事跟自动执行一件事完全是两码事
错误:「绝对不要做 Z」写在 CLAUDE.md 里
绝对性约束用 PreToolUse hook 做硬护栏,exit code 2 直接阻止。组织级别的护栏用 Managed Settings,管理员部署,用户不能覆盖
错误:30 行的流程写在 CLAUDE.md 里
部署流程、review checklist 放 skill。CLAUDE.md 放事实,skill 放流程
错误:Rule 没加路径限定
只适用于 src/api/** 的约束,没加 paths: 就跟写在 CLAUDE.md 里一样,全程加载白费 token
错误:个人偏好写在项目级文件里
个人偏好(比如 commit message 格式)放用户级的本地文件,项目级文件只放团队共识
前段时间,Anthropic 发布了 dynamic workflows/动态工作流,简单来说就是让 Claude 自己写编排脚本,协调多个 subagent 并行工作,解决复杂任务
其诞生,是为了解决默认 harness 的三个老问题:
→偷懒Agentic laziness,安全审查要查 50 项,Claude 查到第 35 项就宣布完成了
→自我偏好Self-preferential bias,让 Claude 检查自己写的代码,它倾向于觉得没问题
→目标漂移Goal drift,长会话中每次压缩都是有损的,边缘需求和约束容易在压缩中丢失
在这个过程中,三个核心函数起到了作用:
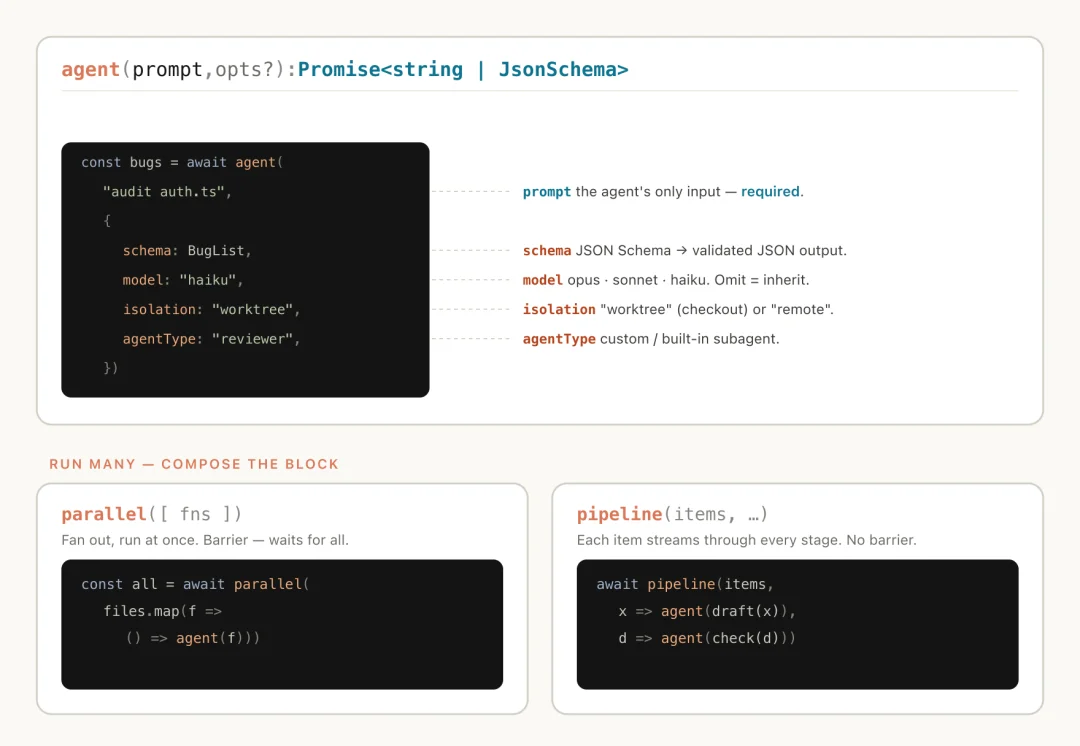
Dynamic workflow 用独立上下文窗口隔离每个子任务,从结构上消解这三个问题。触发方式很直接:跟 Claude 说「用一个 workflow」,或者用触发词 ultracode
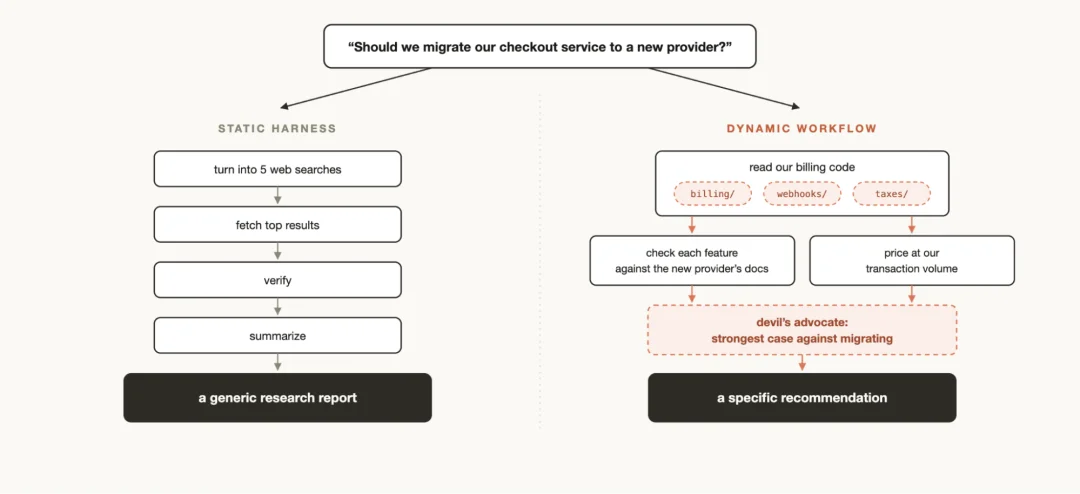
静态工作流 vs 动态工作流
至于 Dynamic workflow 的编排方式,A社总结有以下六种:
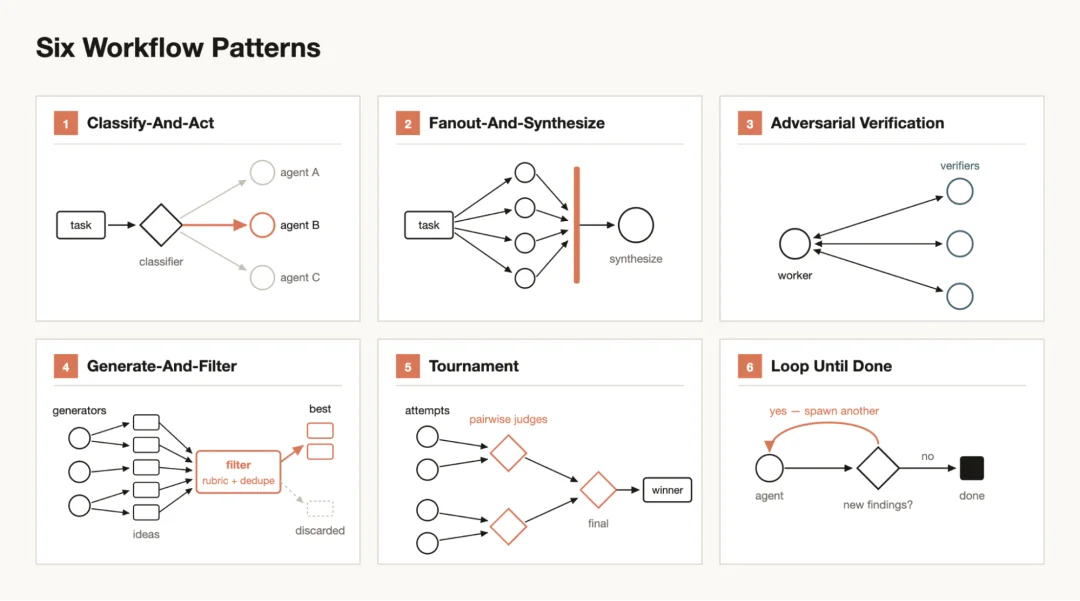
常见的工作流编排模式
Classify-and-act先用一个 classifier 判断任务类型,再分发给对应的专用 agent 处理
Fan-out-and-synthesize
把任务拆成 N 个子任务,每个跑一个 subagent,最后一个 agent 汇总结果
Adversarial verification
每个执行 agent 配一个验证 agent,按标准对抗性检查输出
Tournament
N 个 agent 用不同方法做同一件事,逐对比较选出最优
Generate-and-filter
先大量生成,再过滤去重,只留验证过的高质量结果
Loop until done
不设固定轮数,循环 spawn agent 直到满足终止条件
以之前 Bun 从 Zig 重写到 Rust 用了 dynamic workflows 这个事儿为例,过程中每个修复跑一个 subagent 在独立 worktree 里改,另一个 agent 对抗性 review,通过后合并
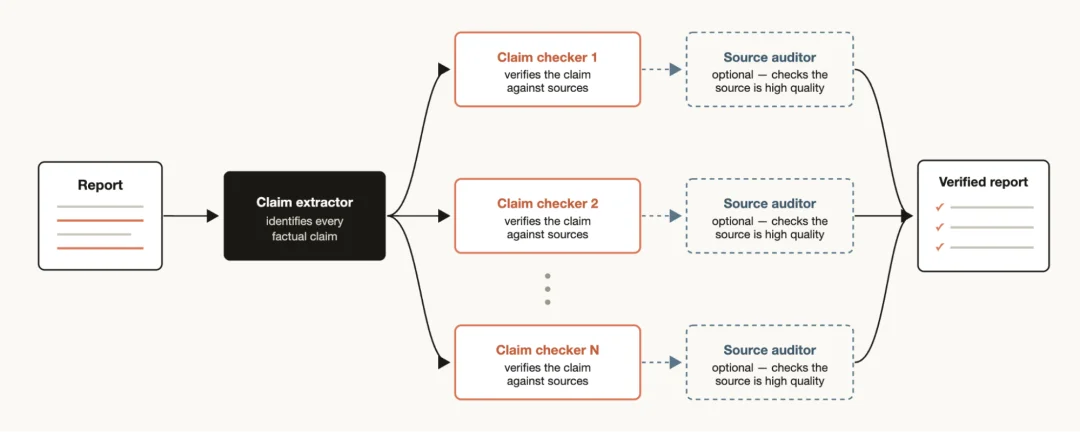
深度验证模式:执行 agent + 验证 agent 对抗
Deep research 是 Claude Code 内置的一个 workflow skill(/deep-research)。扇出搜索、抓取源文档、对抗验证每条声明、汇总成带引用的报告
还有一个反向用法:让 workflow 翻你最近 50 个 session,找出你反复修正 Claude 的模式,聚类成规则候选,对抗验证每条(能不能真的防止之前的错误?),通过的写进 CLAUDE.md
反向用法:从历史 session 挖掘规则候选
这些上下文注入的方法,本质是延续一个思路:需要的时候,出现;不需要的时候,消失
对应到工程上,就是:不同的指令,要有不同的生命周期
有的需要全程在场(CLAUDE.md),有的只在特定场景出现(path-scoped Rules),有的用到才加载(Skills),有的在独立窗口里跑(Subagents),有的完全不占上下文(Hooks)
把所有指令塞进一个 CLAUDE.md 是最简单的做法,但也是最浪费、且会污染上下文的做法,做正式项目的时候,就不推荐了
事实放 CLAUDE.md,流程放 Skill,护栏放 Hook,隔离任务给 Subagent
然后,如果整套 Agent 系统是整个团队在用,就可以尝试着把这些东西打包成一个 plugin,方便共享/分发
但这个 plugin 又该怎么做呢?Agent 时代如何做项目管理呢?就是我们下次再说的事情了
文章来自于微信公众号 “赛博禅心”,作者 “赛博禅心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
